
AI智能体的出现已经重塑了各个行业,带来了前所未有的效率和生产力提升。研究显示,超过60% (opens new window)的企业主预计通过实施AI将增加生产力。具体来说,64% (opens new window)的人认为AI会提高整体业务生产力,而42%的人期待工作流程将被简化。这些统计数据强调了AI智能体在优化工作流程和推动各行各业增长中的变革性影响。
在日常生活中,我们遇到的AI智能体比我们意识到的更多——从像Siri和Alexa这样的虚拟助手 (opens new window)到流媒体平台上的个性化推荐系统 (opens new window)。这些智能体在增强用户体验、提供定制化解决方案和无缝自动化常规任务中扮演了关键角色。
在AI开发领域,LangChain (opens new window)以其革命性的模块化框架脱颖而出,旨在简化AI驱动语言应用的创建。这一创新工具提供了一个标准化接口 (opens new window)用于与语言模型交互,并与外部数据源无缝集成。LangChain消除了通常与操作大型语言模型(LLMs) (opens new window)相关的复杂性,使其即便对于没有机器学习或AI深厚专业知识的人也变得容易接触。
# 什么是LangChain中的链?
LangChain最初是为了提供一个无缝的接口来集成LLMs与外部数据源而开发的。它旨在弥合强大的AI模型的功能与它们可以利用的大量数据之间的差距。这个框架允许开发者创建高级应用程序,利用LLMs的力量来访问和处理来自各种来源的数据。
LangChain的结构主要基于“链”的概念。这些链代表了将输入转换为期望输出的操作序列。LangChain的优雅之处在于其模块性和灵活性,允许开发者根据自己的具体需求定制工作流。
在LangChain中,一个链是一系列处理输入数据以产生输出的步骤或操作。链中的每一步都执行一个特定功能,例如数据检索、转换或与LLM的交互。链可以是简单的,只涉及几个步骤,也可以是复杂的,涉及多个数据处理和模型交互阶段。
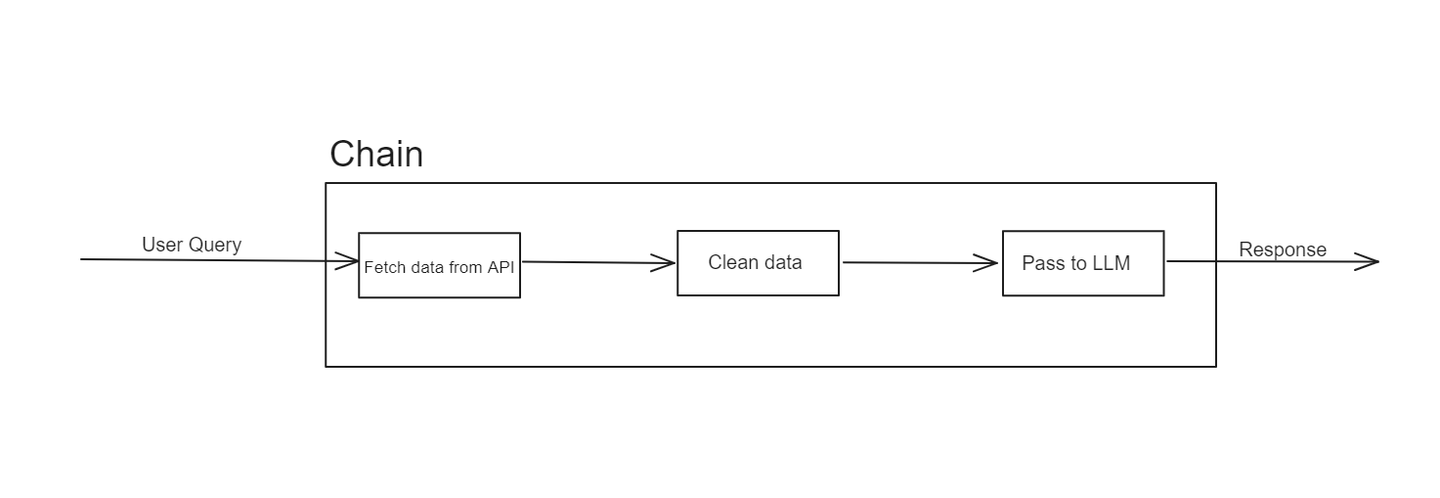
例如,一个链可能从一个API检索数据开始,然后将这些数据通过一系列变换,最终将其输入到LLM以生成响应。这种模块化方法使得设计、测试和重用工作流程的各个组成部分变得容易。
然而,链有其局限性。它们是线性的,有时可能难以应对更动态或自适应的任务。这就是LangChain智能体发挥作用的地方,通过提供更多的灵活性和智能来解决链的局限性。
