
大型语言模型(LLMs) (opens new window)通过生成类似人类的文本、回答复杂问题和分析大量信息以令人印象深刻的准确性,改变了自然语言处理(NLP) (opens new window)领域。它们处理各种查询并生成详细的响应的能力使它们在许多领域中都非常有价值,从客户服务到医学研究。然而,随着LLMs扩展以处理更多数据,它们在管理长文档和高效检索最相关信息方面面临挑战。
虽然LLMs擅长处理和生成类似人类的文本,但它们有一个有限的“上下文窗口”。这意味着它们一次只能在内存中保存一定数量的信息,这使得处理非常长的文档变得困难。LLMs还很难从大型数据集中快速找到最相关的信息。除此之外,LLMs是在固定数据上进行训练的,因此随着新信息的出现,它们可能变得过时。为了保持准确和有用,它们需要定期更新。
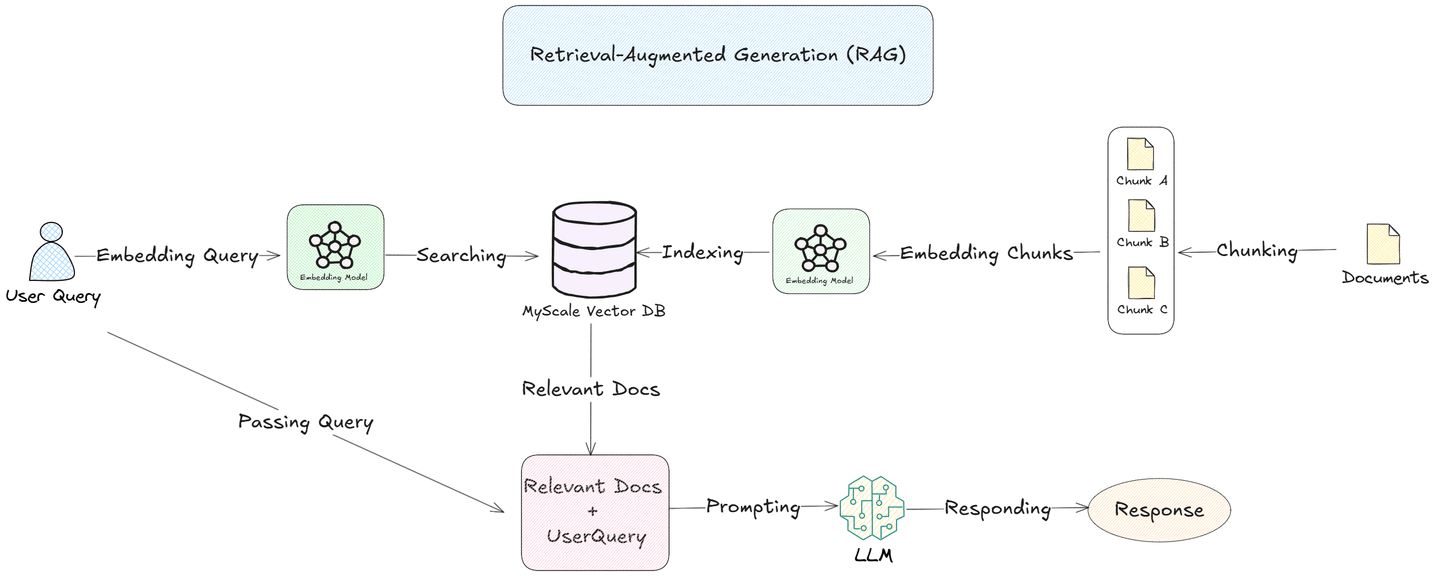
检索增强生成(RAG) (opens new window)解决了这些挑战。通过将文档分块为更小、有意义的片段,并将它们嵌入到像MyScale (opens new window)数据库这样的向量数据库中,RAG系统可以搜索并检索每个查询的最相关的片段。这种方法使LLMs能够专注于特定信息,提高响应的准确性和效率。
