
发现使用检索增强生成(Retrieval Augmented Generation,RAG)的性能提升
大型语言模型(LLM)足够智能,能够理解上下文。无论是天文学、历史还是物理学等主题,它们都可以回答问题,利用其广泛的训练数据提供连贯且与上下文相关的回答。然而,由于它们无法连接各个细节并记住所有细节,尤其是像 llama2-13b-chat 这样的较小模型,在训练数据中存在所需的知识时,可能会产生幻觉。
一种新的技术,检索增强生成(Retrieval Augmented Generation,RAG),通过使用外部数据来填补知识空白,减少幻觉。结合向量数据库(如 MyScale (opens new window)),它在提取式问答系统中显著提高性能,即使在训练集中已经包含了维基百科等详尽的知识库。
因此,本文重点研究了在广泛使用的MMLU数据集上使用RAG的性能提升。我们发现,商业和开源LLM的性能都可以在使用向量数据库从维基百科中检索知识时显著提高。更有趣的是,即使维基百科已经包含在这些模型的训练集中,也可以实现这一结果。
您可以在此处 (opens new window)找到基准测试框架和此示例的代码。
# 检索增强生成
首先,让我们描述一下检索增强生成(RAG)。
研究项目旨在通过将其与外部知识库(如维基百科)、数据库或互联网相结合,增强类似于 gpt-3.5 的LLM,以创建更具知识性和上下文感知的系统。例如,假设用户询问LLM牛顿最重要的成果是什么。为了帮助LLM检索到正确的信息,我们可以搜索牛顿的维基百科,并将维基页面作为上下文提供给LLM。
这种方法被称为检索增强生成(RAG)。Lewis等人在《面向知识密集型自然语言处理任务的检索增强生成》 (opens new window)一文中将检索增强生成定义为:
一种将预训练参数化和非参数化内存结合起来进行语言生成的语言生成模型类型。
此外,该学术论文的作者还指出:
通过通用的微调方法,为预训练的参数化内存生成模型赋予非参数化内存。
注:
参数化内存LLM是像ChatGPT和Google的PaLM这样的大型自我依赖知识存储库。非参数化内存LLM利用外部资源,为参数化内存LLM添加额外的上下文。
将外部资源与LLM结合起来似乎是可行的,因为LLM是良好的学习者,并且参考特定的外部知识领域可以提高真实性。但是,这种组合会带来多大的改进?
RAG系统受到两个主要因素的影响:
- LLM可以从外部上下文中学到多少知识
- 外部上下文的准确性和相关性如何
这两个因素都很难评估。LLM从上下文中获得的知识是隐含的,因此评估这些因素的最实际的方法是检查LLM的回答。然而,评估检索上下文的准确性也是一个棘手的问题。
衡量段落之间的相关性,特别是在问答或信息检索中,可能是一项复杂的任务。相关性评估对于确定给定部分是否包含与特定问题直接相关的信息至关重要。这在涉及从大型数据集或文档中提取信息的任务中尤为重要,例如 WikiHop (opens new window) 数据集。
有时,数据集使用多个注释者来评估段落和问题之间的相关性。使用多个注释者对相关性进行投票有助于减轻个体注释者可能产生的主观性和潜在偏见。这种方法还增加了一层一致性,并确保相关性判断更可靠。
由于所有这些不确定性,我们开发了一个开源的端到端RAG系统评估。该评估考虑了不同的模型设置、检索流水线、知识库选择和搜索算法。
我们希望为RAG系统设计提供有价值的基准,并希望更多的开发人员和研究人员加入我们,共同建立一个全面而系统的基准。更多的结果将帮助我们解开这两个因素,并创建一个更接近实际RAG系统的数据集。
注:
请在GitHub (opens new window)上分享您的评估结果。欢迎提交PR!
