
大型语言模型(LLM)以其理解和生成类似人类的文本的能力带来了巨大的价值。然而,这些模型也面临着显著的挑战。它们是在需要大量成本和时间的庞大数据集上进行训练的。在大规模数据集上训练这些模型所需的巨大成本和时间几乎不可能定期重新训练它们。这个限制意味着它们经常缺乏最新数据的更新,导致在查询不熟悉的主题时可能出现不准确的情况。这种现象被称为“幻觉”,它可能会降低应用程序的性能,并引发对其可靠性和真实性的担忧。
为了克服幻觉,采用了几种技术,其中检索增强生成(RAG)是最常用的,因为它具有高效和高性能 (opens new window)。
我将展示如何设计一个完整的高级RAG系统,可用于生产环境。
# 什么是检索增强生成
RAG是克服幻觉最常用的技术。它确保LLM始终与最新信息保持同步,并提供更好的响应。它在模型的响应生成阶段动态检索相关的外部数据。这种方法使LLM能够在不需要频繁重新训练的情况下访问最新信息。它使模型的响应更准确和上下文适应。
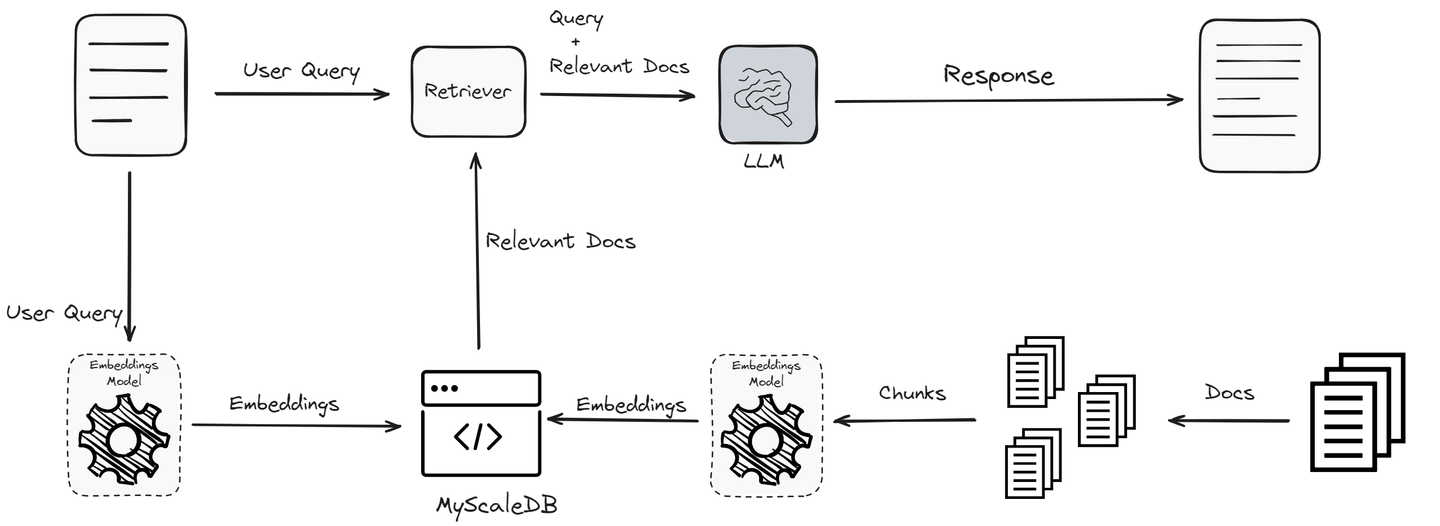
该过程始于用户查询,通过嵌入模型将其转换为嵌入,以捕捉其语义要义。然后,这些嵌入将通过与知识库或向量数据库中的向量进行相似性搜索,以识别最相关的信息。此搜索的前K个结果将作为附加上下文集成到LLM中。
通过处理原始查询和此附加数据,LLM能够生成更准确和上下文相关的响应。这不仅可以缓解幻觉问题,还可以确保模型的输出保持最新和可靠,而无需频繁重新训练。
相关文章:RAG如何工作 (opens new window)
# 什么是LlamaIndex
LlamaIndex (opens new window),以前称为GPT Index,就像胶水一样,帮助您连接LLM和知识库。它提供了一些内置方法,可以从不同的来源获取数据,并在您的RAG应用程序中使用。这包括各种文件格式,如PDF和PowerPoint,以及应用程序,如Notion和Slack,甚至数据库,如Postgres和MyScaleDB。
