
在当今快节奏的 AI 时代,各种规模的企业都在积极探索将大型语言模型 (LLM) 融入日常运营。LLM 无论是在提升客户服务、自动化例行任务,还是打造个性化体验方面,都潜力巨大,带来显著效益。
然而,LLM 应用从概念到落地的过程往往困难重重,尤其是对缺乏深厚技术背景的用户而言,传统方法需要大量的编程知识,这成了许多人难以逾越的障碍。
Dify 应运而生,它是一个开发者友好的平台,致力于简化 LLM 与企业运营的集成,让非技术用户也能轻松驾驭 AI 的力量。本文将手把手地带大家使用 Dify 和 MyScale 开发一个检索增强生成 (RAG) (opens new window)应用程序,体验其便捷性。
# 什么是 Dify
Dify (opens new window) 是一个开源平台,开源的 LLM 应用开发平台。它的一大亮点是支持多种 LLM,用户可以根据自身需求选择最合适的模型。此外,Dify 提供从 Agent 构建到 AI workflow 编排、RAG 检索、模型管理等能力,极大助力轻松构建和运营生成式 AI 原生应用。
下图对 Dify 与其他流行平台(如 LangChain、Flowise 和 OpenAI Assistants API)进行了比较:
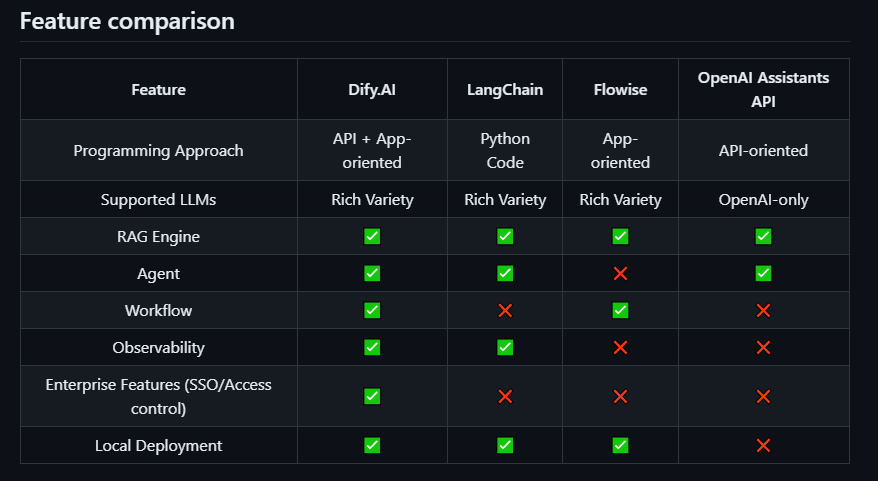
