
在机器学习领域,模型曾经只能处理一种类型的数据。然而,机器学习的最终目标是与人类思维的认知能力相媲美,人类可以轻松地同时理解各种数据模态。最近的突破,如GPT-4V模型,展示了同时处理多种数据模态的卓越能力。这为开发人员创造能够无缝管理各种数据类型的AI应用程序打开了令人兴奋的可能性,这就是所谓的多模态应用程序。
一个引人注目的应用案例是多模态图像搜索。它可以通过分析特征或视觉内容来帮助用户找到相似的图像。由于计算机视觉和深度学习的快速发展,图像搜索变得非常强大。
在本文中,我们将使用Hugging Face库中的一个模型来构建一个多模态图像搜索应用程序。在深入探讨实际实现之前,让我们先了解一些基础知识。
# 什么是多模态系统?
多模态系统是指可以使用多种交互或通信模式的任何系统。它意味着系统可以同时处理和理解不同类型的输入,例如文本、图像、语音,有时甚至包括触摸或手势,并且还可以以各种方式返回结果。
例如,由OpenAI开发的 GPT-4V (opens new window) 是一个先进的多模态模型,可以同时处理文本和图像输入的多种“模态”。当提供一个带有描述性查询的图像时,该模型可以根据提供的文本分析视觉内容。
# 什么是多模态嵌入?
多模态嵌入是一种先进的机器学习技术,用于生成多种模态(例如图像、文本和音频)的数值表示,以向量格式表示。与基本的嵌入技术不同,基本嵌入技术只能在向量空间中表示单一数据类型,而多模态嵌入可以在统一的向量空间中表示各种数据类型。这允许系统将文本描述与相应的图像相关联。借助多模态嵌入的帮助,系统可以分析图像并将其与相关的文本描述相关联,或者反之亦然。
现在,让我们讨论如何开发这个项目以及我们将使用的技术。
# 工具和技术
在这个项目中,我们将使用CLIP、MyScale和Unsplash-25k数据集。让我们详细了解一下它们。
- CLIP:你将使用Hugging Face开发的预训练多模态 CLIP (opens new window) 模型。该模型将用于集成文本和图像。
- MyScale:MyScale是一个SQL向量数据库,用于以优化的方式存储和处理结构化和非结构化数据。你将使用MyScale来存储向量嵌入并查询相关图像。
- Unsplash-25k数据集:Unsplash提供的数据集包含约2.5万张图像。其中包括一些复杂的场景和对象。
# 如何设置Hugging Face和MyScale
要在本地环境中开始使用Hugging Face和MyScale,你需要安装一些Python包。打开终端并输入以下pip命令:
pip install datasets clickhouse-connect requests transformers torch tqdm
安装完成后,你可以通过在终端中输入以下命令来验证:
pip freeze | egrep '(datasets|clickhouse-connect|requests|transformers|torch|tqdm)'
它将打印出新安装的依赖项及其版本。
# 下载和加载数据集
第一步是下载数据集并将其解压到本地。你可以通过在终端中输入以下命令来完成:
# 下载数据集
wget https://unsplash-datasets.s3.amazonaws.com/lite/latest/unsplash-research-dataset-lite-latest.zip
# 将下载的文件解压到临时目录
unzip unsplash-research-dataset-lite-latest.zip -d tmp
让我们从提取的文件中将所需的数据加载到Python数据帧中。
# 导入pandas
import pandas as pd
# 从目录中加载照片文件
df_photos = pd.read_csv("tmp/photos.tsv", sep='\t', header=0)
df_photos
我们正在从目录中加载photos文件,该文件包含数据集中照片的信息。照片的配置如下:
| photo_id | photo_url | photo_image_url |
|---|---|---|
| xapxF7PcOzU | https://unsplash.com/photos/wud-eV6Vpwo | https://images.unsplash.com/photo-143924685475... |
| psIMdj26lgw | https://unsplash.com/photos/psIMdj26lgw | https://images.unsplash.com/photo-144077331099... |
photo_url和photo_image_url之间的区别在于,photo_url包含图像的描述页面的URL,其中包含有关照片的作者和其他元信息。photo_image_url仅包含图像的URL,我们将使用它来下载图像。
# 加载模型并获取嵌入
在加载数据集之后,让我们首先加载clip-vit-base-patch32 (opens new window)模型,并编写一个Python函数将图像转换为向量嵌入。该函数将使用CLIP模型表示嵌入。
# 导入pytorch
import torch
# 导入transformers以从Hugging Face加载模型和处理器
from transformers import CLIPProcessor, CLIPModel
# 从Hugging Face加载CLIP模型
model = CLIPModel.from_pretrained('openai/clip-vit-base-patch32')
# 加载用于预处理图像并使其与模型兼容的处理器
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# 定义方法