# 什么是LangChain智能体?
LangChain智能体是旨在增强LLMs能力的强大组件,使它们能够根据这些决策进行决策和采取行动。与遵循预定动作序列的链不同,智能体使用LLMs作为推理引擎来动态确定要执行的动作序列。
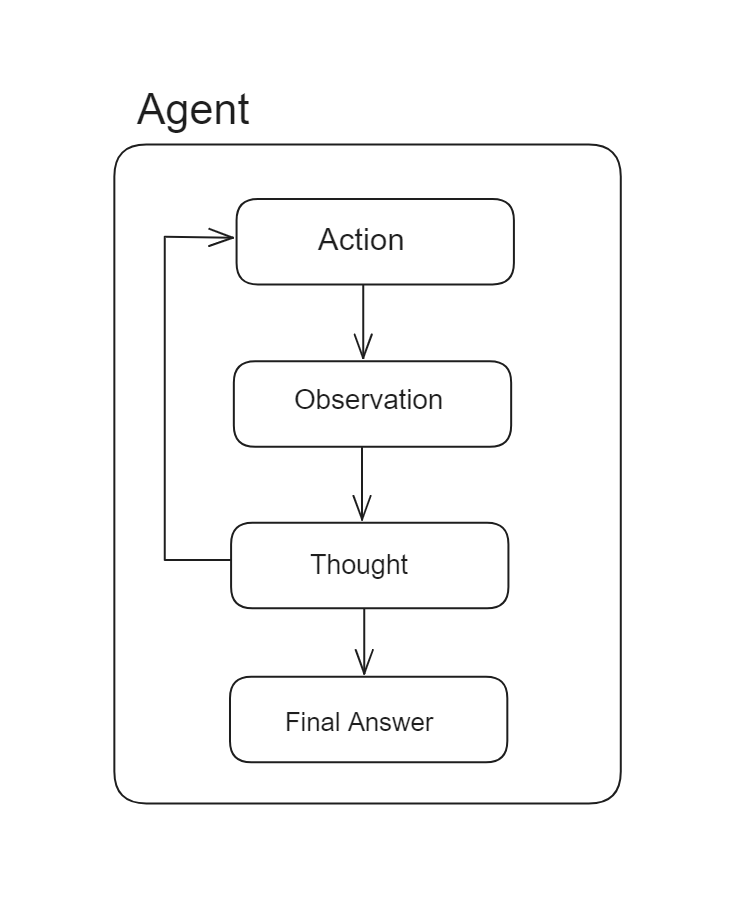
LangChain智能体的核心功能涉及根据输入数据和先前动作的结果选择和执行动作。这使得它们能够以最小的人工干预处理复杂任务。例如,智能体可能会与各种工具和数据源互动,处理信息,并迭代地完善其动作以实现特定目标。
在链中,动作序列是硬编码的,而在智能体中,动作序列不是预先确定的,一个语言模型被用作推理引擎来确定采取哪些动作以及按什么顺序采取。
智能体有几个关键特性:
- 适应性:智能体可以根据它们遇到的数据和上下文调整其行动。这意味着它们不受像链那样预定义步骤序列的限制。
- 自主性:智能体可以独立操作,即兴做出决策,无需持续监督。
- 互动性:智能体可以与多个数据源、工具和LLMs互动,使其在处理各种任务时具有多功能性。
通过整合智能体,您的系统可以管理需要动态响应和适应行为的更复杂工作流程,克服简单链的僵硬性。
# 智能体的主要组成部分是什么
要在LangChain中构建一个有效的智能体,需要几个关键组成部分:
# 工具
工具是智能体用来执行任务的基本构建块,包括与APIs、数据库和数据处理功能的互动。每个工具都提供了智能体可以利用的特定能力,以完成各种任务。
LangChain提供了多种使用不同工具的方式,包括预定义工具、检索器 (opens new window)作为工具,以及自定义工具 (opens new window)。让我们详细探讨其中的每一种:
# 预定义工具
LangChain提供了一系列预定义工具 (opens new window),您可以通过导入它们并将它们集成到您的智能体中来立即使用它们。例如:
from langchain_community.tools import DuckDuckGoSearchRun
search = DuckDuckGoSearchRun()
在这个例子中,我们从langchain_community.tools模块导入了DuckDuckGoSearchRun工具并进行了初始化。初始化后,这个工具可以通过工具包 (opens new window)在智能体中使用,我们稍后会看到。
# 将检索器用作工具
在需要根据用户查询从向量数据库 (opens new window)中获取数据的场景中,LangChain允许您将数据检索器转换为工具并在您的智能体中使用它们。以下
是如何操作:
from langchain.tools.retriever import create_retriever_tool
retriever_tool = create_retriever_tool(
retriever,
"name_of_the_tool",
"Description of the tool",
)
通过使用LangChain的create_retriever_tool方法,您可以将任何检索器转换为LangChain工具。这个方法需要三个参数:您之前创建的retriever,tool的名称,以及工具的描述。描述有助于LLM决定何时使用此工具以及它持有什么类型的数据。
