
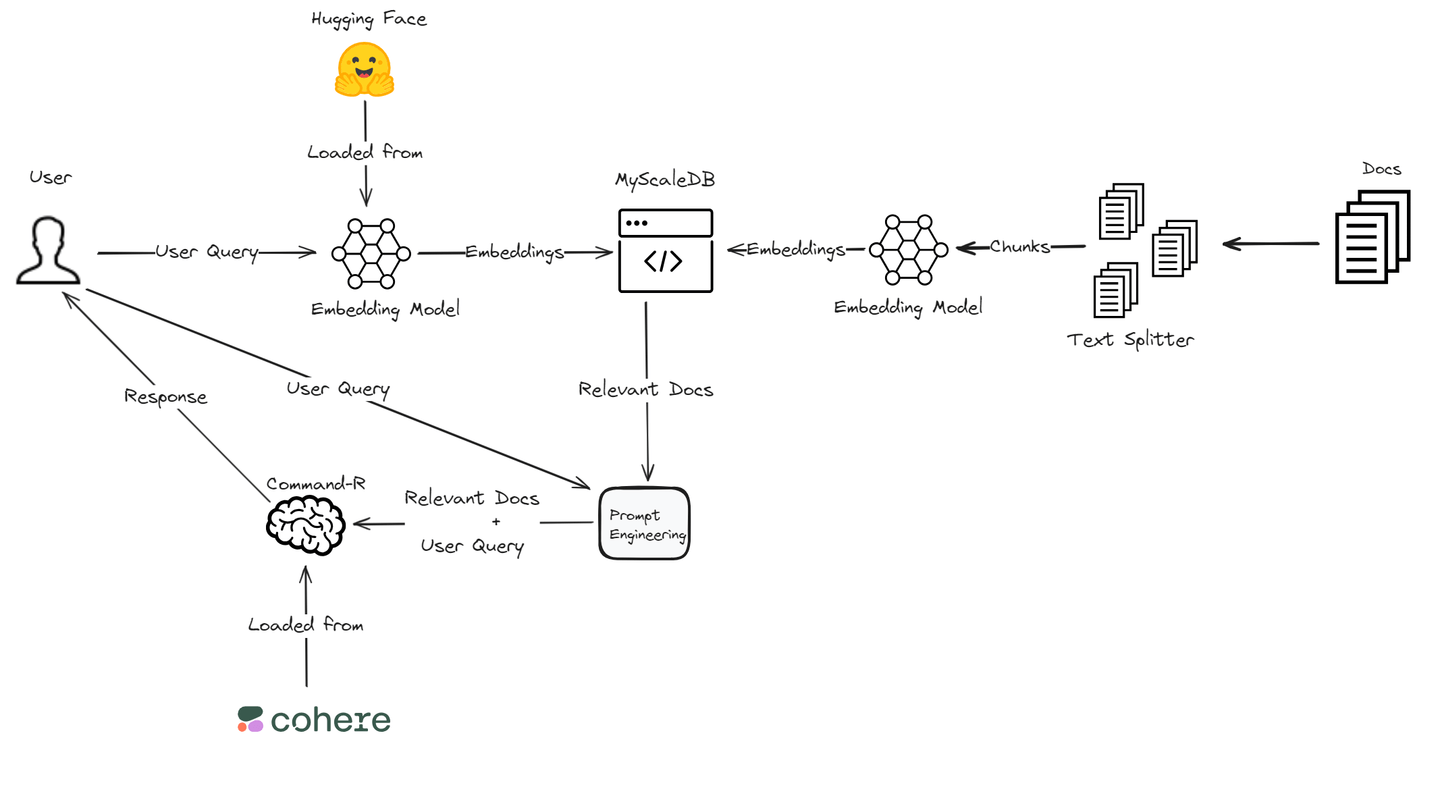
检索增强生成(RAG) (opens new window)是一种通过引用外部知识源来增强大型语言模型的技术。这种方法可以在不重新训练模型的情况下提供更准确和相关的响应。这是一种在各个领域中提高语言模型性能的经济高效的方式。
在本博客中,我们将使用Cohere的Command R模型 (opens new window),因为它在RAG方面具有出色的性能。它在检索和生成相关信息方面具有高准确性。对于嵌入 (opens new window),我们将依赖于Hugging Face的Transformers库 (opens new window),该库对各种NLP任务提供了广泛的支持,并与深度学习框架很好地集成。此外,高性能和高效的MyScaleDB将用于存储嵌入和文本块。这种技术组合确保了一个功能强大且高效的RAG系统,以满足我们特定的应用需求。