# RAG系统的一个简单端到端基准
![]()
在本文中,我们关注在 MMLU(大规模多任务语言理解)数据集 (opens new window)上评估的一个简单基准。该数据集是一个广泛使用的LLM基准 (opens new window),包含许多主题(如历史、天文学和经济学)的多项选择单一答案问题。
我们的目标是找出LLM是否可以通过回答多项选择问题从额外的上下文中学习。
为了实现我们的目标,我们选择了维基百科作为我们的真实来源,因为它涵盖了许多主题和知识领域。我们使用了由 Cohere.ai (opens new window) 在Hugging Face上清理的版本,其中包含34,879,571个段落,属于5,745,033个标题。对这些段落进行详尽的搜索需要相当长的时间,因此我们需要使用适当的ANNS(近似最近邻搜索)算法来检索相关文档。此外,我们使用了MyScale数据库和MSTG向量索引来检索相关文档。
# 语义搜索模型
语义搜索是一个经过深入研究的主题,有许多模型 (opens new window)可用,具有详细的基准 (opens new window)可供参考。当与向量嵌入结合使用时,语义搜索能够识别释义表达、同义词和上下文理解。
此外,嵌入提供了密集和连续的向量表示,可以计算有意义的相关度指标。这些密集的指标捕捉语义关系和上下文,对于评估LLM信息检索任务中的相关性非常有价值。
考虑到上述因素,我们决定使用Hugging Face的 paraphrase-multilingual-mpnet-base-v2 (opens new window) 模型来提取检索任务的特征。该模型是MPNet系列的一部分,旨在生成适用于各种NLP任务(包括语义相似性和检索)的高质量嵌入。
# 大型语言模型(LLMs)
对于我们的LLMs,我们选择了OpenAI的 gpt-3.5-turbo 和 llama2-13b-chat(使用6位量化)。这些模型是商业和开源趋势中最受欢迎的模型。LLaMA2模型通过 llama.cpp (opens new window) 进行了6位量化。我们选择了这种6位量化设置,因为它在不牺牲性能的情况下价格合理。
注:
您也可以尝试其他模型来测试它们的RAG性能。
# 我们的RAG系统
下图描述了如何构建一个简单的RAG系统:
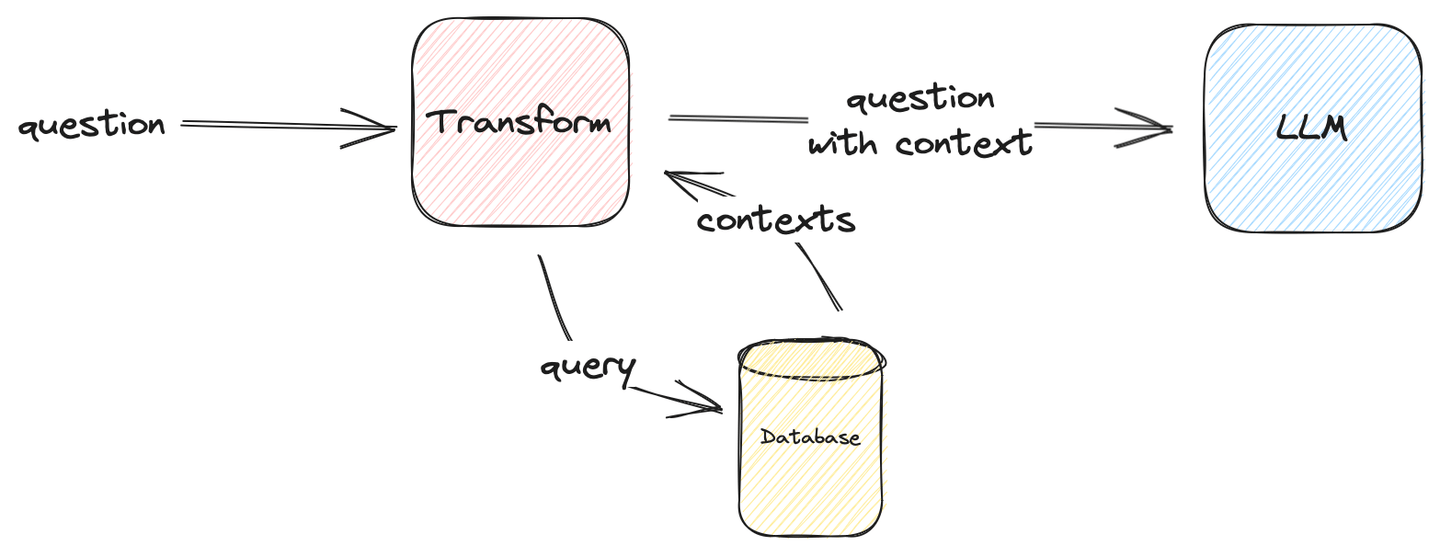
图1:简单的基准 RAG
注:
Transform可以是任何可以输入LLM并返回正确答案的内容。在我们的用例中,Transform将上下文注入到问题中。
我们最终的LLM提示词如下:
template = \
("The following are multiple choice questions (with answers) with context:"
"\n\n{context}Question: {question}\n{choices}Answer: ")
现在让我们进入结果!