在本博客中,我们将更深入地探讨分块及其不同的策略,以及它们在优化LLMs用于实际应用中的作用。
# 什么是分块?
分块是将大型数据源分割成更小、可管理的部分或“块”的过程。这些块被存储在向量数据库中,可以根据相似性进行快速高效的搜索。当用户提交查询时,向量数据库会找到最相关的块并将它们发送给语言模型。这样,模型可以只关注最相关的信息,使其响应更快、更准确。通过缩小需要查看的数据范围,分块有助于语言模型更顺畅地处理大型数据集并提供精确的答案。
对于需要快速、准确答案的应用(如客户支持或法律文件搜索),分块是一种重要的策略,可以提高性能和可靠性。
以下是在RAG中使用的一些主要分块策略:
- 固定大小分块
- 递归分块
- 语义分块
- 主动分块
现在,让我们深入了解每种分块策略的详细信息。
# 固定大小分块
固定大小分块涉及将数据均匀分成大小相等的部分,从而更容易处理大型文档。有时,开发人员在块之间添加轻微的重叠,其中一个段的一小部分在下一个段的开头重复。这种重叠的方法有助于模型在每个块的边界上保持上下文连续性,确保关键信息不会丢失。这种策略特别适用于需要连续的信息流的任务,因为它使模型能够更准确地解释文本并理解段之间的关系,从而实现更连贯和具有上下文意识的响应。

上图是固定大小分块的完美示例,每个块由唯一的颜色表示。绿色部分表示块之间的重叠部分,确保模型在处理下一个块时可以访问相关上下文。
这种重叠改善了模型处理和理解完整文本的能力,从而在摘要或翻译等任务中提高性能,其中在块边界上保持信息流的连续性至关重要。
# 代码示例
现在让我们通过一个编码示例来重新创建这个例子,我们将使用LangChain (opens new window)来帮助我们实现固定大小分块。
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 使用固定大小分块和重叠的函数
def split_text_with_overlap(text, chunk_size, overlap_size):
# 创建一个带有重叠的文本分割器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=overlap_size
)
# 分割文本
chunks = text_splitter.split_text(text)
return chunks
# 示例文本
text = """人工智能(AI)模拟人类智能,用于视觉感知、语音识别和语言翻译等任务。它已从基于规则的系统发展到基于数据驱动的模型,通过机器学习和深度学习提高性能。"""
# 定义块大小和重叠大小
chunk_size = 80 # 每个块80个字符
overlap_size = 10 # 块之间10个字符的重叠
# 获取带有重叠的块
chunks = split_text_with_overlap(text, chunk_size, overlap_size)
# 打印块和重叠部分
for i in range(len(chunks)):
print(f"块 {i+1}:")
print(chunks[i]) # 打印块本身
# 如果有下一个块,打印当前块和下一个块之间的重叠部分
if i < len(chunks) - 1:
overlap = chunks[i][-overlap_size:] # 获取重叠部分
print(f"与块 {i+2} 的重叠部分:")
print(overlap)
print("\n" + "="*50 + "\n")
执行上述代码将生成以下输出:
块 1:
人工智能(AI)模拟人类智能,用于视觉感知、语音识别和语言翻译等任务。它已从基于规则的系统发展到基于数据驱动的模型,通过机器学习和深度学习提高性能。
与块 2 的重叠部分:
用于视觉感知、语音识别和语言翻译等任务。它已从基于规则的系统发展到基于数据驱动的模型,通过机器学习和深度学习提高性能。
==================================================
