
检索增强生成(RAG) (opens new window)经常用于开发定制的人工智能应用程序,包括聊天机器人 (opens new window)、推荐系统 (opens new window)和其他个性化工具。该系统利用向量数据库和大型语言模型(LLMs)的优势提供高质量的结果。
选择适合任何RAG模型的正确LLM非常重要,需要考虑成本、隐私问题和可扩展性等因素。商业LLMs如OpenAI的GPT-4 (opens new window)和Google的Gemini (opens new window)非常有效,但可能昂贵并引发数据隐私问题。一些用户更喜欢开源LLMs (opens new window),因为它们具有灵活性和成本节省的优势,但它们需要大量资源进行微调 (opens new window)和部署,包括GPU和专用基础设施。此外,使用本地设置管理模型更新和可扩展性可能具有挑战性。
更好的解决方案是选择一个开源LLM并将其部署在云上。这种方法提供了必要的计算能力和可扩展性,而无需承担本地托管的高成本和复杂性。它不仅节省了初始基础设施成本,还减少了维护方面的担忧。
让我们探索一种类似的方法,使用云托管的开源LLMs和可扩展的向量数据库来开发一个应用程序。
# 工具和技术
开发这个基于RAG的人工智能应用程序需要几个工具,包括:
- BentoML (opens new window):BentoML是一个开源平台,简化了将机器学习模型部署为生产就绪API的过程,确保可扩展性和易管理性。
- LangChain (opens new window):LangChain是一个使用LLMs构建应用程序的框架。它提供了易于集成和定制的模块化组件。
- MyScaleDB (opens new window):MyScaleDB是一个高性能、可扩展的数据库,针对高效的数据检索和存储进行了优化,支持高级查询功能。
在本教程中,我们将使用LangChain的WikipediaLoader模块从维基百科提取数据,并在此数据上构建一个LLM。
注意:
您可以在MyScale示例存储库上找到完整的Python笔记本 (opens new window)。
# 准备工作
# 设置环境
通过打开终端并输入以下命令,开始设置您的环境以在系统中使用BentoML、MyScaleDB和LangChain:
pip install bentoml langchain clickhouse-connect
这将在您的系统中安装这三个软件包。安装完成后,您就可以编写代码并开发RAG应用程序了。
# 加载数据
首先,从langchain_community.document_loaders.wikipedia模块中导入WikipediaLoader (opens new window)。您将使用这个加载器来获取与"阿尔伯特·爱因斯坦"相关的维基百科 (opens new window)文档。
from langchain_community.document_loaders.wikipedia import WikipediaLoader
loader = WikipediaLoader(query="Albert Einstein")
# 加载文档
docs = loader.load()
# 显示第一个文档的内容
print(docs[0].page_content)
这里使用load方法来检索“阿尔伯特·爱因斯坦”文档,并使用print方法打印第一个文档的内容以验证加载的数据。
