
检索增强生成 (opens new window)(RAG)是自然语言处理(NLP)领域的一项重大突破,特别适用于AI应用的开发。RAG将大型知识库 (opens new window)和大型语言模型 (opens new window)(LLM)的语言能力与数据检索能力相结合。实时检索和使用信息使得AI交互更加真实和知情。
RAG显然改善了用户与AI的互动方式。例如,由LLM驱动的聊天机器人 (opens new window)已经可以处理复杂问题,并根据个体用户进行个性化回应。RAG应用通过不仅使用训练数据,还在交互过程中查找最新信息来增强这一功能。
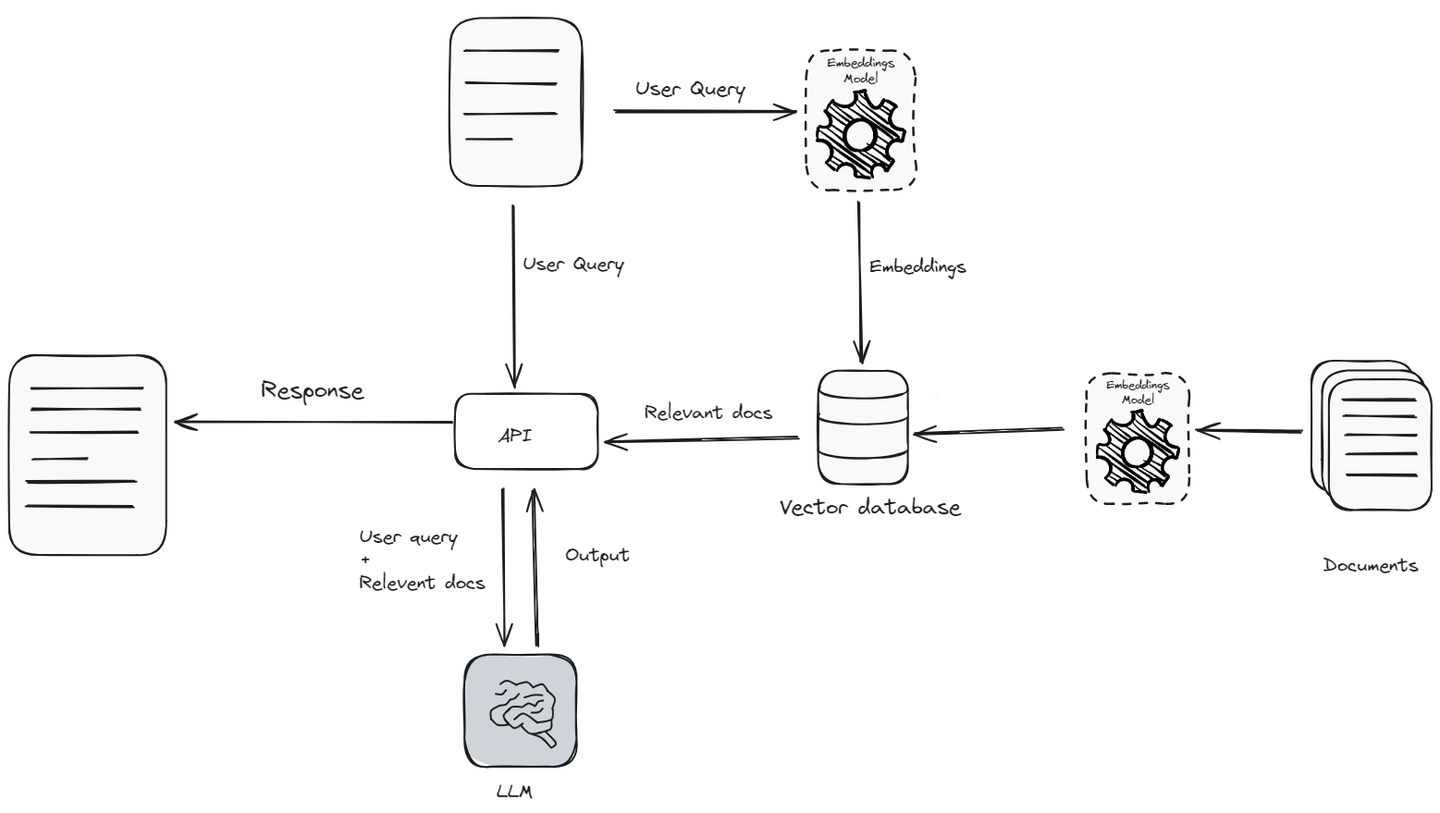
然而,当我们尝试扩展RAG应用时,它们在小规模使用时效果很好,但会带来一些重大挑战,例如管理API和数据存储成本、降低延迟和提高吞吐量、高效搜索大型知识库以及确保用户隐私。
在本博客中,我们将探讨扩展RAG应用时遇到的各种挑战,以及解决这些挑战的有效方法。
# 管理成本:数据存储和API使用
扩展RAG应用的最大障碍之一是管理成本,特别是由于依赖大型语言模型(LLM)(如OpenAI (opens new window)或Gemini (opens new window))的API。在构建RAG应用时,有三个主要的成本因素需要考虑:
- LLM API
- 嵌入模型API
- 向量数据库
这些API的成本较高,因为服务提供商在其端管理一切,如计算成本、训练等。这种设置对于较小的项目可能是可持续的,但随着应用的使用规模扩大,成本很快可能成为一个重大负担。
假设您在RAG应用中使用gpt-4,并且您的RAG应用每天处理超过1000万个输入和300万个输出标记,您可能需要支付每天约480美元的费用,这是运行任何应用程序的重大开销。同时,向量数据库也需要定期更新,并且必须随着数据的增长而扩展,这会增加更多的成本。
# 降低成本的策略
正如我们所讨论的,RAG架构中的某些组件可能非常昂贵。让我们讨论一些降低这些组件成本的策略。
- 微调LLM和嵌入模型:为了降低LLM API和嵌入模型的成本,最有效的方法是选择一个开源LLM (opens new window)和嵌入模型,然后使用您的数据对其进行微调。然而,这需要大量的数据、技术专长和计算资源。