块 2:
用于视觉感知、语音识别和语言翻译等任务。它已从基于规则的系统发展到基于数据驱动的模型,通过机器学习和深度学习提高性能。
与块 3 的重叠部分:
通过机器学习和深度学习提高性能。
==================================================
块 3:
通过机器学习和深度学习提高性能。
# 递归分块
递归分块是一种将大段文本系统地分割成更小、可管理的部分的方法,通过反复将其分解为子块来实现。这种方法特别适用于复杂或分层文档,确保每个段落保持连贯和上下文完整。该过程将继续进行,直到文本达到适合进行高效处理的大小。
例如,考虑一个需要由具有有限上下文窗口的语言模型处理的长文档。递归分块首先将文档分成主要部分。如果这些部分仍然太大,该方法将进一步将它们分成子部分,并继续此过程,直到每个块适合模型的处理能力。这种分层分解保留了原始文档的逻辑流和上下文,使模型能够更有效地处理长文本。
在实践中,递归分块可以使用各种策略来实现,例如基于标题、段落或句子的分割,具体取决于文档的结构和任务的特定要求。

在上图中,文本被分成四个块,每个块用不同的颜色表示,使用递归分块。文本被分解成更小、可管理的部分,每个块包含多达80个单词。块之间没有重叠。颜色编码有助于显示内容如何分成逻辑部分,使模型更容易处理和理解长文本而不丢失重要的上下文。
# 代码示例
现在让我们编写一个示例代码,来实现递归分块。
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 将文本使用递归分块分割的函数
def split_text_recursive(text, chunk_size=80):
# 初始化RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, # 每个块的最大大小(80个单词)
chunk_overlap=0 # 块之间没有重叠
)
# 将文本分割成块
chunks = text_splitter.split_text(text)
return chunks
# 示例文本
text = """人工智能(AI)模拟人类智能,用于视觉感知、语音识别和语言翻译等任务。它已从基于规则的系统发展到基于数据驱动的模型,通过机器学习和深度学习提高性能。"""
# 使用递归分块分割文本
chunks = split_text_recursive(text, chunk_size=80)
# 打印结果块
for i, chunk in enumerate(chunks):
print(f"块 {i+1}:")
print(chunk)
print("="*50)
上述代码将生成以下输出:
块 1:
人工智能(AI)模拟人类智能,用于视觉感知、语音识别和语言翻译等任务。它已从基于规则的系统发展到基于数据驱动的模型,通过机器学习和深度学习提高性能。
==================================================
块 2:
通过机器学习和深度学习提高性能。
==================================================
在了解了基于长度的两种分块策略之后,现在是时候了解一种更注重文本的含义/上下文的分块策略。
# 语义分块
语义分块是根据内容的含义或上下文将文本分块的方法。这种方法通常使用机器学习 (opens new window)或自然语言处理(NLP) (opens new window)技术,例如句子嵌入,来识别具有相似含义或语义结构的文本部分。

在上图中,每个块由不同的颜色表示,蓝色表示AI,黄色表示Prompt Engineering。这些块之间被分开,因为它们涵盖了不同的主题。这种方法确保模型可以清楚地理解每个主题,而不会混淆它们。
# 代码示例
现在让我们编写一个示例代码,来实现语义分块。
import os