# 什么是Cohere?
Cohere (opens new window)是一家专门开发先进语言模型的平台,帮助企业自动化和增强客户互动。他们提供最先进的大型语言模型(LLMs),如Command,支持对话代理和摘要等应用,以及Rerank,优化搜索结果的相关性。这些工具提高了企业的沟通效率和准确性。
除了主要的LLMs,Cohere还提供了像Embed这样的模型,用于文本分类和语义搜索等任务,以及RAG功能,用于集成和检索来自文档和企业数据源的信息。这些模型使企业能够部署安全、可扩展的AI解决方案,提高整体运营效率和客户体验。
# 什么是Hugging Face?
Hugging Face (opens new window)是一个以使最先进的机器学习技术普及为目标的平台。他们的核心产品是Transformers库,是一个开源库,支持文本生成、摘要和翻译等任务。该库与PyTorch和TensorFlow等流行的深度学习框架兼容,使用户能够轻松实现BERT和GPT-2等最新的NLP模型。
除了提供强大的NLP工具,Hugging Face还提供各种无代码和低代码解决方案,用于部署生成式AI模型。他们的平台包括Inference Endpoints等功能,用于轻松部署模型,以及Spaces等功能,用于托管机器学习应用程序。Hugging Face还通过其Model Hub支持协作,用户可以共享和访问数千个模型、数据集和应用程序。这种社区驱动的方法有助于民主化机器学习,并促进AI领域的创新。
# 使用Cohere和Hugging Face构建RAG应用程序的基本组件
让我们深入了解使用Cohere和Hugging Face构建强大的RAG应用程序的基本组件。
# 集成Cohere的Command-R模型
在使用Cohere构建RAG应用程序时,Command-R模型是一个重要的功能。该模型通过连接外部数据源来获取相关信息,从而提高检索增强生成的效果,使响应更具相关性和准确性。通过使用此功能,您的应用程序可以提供更有见地和上下文恰当的答案。
# 使用Hugging Face的预训练模型
将Hugging Face的预训练模型整合到您的RAG应用程序中,可以在效率和准确性方面获得重要优势。这些模型经过广泛的训练,可以在各个领域生成高质量的响应。通过利用这些预训练模型,您可以加快开发过程,同时保持高水平的输出质量。
注意:
要在项目中使用Hugging Face模型,首先在Hugging Face上创建一个帐户并获取访问令牌 (opens new window)。
# 设置您的环境
在开始RAG应用程序之旅之前,请确保您已准备好必要的工具和帐户。您需要访问Cohere和Hugging Face等平台,并在这些平台上拥有帐户。此外,安装Cohere的API和Hugging Face Transformers等重要库对于无缝集成至关重要。
pip install cohere transformers clickhouse-connect
我们将使用MyScaleDB (opens new window)作为此RAG应用程序的向量数据库。MyScaleDB是一个SQL向量数据库,使用熟悉的SQL语法高效地检索LLMs的相关文档。它提供500万个免费的向量存储,让我们能够在没有任何成本的情况下利用其功能。

# 创建您的RAG应用程序
一旦您使用Cohere和Hugging Face为RAG应用程序打下基础,就是时候测试您的创作并优化其性能以获得最佳结果了。
# 加载数据
首先,我们需要使用langchain.document_loaders模块中的TextLoader加载数据。在本教程中,我们将使用Microsoft的WikiQA语料库 (opens new window)。
from langchain.document_loaders import TextLoader
loader = TextLoader('wikiQA-dev.txt', encoding='utf-8')
documents = loader.load()
text = documents[0].page_content
# 分割文本
接下来,我们使用CharacterTextSplitter将加载的文本分割成块。这有助于通过将大型文档分割成较小的可管理的部分来管理大型文档。分割文本对于高效处理大型文档是必要的,并且可以更好地处理和检索特定部分。
from langchain_text_splitters import CharacterTextSplitter
# 将文本分割成块
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=400,
chunk_overlap=100,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.create_documents([text])
# 加载预训练模型和分词器
我们使用Hugging Face的sentence-transformers/all-MiniLM-L6-v2模型生成文本嵌入。加载分词器和模型,并定义一个函数来获取文本嵌入。嵌入是文本的数值表示,捕捉其语义含义,对于相似性搜索和比较非常重要。
from transformers import AutoTokenizer, AutoModel
import torch
# 加载预训练的分词器和模型
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
# 获取文本嵌入的函数
def get_text_embeddings(text):
inputs = tokenizer(text, return_tensors='pt', truncation=True, padding=True)
with torch.no_grad():
embeddings = model(inputs).last_hidden_state.mean(dim=1)
return embeddings.numpy().flatten()
# 为文本块生成嵌入
对于每个文本块,我们生成嵌入并将其与原始文本一起存储在DataFrame中。这一步帮助我们更有效地管理数据,从而使存储过程更加轻松。
import pandas as pd
# 为每个文本块生成嵌入
page_contents = []
embeddings_list = []