LlamaIndex提供了一些重要的工具,可以帮助您收集、组织、检索和集成各种应用程序框架的数据。它使您的数据更易于访问和使用,使您能够构建功能强大、定制化的LLM应用程序和工作流程。
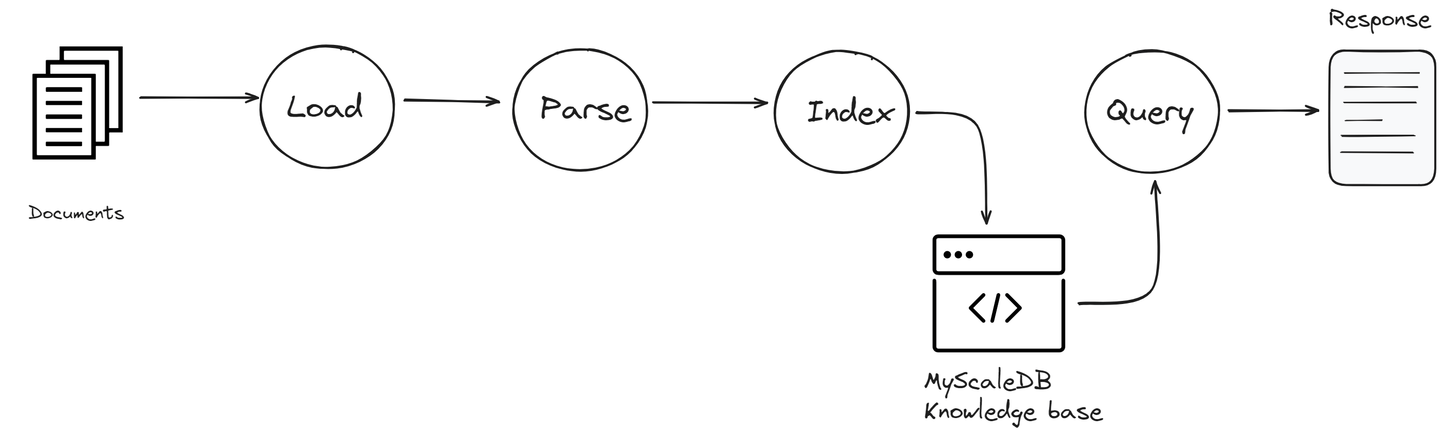
LlamaIndex的主要组成部分包括:
- 数据连接器:这些连接器允许LlamaIndex访问各种数据源。无论是连接到本地文件系统、云存储服务还是数据库,这些连接器都有助于检索所需的信息。
- 索引:LlamaIndex中的索引是一个关键组件,它以便于快速访问的方式组织数据。它将来自所有连接源的信息按照结构化格式进行分类,易于搜索。这有助于加快检索过程,并确保在需要时提供最相关的信息供LLM使用。
- 查询引擎:该组件旨在高效地搜索连接的数据源。它处理您的查询,找到相关信息并检索出来,以便LLM在生成响应时使用。
LlamaIndex的每个组件都在通过确保它们可以高效地访问和使用各种数据的能力方面发挥着关键作用,从而增强了RAG应用程序的功能。
# MyScaleDB概述
MyScaleDB (opens new window)是一个开源的SQL向量数据库,专为管理用于AI应用程序的大量数据而设计和优化。它建立在SQL数据库ClickHouse之上,将向量相似性搜索的能力与完整的SQL支持相结合。
与专门的向量数据库不同,MyScaleDB将向量搜索算法与结构化数据库无缝集成,允许向量和结构化数据一起在同一个数据库中进行管理。这种集成提供了简化的通信、灵活的元数据过滤、支持SQL和向量联合查询 (opens new window)以及与通常用于通用多用途数据库的已建立工具的兼容性等优势。
