
在不断发展的人工智能领域中,对更智能、更响应、更具上下文感知能力的聊天机器人的追求,将我们带到了一个新时代的门槛。欢迎来到RAG的世界——检索增强生成(RAG) (opens new window),这是一种创新的方法,将检索系统的广博知识与生成模型的创造力相结合。RAG技术使聊天机器人能够通过访问知识库有效处理任何类型的用户查询。但要有效地利用这种能力,我们需要一个能够匹配其速度和效率的存储解决方案。这就是向量数据库的优势所在,它在管理和检索大量数据方面实现了飞跃。
在本博客中,我们将向您展示如何在几分钟内使用Google Gemini模型和MyScaleDB (opens new window)构建基于RAG的聊天机器人。
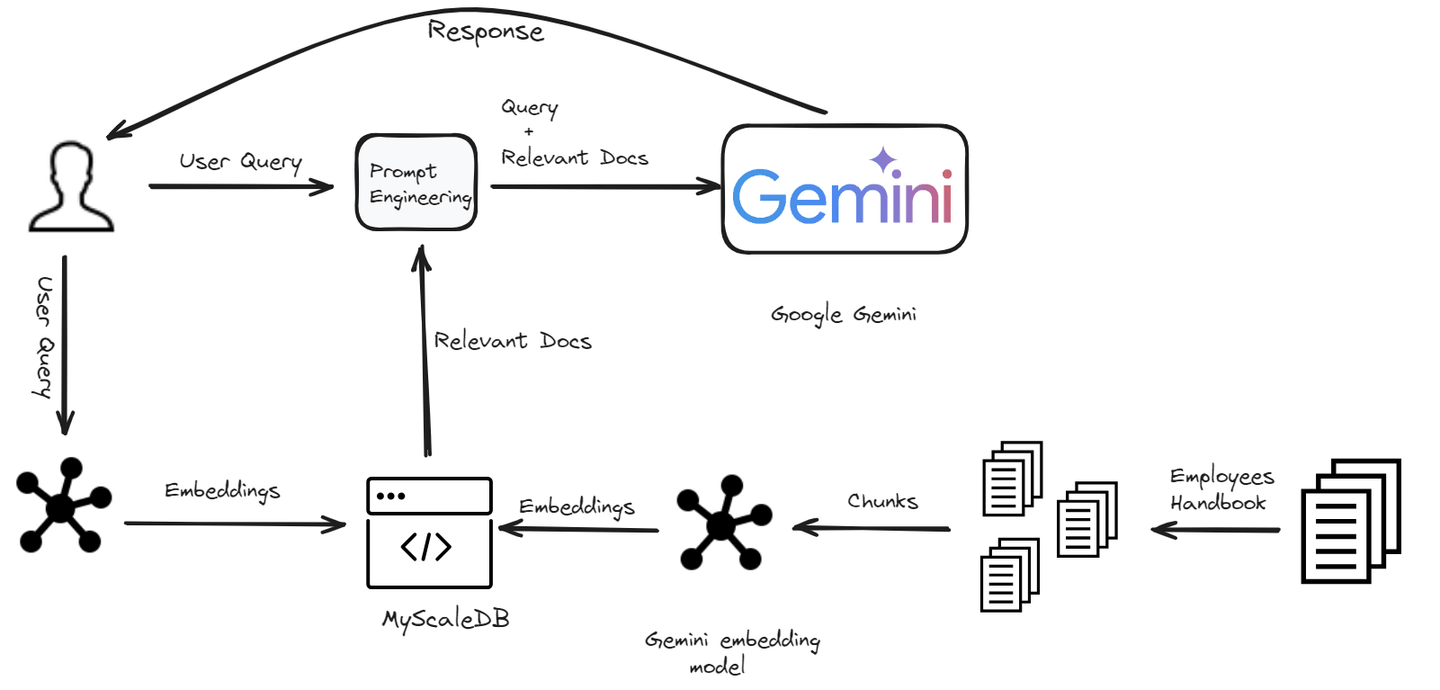
# 设置环境
# 安装必要的软件
为了开始我们的聊天机器人开发之旅,我们需要确保安装了所需的依赖项。以下是所需工具的详细信息:
Python (opens new window):我们将使用Python作为构建此聊天机器人的编程语言。
Gemini API (opens new window):我们将使用Gemini API来访问Gemini LLM并在我们的聊天机器人中使用它。
LangChain (opens new window):这是一个允许开发人员集成大型语言模型和向量数据库以构建可扩展的RAG应用程序的框架。
MyScaleDB (opens new window):这是一个专为构建AI应用程序而设计的SQL向量数据库。
# 安装Python
如果您的系统已经安装了Python,则可以跳过此步骤。否则,请按照以下步骤操作。
下载Python:转到官方Python网站 (opens new window)并下载最新版本。
安装Python:运行下载的安装程序并按照屏幕上的说明进行操作。确保选中将Python添加到系统路径的复选框。
# 安装Gemini、LangChain和MyScaleDB
要安装所有这些依赖项,请在终端中输入以下命令:
pip install gemini-api langchain clickhouse-client
上述命令应安装所有必需的软件包以开发聊天机器人。现在,让我们开始开发过程。
# 构建聊天机器人
我们正在构建一个专门为公司员工设计的聊天机器人。这个聊天机器人将帮助员工解答与公司政策相关的任何问题。从理解着装规定到澄清请假政策,聊天机器人将提供快速准确的答案。
# 加载和拆分文档
第一步是使用LangChain的PyPDFLoader模块加载数据并进行拆分。
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("Employee_Handbook.pdf")
pages = loader.load_and_split()
pages = pages[4:] # 跳过前几页,因为它们不需要
text = "\n".join([doc.page_content for doc in pages])
我们加载文档并将其拆分为页面,跳过前几页。然后将所有页面的文本连接成一个字符串。
注意:
我们使用了kaggle存储库 (opens new window)中的手册
接下来,我们将这个文本拆分成较小的块,以便在聊天机器人中更容易处理。
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=150,
length_function=len,
is_separator_regex=False,
)
docs = text_splitter.create_documents([text])
for i, d in enumerate(docs):
d.metadata = {"doc_id": i}
在这里,我们使用RecursiveCharacterTextSplitter将文本拆分为每个块500个字符,重叠150个字符以确保连续性。
# 生成嵌入向量
为了使我们的聊天机器人能够理解和检索相关信息,我们需要为每个文本块生成嵌入向量。这些嵌入向量是文本的数值表示,捕捉了文本的语义含义。
import os
import google.generativeai as genai
import pandas as pd
os.environ["GEMINI_API_KEY"] = "your_key_here"