- 缓存:使用缓存 (opens new window)存储LLM的响应可以减少API调用的成本,同时使应用程序更快、更高效。当响应保存在缓存中时,如果需要再次使用,可以快速检索,而无需再次向LLM请求。使用缓存可以将API调用的成本降低多达10%。您可以使用来自langchain的不同缓存技术 (opens new window)。
- 简洁的输入提示:通过精炼和缩短输入提示,可以减少所需的输入标记数量。这不仅使模型更好地理解用户查询,而且由于使用的标记更少,还可以降低成本。
- 限制输出标记:设置输出标记的数量限制可以防止模型生成不必要的长回应,从而在提供相关信息的同时控制成本。
# 降低向量数据库成本
向量数据库在RAG应用中起着关键作用,输入的数据类型同样重要。正如一句名言所说:“垃圾进,垃圾出”。
- 预处理:预处理数据的目的是实现文本标准化和一致性。文本标准化去除了不相关的细节和特殊字符,使数据在上下文中丰富和一致。专注于清晰度、上下文和正确性不仅增强了系统的效率,还减少了数据量。数据量的减少意味着需要存储的数据较少,从而降低了存储成本,并提高了数据检索的效率。
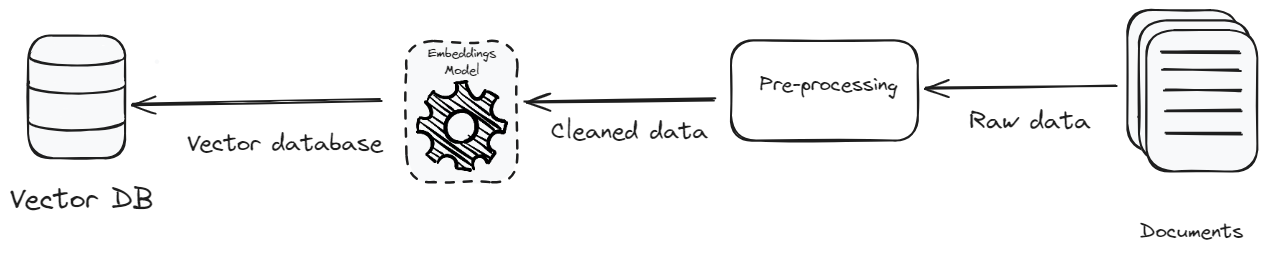
- 成本效益的向量数据库:降低成本的另一种方法是选择一个价格较低的向量数据库。目前市场上有很多选择,但选择一个既经济实惠又可扩展的数据库非常重要。MyScaleDB (opens new window)是一个专为开发可扩展的RAG应用而设计的向量数据库,特别考虑了成本等多个因素。它是市场上最便宜的向量数据库之一,性能比竞争对手更好。
相关文章:通过Python客户端开始使用MyScale (opens new window)
# 大量用户对性能的影响
随着RAG应用的扩展,它不仅必须支持越来越多的用户,还必须保持速度、效率和可靠性。这涉及优化系统,以确保即使在高并发用户的情况下也能实现最佳性能。
延迟:对于实时应用程序(如聊天机器人),保持低延迟 (opens new window)至关重要。延迟是指在传输数据的指令后,数据传输开始之前的延迟。减少延迟的技术包括优化网络路径、减少数据处理的复杂性和使用更快的处理硬件。有效管理延迟的一种方法是将提示大小限制为必要的信息,避免过于复杂的指令,以免降低处理速度。
吞吐量:在高需求时,处理大量请求的能力称为吞吐量。通过使用连续批处理等技术,可以显著增强吞吐量,即在请求到达时动态地将请求分组为单个批次,而不是等待填充一个批次。
# 提高性能的建议:
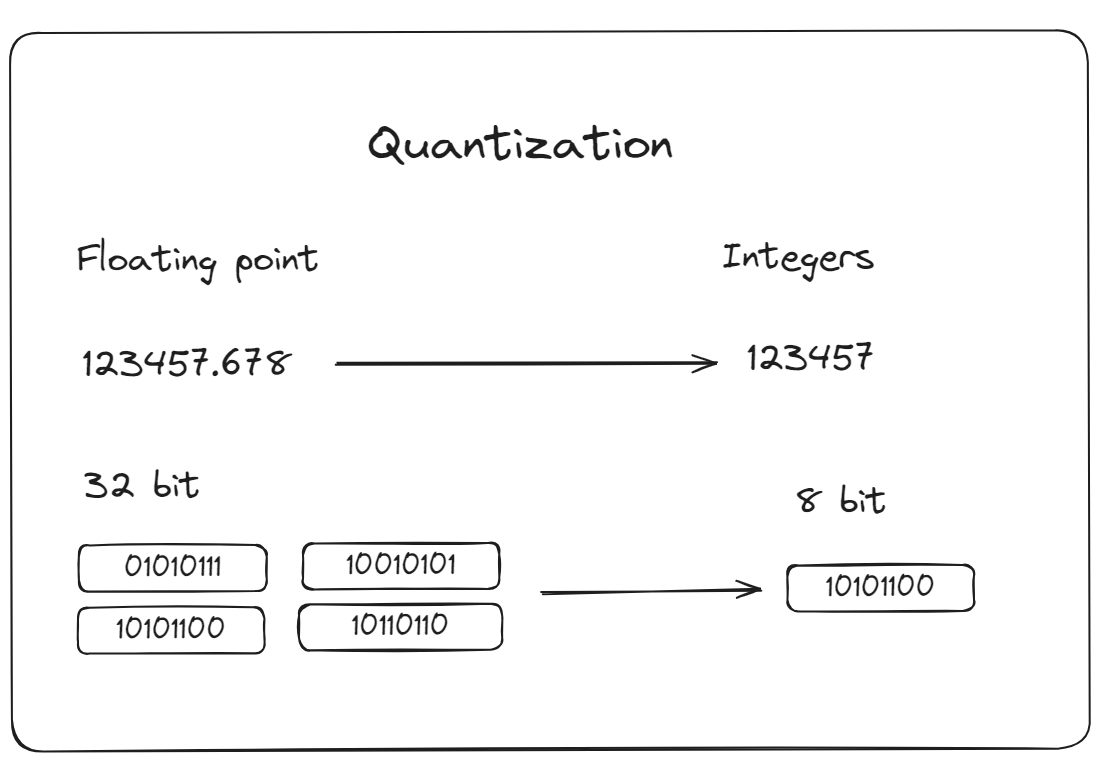