Dify 提供两种版本:基于 Web 的云平台版本(无需设置,任何人都可访问)和本地部署版本(适用于偏好于在自己的环境中进行自托管的用户)。
Dify 的本地部署版本允许用户在其自己的环境中部署平台,从而完全掌控数据和安全性。此版本非常适合希望在自己的基础架构上管理 AI 应用程序的企业或开发者。
本文将使用 Dify 的本地部署版本构建 RAG 应用程序。
# 下载 Dify
要设置 RAG 应用程序,首先需要下载 Dify 平台。用户可以使用以下命令从 GitHub 将 Dify repo (opens new window) 克隆到本地环境,以获得在本地机器上使用 Dify 所需的所有文件和配置:
git clone https://github.com/langgenius/dify.git
# 选择合适的向量数据库
RAG 应用程序的效率很大程度上取决于它响应用户查询时检索文档的速度和准确性。默认情况下,Dify 配置将 Weaviate 作为其向量数据库,在本文中,我们将使用 MyScaleDB。MyScaleDB 是一个基于 SQL 的向量数据库,在速度和准确性方面均表现出色,在各种基准测试 (opens new window)中均优于其他向量数据库。通过使用 MyScaleDB,我们可以确保 RAG 应用程序以最高的精度检索数据,从而优化整体用户体验。