# 自定义工具
LangChain还赋予开发者定义针对其应用程序或用例的定制工具的能力。定义自定义工具的最简单方法是使用@tool装饰器与任何Python方法一起使用。这里有一个例子:
from langchain.agents import tool
@tool
def get_word_length(word: str) -> int:
"""返回一个单词的长度。"""
return len(word)
get_word_length.invoke("abc")
在这个例子中,方法名被用作工具名,docstring充当工具的描述。这种设置使得智能体能够理解并有效地使用该工具。
对于更复杂的工具,您可以扩展LangChain提供的BaseTool类来创建满足特定需求的复杂自定义工具。
# 工具包
工具包是智能体可以访问的工具集合。它定义了智能体可以执行的操作范围和它可以利用的资源。就像这样,它是您已定义的用于在智能体中使用的工具列表:
tool_kit=[retriever_tool,get_word_length]
工具包中的所有工具都以相同的方式运作,无论它们是如何定义的。
# LLM(大型语言模型)
LLM是智能体智能的核心,处理自然语言输入,生成响应,并驱动决策过程。LangChain与各种最先进的LLM(如GPT-4 (opens new window)、BERT (opens new window)和T5 (opens new window))无缝集成,确保智能体可以访问尖端AI功能。
这种集成增强了自然语言理解,允许进行复杂的决策,并支持针对特定领域的定制,使LangChain智能体在执行复杂任务时既多功能又强大。
# 提示
提示是指导LLM行为的初始指令或查询。制定清晰有效的提示对于确保智能体准确高效地执行任务至关重要。
LangChain Hub
LangChain Hub是一个用于发现、分享和管理提示、链、智能体等的中央存储库。它帮助开发者和团队获取高质量的提示并加速其开发过程。
使用LangChain Hub
通过LangChain Hub (opens new window),您可以轻松地将公共提示拉入您的代码库,允许您利用为您的特定用例和所使用的语言模型量身定制的精心制作的提示。以下是如何导入预先编写的提示:
from langchain import hub
prompt = hub.pull("hwchase17/openai-functions-agent")
代码hub.pull("hwchase17/openai-functions-agent")用于从LangChain Hub拉取预定义的提示,专门设计用于与OpenAI函数 (opens new window)一起工作。这个特定的提示是旨在增强使用OpenAI强大语言模型的智能体的功能的集合的一部分。
# 智能体执行者
智能体执行者 (opens new window)是LangChain生态系统中的一个关键元素。它协调智能体的活动,管理操作流程并确保每个组件的协调运作。
从LangChain的文档来看,智能体执行者的工作流程大致如下:
next_action = agent.get_action(...)