# 将文本拆分为块
从langchain_text_splitters导入CharacterTextSplitter (opens new window),将所有页面的内容连接成一个字符串,然后将文本拆分为可管理的块。
from langchain_text_splitters import CharacterTextSplitter
# 将文本拆分为块
text = ' '.join([page.page_content.replace('\\t', ' ') for page in docs])
text_splitter = CharacterTextSplitter(
separator="\\n",
chunk_size=400,
chunk_overlap=100,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.create_documents([text])
splits = [item.page_content for item in texts]
CharacterTextSplitter被配置为将文本拆分为400个字符的块,重叠100个字符,以确保在块之间不丢失任何信息。page_content或文本存储在splits数组中,该数组仅包含文本内容。您将使用splits数组来获取嵌入 (opens new window)。
# 在BentoML上部署模型
数据准备完毕,下一步是在BentoML上部署模型,并在RAG (opens new window)应用程序中使用它们。首先部署LLM。您需要一个免费的BentoML帐户,如果需要,可以在BentoCloud (opens new window)上注册一个。接下来,转到部署部分,并单击右上角的“创建部署”按钮。将打开一个新页面,看起来像这样:
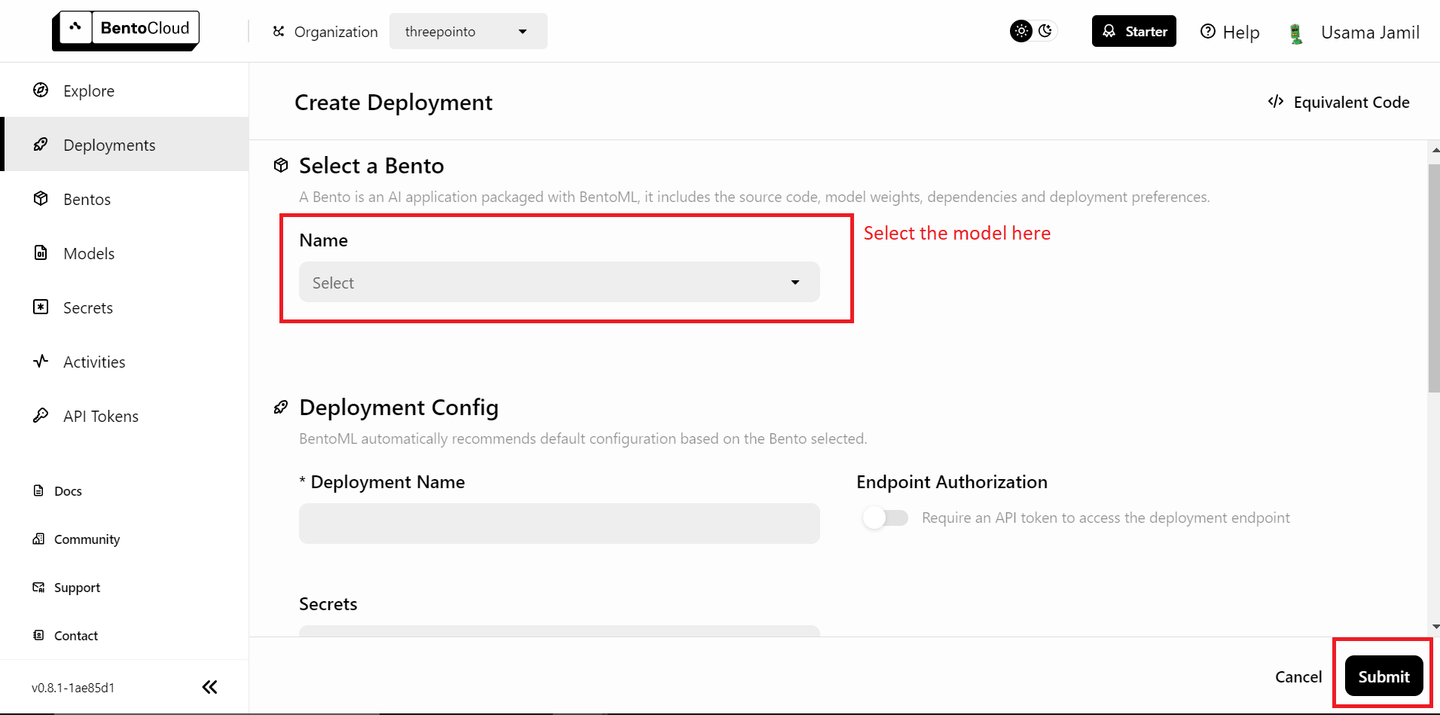
从下拉列表中选择"bentoml/bentovllm-llama3-8b-instruct-service (opens new window)"模型,然后点击右下角的"提交"按钮。这将开始部署模型。将打开一个类似于下面的新页面:
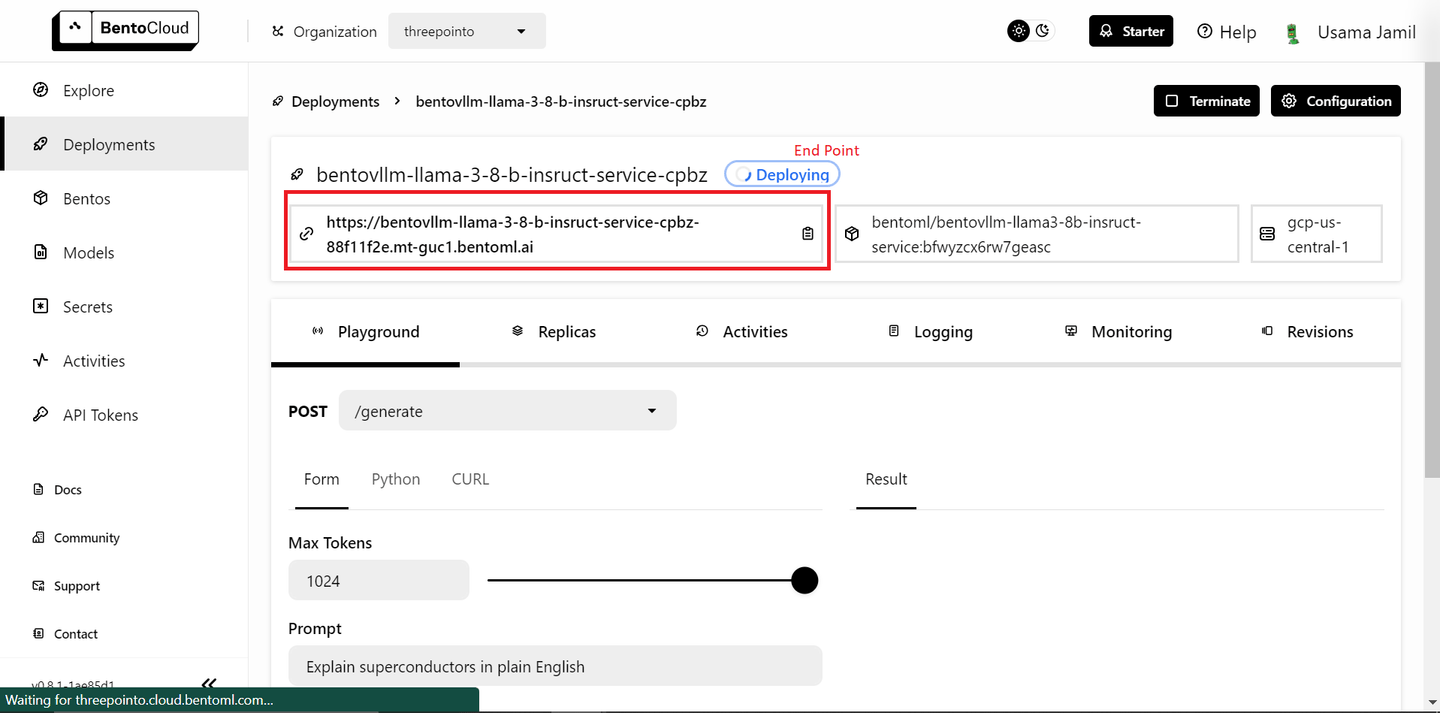
部署可能需要一些时间。部署完成后,复制端点。
注意:
BentoML的免费版只允许部署一个模型。如果您有付费计划并且可以部署多个模型,请按照下面的步骤操作。如果没有,不用担心——我们将在本地使用一个开源模型进行嵌入。
部署嵌入模型与部署LLM的步骤非常相似:
- 转到部署页面。
- 点击"创建部署"按钮。
- 从列表中选择
sentence-transformers模型,然后点击"提交"。 - 部署完成后,复制端点。
接下来,转到API令牌页面 (opens new window)并生成一个新的API密钥。现在,您可以在RAG应用程序中使用部署的模型了。
# 定义嵌入方法
您将定义一个名为get_embeddings的函数,用于为提供的文本生成嵌入。该函数接受三个参数。如果提供了BentoML端点和API令牌,函数将使用BentoML的嵌入服务;否则,它将使用本地的transformers和torch库加载sentence-transformers/all-MiniLM-L6-v2模型并生成嵌入。
# 导入库
import subprocess
import sys
import numpy as np
# 如果未提供API密钥,则安装软件包
def install(package):