def create_embeddings(image=None, text=None):
# 初始化嵌入
image_embeddings = None
text_embeddings = None
# 处理图像(如果提供)
if image is not None:
image_embeddings = extract_image_features(image)
image_embeddings = torch.tensor(image_embeddings)
image_embeddings = image_embeddings / image_embeddings.norm(dim=-1, keepdim=True)
# 处理文本(如果提供)
if text is not None:
text_inputs = processor(text=[text], return_tensors="pt", padding=True)
with torch.no_grad():
text_outputs = model.get_text_features(**text_inputs)
text_embeddings = text_outputs / text_outputs.norm(dim=-1, keepdim=True)
text_embeddings = text_embeddings.squeeze(0).tolist()
# 如果同时提供图像和文本,则合并嵌入并进行归一化
if image_embeddings is not None and text_embeddings is not None:
combined_embeddings = (image_embeddings + torch.tensor(text_embeddings)) / 2
combined_embeddings = combined_embeddings / combined_embeddings.norm(dim=-1, keepdim=True)
return combined_embeddings.tolist()
# 如果只提供其中一个图像或文本,则只返回相应的嵌入
return image_embeddings.tolist() if text_embeddings is None else text_embeddings
上面的代码旨在同时处理文本和图像输入,无论是分别还是同时,并返回相应的嵌入。让我们看看它们是如何工作的:
- 如果你同时提供图像和文本,代码将返回一个向量,将两者的嵌入组合起来。
- 如果你只提供文本或图像(但不是两者),代码将简单地返回所提供文本或图像的嵌入。
注意:
我们使用了一种基本的方法来合并两个嵌入,以便专注于多模态概念。但是,还有一些更好的合并嵌入的方法,如连接和注意机制。
我们将加载、下载并将数据集中的前1000个图像传递给上述的create_embeddings函数。然后,返回的嵌入将存储到新的列photo_embed中。
# 导入图像处理模块
from PIL import Image
# 导入用于进行HTTP请求的requests模块
import requests
# 导入tqdm以进行进度条可视化
from tqdm.auto import tqdm
# 获取前1000个图像
photo_ids = df_photos['photo_id'][:1000]
# 过滤数据帧以获取所需的列
df_photos = df_photos.loc[photo_ids.index, ['photo_id', 'photo_image_url']]
# 创建一个会话以进行HTTP请求
session = requests.Session()
# 定义Python函数以下载图像并获取嵌入
def process_image(url):
try:
# 发送GET请求以下载图像
response = session.get(url, stream=True)
response.raise_for_status()
image = Image.open(response.raw)
# 获取嵌入并返回
return create_embeddings(image)
except requests.RequestException:
return None
# 构造一个URL以通过修改图像URL来下载较小尺寸的图像
df_photos['photo_image_url'] = df_photos['photo_image_url'].apply(lambda x: x + "?q=75&fm=jpg&w=200&fit=max")
# 逐个传递图像到'process_image'并将嵌入保存到新创建的列'photo_embed'中
df_photos['photo_embed'] = [process_image(url) for url in tqdm(df_photos['photo_image_url'], total=len(df_photos))]
# 删除图像处理失败的行
df_photos.dropna(subset=['photo_embed'], inplace=True)
# 重置索引并将'id'列重命名为'index'
df_photos = df_photos[df_photos['photo_id'].isin(photo_ids)].reset_index().rename(columns={'index': 'id'})
# 关闭会话
session.close()
注意:
这个过程需要一些时间,也取决于你的互联网速度。
完成此过程后,我们的数据集就准备好了。下一步是创建一个新表并将数据存储到MyScale中。
# 连接到MyScale
要将应用程序与MyScale连接,你需要完成一些设置和配置步骤。