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai.embeddings import OpenAIEmbeddings
# 将OpenAI API密钥设置为环境变量(替换为您的实际API密钥)
os.environ["OPENAI_API_KEY"] = "replace with your actual OpenAI API key"
# 将文本分割为语义块的函数
def split_text_semantically(text, breakpoint_type="percentile"):
# 使用OpenAI嵌入初始化SemanticChunker
text_splitter = SemanticChunker(OpenAIEmbeddings(), breakpoint_threshold_type=breakpoint_type)
# 创建文档(块)
docs = text_splitter.create_documents([text])
# 返回块的列表
return [doc.page_content for doc in docs]
def main():
# 示例内容(国情咨文或您自己的文本)
document_content = """
人工智能(AI)模拟人类智能,用于视觉感知、语音识别和语言翻译等任务。它已从基于规则的系统发展到基于数据驱动的模型,通过机器学习和深度学习提高性能。
Prompt Engineering涉及设计输入提示,以指导AI模型生成准确和相关的响应,改善文本生成和摘要等任务。
"""
# 使用选择的阈值类型(百分位数)拆分文本
threshold_type = "percentile"
print(f"\n使用{threshold_type}阈值的块:")
chunks = split_text_semantically(document_content, breakpoint_type=threshold_type)
# 打印每个块的内容
for idx, chunk in enumerate(chunks):
print(f"块 {idx + 1}:")
print(chunk)
print()
if __name__ == "__main__":
main()
上述代码将生成以下输出:
使用百分位数阈值的块:
块 1:
人工智能(AI)模拟人类智能,用于视觉感知、语音识别和语言翻译等任务。它已从基于规则的系统发展到基于数据驱动的模型,通过机器学习和深度学习提高性能。
块 2:
Prompt Engineering涉及设计输入提示,以指导AI模型生成准确和相关的响应,改善文本生成和摘要等任务。
# 主动分块
主动分块是这些策略中的一种强大策略。在这种策略中,我们利用GPT等LLMs作为代理来执行分块过程。与手动确定如何分割内容不同,LLMs主动根据其理解输入来组织或分割信息。LLMs根据任务的上下文确定将内容分割成可管理的部分的最佳方法。
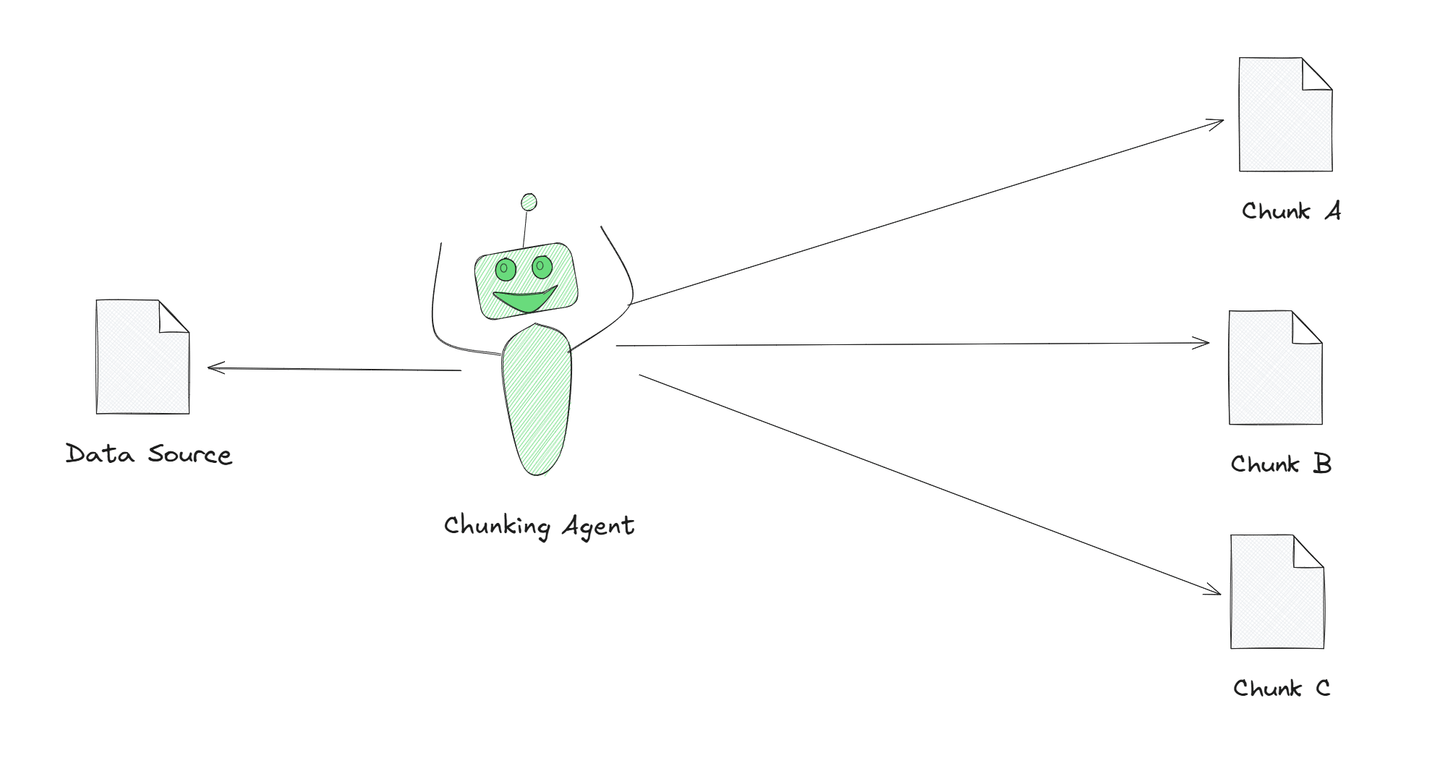
图示展示了一个分块代理将大型文本分解为更小、有意义的部分。这个代理由AI驱动,帮助它更好地理解文本并将其分成有意义的块。这被称为主动分块,与简单地将文本切割成相等部分相比,这是一种更智能的处理文本的方式。
现在让我们看看如何在代码示例中实现它。
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.agents import initialize_agent, Tool, AgentType
# 初始化OpenAI聊天模型(替换为您的API密钥)
llm = ChatOpenAI(model="gpt-3.5-turbo", api_key="replace with your actual OpenAI API key")
# 步骤1:定义分块和摘要的提示模板
chunk_prompt_template = """