subprocess.check_call([sys.executable, "-m", "pip", "install", package])
# 定义嵌入方法
def get_embeddings(texts: list, BENTO_EMBEDDING_MODEL_END_POINT=None, BENTO_API_TOKEN=None) -> list:
# 如果提供了BentoML密钥,则该方法将使用BENTOML模型获取嵌入
if BENTO_EMBEDDING_MODEL_END_POINT and BENTO_API_TOKEN:
import bentoml
embedding_client = bentoml.SyncHTTPClient(BENTO_EMBEDDING_MODEL_END_POINT, token=BENTO_API_TOKEN)
return embedding_client.encode(sentences=texts).tolist()
# 否则将使用transformers库
else:
# 如果尚未安装transformers和torch,则安装它们
try:
import transformers
except ImportError:
install("transformers")
try:
import torch
except ImportError:
install("torch")
from transformers import AutoTokenizer, AutoModel
# 初始化用于嵌入的tokenizer和model
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt", max_length=512)
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1)
return embeddings.numpy().tolist()
这个设置允许免费版BentoML用户灵活地部署一个模型。如果您有付费版本的BentoML并且可以部署两个模型,您可以传递BentoML端点和Bento API令牌以使用部署的嵌入模型。
# 获取嵌入
使用上面定义的get_embeddings函数,对文本块(splits)进行批处理,每批处理25个块,生成嵌入。
all_embeddings = []
# 每次处理25个块
for i in range(0, len(splits), 25):
batch = splits[i:i+25]
# 将批处理传递给get_embeddings方法
embeddings_batch = get_embeddings(batch)
# 将嵌入追加到保存整个数据集嵌入的all_embeddings列表中
all_embeddings.extend(embeddings_batch)
这样可以防止一次向嵌入模型传递过多数据,特别是对于管理内存和计算资源非常有用。
# 创建DataFrame
现在,创建一个pandas (opens new window) DataFrame来存储文本块及其对应的嵌入。
import pandas as pd
df = pd.DataFrame({
'page_content': splits,
'embeddings': all_embeddings
})
这种结构化格式使得更容易操作和存储数据到MyScaleDB中。
# 连接到MyScaleDB
知识库已经完成,现在是时候将数据保存到向量数据库中了。本演示使用MyScaleDB进行向量存储。按照快速入门指南 (opens new window)在云环境中启动一个MyScaleDB集群,然后使用clickhouse_connect库建立与MyScaleDB数据库的连接。