# 如何在 Dify 中使用 MyScaleDB
Dify 同时支持开源版 MyScaleDB (opens new window) 和企业版 MyScale Cloud (opens new window)。如果你更喜欢使用开源版 MyScaleDB,则可以跳过此部分。
要开始使用 MyScale Cloud,请访问 MyScaleDB 注册页面 (opens new window)并创建一个新帐户。设置好帐户后,转到“集群”页面,点击右上角的“+ 新建集群”按钮创建一个新集群。
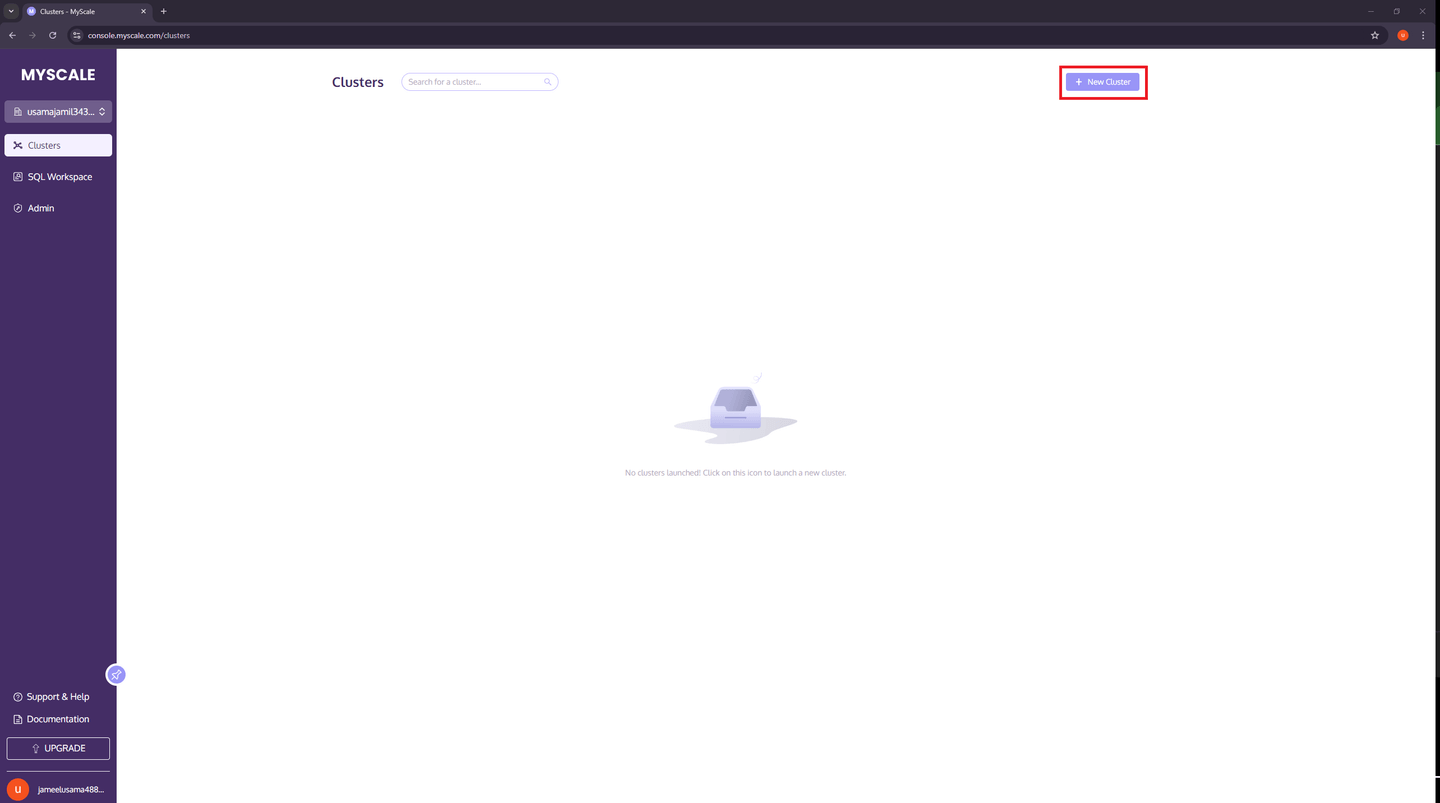
然后,输入集群名称,点击“下一步”按钮,等待集群启动完成。
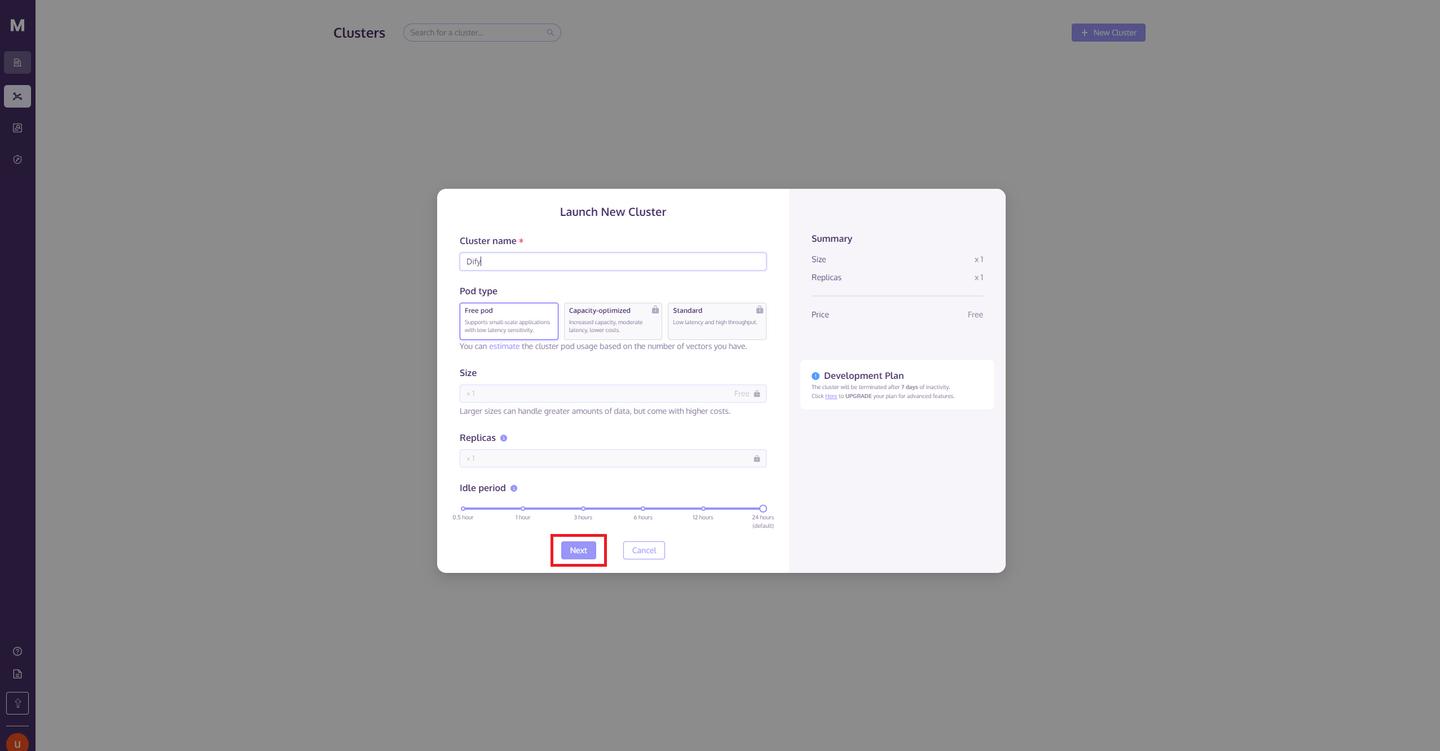
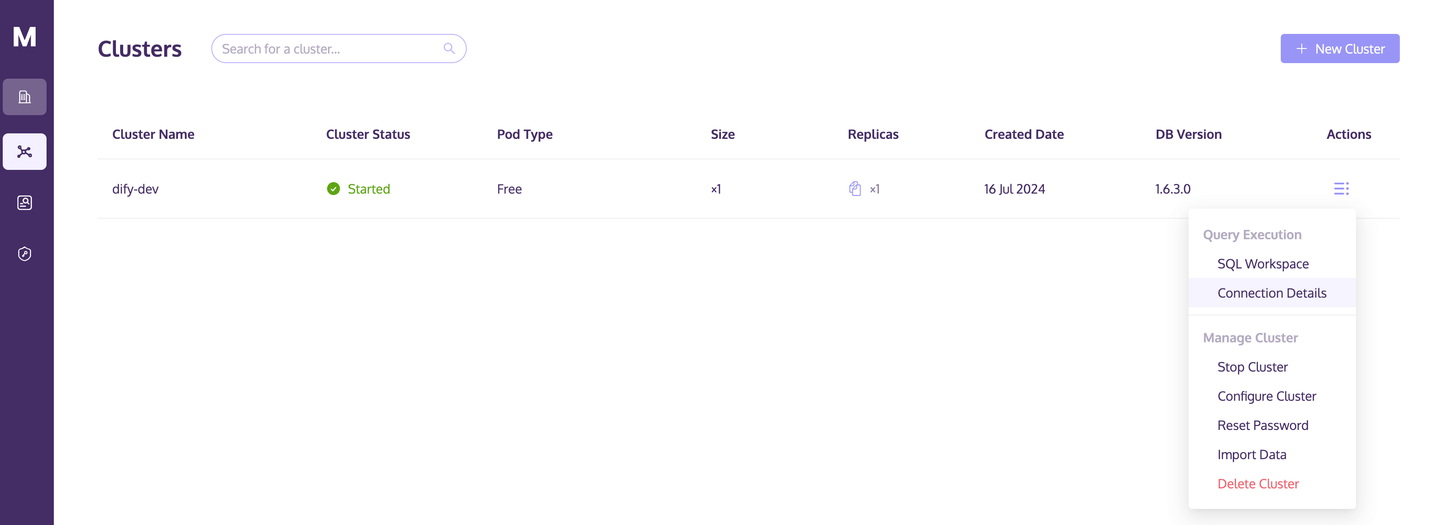
点击集群右侧的“操作”按钮,从弹出列表中选择“连接详情”。
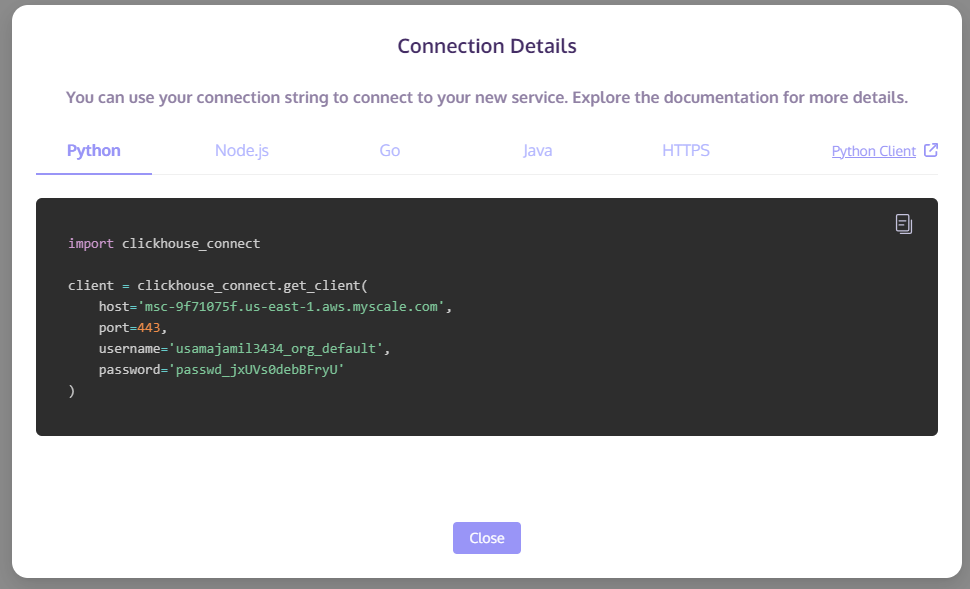
记录“Python”选项卡中的 host/port/username/password信息。这些信息将用于配置 Dify 对 MyScale 集群的访问。
# 将 MyScale 与 Dify 集成
要将 MyScale 与 Dify 集成,首先需要创建一个 .env 文件的副本。在终端中输入以下命令:
cd dockercp .env.example .env