- 创建帐户:首先,在MyScale (opens new window)上创建一个帐户。
- 创建集群:接下来,你需要创建一个集群。为此,你可以参考MyScale提供的详细说明文档中的“创建集群 (opens new window)”部分。
- 获取连接详细信息:一旦设置好了集群,下一步是获取连接详细信息 (opens new window),以建立应用程序与MyScale集群之间的连接。
一旦你获得了连接详细信息,你可以在下面的代码中替换这些值:
import clickhouse_connect
client = clickhouse_connect.get_client(
host='your-host-addres',
port=443,
username='your-username',
password='your-password'
)
# 创建表格
建立连接后,下一步是创建一个表格。现在,让我们首先使用以下命令查看我们的数据帧:
df_photos
数据帧如下所示:
| photo_id | photo_image_url | photo_embed |
|---|---|---|
| wud-eV6Vpwo | https://images.unsplash.com/uploads/1411949294... | [0.0028754104860126972, 0.02760922536253929, 0... |
| psIMdj26lgw | https://images.unsplash.com/photo-141633941111... | [0.019032524898648262, -0.04198262840509415, 0... |
| 2EDjes2hlZo | https://images.unsplash.com/photo-142014251503... | [-0.015412664040923119, 0.01923416182398796, 0... |
让我们根据数据帧创建一个表格。
# 检查是否存在同名的表格。如果存在,则删除该表格
client.command("DROP TABLE IF EXISTS default.myscale_photos")
# 为照片创建一个表格
client.command("""
CREATE TABLE default.myscale_photos
(
id UInt64,
photo_id String,
photo_image_url String,
photo_embed Array(Float32),
CONSTRAINT vector_len CHECK length(photo_embed) = 512
)
ORDER BY id
""")
上述命令将在MyScale集群中创建一个表格。
# 插入数据
让我们将数据插入到新创建的表格中:
# 从数据集中上传数据
client.insert("default.myscale_photos", df_photos.to_records(index=False).tolist(),
column_names=df_photos.columns.tolist())
# 检查插入的数据数量
print(f"photos count: {client.command('SELECT count(*) FROM default.myscale_photos')}")
# 使用余弦距离创建向量索引
client.command("""
ALTER TABLE default.myscale_photos
ADD VECTOR INDEX photo_embed_index photo_embed
TYPE MSTG
('metric_type=Cosine')
""")
# 检查向量索引的状态,确保向量索引处于“已构建”状态
get_index_status="SELECT status FROM system.vector_indices WHERE name='photo_embed_index'"
print(f"index build status: {client.command(get_index_status)}")
上面的代码将数据插入表格,并使用MSTG算法创建索引。索引用于快速从表格中检索数据。最后一个命令用于确保索引是否成功创建。如果是,则会显示“index build status: Built”。
注意:
MSTG算法是由MyScale创建的,它比其他索引算法(如IVF和HNSW)更快。

# 如何查询MyScale
一旦数据插入完成,我们就可以利用MyScale查询数据并使用多模态获取图像。因此,让我们首先尝试从表格中获取一张随机图像。
import requests
import matplotlib.pyplot as plt
from PIL import Image
from io import BytesIO
# 通过URL下载图像
def download(url):
response = requests.get(url)
return Image.open(BytesIO(response.content))
def show_image(url, title=None):
img = download(url)
fig = plt.figure(figsize=(4, 4))
plt.imshow(img)
plt.show()
random_image = client.query("SELECT * FROM default.myscale_photos ORDER BY rand() LIMIT 1")
target_image_url = random_image.first_item["photo_image_url"]
print("Loading target image...")