- 量化:量化是指减少用于表示模型参数的数字的精度。这减少了模型计算量,可以减少所需的计算资源,从而加快推理时间。MyScaleDB提供了先进的向量索引选项,如IVFPQ(倒排文件分区和量化)或HNSWSQ(分层可导航小世界量化)。这些方法旨在通过优化数据检索过程来改善应用程序的性能。
除了这些流行的算法外,MyScaleDB还开发了多尺度树图(MSTG)(企业级功能),它围绕量化和分层存储等新颖策略。与IVFPQ或HNSWSQ相比,该算法推荐用于实现低成本和高精度。通过利用内存和快速的NVMe SSD,MSTG在资源消耗方面与IVF和HNSW算法相比显著降低,同时保持出色的性能和精度。
多线程:多线程将使您的应用程序能够同时处理多个请求,利用多核处理器的能力。通过这样做,可以最小化延迟,并提高系统的整体速度,特别是在处理许多用户或复杂查询时。
动态批处理:与按顺序处理大型语言模型(LLMs)的请求不同,动态批处理将多个请求智能地分组为单个批次发送。这种方法提高了效率,特别是在处理OpenAI和Gemini等服务提供商时,他们会施加API速率限制。使用动态批处理可以在这些速率限制内处理更多的请求,使您的服务更可靠,并优化API使用。
# 高效搜索庞大的嵌入空间
高效的检索主要取决于向量数据库对数据进行索引的能力以及检索相关信息的速度和效果。每个向量数据库在数据集较小的情况下表现得相当好,但随着数据量的增加,问题就会出现。索引和检索相关信息的复杂性增加。这可能导致检索过程变慢,而在需要实时或准实时响应的环境中,这是至关重要的。此外,数据库越大,越难保持其准确性和一致性。错误、重复和过时的信息很容易出现,这可能会影响LLM应用程序提供的输出质量。
此外,RAG系统依赖于从庞大数据集中检索最相关的信息,这意味着数据质量的任何下降都直接影响应用程序的性能和可靠性。随着数据集的增长,确保每个查询都得到最准确和上下文适当的响应变得越来越困难。
# 优化搜索的解决方案:
为了确保数据量的增长不会影响系统的性能或输出质量,需要考虑以下几个因素:
- 高效的索引:使用更复杂的索引方法或更高效的向量数据库解决方案来处理大型数据集,而不会影响速度。MyScaleDB (opens new window)提供了一种先进的向量索引方法MSTG (opens new window),专为处理非常大的数据集而设计。在LAION 5M数据集上,它的QPS(每秒查询数)达到了390,实现了95%的召回率,并保持了18ms的平均查询延迟,使用s1.x1 pod。