将MyScaleDB集成到RAG应用程序中,通过实现更复杂的数据交互,直接影响生成内容的质量。
# 使用LlamaIndex和MyScaleDB的RAG:逐步指南
要构建RAG应用程序,首先需要在MyScaleDB上创建一个帐户 (opens new window),该帐户将用作知识库。MyScaleDB为每个新用户提供了高达500万个向量的免费存储空间,因此不需要初始付款。
创建完帐户后,转到主页,然后点击右上角的“+新建集群”。这将打开一个对话框,如下所示:
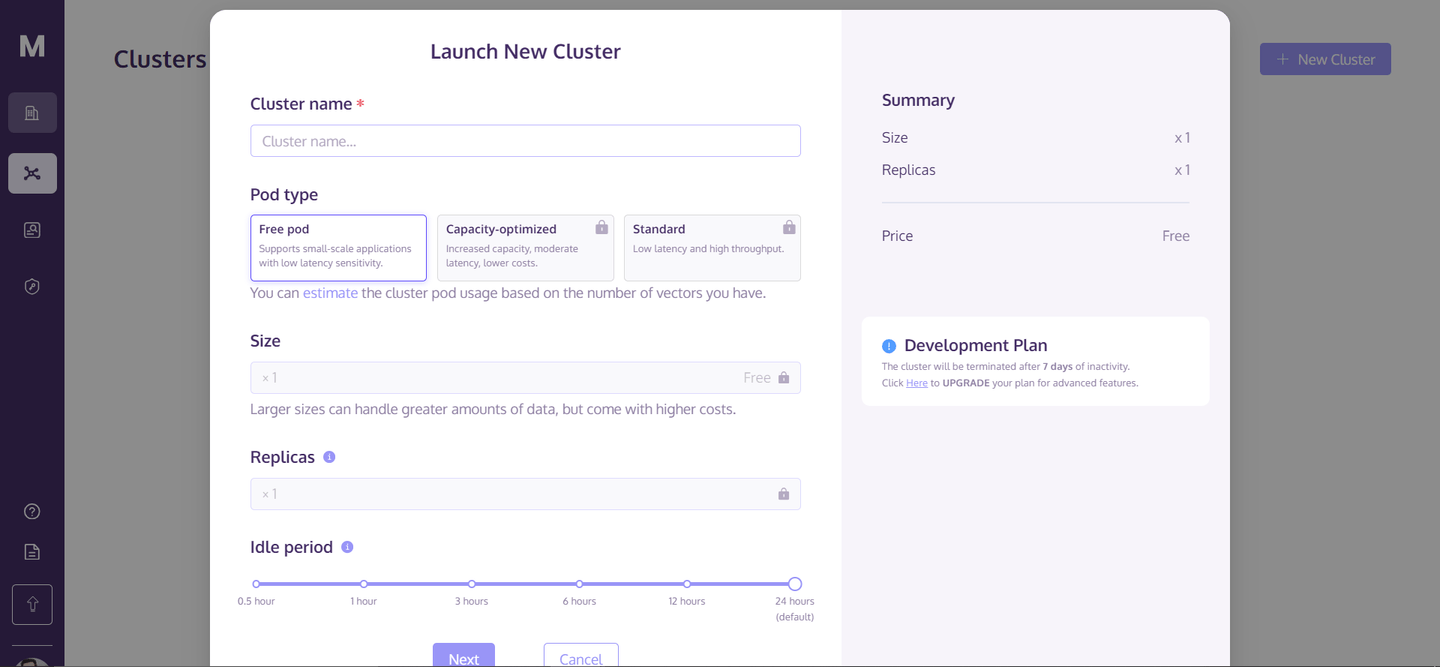
输入集群的名称,然后点击“下一步”。它将花费几秒钟来初始化您的集群,之后您可以访问它。
要访问集群,您可以返回到MyScaleDB个人资料,将鼠标悬停在“操作”文本下方的三个垂直对齐的点上,然后点击连接详细信息。
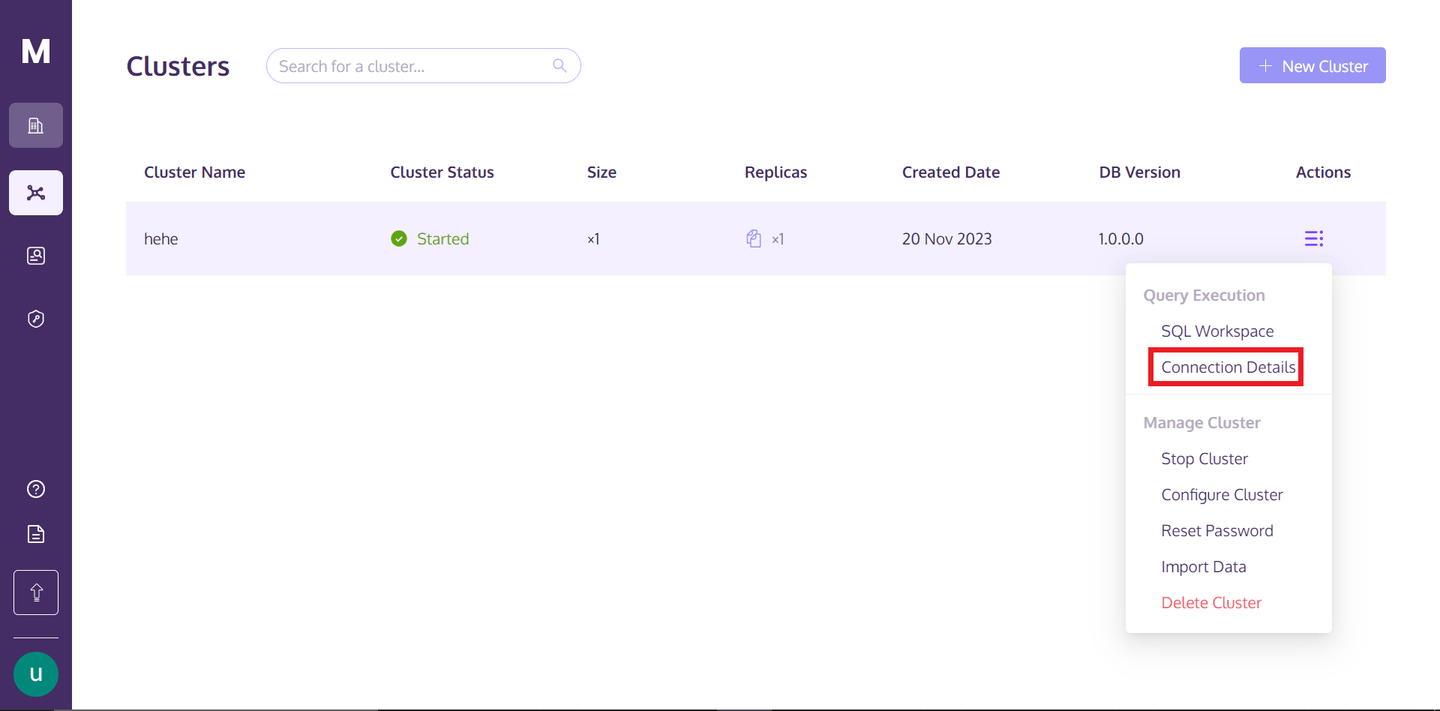
点击“连接详细信息”后,您将看到以下框:
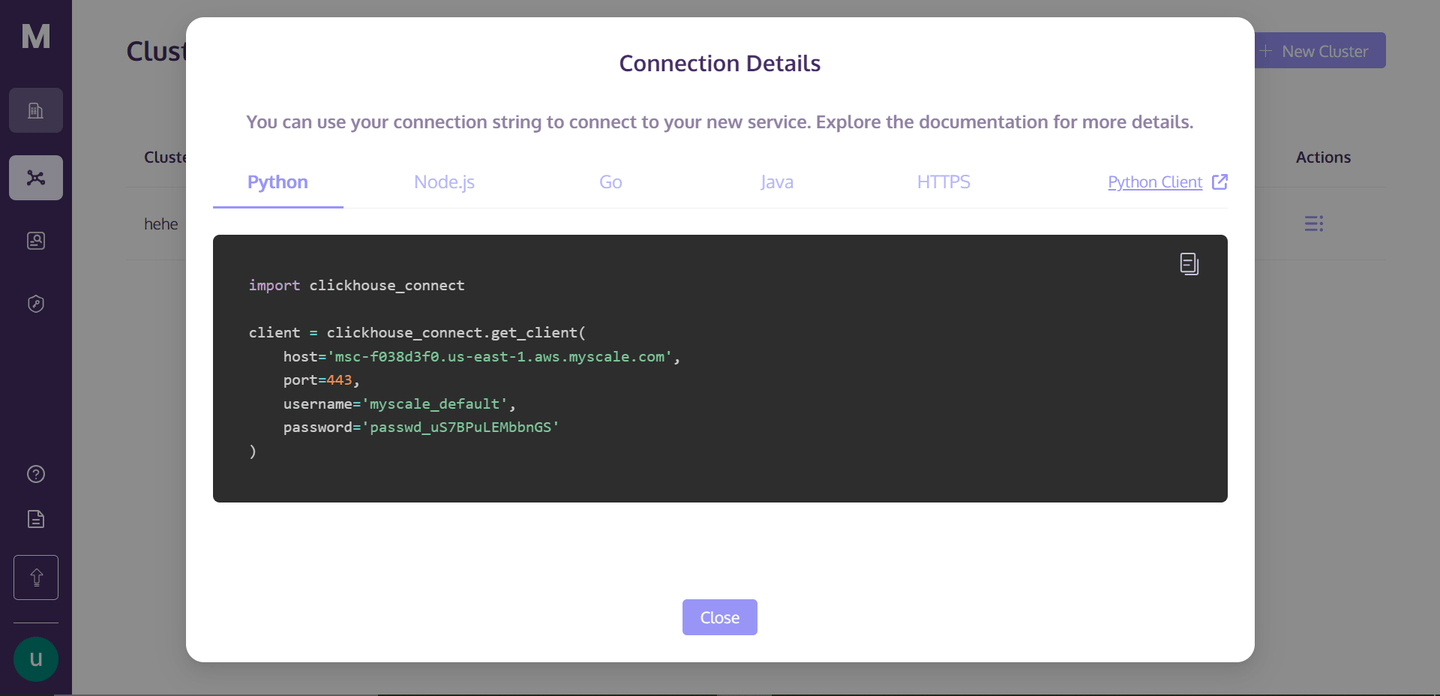
这些是您连接到集群所需的连接详细信息。只需在您的目录中创建一个Python笔记本文件,我们将开始构建我们的RAG应用程序。

# 设置环境
要安装依赖项,请打开终端并输入以下命令:
pip install -U llama-index clickhouse-connect llama-index-postprocessor-jinaai-rerank llama-index-vector-stores-myscale
此命令将安装所有所需的依赖项。在这里,我们使用Jina Reranker (opens new window),其算法显著改善了搜索结果,命中率提高了8%以上,平均倒数排名提高了33%。