import clickhouse_connect
client = clickhouse_connect.get_client(
host='your-host-name',
port=443,
username='your-user-name',
password='your-password'
)
在这里创建的client对象将用于执行SQL命令和与数据库交互。
# 创建表并插入数据
在MyScaleDB中创建一个表来存储文本块和嵌入。表的模式包括一个id、page_content和embeddings。
# 创建名为RAG的表
client.command("""
CREATE TABLE IF NOT EXISTS default.RAG (
id Int64,
page_content String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 384
) ENGINE = MergeTree()
ORDER BY id
""")
# 将数据插入表中
batch_size = 100
num_batches = (len(df) + batch_size - 1) // batch_size
for i in range(num_batches):
batch_data = df[i * batch_size: (i + 1) * batch_size]
client.insert('default.RAG', batch_data.values.tolist(), column_names=batch_data.columns.tolist())
print(f"已插入第{i+1}/{num_batches}批数据。")
这样可以确保嵌入具有固定的长度384。然后将DataFrame中的数据以批处理的方式插入表中,以有效地管理大量数据。
# 创建向量索引
下一步是在RAG表的embeddings列中添加一个向量索引。向量索引允许进行高效的相似性搜索,这对于检索增强生成任务非常重要。
client.command("""
ALTER TABLE default.RAG
ADD VECTOR INDEX vector_index embeddings
TYPE MSTG
""")
# 检索相关向量
定义一个函数,根据用户查询检索相关文档。使用get_embeddings函数生成查询嵌入,并执行高级SQL向量查询,以在数据库中找到最接近的匹配项。
def get_relevant_docs(user_query, top_k):
query_embeddings = get_embeddings(user_query)[0]
results = client.query(f"""
SELECT page_content,
distance(embeddings, {query_embeddings}) as dist FROM default.RAG ORDER BY dist LIMIT {top_k}
""")
relevant_docs = " "
for row in results.named_results():
relevant_docs=relevant_docs + row["page_content"]
return relevant_docs
# 示例查询
message="阿尔伯特·爱因斯坦是谁?"
