
在当今世界中,推荐系统已经成为提升各种平台用户体验的重要工具,包括电子商务、流媒体服务、新闻订阅、社交媒体和个性化学习等。
在推荐系统领域,传统方法依赖于分析用户-物品交互和评估物品相似性。然而,随着人工智能领域的进步,推荐系统的领域也得到了发展,提高了精确性并根据个人偏好进行定制推荐。
# 广泛采用的内容推荐方法
内容推荐系统使用了三种类型的过滤方法。有些使用协同过滤 (opens new window),有些使用基于内容的过滤 (opens new window),还有一些使用这两种方法的混合方法。让我们详细讨论一下。
# 基于内容的过滤
基于内容的过滤侧重于物品本身的特征。它推荐与用户先前表现出兴趣相似的物品。
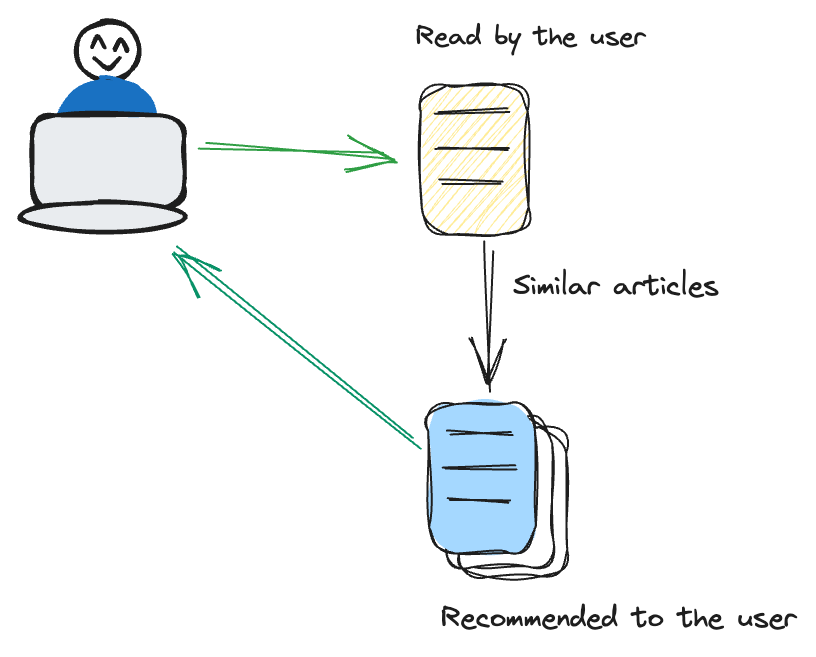
例如,如果用户经常观看惊悚电影,推荐系统会采用一种定制的方法,通过建议惊悚类型的其他电影来满足用户的需求。这种方法非常注重物品的固有特征,如类型、作者或艺术家。通过专注于这些属性,系统确保了更加精准和特定内容的推荐策略,与用户的偏好密切相关。
# 协同过滤
协同过滤是以用户为中心的。它分析用户行为的模式和相似之处,以进行推荐。
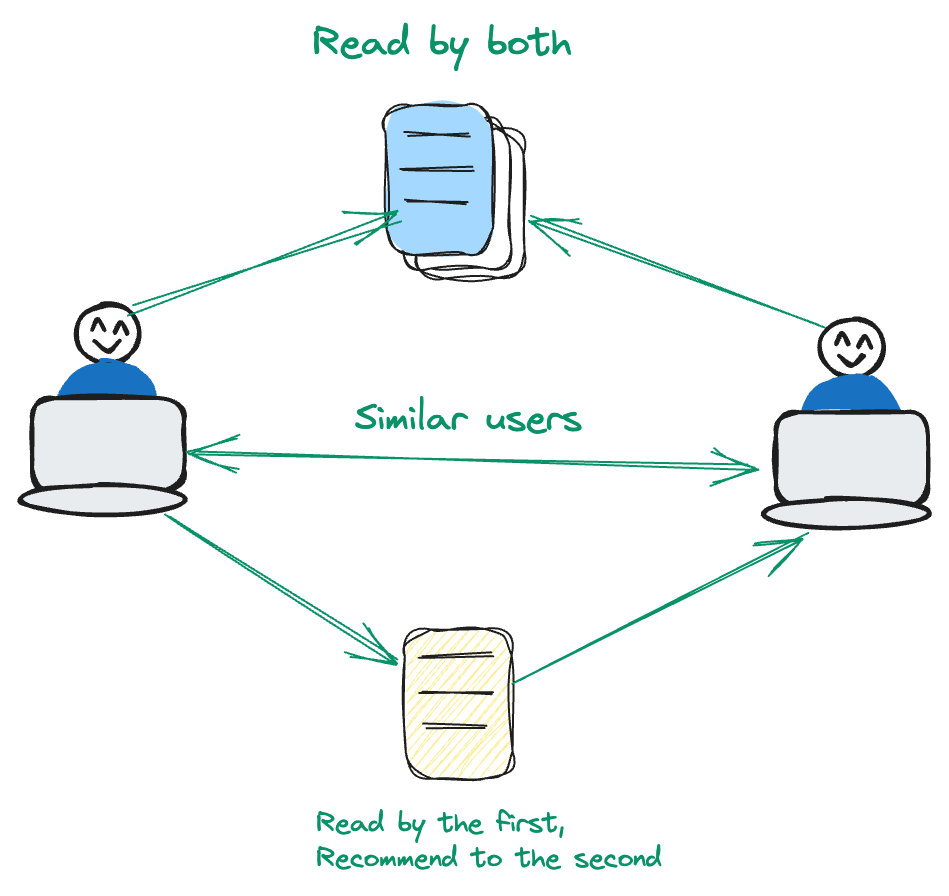
假设用户A和用户B对一组特定电影有共同的兴趣。现在,如果用户B喜欢一部用户A尚未接触过的电影,推荐系统会注意到这一点。在这种方法中,重点是利用用户的交互和偏好,而不是以内容为中心的方法。通过优先考虑用户和物品之间的动态关系,系统可以为用户提供更加个性化的推荐体验。
# 混合技术
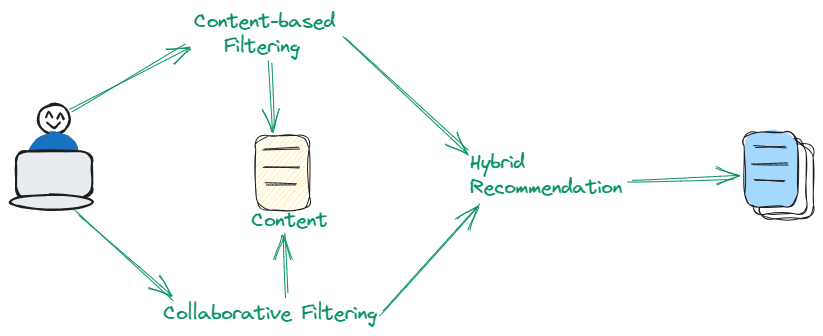
混合技术巧妙地结合了基于内容和协同过滤的优点,以提高推荐准确性。通过结合物品属性和用户偏好模式的双重方法,这种方法巧妙地解决了仅依赖于每种方法独立应用时存在的固有局限性。混合技术在提供精细和多样化的推荐方面特别有效。
# 先进的内容推荐方法
大型语言模型(LLMs)的崛起显著简化了各种任务,尤其是推荐系统的发展。对于现代推荐系统来说,传统的基于内容或协同过滤的依赖已经让位于更复杂的方法。现代推荐系统利用语义的力量,通过导航和探索语言意义来提出相关的物品。
在本博客中,我将向您展示如何使用这种先进的方法构建内容推荐系统。首先让我们先了解一下这个系统所需的工具。
![]()
# 工具和技术
在这个项目中,我们将使用OpenAI的文本嵌入模型 (opens new window),MyScale作为向量数据库 (opens new window),以及TMDB 5000电影数据集 (opens new window)。
- OpenAI:我们将使用OpenAI的模型
text-embedding-3-small来获取文本的嵌入,然后使用这些嵌入来开发模型。 - MyScale:MyScale是一个SQL向量数据库,我们可以使用它来优化存储和处理结构化和非结构化数据。
- TMDB 5000电影数据集:该数据集包含了一系列电影的元数据,包括演员、剧组、预算和收入等详细信息。
# 加载数据
我们有两个关键的CSV文件:tmdb_5000_credits.csv和tmdb_5000_movies.csv。这些文件包含了各种电影的基本信息,将成为我们推荐系统的基础。
import pandas as pd
credits = pd.read_csv("tmdb_5000_credits.csv")
movies = pd.read_csv("tmdb_5000_movies.csv")
# 数据预处理
数据预处理对于确保推荐系统的质量至关重要。我们将合并这两个CSV文件,并关注最相关的列-title、overview、genres、cast和crew。这一步是为了精炼数据,使其适合我们的模型。
credits.rename(columns = {'movie_id':'id'}, inplace = True)
df = credits.merge(movies, on = 'id')
df.dropna(subset = ['overview'], inplace=True)
df = df[['id', 'title_x', 'genres', 'overview', 'cast', 'crew']]
通过合并和筛选数据,我们为系统创建了一个干净而专注的数据集。
# 生成语料库
接下来,我们通过将overview、genre、cast和crew组合成一个字符串,为每部电影生成一个corpus。这些综合信息有助于系统进行准确的推荐。
import pandas as pd