您获得了一大段文本。您的任务是,如果需要,将其分成更小的部分(块),并对每个块进行摘要。
一旦所有部分都被摘要,将它们合并成最终摘要。
如果文本已经足够小,可以一次提供完整的摘要。
请对以下文本进行摘要:\n{input}
"""
chunk_prompt = PromptTemplate(input_variables=["input"], template=chunk_prompt_template)
# 步骤2:定义分块处理工具
def chunk_processing_tool(query):
"""处理文本块并生成摘要,使用定义的提示。"""
chunk_chain = LLMChain(llm=llm, prompt=chunk_prompt)
print(f"处理块:\n{query}\n") # 显示正在处理的块
return chunk_chain.run(input=query)
# 步骤3:定义外部工具(可选,可用于获取额外信息)
def external_tool(query):
"""模拟可以获取额外信息的外部工具。"""
return f"基于查询的外部响应:{query}"
# 步骤4:使用工具初始化代理
tools = [
Tool(
name="分块处理",
func=chunk_processing_tool,
description="处理文本块并生成摘要。"
),
Tool(
name="外部查询",
func=external_tool,
description="获取额外数据以增强分块处理。"
)
]
# 使用定义的工具和零样本能力初始化代理
agent = initialize_agent(
tools=tools,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
llm=llm,
verbose=True
)
# 步骤5:主动分块处理函数
def agent_process_chunks(text):
"""使用代理处理文本块并生成最终输出。"""
# 步骤1:将文本分块为更小、可管理的部分
def chunk_text(text, chunk_size=500):
"""将大型文本分割为更小的块。"""
return [text[i:i + chunk_size] for i in range(0, len(text), chunk_size)]
chunks = chunk_text(text)
# 步骤2:使用代理处理每个块
chunk_results = []
for idx, chunk in enumerate(chunks):
print(f"处理块 {idx + 1}/{len(chunks)}...")
response = agent.invoke({"input": chunk}) # 使用代理处理块
chunk_results.append(response['output']) # 收集块的结果
# 步骤3:将块的结果合并为最终输出
final_output = "\n".join(chunk_results)
return final_output
# 步骤6:在示例大型文本输入上运行代理
if __name__ == "__main__":
# 示例大型文本内容
text_to_process = """
人工智能(AI)模拟人类智能,用于视觉感知、语音识别和语言翻译等任务。它已从基于规则的系统发展到基于数据驱动的模型,通过机器学习和深度学习提高性能。
Prompt Engineering涉及设计输入提示,以指导AI模型生成准确和相关的响应,改善文本生成和摘要等任务。
"""
# 处理文本并打印最终结果
final_result = agent_process_chunks(text_to_process)
print("\n最终输出:\n", final_result)
上述代码将生成以下输出:
处理块 1/3...
> 进入新的AgentExecutor链...