- 更好的数据质量:为了提高数据质量,这对于RAG系统的准确性和可靠性非常重要,需要实施多种预处理技术。这将帮助我们优化数据集,减少噪音,增加检索信息的精确性。它将直接影响RAG应用的效果。
- 数据修剪和优化:您可以定期审查和修剪数据集,删除过时或无关的向量,使数据库保持精简和高效。
此外,MyScaleDB在数据摄入时间方面也优于其他向量数据库,完成5M数据点的任务只需约30分钟。如果您注册,您可以免费使用一个x1 pod,可以处理高达500万个向量。

# 数据泄露的风险始终存在
在RAG应用中,由于两个主要方面,隐私问题尤为重要:LLM API的使用和数据存储在向量数据库中。通过LLM API传递私人数据时,存在数据可能会暴露给第三方服务器的风险,可能导致敏感信息的泄露。此外,将数据存储在可能不完全安全的向量数据库中也可能对数据隐私造成风险。
# 提升隐私的解决方案:
为了应对这些风险,特别是在处理敏感或高度机密的数据时,请考虑以下策略:
内部LLM开发:不要依赖第三方LLM API,您可以选择任何开源LLM,并在内部对其进行微调 (opens new window)。这种方法确保所有敏感数据都保留在组织的受控环境中,大大降低数据泄露的可能性。
安全的向量数据库:确保您的向量数据库采用最新的加密标准和访问控制。MyScaleDB由于其强大的安全功能而受到团队和组织的信任。它在安全、完全托管的AWS基础设施上运行多租户Kubernetes集群。MyScaleDB通过将客户数据存储在隔离的容器中并持续监控操作指标来保护客户数据,以维护系统的健康和性能。此外,它已成功完成SOC 2 Type 1审计,符合最高的全球数据安全标准。使用MyScaleDB,您可以确保您的数据始终严格属于您自己。
相关文章:通过MyScale超越专用向量数据库 (opens new window)
# 结论
尽管检索增强生成(RAG)是人工智能的重大进步,但它也面临着挑战。这些挑战包括API和数据存储的高成本、增加的延迟以及随着更多用户加入的需求提高吞吐量。随着存储数据量的增加,隐私和数据安全也变得至关重要。
我们可以通过几种策略来解决这些问题。通过使用内部微调的开源LLMs和缓存来降低成本是可能的。为了提高延迟和吞吐量,我们可以使用动态批处理和先进的量化技术来加快处理速度和效率。为了提高安全性,开发专有的LLMs并使用像MyScaleDB这样的向量数据库是一个很好的选择。
如果您有任何建议,请通过**Twitter (opens new window)或Discord (opens new window)**与我们联系。