这将在 Docker 存储库中生成一个新的 .env 文件。下一步是将从 MyScale 集群获取的详细信息输入到此文件中。 打开 .env 文件并执行以下步骤:
- 将
VECTOR_STORE设置为MyScale
VECTOR_STORE=MyScale
- 如果你使用的是 MyScale Cloud,请根据从 MyScale Cloud 网页获取的详细信息调整相关配置(可以保留
MYSCALE_DATABASE不变)。如果你使用的是开源版 MyScaleDB,则以下配置无需更改:
MYSCALE_HOST=your-hostname-hereMYSCALE_PORT=8443
MYSCALE_USER=your-username-hereMYSCALE_PASSWORD=your-password-hereMYSCALE_DATABASE=defaultMySCALE_FTS_PARAMS=
MyScaleDB 提供强大的全文搜索功能,可轻松搜索大型文本数据集。MYSCALE_FTS_PARAMS 变量允许你配置这些搜索参数,例如设置分词器和调整大小写敏感度,确保你的搜索针对特定需求进行了优化。
在本文中,我们将保持简单,使用默认的分词器。为此,你只需在 .env 文件中添加以下行:
MySCALE_FTS_PARAMS='{"text":{"tokenizer":{"type":"default"}}}'
注意: 如果需要支持多种语言(例如中文文档),请参阅 MyScale 官方文档 (opens new window)配置 MySCALE_FTS_PARAMS 参数。
- 完成这些修改后,按如下方式启动 Dify:
docker compose up -d
注意: 在输入上述命令之前,请确保你的系统已安装并运行 Docker。如果未安装 Docker,请从 Docker 官网 (opens new window)下载并安装。
上述命令将启动所需的服务(Docker Compose 将启动必要的应用程序)。一旦所有服务都处于“started”状态,请在浏览器中打开 http://localhost,即可开始使用 (opens new window) Dify。你将看到如下登录页面:
接下来,你需要设置一个管理员帐户并登录 Dify。登录后,你将被定向到主页。
至此,我们的 Dify 平台和 MyScaleDB 已顺利运行。现在,我们可以开始构建聊天机器人了。
# 使用 MyScale 和 Dify 构建聊天机器人
# 步骤 1:设置知识库
现在一切就绪,我们可以开始构建聊天机器人了。首先,我们需要一个知识库,供聊天机器人用来回答用户查询。点击“Knowledge”按钮,上传你想用作知识库的文件。
Dify 允许你整合来自各种来源的数据,例如与 Notion 或网站同步。