for segment in texts:
embeddings_list.append(get_text_embeddings(segment.page_content))
page_contents.append(segment.page_content)
df = pd.DataFrame({
'page_content': page_contents,
'embeddings': embeddings_list
})
# 连接到MyScaleDB
我们连接到MyScaleDB (opens new window)数据库,以存储嵌入和文本块。请按照获取MyScaleDB集群凭据的步骤 (opens new window)。
import clickhouse_connect
# 连接到ClickHouse
client = clickhouse_connect.get_client(
host='your_host',
port=443,
username='your_user_name',
password='your_password'
)
# 创建并填充MyScaleDB表
我们在MyScale中创建一个表,用于存储文本块和嵌入,然后将数据插入表中。这一步将数据在数据库中进行结构化,使其准备好进行高效的查询和检索。
# 创建表
client.command("""
CREATE TABLE IF NOT EXISTS default.QnA (
id Int64,
page_content String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 384
) ENGINE = MergeTree() ORDER BY id
""")
# 将数据插入表中
batch_size = 100
num_batches = (len(df) + batch_size - 1) // batch_size
for i in range(num_batches):
batch_data = df[i * batch_size: (i + 1) * batch_size]
client.insert('default.QnA', batch_data.values.tolist(), column_names=batch_data.columns.tolist())
print(f"已插入第{i+1}/{num_batches}批数据。")
# 向表中添加向量索引
我们向表中添加向量索引,以便实现高效的相似性搜索。向量索引通过快速查找嵌入来增强检索过程,这对于根据语义内容查找相似文档至关重要。
# 向表中添加向量索引
client.command("""
ALTER TABLE default.QnA
ADD VECTOR INDEX vector_index embeddings
TYPE MSTG
""")
# 检索相关文档
我们定义一个函数来根据用户的查询检索最相关的文档。该函数计算查询嵌入和存储嵌入之间的距离,以找到最相关的文档。
# 检索相关文档的函数
def get_relevant_docs(user_query, top_k):
query_embeddings = get_text_embeddings(user_query).tolist()
results = client.query(f"""
SELECT page_content,
distance(embeddings, {query_embeddings}) as dist FROM default.QnA ORDER BY dist LIMIT {top_k}
""")
relevant_docs = []
doc_counter = 1
for row in results.named_results():
doc_key = f"doc{doc_counter}"
relevant_docs.append({doc_key: row['page_content']})
doc_counter += 1
return relevant_docs
# 示例查询
query = "上皮组织是如何连接在一起的?"
relevant_docs = get_relevant_docs(query, 8)
print(relevant_docs)
# 使用Cohere增强响应
我们使用Cohere的API通过查询检索到的文档来增强响应。Cohere的语言模型处理查询和检索到的文档,生成更全面和准确的响应。这一步将先进语言模型的能力与我们的检索系统集成起来。
import cohere
# 连接到Cohere
co = cohere.Client('your-cohere-client-api')
# 使用Cohere查询相关文档
response = co.chat(
model='command-r-plus',
message="上皮组织是如何连接在一起的?",
documents=relevant_docs
)
print(response.text)
# 总结和下一步
随着我们结束对使用Cohere和Hugging Face构建RAG应用程序的探索之旅,回顾在这个过程中遇到的挑战和经历的成长是非常重要的。
着手开发RAG流水线 (opens new window)可能会遇到意想不到的障碍,从而引发对性能差异的疑问。然而,通过利用Cohere的Command-R模型和Hugging Face的预训练模型,开发人员可以有效地应对这些挑战。检索和生成方法的集成需要精细调整以实现最佳结果,这需要毅力和策略性的调整。
对于任何RAG系统来说,直接影响其性能的另一个重要组成部分是向量数据库,它决定了数据的检索速度以及用户接收响应的速度。因此,在设计RAG系统时,选择正确的向量数据库非常重要。
然而,许多数据库在扩展时变得更慢。MyScaleDB (opens new window)是一个基于ClickHouse构建的开源SQL向量数据库。它继承了ClickHouse的高可扩展性,轻松管理大规模数据,为用户提供了一个强大而灵活的数据管理解决方案,用于构建可扩展的RAG系统。此外,它在速度和准确性方面表现出比大多数竞争对手更好的性能。
通过深入研究Cohere和Hugging Face提供的高级功能,开发人员可以在其RAG应用程序中实现更高效和更高性能的新维度。从优化检索机制到定制生成过程,这些平台提供了丰富的工具,进一步增强应用程序的功能。