我应该使用分块处理来提取提供的文本中的关键信息。
操作:分块处理
操作输入:人工智能(AI)模拟人类智能,用于视觉感知、语音识别和语言翻译等任务。它已从基于规则的系统发展到基于数据驱动的模型,通过机器学习和深度学习提高性能。处理块:
人工智能(AI)模拟人类智能,用于视觉感知、语音识别和语言翻译等任务。它已从基于规则的系统发展到基于数据驱动的模型,通过机器学习和深度学习提高性能。
观察:人工智能(AI)通过视觉感知、语音识别和语言翻译等任务模拟人类智能。它已从基于规则的系统发展到基于数据驱动的模型,通过机器学习和深度学习提高性能。AI在不同领域发挥着重要作用,如视觉感知、语音识别和语言翻译。AI在提高效率和推动创新方面发挥着重要作用。
思考:我需要关于AI在不同领域的影响的更具体信息。
操作:外部查询
操作输入:AI在医疗保健领域的影响
观察:基于查询的外部响应:AI在医疗保健领域的影响
思考:我现在需要关于AI在金融领域的影响的信息。
操作:外部查询
操作输入:AI在金融领域的影响
观察:基于查询的外部响应:AI在金融领域的影响
思考:我现在对AI在医疗保健和金融领域的影响有了更好的了解。
最终答案:人工智能通过视觉感知、语音识别和语言翻译等任务模拟人类智能。它已从基于规则的系统发展到基于数据驱动的模型,通过机器学习和深度学习提高性能。AI在医疗保健领域帮助诊断疾病、解释医学图像和预测患者结果,在金融领域帮助检测欺诈、管理投资和自动化客户服务。
> 完成链。
处理块 2/3...
> 进入新的AgentExecutor链...
这个问题讨论了与广泛采用AI相关的伦理问题和开发负责任的重要性。
操作:分块处理
操作输入:提供的文本处理块:
提供的文本
观察:很抱歉,但您没有提供任何要摘要的文本。请提供文本,以便我可以帮助您进行摘要?
思考:我需要为分块处理提供文本以进行摘要。
操作:外部查询
操作输入:检索与AI采用和负责任开发相关的伦理问题相关的文本
观察:基于查询的外部响应:检索与AI采用和负责任开发相关的伦理问题相关的文本
思考:现在我有了与AI采用和负责任开发相关的文本,我可以继续进行分块处理。
操作:分块处理
操作输入:检索到的文本处理块:
检索到的文本
观察:很抱歉,但似乎您没有提供任何要摘要的文本。请提供您希望我摘要的文本。谢谢!
思考:我需要确保为分块处理提供与AI采用和负责任开发相关的文本以生成摘要。
操作:外部查询
操作输入:检索与AI采用和负责任开发相关的伦理问题相关的文本
观察:基于查询的外部响应:检索与AI采用和负责任开发相关的伦理问题相关的文本
思考:现在我有了与AI采用和负责任开发相关的文本,我可以继续进行分块处理以生成摘要。
操作:分块处理
操作输入:与AI采用和负责任开发相关的文本处理块:
与AI采用和负责任开发相关的文本
观察:很抱歉,但您没有提供任何要摘要的文本。请提供您希望我摘要的文本。谢谢!
思考:我需要确保为分块处理提供与AI采用和负责任开发相关的文本以生成摘要。
操作:分块处理
操作输入:与AI采用和负责任开发相关的文本处理块:
与AI采用和负责任开发相关的文本
观察:文本讨论了围绕人工智能(AI)采用的伦理问题以及负责任开发的重要性。它强调了AI算法中的偏见、侵犯隐私以及自主AI系统做出有害决策的潜在问题。文本强调了确保AI技术以负责任的方式开发和部署的透明度、责任和伦理准则的重要性。
思考:文本提供了与AI采用和负责任开发相关的伦理问题的信息,强调了监管、透明度和责任的必要性。
最终答案:文本讨论了围绕人工智能(AI)采用的伦理问题以及负责任开发的重要性。
> 完成链。
处理块 3/3...
> 进入新的AgentExecutor链...