relevant_docs = get_relevant_docs(message, 8)
print(relevant_docs)
结果按距离排序,并返回前k个匹配项。这个设置可以找到给定查询的最相关文档。
注意:
distance方法接受一个嵌入列和用户查询的嵌入向量,通过应用余弦相似度找到相似的文档。
# 连接到BentoML LLM
与托管的BentoML LLM建立连接。llm_client对象将用于与LLM进行交互,根据检索到的文档生成响应。
import bentoml
BENTO_LLM_END_POINT = "在这里添加您的端点"
llm_client = bentoml.SyncHTTPClient(BENTO_LLM_END_POINT, token="在这里添加您的令牌")
将BENTO_LLM_END_POINT和token替换为您在LLM部署期间复制的值。
# 执行RAG
定义一个执行RAG的函数。该函数接受用户问题和检索到的上下文作为输入。它构建一个用于LLM的提示,指示它根据提供的上下文回答问题。然后返回LLM的响应作为答案。
def dorag(question: str, context: str):
# 定义提示模板
prompt = (f"您是一个乐于助人的助手。用户有一个问题。根据上下文回答用户的问题:{context}。\\n"
f"用户的问题是{question}")
# 调用LLM端点,使用上面定义的提示
results = llm_client.generate(
max_tokens=1024,
prompt=prompt,
)
res = ""
for result in results:
res += result
return res

# 发起查询
最后,您可以通过向RAG应用程序发起查询来进行测试。询问问题"阿尔伯特·爱因斯坦是谁?",并使用dorag函数根据之前检索到的相关文档获取答案。
query = "阿尔伯特·爱因斯坦是谁?"
dorag(question=query, context=relevant_docs)
输出将提供对问题的详细回答,展示了RAG设置的有效性。

如果向RAG模型询问关于阿尔伯特·爱因斯坦的死亡,响应应该如下所示:

# 结论
BentoML是一个出色的机器学习模型部署平台,包括LLMs,无需管理资源的麻烦。使用BentoML,您可以快速在云上部署和扩展您的人工智能应用程序,确保它们准备投入生产并且易于访问。其简单性和灵活性使其成为开发人员的理想选择,使他们能够更多地关注创新,而不是部署复杂性。
另一方面,MyScaleDB专门为RAG应用程序开发,提供了一个高性能的SQL向量数据库。它熟悉的SQL语法使开发人员能够轻松集成和使用MyScaleDB在他们的应用程序中,因为学习曲线很小。MyScaleDB的多尺度树图(MSTG) (opens new window)算法在速度和准确性方面明显优于其他向量数据库。此外,对于新用户,MyScaleDB包括对500万个768D向量的存储访问,使其成为寻求实现高效可扩展的人工智能解决方案的开发人员的理想选择。
您对这个项目有什么看法?在Twitter (opens new window)和Discord (opens new window)上分享您的想法。