# 假设'df'是您的DataFrame,并且它具有'overview'、'genres'、'cast'和'crew'列
def generate_corpus(row):
overview, genre, cast, crew = row['overview'], row['genres'], row['cast'], row['crew']
corpus = ""
genre = ','.join([i['name'] for i in eval(genre)])
cast = ','.join([i['name'] for i in eval(cast)[:3]])
crew = ','.join(list(set([i['name'] for i in eval(crew) if i['job'] == 'Director' or i['job'] == 'Producer'])))
corpus += overview + " " + genre + " " + cast + " " + crew
return pd.Series([corpus, crew, cast, genre], index=['corpus', 'crew', 'cast', 'genres'])
# 对每一行应用该函数
df[['corpus', 'crew', 'cast', 'genres']] = df.apply(generate_corpus, axis=1)
# 获取嵌入
然后,我们使用OpenAI的嵌入模型text-embedding-3-small将我们的语料库转换为嵌入,这些嵌入是电影内容的数值表示。
import os
import numpy as np
import openai
os.environ["OPENAI_API_KEY"] = "your-api-key"
def get_embeddings(text):
response = openai.embeddings.create(
model="text-embedding-3-small",
input=text
)
return response.data
# 获取前1000个条目,因为我们无法将整个5000个条目传递给嵌入模型。如果您想获取整个数据集的嵌入,可以应用一个循环
df=df[0:1000]
embeddings=get_embeddings(df["corpus"].tolist())
vectors = [embedding.embedding for embedding in embeddings]
array = np.array(vectors)
embeddings_series = pd.Series(list(array))
df['embeddings'] = embeddings_series
通过获取文本的向量表示,我们现在可以轻松地使用MyScale进行语义搜索。
# 设置MyScale
正如我们在开头所讨论的,我们将使用MyScale作为向量数据库来存储和管理数据。在这里,我们将连接到MyScale以准备存储数据。
import clickhouse_connect
client = clickhouse_connect.get_client(
host='your-host-name',
port=443,
username='your-user-name',
password='your-password'
)
注意:有关如何连接到MyScale集群的更多信息,请参见连接详细信息 (opens new window)。
# 创建表格
现在,我们根据DataFrame创建一个表格。所有的数据都将存储在这个表格中,包括嵌入。
client.command("""
CREATE TABLE default.movies (
id Int64,
title_x String,
genres String,
overview String,
cast String,
crew String,
corpus String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 1536
) ENGINE = MergeTree()
ORDER BY id
""")
上述SQL语句在集群上创建了一个名为movies的表格。CONSTRAINT确保所有的向量嵌入都具有相同的长度1536。
# 存储数据并在MyScale中创建索引
在这一步中,我们将处理后的数据插入到MyScale中。这涉及到批量插入数据,以确保高效的存储和检索。