# 此函数将句子作为参数,并返回其嵌入向量
def get_embeddings(text):
# 定义嵌入模型
model = 'models/embedding-001'
# 获取嵌入向量
embedding = genai.embed_content(model=model,
content=text,
task_type="retrieval_document")
return embedding['embedding']
# 从文档中获取page_content并创建一个新列表
content_list = [doc.page_content for doc in docs]
# 逐个发送page_content
embeddings = [get_embeddings(content) for content in content_list]
# 创建一个数据框以将其导入数据库
dataframe = pd.DataFrame({
'page_content': content_list,
'embeddings': embeddings
})
我们定义了一个函数get_embeddings,它使用Google Gemini为每个文本块生成嵌入向量。这些嵌入向量存储在DataFrame中以供进一步处理。
注意:
我们使用了Gemini模型中的embedding-001模型,您可以在这里获取Gemini API (opens new window)。
# 在MyScaleDB中存储数据
当我们准备好文本块及其对应的嵌入向量后,下一步是将这些数据存储在MyScaleDB中。这将使我们能够在以后执行高效的检索操作。让我们首先与MyScaleDB建立连接。
import clickhouse_connect
client = clickhouse_connect.get_client(
host='your_host_name',
port="port_number,
username='your_username',
password='yiur_password_hhere'
)
要获取MyScaleDB帐户的凭据,请按照快速入门指南 (opens new window)操作。
# 创建表并插入数据
在与数据库建立连接后,下一步是创建一个表(因为MyScaleDB是一个SQL向量数据库)并将数据插入其中。
# 创建名为'handbook'的表
client.command("""
CREATE TABLE default.handbook (
id Int64,
page_content String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 768
) ENGINE = MergeTree()
ORDER BY id
""")
# CONSTRAINT将确保每个嵌入向量的长度为768
# 批量插入数据
batch_size = 10
num_batches = len(dataframe) // batch_size
for i in range(num_batches):
start_idx = i * batch_size
end_idx = start_idx + batch_size
batch_data = dataframe[start_idx:end_idx]
# 插入数据
client.insert("default.handbook", batch_data.to_records(index=False).tolist(), column_names=batch_data.columns.tolist())
print(f"已插入第{i+1}/{num_batches}批数据。")
# 为快速检索数据创建向量索引
client.command("""
ALTER TABLE default.handbook
ADD VECTOR INDEX vector_index embeddings
TYPE MSTG
""")
数据以批量方式插入以提高效率,并添加了一个向量索引以实现快速相似性搜索。
# 检索相关文档
数据存储后,下一步是使用嵌入向量检索给定用户查询的最相关文档。
def get_relevant_docs(user_query):
# 再次调用get_embeddings函数将用户查询转换为向量嵌入
query_embeddings = get_embeddings(user_query)
# 进行查询
results = client.query(f"""
