
向量数据库专门设计用于存储和管理向量数据,在许多人工智能应用中发挥着关键作用,如语义文本搜索和图像搜索。虽然传统的词项匹配和BM25算法在文本检索中仍然具有重要意义,但广泛采用的Elasticsearch系统最近也增加了向量搜索功能。值得注意的是,开源高性能SQL向量数据库MyScaleDB最近也引入了全文搜索 (opens new window)功能。在本文中,我们展示了MyScaleDB在全文搜索性能方面与Elasticsearch不相上下,同时实现了更低的延迟和40%的内存利用率。此外,当结合向量搜索时,MyScale的性能提高了10倍,而成本仅为原来的12%。凭借其高性能、低成本以及基于ClickHouse的丰富SQL生态系统,MyScaleDB成为Elasticsearch的高效和强大的升级和替代方案。
# 什么是Elasticsearch
Elasticsearch是一个基于Apache Lucene构建的分布式RESTful搜索和分析引擎。它可以快速存储、搜索和分析大量数据,在日志分析、应用搜索、安全分析和业务分析等领域被广泛使用。
Elasticsearch具有以下优点:
- 强大的搜索能力:Elasticsearch提供强大的全文搜索能力,包括精确值、全文和向量搜索,以及复杂的查询、过滤和聚合操作,使用户能够快速准确地检索所需信息。
- 丰富的功能:Elasticsearch提供丰富的功能和灵活的配置选项,如文本分析、聚合分析和地理空间搜索,以满足各种搜索和分析需求。
- 丰富的生态系统:Elasticsearch的生态系统非常庞大,包括各种插件、工具和第三方集成,扩展了其功能和应用场景,为用户提供更多选择和灵活性。
- 分布式架构:作为一个分布式系统,Elasticsearch可以轻松扩展到多个节点,实现高可用性和横向扩展性,适用于大规模数据处理和分析任务。
- 实时数据处理:Elasticsearch支持实时数据的索引和搜索,可以快速处理大量实时数据并提供即时的查询结果。
然而,Elasticsearch仍然存在一些缺点,包括:
- 陡峭的学习曲线:Elasticsearch的学习曲线相对陡峭,特别是对于初学者来说,需要时间来掌握其复杂的概念和使用方法。
- 有限的向量检索算法:截至8.13版本,Elasticsearch对向量检索算法的支持有限,如基于HNSW的暴力k最近邻搜索和近似k最近邻搜索。这限制了它在复杂向量检索场景中的应用。
- 高资源消耗:由于其强大的功能和分布式架构,Elasticsearch在运行时需要相对较高的资源,包括内存、CPU和存储空间。
总之,Elasticsearch在文本检索领域是一个强大的工具,但在易用性、向量检索和资源利用方面存在一些缺点,限制了它在复杂的人工智能检索和分析场景中的应用。
# 首选的Elasticsearch替代方案:MyScaleDB
MyScaleDB是基于开源SQL列式存储数据库ClickHouse构建的。它采用了自主开发的高性能高数据密度向量索引算法。我们对其检索能力和存储引擎进行了深入研究和优化,使MyScaleDB成为全球首个在综合性能和成本效益方面显著超越专用向量数据库的SQL向量数据库产品。
# 与SQL和向量的本地兼容性
用户使用SQL与MyScaleDB进行交互,降低了使用门槛,减少了学习曲线,使他们能够快速上手和轻松上手。MyScaleDB提供了灵活的数据模型和查询语言,支持用户根据特定需求自定义数据处理和分析策略,提高应用的灵活性和执行效率。在复杂的人工智能应用场景中,将SQL和向量结合起来给开发人员提供了更直观、高效的开发方法,极大地提高了开发效率。
与基于JSON查询的Elasticsearch的领域特定语言(DSL)不同,用户只需要掌握MyScaleDB的向量检索distance()函数就可以使用MyScaleDB。他们可以使用这些信息和他们现有的SQL知识开发复杂的向量检索查询。此外,他们还可以在数据库级别执行复杂的分析和数据处理,加快应用系统的整体处理效率。