# 与知识库建立连接
首先,您需要与MyScale向量数据库建立连接。为此,您可以从“连接详细信息”页面复制详细信息,然后像这样粘贴:
import clickhouse_connect
client = clickhouse_connect.get_client(
host='your-host',
port=443,
username='your-user-name',
password='your-password-here'
)
它将与您的知识库建立连接并创建一个对象。
# 下载和加载数据
在这里,我们将使用一个Nike产品目录数据集。此代码将首先下载.pdf文件并将其保存在本地。然后,它将使用LlamaIndex reader加载.pdf文件。
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
import requests
url = '<https://niketeam-asset-download.nike.net/catalogs/2024/2024_Nike%20Kids_02_09_24.pdf?cb=09302022>'
response = requests.get(url)
with open('Nike_Catalog.pdf', 'wb') as f:
f.write(response.content)
reader = SimpleDirectoryReader(
input_files=["Nike_Catalog.pdf"]
)
documents = reader.load_data()
# 对数据进行分类
此函数将文档分类为不同的类别。我们将在整个知识库上编写一些过滤查询时使用它。通过对文档进行分类,可以执行有针对性的搜索,显著提高RAG系统中检索的效率和相关性。
def analyze_and_assign_category(text):
if "football" in text.lower():
return "足球"
elif "basketball" in text.lower():
return "篮球"
elif "running" in text.lower():
return "跑步"
else:
return "未分类"
# 创建索引
在这里,我们将数据加载到由MyScaleVectorStore提供的向量存储中。首先添加每个文档的元数据,然后将其添加到向量存储中。创建索引有助于快速和高效的搜索操作。通过对数据进行索引,系统可以执行快速的基于向量的搜索,这对于根据RAG应用程序中的相似度度量检索相关文档至关重要。
from llama_index.vector_stores.myscale import MyScaleVectorStore
from llama_index.core import StorageContext
for document in documents:
category = analyze_and_assign_category(document.text)
document.metadata = {"Category": category}
vector_store = MyScaleVectorStore(myscale_client=client)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context
)
注意:在使用MyScaleDB创建索引时,它使用了来自OpenAI的嵌入模型。为了启用此功能,您必须将OpenAI密钥添加为环境变量。