while next_action != AgentFinish:
observation = run(next_action)
next_action = agent.get_action(..., next_action, observation)
return next_action
基本上,它是一个while循环,不断调用智能体上的下一个动作方法,直到智能体返回其最终响应。执行者负责:
- 启动任务:它根据给定的提示和上下文开始智能体的活动。
- 管理工作流:它协调工具、工具包和LLM之间的交互,确保工作流的顺畅执行。
- 处理错误:它管理智能体操作中发生的任何错误或异常 (opens new window),提供坚固可靠的性能。
这些组件在智能体的功能中发挥着至关重要的作用。LangChain以极大的灵活性处理这些组件,允许开发者根据自己的需求定制和优化每个部分。

# 使用MyScaleDB和LangChain创建智能体
到目前为止,我们已经探讨了构建智能体所需的重要组成部分。现在,让我们使用MyScaleDB (opens new window)和DuckDuckGo (opens new window)创建一个智能体。这个智能体将有两个工具:
- 检索器:此工具将获取与MyScaleDB遥测 (opens new window)相关的信息。
- DuckDuckGo工具:此工具将从互联网获取数据。
# 设置环境
在我们开始构建智能体之前,让我们安装必要的工具和技术。打开您的终端并输入以下命令:
pip install langchain langchain_openai duckduckgo-search
这将安装构建此智能体所需的所有包。
# 加载检索器工具的数据
让我们首先使用LangChain的WebBaseLoader加载检索器工具的数据:
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 从互联网加载数据
loader = WebBaseLoader("https://myscale.com/blog/zh/myscale-telemetry-llm-app-observability/")
docs = loader.load()
# 将文本分割成更小的块
documents = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200
).split_documents(docs)
# 设置MyScaleDB凭证
在初始化检索器之前,我们需要设置向量数据库的凭证。我们使用的是MyScale,您可以在快速入门指南 (opens new window)中了解更多相关信息。按照如下方式设置凭证:
import os
# MyScaleDB的凭证
os.environ["MYSCALE_HOST"] = "your-hostname-here"
os.environ["MYSCALE_PORT"] = "443"
os.environ["MYSCALE_USERNAME"] = "your-username-here"
os.environ["MYSCALE_PASSWORD"] = "your-password-here"
# 设置OpenAI LLM的OpenAI API密钥
os.environ["OPENAI_API_KEY"] = "api-key-here"