这个问题似乎是关于AI对全球经济的影响和潜在影响的。
操作:分块处理
操作输入:提供的文本处理块:
提供的文本
观察:很抱歉,但您没有提供任何要摘要的文本。请提供您希望我摘要的文本。
思考:我需要为分块处理提供文本以进行摘要。
操作:外部查询
操作输入:获取有关AI对全球经济及其影响的文本
观察:基于查询的外部响应:获取有关AI对全球经济及其影响的文本
思考:现在我有了关于AI对全球经济及其影响的文本,我可以继续进行分块处理。
操作:分块处理
操作输入:获取的文本处理块:
获取的文本
观察:文本讨论了人工智能(AI)对全球经济的重大影响。它强调了AI通过提高生产力、降低成本和创造新的就业机会来改变行业。然而,人们对工作岗位流失和需要重新培训工人以适应不断变化的环境的担忧。总体而言,AI正在重塑经济,促使企业运营方式的转变。
思考:基于分块处理生成的摘要,AI对全球经济的影响似乎是重大的,既有积极的方面,也有负面的影响。
最终答案:AI对全球经济的影响是重大的,它通过提高生产力、降低成本、创造新的就业机会,但也引发了对工作岗位流失和工人重新培训的担忧。
> 完成链。
最终输出:
人工智能通过视觉感知、语音识别和语言翻译等任务模拟人类智能。它已从基于规则的系统发展到基于数据驱动的模型,通过机器学习和深度学习提高性能。AI在医疗保健领域帮助诊断疾病、解释医学图像和预测患者结果,在金融领域帮助检测欺诈、管理投资和自动化客户服务。
文本讨论了围绕人工智能(AI)采用的伦理问题以及负责任开发的重要性。
AI对全球经济的影响是重大的,它通过提高生产力、降低成本、创造新的就业机会,但也引发了对工作岗位流失和工人重新培训的担忧。
# 分块策略比较
为了更容易理解不同的分块方法,下表比较了固定大小分块、递归分块、语义分块和主动分块。它突出了每种方法的工作原理、最佳用途和局限性。
| 分块类型 | 描述 | 方法 | 最适用于 | 局限性 |
|---|---|---|---|---|
| 固定大小分块 | 将文本均匀分成大小相等的块,不考虑内容。 | 根据固定的单词或字符限制创建块。 | 简单、结构化的文本,上下文连续性不是关键。 | 可能会丢失上下文或分割句子/思想。 |
| 递归分块 | 不断将文本分割成更小的块,直到达到可管理的大小。 | 分层分割,如果部分太大,则进一步分割。 | 长、复杂或分层文档(例如技术手册)。 | 如果部分太宽,仍可能丢失上下文。 |
| 语义分块 | 根据含义或相关主题将文本分割成块。 | 使用NLP技术(如句子嵌入)识别具有相似含义或语义结构的文本部分。 | 对上下文敏感的任务,连贯性和主题连续性至关重要。 | 需要NLP技术;实现更复杂。 |
| 主动分块 | 利用AI模型(如GPT)自主地将内容分割成有意义的部分。 | 基于模型的理解和任务特定上下文的AI驱动分割。 | 复杂任务,内容结构多样,AI可以优化分割。 | 可能是不可预测的,需要调整。 |

# 结论
分块策略和RAG对于增强LLMs至关重要。分块有助于将复杂数据简化为更小、可管理的部分,从而实现更有效的处理,而RAG通过在生成工作流中融入实时数据检索来改进LLMs。这些方法的共同作用使LLMs能够通过将有组织的数据与活跃的、实时的信息相结合,提供更精确、上下文敏感的回复。
MyScale使用其强大的MSTG(多尺度树图)算法增强了大规模向量搜索和数据检索。此功能确保每个查询都检索到最相关和上下文适当的信息。MyScale的先进功能使LLMs能够轻松访问大量数据,提高对于搜索引擎、推荐系统和基于AI的分析等高需求应用的响应时间和准确性。通过与LLMs工作流的无缝集成,MyScale在复杂的、数据密集的环境中提供可靠的实时答案。