show_image(target_image_url)
上述代码应该从表格中随机搜索一张图像,并在代码编辑器中显示它。
# 如何使用文本和图像获取相关图像
正如你所了解的,多模态模型可以同时处理多种数据模态。类似地,我们的模型可以同时处理图像和文本,提供相关的图像。我们将提供以下图像以及文本:'一个站在海滩上的男人'。

让我们将图像URL与文本一起传递给create_embeddings函数。
image_url="https://images.unsplash.com/photo-1701443478334-c1a4bfda91ff?q=80&w=1936&auto=format&fit=crop&ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D"
query_text="一个站在海滩上的男人"
embeddings=create_embeddings(download(url),query_text)
下一步是编写一个查询,从数据集中获取top_k个相关结果。
top_k = 5
# 查询数据库中的相关结果
results = client.query(f"""
SELECT photo_id, photo_image_url, distance(photo_embed, {embeddings}) as dist
FROM default.myscale_photos
ORDER BY dist ASC
LIMIT {top_k}
""")
# 下载相关图像
images_url = []
for r in results.named_results():
# 通过修改图像URL构造一个URL以下载较小尺寸的图像
url = r['photo_image_url'] + "?q=75&fm=jpg&w=200&fit=max"
images_url.append(download(url))
# 显示图像
print("Loading candidate images...")
for row in range(int(top_k / 5)):
fig, axs = plt.subplots(1, 5, figsize=(20, 4))
for i, img in enumerate(images_url[row * 5:row * 5 + 5]):
axs[i % 5].imshow(img)
plt.show()
注意:
距离函数计算查询向量与所有相关向量之间的欧氏距离。
上述代码将生成类似于以下内容的结果:
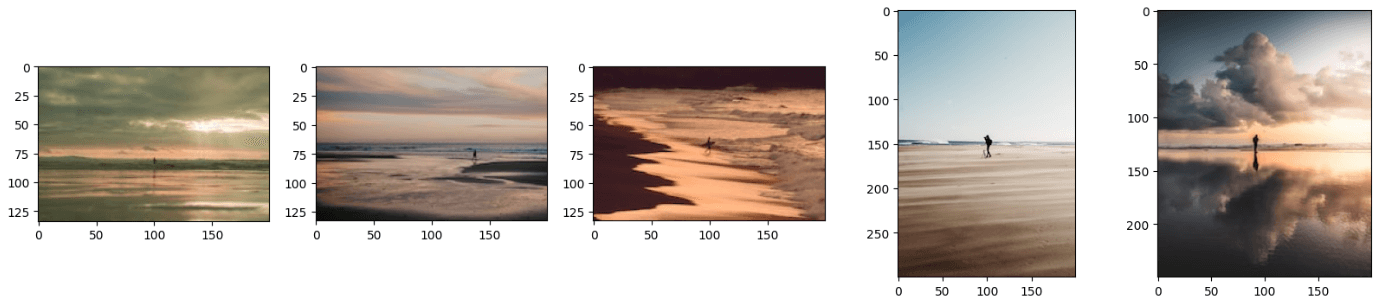
注意:
你可以使用更好的技术来合并嵌入以进一步改进结果。
你可能已经注意到,结果图像看起来像是文本和图像的组合。你还可以通过仅提供图像或文本给该模型来获取结果,它仍然可以正常工作。为此,你只需将代码中的image_url或query_text行注释掉。
# 结论
传统模型用于获取单一数据类型的向量表示,但最新的模型经过更多数据的训练,现在能够在统一的向量空间中表示不同类型的数据。我们利用最新模型CLIP的能力开发了一个应用程序,该应用程序接受文本和图像作为输入,并返回相关的图像。
多模态嵌入的能力不仅限于图像搜索应用程序,而且你可以利用这种前沿技术开发最先进的推荐系统、视觉问答应用程序(用户可以针对图像提出问题)等等。在开发这些应用程序时,考虑使用 MyScale (opens new window),这是一个集成的SQL向量数据库,可以让你以超快的数据检索能力存储向量嵌入和数据集中的表格数据。
如果你正在构建图像搜索应用程序,欢迎在 MyScale 的Discord (opens new window)中交流你的想法或反馈。