对于这个项目,我们将利用OpenAI嵌入 (opens new window)和ChatGPT,这需要设置OpenAI API (opens new window)密钥。
# 初始化检索器
让我们初始化检索器并将数据放入MyScaleDB检索器 (opens new window)中。
from langchain_community.vectorstores import MyScale
from langchain_openai import OpenAIEmbeddings
vector = MyScale.from_documents(documents, OpenAIEmbeddings())
retriever = vector.as_retriever()
一旦检索器准备好,下一步就是将检索器转换为langchain工具。为此,我们将使用create_retriever_tool方法:
from langchain.tools.retriever import create_retriever_tool
retriever_tool = create_retriever_tool(
retriever,
"MyScale_telemetry",
"Search for information about MyScale Telemetry. For any questions about Telemetry, you must use this tool!",
)
定义的工具将在用户查询有关MyScale遥测时使用。如前所述,工具的描述非常重要,因为它帮助LLM选择基于查询的适当工具。
# 定义搜索工具
让我们为我们的智能体定义第二个工具。这是一个预定义的工具,旨在搜索当前事件或从互联网获取最新信息。
from langchain_community.tools import DuckDuckGoSearchRun
search = DuckDuckGoSearchRun()
# 创建工具包
我们的智能体将使用两个工具:检索器和网络搜索。让我们创建工具包:
tools = [search, retriever_tool]
# 初始化LLM
我们将使用OpenAI的GPT-3.5-turbo模型为智能体:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
# 获取提示
我们将使用与OpenAI模型一起使用的LangChain中心的相同预定义提示,因为我们正在使用OpenAI模型为我们的智能体。
from langchain import hub
# 拉取提示模板
prompt = hub.pull("hwchase17/openai-functions-agent")
prompt.messages
# 创建智能体和智能体执行者
LangChain提供了几种类型的智能体 (opens new window),每种都具有独特的推理能力和功能。对于这个项目,我们将使用最先进和最健壮的智能体:OpenAI Tools智能体 (opens new window)。正如官方文档中强调的那样,这个智能体利用了来自OpenAI的最新模型,提供了增强的性能和广泛的功能。
from langchain.agents import create_tool_calling_agent
agent = create_tool_calling_agent(llm, tools, prompt)
现在,让我们将智能体传递给将处理定义智能体所有功能的AgentExecutor。