例如:
-- 执行向量搜索并返回前10个结果
SELECT
id, title, text
distance(vector, query_vector) as dist
FROM doc_table
ORDER BY
dist ASC
LIMIT 10;
# 使用全文搜索功能替代Elasticsearch
在最新版本中,MyScaleDB引入了全文搜索和混合搜索等强大功能,为处理复杂的人工智能需求和数据挑战提供了实用的解决方案。它嵌入了Tantivy全文搜索引擎库,具有快速的索引构建、高效的搜索和多线程支持。最重要的是,它非常易于使用,非常灵活,非常适合快速检索大规模文本数据。这使用户可以快速搜索存储在数据库中的文本数据,并返回与BM25分数最接近的结果集。
例如,下表显示了我们在相同数据集“wiki”(5.6亿条记录)上运行的文本搜索能力测试的结果。MyScaleDB的P95查询延迟显著降低,内存使用量也有明显减少。因此,在全文搜索的背景下,从功能上讲,MyScaleDB可以有效替代Elasticsearch。
| Engine | Function | QPS | p95 Latency | Peak Memory |
|---|---|---|---|---|
| MyScaleDB | TextSearch | 4099.16 | 4.563ms | 2.35GB |
| ElasticSearch | match | 3907 | 8.863ms | 3.7GB |
| ElasticSearch | wildcard | 4679.16 | 5.583ms | 3.7GB |
# 在向量搜索能力方面胜过Elasticsearch
MyScaleDB利用向量检索技术,支持多种向量索引算法,包括MTSG、SCANN、FLAT以及HNSW和IVF系列。这更好地满足了各种人工智能场景的检索需求,在处理大规模高维数据方面具有绝对优势。
使用大规模数据集(LAION 5M向量,768维),我们测试了MyScaleDB和Elasticsearch在不同并发查询线程下的向量搜索性能。准确性和吞吐量测试的结果如下图所示。
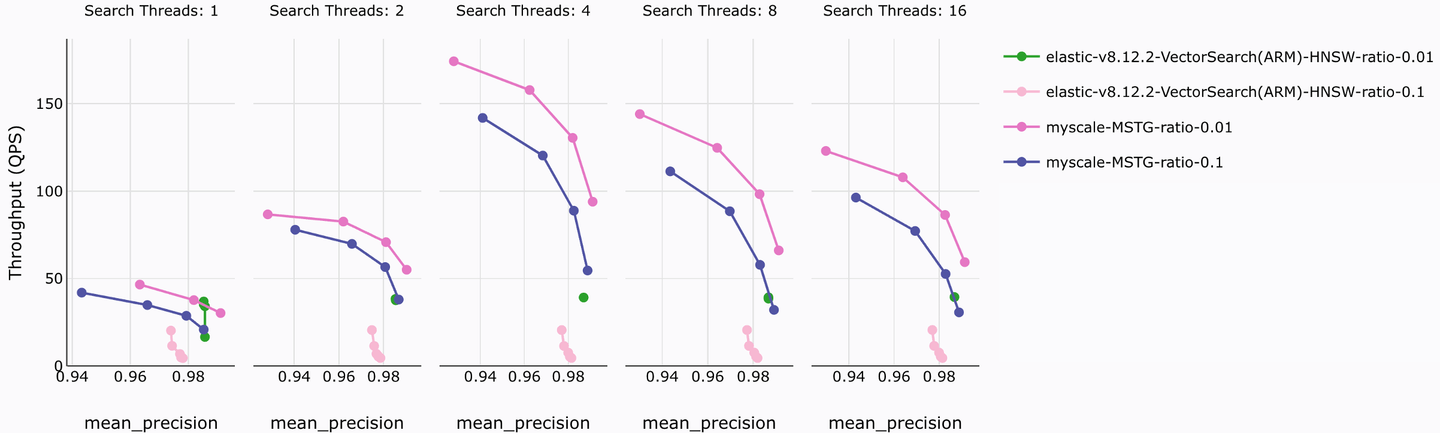
该测试测试了两个常见的过滤比例,0.1和0.01。结果分析显示,在相似的准确性下,MyScaleDB的MSTG索引在QPS性能上提高了10倍。MyScaleDB在索引资源消耗、创建时间、查询延迟和查询成本方面也具有类似的优势。
更值得注意的是,MyScaleDB SaaS每月只需120美元即可为500万个向量提供服务,而ElasticCloud的费用则是其8倍以上的982美元。此外,MyScaleDB支持多种类型的向量索引,并结合其强大的检索性能和经济实用的使用成本,更适合向量检索和分析查询场景。
您可以参考MyScaleDB向量数据库基准测试 (opens new window)获取更多性能测试结果。
# 资源的经济有效利用
如上所述,MyScaleDB是基于高性能列式数据库ClickHouse构建的,目前是用于实时应用和分析的最快和最资源高效的开源数据库。ClickHouse的一些先进功能使其成为一个很好的选择,包括高效的索引机制、数据压缩技术、列式存储结构、向量化查询执行和分布式处理能力。
此外,MyScaleDB的查询引擎针对现代CPU和内存进行了优化。它使用向量化查询处理和数据并行处理技术,充分发挥多核处理器的性能,加速数据计算。继承了ClickHouse的列式存储模型,MyScaleDB实现了高效的数据压缩和快速的列级操作。它只能读取查询中指定的列,减少数据读取量,提高数据压缩率,降低存储成本,特别适用于分析和处理大量数据。