注意: 我们这次用到的知识库整合了两篇文章的内容:MyScaleDB vs. Zilliz (opens new window) 和 MyScale vs. Pinecone (opens new window)。
# 步骤 2:自定义知识库选项
上传文件后,你将看到几个自定义选项,包括调整 chunk 大小、选择 embedding 模型以及选择要应用的搜索类型。
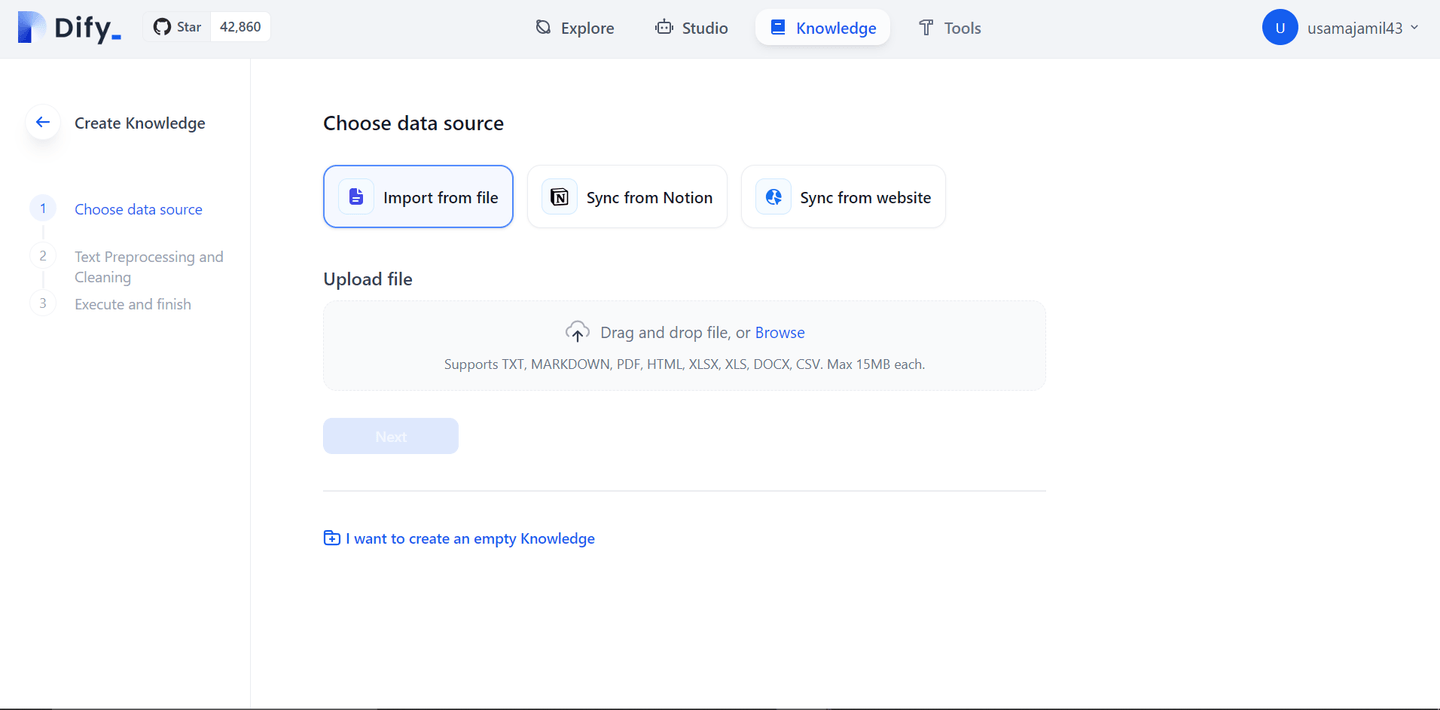
在这里我们将选择全文搜索以简化搜索查询,并可高效搜索文本数据。
注意: 我们将使用 OpenAI 的 embedding 模型 (opens new window)。要在你的环境中设置 OpenAI 密钥 (opens new window),请点击右上角的你的个人资料,进入“设置”,并为你想使用的平台配置密钥。
点击“保存并处理”按钮,系统将需要几秒钟时间来生成 embedding 并将数据存储在你的知识库(MyScaleDB)中。数据保存完成后,知识库就设置好了。
# 步骤 3:创建和配置聊天机器人
现在,我们准备从 Studio 中选择聊天机器人模板,并将知识库与之集成。
在 Studio 中,选择“Chatbot”,然后在“Create APP”菜单下点击“Create from Blank”。此时将弹出一个窗口,引导你完成后续步骤。
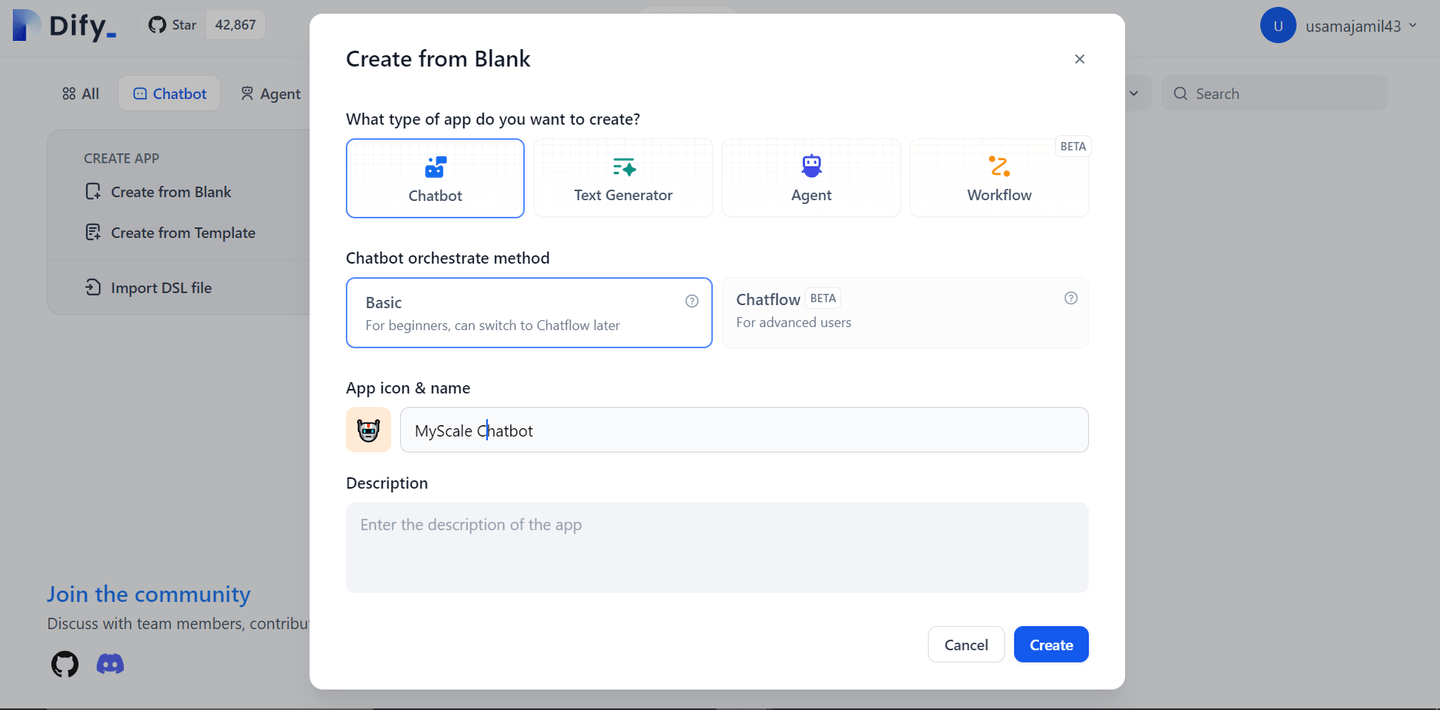