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
在AgentExecutor中设置verbose=True启用了智能体操作的详细日志记录。这为调试和理解智能体如何与不同工具互动提供了更大的透明度和洞察力。
# 为智能体添加内存
我们为智能体添加内存,以保留以前交互的上下文,这增强了其在持续对话中提供相关和连贯响应的能力。内存还使智能体能够随时间学习和适应,从而提高其性能并使互动更加个性化和智能化。
from langchain.memory import ChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
memory = ChatMessageHistory(session_id="test-session")
agent_with_chat_history = RunnableWithMessageHistory(
agent_executor,
lambda session_id: memory,
input_messages_key="input",
history_messages_key="chat_history",
)
使用会话ID有助于维护和组织个别用户会话,确保智能体可以准确跟踪和回忆每个会话的特定互动
# 调用智能体
最后,我们可以调用智能体来检索信息。在进行这个查询时:
# 获取有关MyScale遥测的信息
agent_executor.invoke({"input": "What's MyScale telemetry?"}, config={"configurable": {"session_id": "<foo>"}})
结果将类似于此:
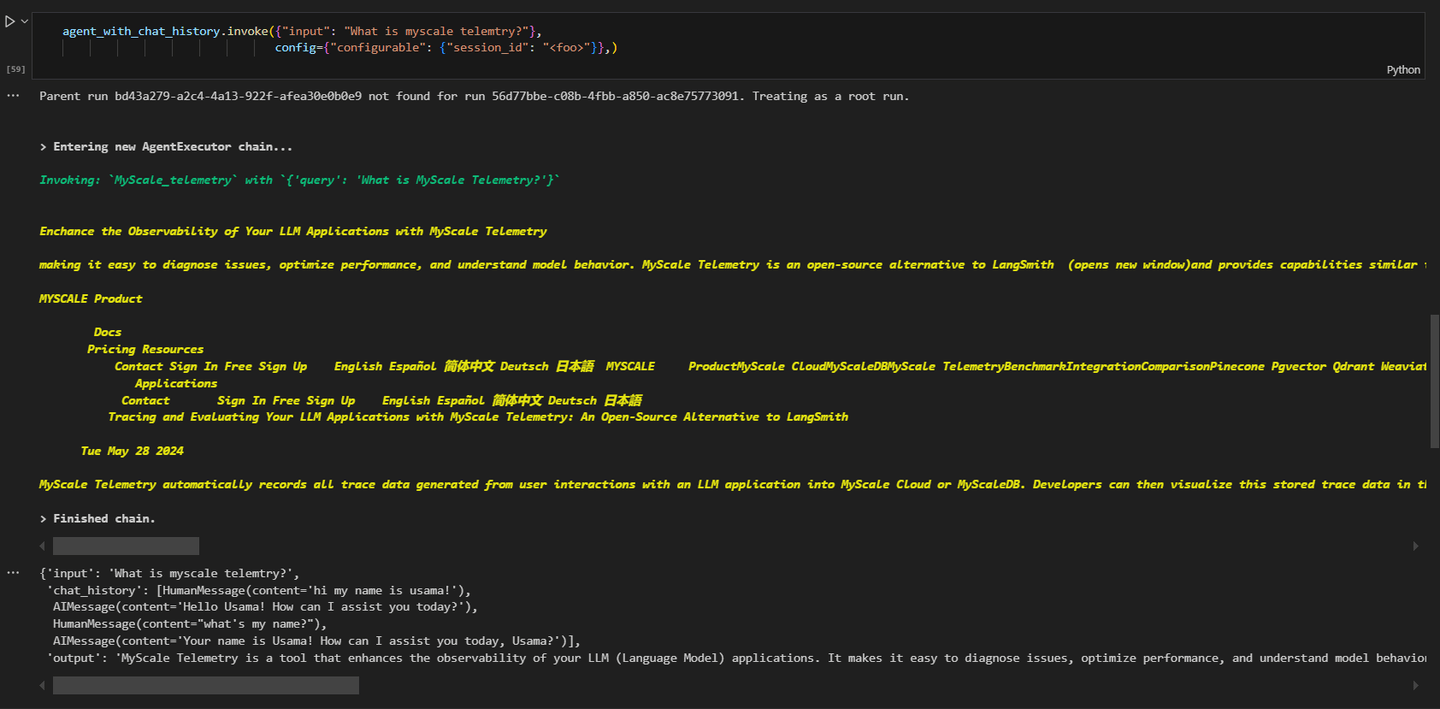
如您所见,查询与MyScale遥测相关,智能体正在调用MyScale_telemetry智能体。
让我们进行另一个查询并从互联网获取最新数据。
# 从网络获取信息
agent_executor.invoke({"input": "How's the weather in California?"}, config={"configurable": {"session_id": "<foo>"}})
结果将类似于此:
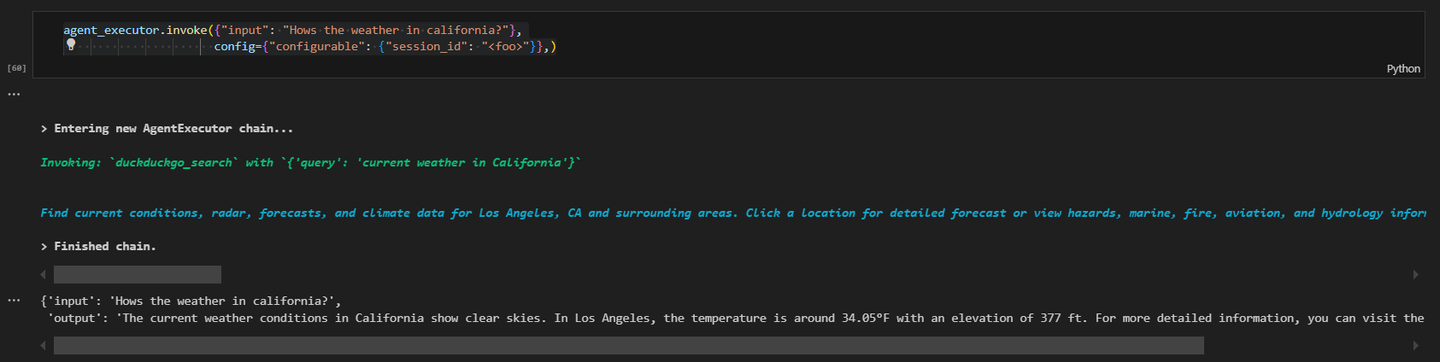
这个实际示例展示了如何使用MyScaleDB和DuckDuckGo工具创建LangChain智能体。每个组件对智能体的功能至关重要,正确设置环境确保了操作的顺畅。
# 结论
LangChain智能体是增强LLMs功能的高级组件。它们通过使LLMs能够根据这些决策进行决策和采取行动来实现这一目标。与遵循固定序列的传统链不同,智能体使用LLMs动态确定行动序列。这种灵活性使智能体能够更有效地处理复杂和变化的任务。LangChain智能体高度模块化,使得易于整合各种工具和自定义功能,这让开发者能够创建针对特定需求的工作流程。
MyScaleDB (opens new window)是向量数据库中的首选之一,以其卓越的性能和可扩展性而闻名。其MSTG(多阶段树图)算法 (opens new window)通过提供更快、更准确的数据检索,胜过其他算法,这对于AI驱动的任务至关重要。MyScaleDB设计用于高效处理大量数据负载,确保可靠和高速的操作。这使得它成为开发者创建需要高效数据管理和检索的强大AI应用的必备工具。