SELECT page_content,
distance(embeddings, {query_embeddings}) as dist FROM default.handbook ORDER BY dist LIMIT 3
""")
relevant_docs = []
for row in results.named_results():
relevant_docs.append(row['page_content'])
return relevant_docs
该函数首先为用户查询生成嵌入向量,然后根据其嵌入向量的相似性从数据库中检索出前3个最相关的文本块。
# 生成回复
最后,我们使用检索到的文档生成对用户查询的回复。
def make_rag_prompt(query, relevant_passage):
relevant_passage = ' '.join(relevant_passage)
prompt = (
f"您是一个乐于助人和富有信息的聊天机器人,使用下面的参考段落中的文本回答问题。"
f"以完整的句子回答,并确保您的回答易于理解。"
f"保持友好和对话的语气。如果段落与问题无关,请随意忽略。\n\n"
f"问题:'{query}'\n"
f"段落:'{relevant_passage}'\n\n"
f"回答:"
)
return prompt
import google.generativeai as genai
def generate_response(user_prompt):
model = genai.GenerativeModel('gemini-pro')
answer = model.generate_content(user_prompt)
return answer.text
def generate_answer(query):
relevant_text = get_relevant_docs(query)
text = " ".join(relevant_text)
prompt = make_rag_prompt(query, relevant_passage=relevant_text)
answer = generate_response(prompt)
return answer
answer = generate_answer(query="办公室的午餐时间是什么时候?")
print(answer)
make_rag_prompt函数使用相关文档创建聊天机器人的提示。generate_response函数使用Google Gemini根据提示生成回复,generate_answer函数将所有内容绑定在一起,检索相关文档并生成对用户查询的回复。
**注意:**在本博客中,我们使用了Gemini Pro 1.0 (opens new window),因为它在免费层中允许更多的请求。虽然Gemini提供了高级模型,如Gemini 1.5 Pro (opens new window)和Gemini 1.5 Flash (opens new window),但这些模型具有更严格的免费层和更高的使用成本。
聊天机器人的一些输出如下所示:

当被问及办公室的午餐时间时:

通过将这些步骤集成到聊天机器人开发过程中,您可以充分利用Google Gemini和MyScaleDB的强大功能,构建一个复杂的、基于AI的聊天机器人。关键是不断调整聊天机器人以提高其性能。保持好奇心,保持创新,观察您的聊天机器人如何演变成一个对话奇迹!

# 结论
RAG的出现通过集成Gemini或GPT等大型语言模型彻底改变了聊天机器人的开发过程。这些先进的LLM通过从向量数据库中检索相关信息,生成更准确、事实正确和上下文适当的回答,提高了聊天机器人的性能。这种转变不仅减少了开发时间和成本,还显著提高了用户体验,使聊天机器人更加智能和响应。
RAG模型的性能在很大程度上依赖于其向量数据库的效率。向量数据库快速检索相关文档的能力对于为用户提供快速响应至关重要。在扩展RAG系统时,保持这种高性能水平变得更加重要。MyScaleDB是这个目的的绝佳选择,因为它从ClickHouse继承了高可扩展性,并以最小的延迟提供闪电般快速的查询响应。您不能错过的是,它还为新用户提供了500万个免费的向量存储,可以轻松用于开发小规模应用程序。
如果您想与我们进一步讨论,欢迎加入MyScale的Discord (opens new window)分享您的想法和反馈。