点击“创建”按钮后,你将进入一个新窗口,你可以在其中编写提示并添加你创建的知识库作为上下文。
# 步骤 4:将知识库添加到聊天机器人
在“Context”窗口中,点击“+添加”按钮,你将看到已添加到知识库中的所有文件的列表。选择你希望聊天机器人使用的文件,然后点击“添加”按钮。这样一来,你的聊天机器人就有了正确的上下文,可以提供准确的响应。
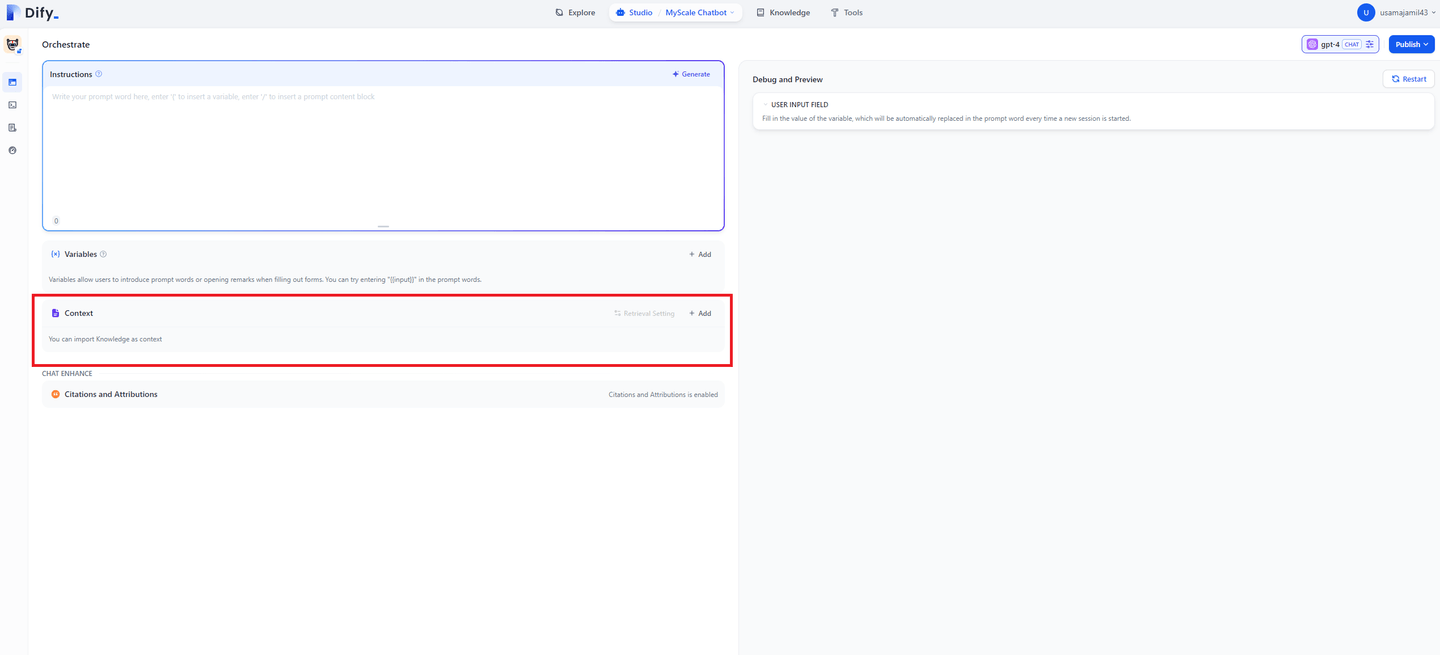
同样,你可以在“Instructions”框中为聊天机器人提供具体的指令。
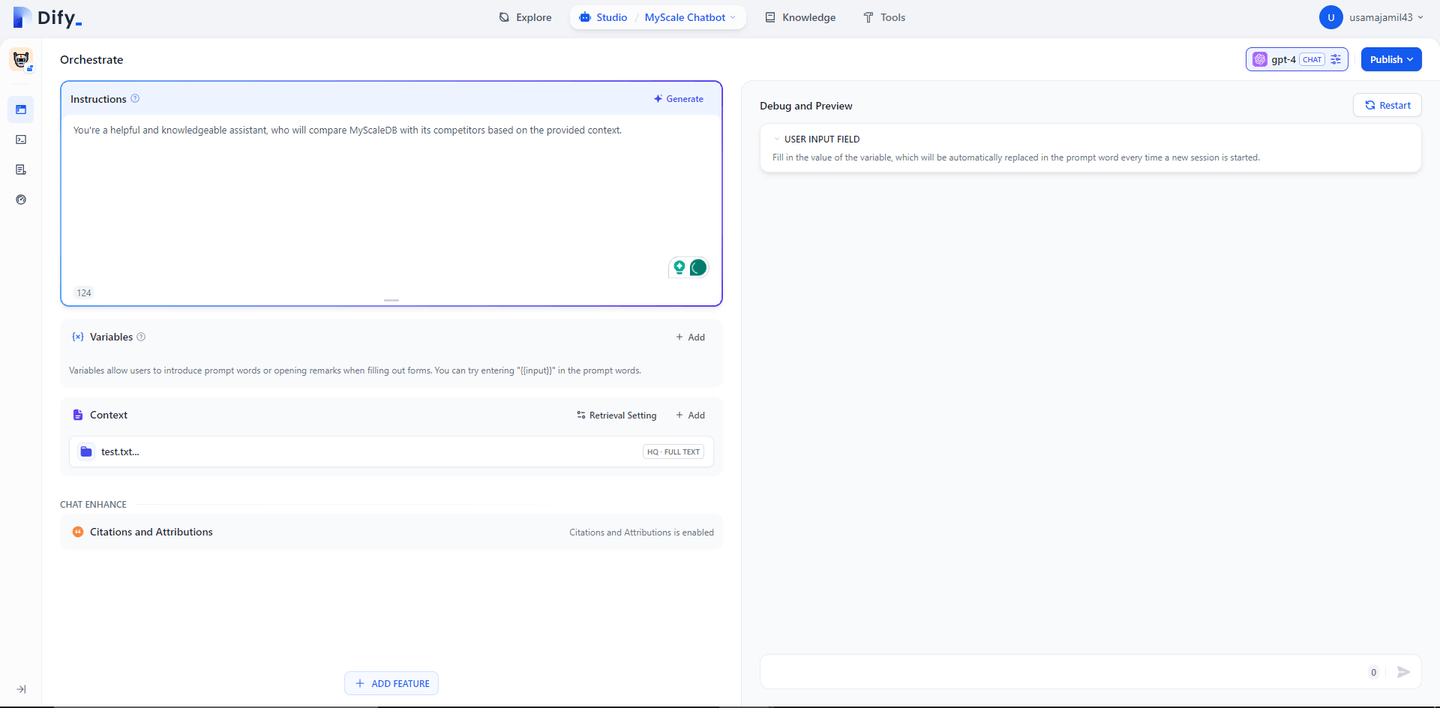
# 步骤 5:发布和部署你的聊天机器人
到此,我们的聊天机器人已准备就绪,最后就是发布这个聊天机器人。点击右上角的“Publish”按钮,你将看到如下菜单:
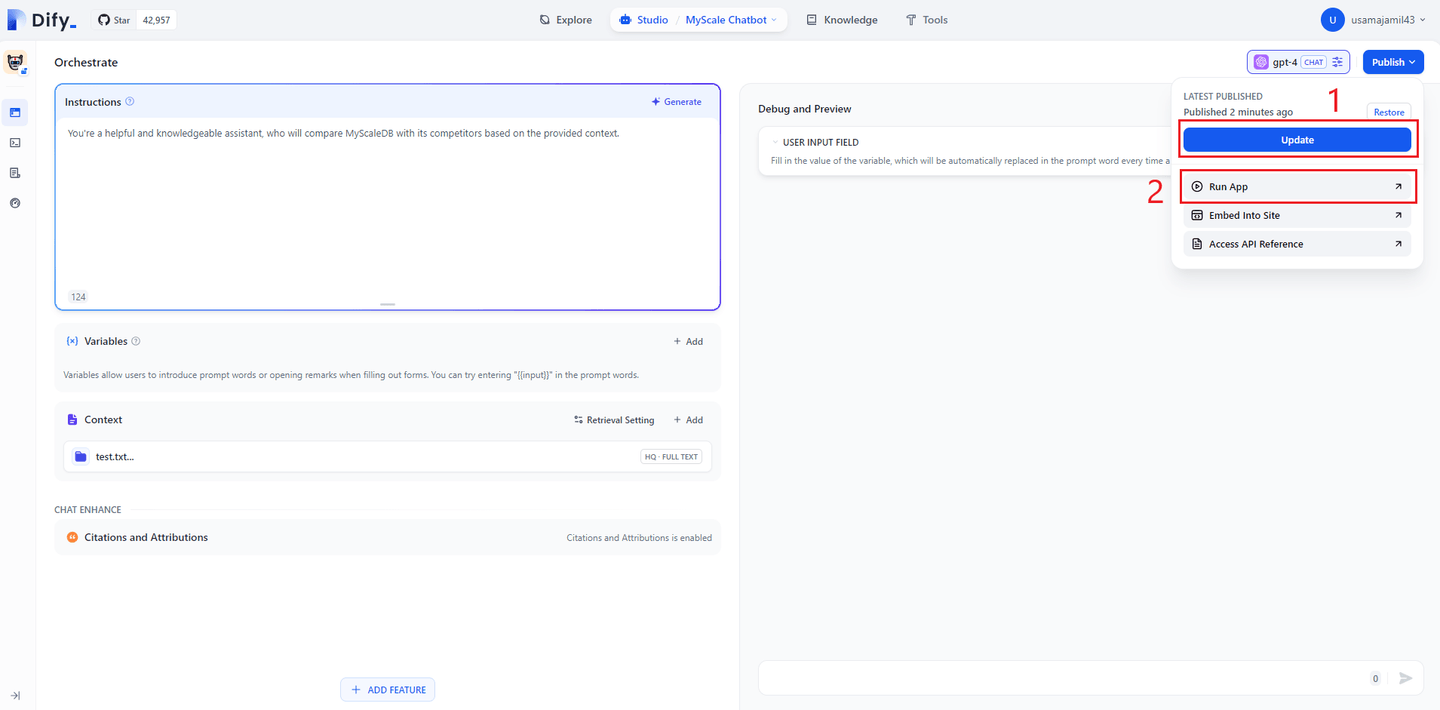
点击“更新”按钮保存你对聊天机器人所做的所有更改。然后,点击“运行应用”按钮,一个新的聊天窗口就会打开。
注意: 聊天机器人准备就绪后,Dify 允许你使用 iframe 将其轻松嵌入到任何地方。只需选择“Embed into website”选项并复制 iframe 代码即可。这使你可以将聊天机器人无缝集成到你的网站或应用程序中。
点击“开始聊天”,你就可以开始使用你的聊天机器人了。