batch_size = 100 # 根据您的需求进行调整
num_batches = len(df) // batch_size
for i in range(num_batches):
start_idx = i * batch_size
end_idx = start_idx + batch_size
batch_data = df[start_idx:end_idx]
client.insert("default.movies", batch_data.to_records(index=False).tolist(), column_names=batch_data.columns.tolist())
print(f"已插入第{i+1}/{num_batches}批数据。")
client.command("""
ALTER TABLE default.movies
ADD VECTOR INDEX vector_index embeddings
TYPE MSTG
""")
# 生成电影推荐
最后,我们创建一个根据用户输入生成电影推荐的函数。该函数利用指数衰减因子,使最近观看的电影更具相关性,提高推荐质量。
import numpy as np
from IPython.display import clear_output
genres = []
for i in range(3):
genre = input("输入一个类型:")
genres.append(genre)
genre_string = ', '.join(genres)
genre_embeddings=get_embeddings(genre_string)
embeddings=genre_embeddings[0].embedding
embeddings = np.array(genre_embeddings[0].embedding) # 转换为numpy数组
decay_factor = 0.9 # 根据需要进行调整的指数衰减因子
while True:
clear_output(wait=True)
# 使用组合嵌入来查询数据库
results = client.query(f"""
SELECT title_x, genres,
distance(embeddings, {embeddings.tolist()}) as dist FROM default.movies ORDER BY dist LIMIT 10
""")
# 显示结果
print("推荐电影:")
movies = []
for row in results.named_results():
print(row["title_x"])
movies.append(row['title_x'])
# 要求用户选择一部电影
selection = int(input("选择一部电影(或输入0退出):"))
if selection == 0:
break
selected_movie = movies[selection - 1]
# 获取所选电影标题的嵌入
selected_movie_embeddings = get_embeddings(selected_movie)[0].embedding
selected_movie_embeddings_array = np.array(selected_movie_embeddings)
# 应用指数衰减并更新组合嵌入
embeddings = decay_factor * embeddings + (1 - decay_factor) * selected_movie_embeddings_array
# 归一化组合嵌入
embeddings = embeddings / np.linalg.norm(embeddings)
我们现在已经使用MyScale和向量嵌入构建了一个完全功能的电影推荐系统。请随意尝试本教程,或根据需要创建自己的教程。

# 总结
在本教程中,我们探讨了如何将LLMs与向量数据库MyScale相结合,创建一个内容推荐系统。选择正确的向量数据库对于开发任何高效的应用程序非常重要。MyScale在处理向量数据和结构化元数据方面表现出色,确保快速准确的查询响应。它的高效扩展能力保证了即使数据集扩大,也能保持强大的性能。通过先进的索引和查询功能,MyScale显著提高了应用程序的性能和准确性。
您是否计划使用MyScale构建一个AI应用程序?加入我们,在Twitter (opens new window)和Discord (opens new window)上分享您的想法。