# 简单查询
要执行简单查询,我们需要将现有的索引转换为查询引擎。查询引擎是一种专门处理和解释搜索查询的工具。
query_engine = index.as_query_engine()
response = query_engine.query("我想要几双跑鞋")
print(response.source_nodes[0].text)
使用查询引擎,我们执行一个查询来查找“我想要几双跑鞋”。引擎处理此查询,然后在索引文档中搜索以找到最佳满足查询条件的匹配项。
# 过滤查询
在这里,使用MetadataFilters和ExactMatchFilter类配置了具有元数据过滤器的查询引擎。将ExactMatchFilter应用于“Category”元数据字段,以仅包括明确分类为“Running”的文档。此过滤器确保查询引擎仅考虑与跑步相关的文档,这可以带来更相关和聚焦的结果。similarity_top_k=2配置将搜索限制为最相似的两个文档,vector_store_query_mode="hybrid"建议使用向量和传统搜索方法的组合以获得最佳结果。
from llama_index.core.vector_stores import ExactMatchFilter, MetadataFilters
query_engine = index.as_query_engine(
filters=MetadataFilters(
filters=[
ExactMatchFilter(key="Category", value="Running"),
]
),
similarity_top_k=2,
vector_store_query_mode="hybrid",
)
response = query_engine.query("我想要几双跑鞋?")