现在我们已经使用 Dify 和 MyScaleDB 构建了一个聊天机器人,它结合了易用性和强大的搜索功能。Dify 和 MyScaleDB 的结合为创建满足需求的 AI 驱动应用程序奠定了坚实的基础。

# 总结
Dify (opens new window) 是一个创新的开源平台,旨在让每个人都能轻松使用 AI 开发。它提供了一套全面的工具集,包括可视化提示编排和简单的集成选项,让用户无需深入掌握技术就能创建强大的 AI 应用程序。Dify 的重点是消除传统的 AI 开发障碍,从而快速高效地部署复杂的 AI 解决方案。
MyScaleDB 作为一款可靠的 SQL 向量数据库,可以与 Dify 互作完美辅助,高效地处理大规模数据。MyScaleDB 对 SQL 的完全兼容和强大的搜索功能使其成为需要有效管理海量向量及结构化数据的 AI 应用程序的理想选择。MyScaleDB 的 AI 解决方案既具备可扩展性又提供了高性能,与 Dify 这样用户友好的工具相辅相成。
此外,MyScaleDB 为新用户提供的免费 development tier,可以存储多达 500 万个 768 维向量,如果你想要探索和构建 AI 应用程序而又想降低初期成本,可以免费体验。
想与我们进一步讨论构建 RAG/GenAI 应用程序吗?欢迎通过 Discord (opens new window) 联系我们。