总之,通过结合向量检索技术、全文搜索引擎Tantivy、ClickHouse的高性能特性、分布式架构和优化的查询引擎,MyScaleDB实现了大规模数据的高效处理和分析。它特别适用于复杂的数据分析、混合搜索、全文搜索和向量检索场景。
# 如何用MyScaleDB替代Elasticsearch
这个过程涉及数据建模、数据迁移和查询逻辑转换等任务。有关快速启动MyScaleDB集群、导入数据和执行SQL查询的更多信息,请参阅快速入门 (opens new window)指南。
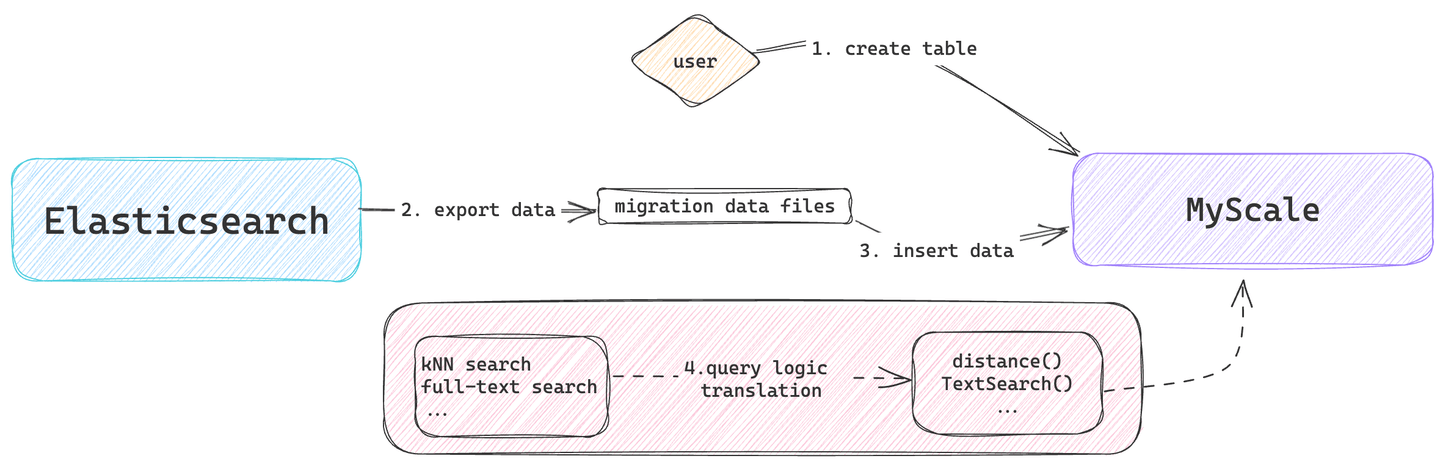
# 数据模型设计
数据模型设计阶段涉及确定如何将Elasticsearch中的文档模型映射到MyScaleDB中的表结构。它主要定义了在MyScaleDB中迁移数据表的列、数据类型和索引类型。
# 数据类型转换
MyScaleDB与ClickHouse的所有数据类型兼容,因此Elasticsearch中的所有字段数据类型在MyScaleDB中都有相应的数据类型。
注意
在Elasticsearch中用于向量搜索的dense_vector类型应根据element_type映射到MyScaleDB中的Array(Float32)或FixedString。其次,应相应地添加列的长度约束。
# 向量索引定义
MyScaleDB支持多种类型的向量索引,但我们强烈建议使用MSTG索引以获得最佳性能。
有关创建和操作加速向量搜索的向量索引的信息,请参阅向量查询教程 (opens new window)。
以下是将Elasticsearch中的图像索引转换为MyScaleDB中的es_data_migration表的示例:
{
"image-index": {
"mappings": {
"properties": {
"file-type": {
"type": "keyword"
},
"image-vector": {
"type": "dense_vector",
"dims": 3,
"index": true,
"similarity": "l2_norm"
},
"title": {
"type": "text"
},
"title-vector": {
"type": "dense_vector",
"dims": 5,
"index": true,
"similarity": "l2_norm"
}
}
}
}
}
CREATE TABLE default.es_data_migration
(
`id` UInt32,
`file_type` String,
`image_vector` Array(Float32),
`title` String,
`title_vector` Array(Float32),
VECTOR INDEX vec_ind_image image_vector TYPE MSTG('metric_type=L2'),
VECTOR INDEX vec_ind_title title_vector TYPE MSTG('metric_type=L2'),
CONSTRAINT check_length_image CHECK length(image_vector) = 3,
CONSTRAINT check_length_title CHECK length(title_vector) = 5
)
ENGINE = MergeTree
PRIMARY KEY id;
# 数据迁移
这个阶段主要涉及从Elasticsearch导出数据及其后续导入到MyScaleDB。
- 从Elasticsearch导出数据:用户可以使用各种方法(如Elasticsearch API、Logstash、Kibana的CSV报告功能和Python的es2csv工具)以常见格式(如JSON或CSV)导出数据。