print(response.source_nodes[0].text)
此输出应与用户的查询非常接近,展示了元数据过滤器如何有效地提高搜索结果的准确性。
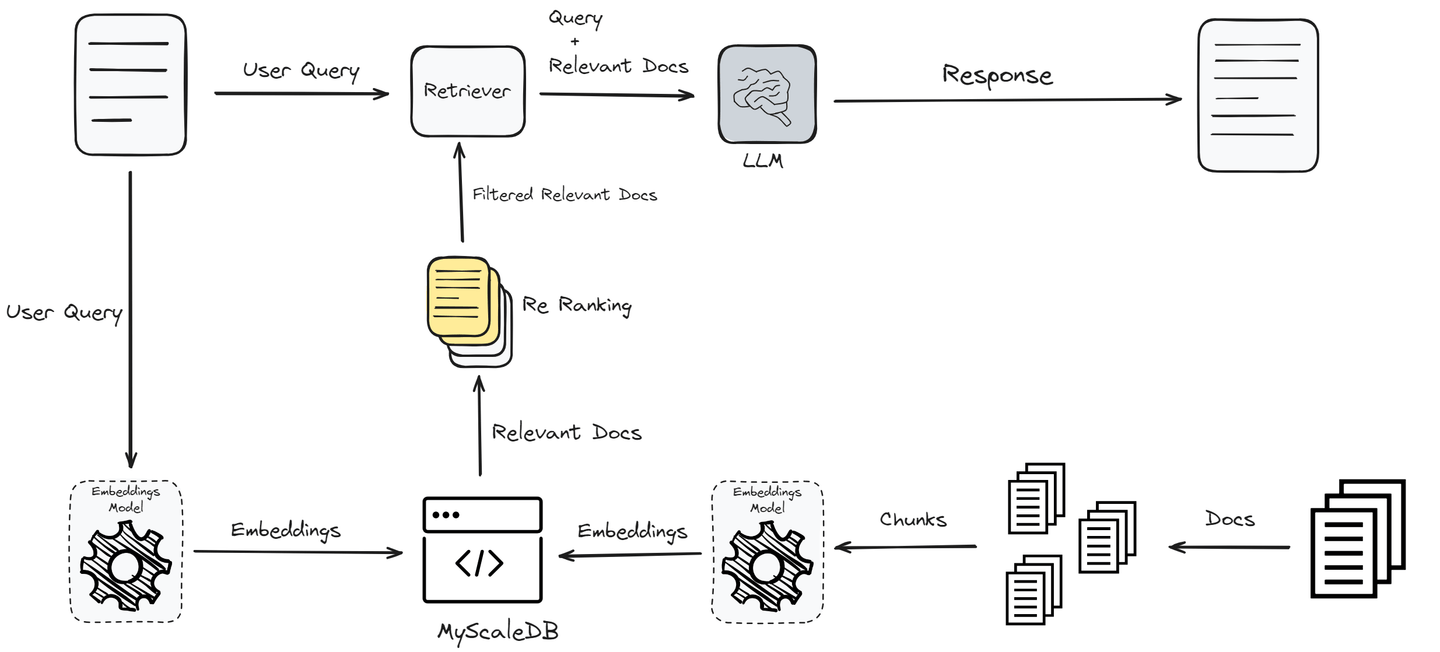
到目前为止,我们已经实现了最简单形式的RAG,可能无法获得最佳性能。为了提高性能并为用户提供准确的答案,我们现在将实现一个重新排序器,进一步过滤检索到的文档。
# 添加重新排序器以增强文档检索
此代码使用Jina AI集成了一个使用重新排序机制的重新排序器,以优化初始查询检索到的文档。
from llama_index.postprocessor.jinaai_rerank import JinaRerank
jina_rerank = JinaRerank(api_key="api-key-here", top_n=2)
from llama_index.llms.openai import OpenAI
llm = OpenAI(model="gpt-4", temperature=0)
query_engine = index.as_query_engine(
similarity_top_k=10, llm=llm, node_postprocessors=[jina_rerank]
)
response = query_engine.query("我想要几双跑鞋?")
print(response.source_nodes[0].text)
注意:您可以在此处 (opens new window)找到Jina Reranker密钥。点击API并滚动到新打开的页面下方,您将在Reranker API部分的正下方找到API密钥。
# 结论
RAG显著帮助LLM保持更新,并确保其响应准确和相关。然而,简单的RAG系统通常不适用于生产就绪的应用程序,因为它们的性能不佳。为了提高性能,我们使用了高级技术,如重新排序、预处理和过滤查询。
向量数据库的选择是影响RAG系统性能的另一个因素。
选择适合您应用程序需求的向量数据库至关重要。MyScaleDB作为SQL向量数据库,对于开发人员来说是一个不错的选择,它具有熟悉的SQL界面,而且价格实惠、快速且针对生产级应用进行了优化。
如果您有任何建议,请通过Twitter (opens new window)或Discord (opens new window)与我们联系。