- 将数据导入到MyScaleDB:MyScaleDB支持不同的数据导入方法,包括Python客户端 (opens new window)、HTTPS接口 (opens new window)等。
例如,以下是使用Python客户端将从Elasticsearch导出的数据文件迁移到MyScaleDB的示例:
import clickhouse_connect
import pandas as pd
# 初始化客户端
# 对于SaaS用户,请转到MyScaleDB集群页面,单击操作下拉链接,然后选择连接详细信息。
client = clickhouse_connect.get_client(
host='127.0.0.1',
port=8123,
username='default',
password=''
)
def convert_vector(vector_str):
return list(map(float, vector_str.split(', ')))
# 读取迁移数据文件
data = pd.read_csv('test.csv', usecols=['_id', 'image-vector', 'title', 'title-vector'], converters={'image-vector': convert_vector, 'title-vector': convert_vector})
# 将数据插入到迁移表中
client.insert('default.es_data_migration', data.values.tolist(), ['id', 'image_vector', 'title', 'title_vector'])
# 查询逻辑转换
原始应用程序的查询检索逻辑,最初由Elasticsearch处理,现在已更改为MyScaleDB搜索,并相应地更新了数据处理逻辑。
{
"knn": {
"field": "image-vector",
"query_vector": [-5, 9, -12],
"k": 10,
"num_candidates": 100
},
"fields": [ "title", "file-type" ]
}
SELECT
id,
title,
file_type,
distance(image_vector, [-5.0, 9.0, -12.0]) AS l2_dist
FROM default.es_data_migration
ORDER BY l2_dist ASC
LIMIT 10

# 结论
通过对MyScaleDB和Elasticsearch的功能和性能进行比较分析,可以看出MyScaleDB不仅是Elasticsearch的高效替代品和升级版,而且是一种能够适应未来数据需求和技术趋势的先进数据解决方案。它在向量搜索和资源成本方面具有显著优势。
此外,基于ClickHouse强大的分布式存储和处理架构,MyScaleDB在可扩展性方面非常灵活,可以轻松扩展到大型集群,以满足不断增长的数据需求。
此外,MyScaleDB与ClickHouse的生态系统组件兼容,包括丰富的文档资源和广泛的社区支持。它还与全球流行的开发工具集成,如Python客户端 (opens new window)、Node.js (opens new window)和LLM框架,包括OpenAI (opens new window)、LangChain (opens new window)、LangChain JS/TS (opens new window)和LlamaIndex (opens new window),为用户提供更好的用户体验和支持。
最后,MyScaleDB支持广泛的数据类型和查询语法,使其适应不同的数据需求和查询场景。凭借其全面的SQL数据管理能力、强大的数据存储和查询能力,MyScaleDB将在未来的数据存储和处理中发挥越来越重要的作用,为用户提供更丰富、更高效的服务。