# 几个基准测试见解
我们的基准测试结果总结在表1中。
但首先,我们的总结结果如下:
表1:使用不同上下文的检索准确性
| Setup | Dataset | Average | |||||
|---|---|---|---|---|---|---|---|
| LLM | Contexts | mmlu-astronomy | mmlu-prehistory | mmlu-global-facts | mmlu-college-medicine | mmlu-clinical-knowledge | |
| gpt-3.5-turbo | ❌ | 71.71% | 70.37% | 38.00% | 67.63% | 74.72% | 68.05% |
| ✅ (Top-1) | 75.66% (+3.95%) | 78.40% (+8.03%) | 46.00% (+8.00%) | 67.05% (-0.58%) | 73.21% (-1.51%) | 71.50% (+3.45%) | |
| ✅ (Top-3) | 76.97% (+5.26%) | 81.79% (+11.42%) | 48.00% (+10.00%) | 65.90% (-1.73%) | 73.96% (-0.76%) | 72.98% (+4.93%) | |
| ✅ (Top-5) | 78.29% (+6.58%) | 79.63% (+9.26%) | 42.00% (+4.00%) | 68.21% (+0.58%) | 74.34% (-0.38%) | 72.39% (+4.34%) | |
| ✅ (Top-10) | 78.29% (+6.58%) | 79.32% (+8.95%) | 44.00% (+6.00%) | 71.10% (+3.47%) | 75.47% (+0.75%) | 73.27% (+5.22%) | |
| llama2-13b-chat-q6_0 | ❌ | 53.29% | 57.41% | 33.00% | 44.51% | 50.19% | 50.30% |
| ✅ (Top-1) | 58.55% (+5.26%) | 61.73% (+4.32%) | 45.00% (+12.00%) | 46.24% (+1.73%) | 54.72% (+4.53%) | 55.13% (+4.83%) | |
| ✅ (Top-3) | 63.16% (+9.87%) | 63.27% (+5.86%) | 49.00% (+16.00%) | 46.82% (+2.31%) | 55.85% (+5.66%) | 57.10% (+6.80%) | |
| ✅ (Top-5) | 63.82% (+10.53%) | 65.43% (+8.02%) | 51.00% (+18.00%) | 51.45% (+6.94%) | 57.74% (+7.55%) | 59.37% (+9.07%) | |
| ✅ (Top-10) | 65.13% (+11.84%) | 66.67% (+9.26%) | 46.00% (+13.00%) | 49.71% (+5.20%) | 57.36% (+7.17%) | 59.07% (+8.77%) | |
| * 该基准测试使用 MyScale MSTG 作为向量索引 * 该基准测试可以通过我们的 GitHub 进行重现 retrieval-qa-benchmark | |||||||
# 1. 额外上下文通常有帮助
在这些基准测试中,我们比较了有上下文和没有上下文时的性能表现。没有上下文时的测试代表了内部知识如何能解决问题。其次,有上下文时的测试展示了 LLM 如何能从上下文中学习
注:
llama2-13b-chat 和 gpt-3.5-turbo 即使只增加一个额外的上下文,整体性能也都能提升约 3-5%。
表中报告了一些负数,例如将上下文插入到 gpt-3.5-turbo 的 clinical-knowledge 中。
这可能与知识库有关,即维基百科对临床知识的信息不多,或者因为OpenAI的使用条款和指南明确表示强烈不建议使用他们的AI模型进行医疗建议,甚至可能被禁止。尽管如此,增加对于两个模型来说都是相当明显的。
值得注意的是,gpt-3.5-turbo 的结果表明,RAG系统在与其他语言模型竞争时可能非常强大。一些报告的数字,如 prehistory 和 astronomy ,趋向于具有额外标记的 gpt4 的性能,这表明与微调相比,RAG可能是专门的通用人工智能(AGI)的另一种解决方案。
注:
与微调模型相比,RAG更实用,因为它是一种插件解决方案,适用于自托管和远程模型。
# 2. 更多上下文有时有帮助
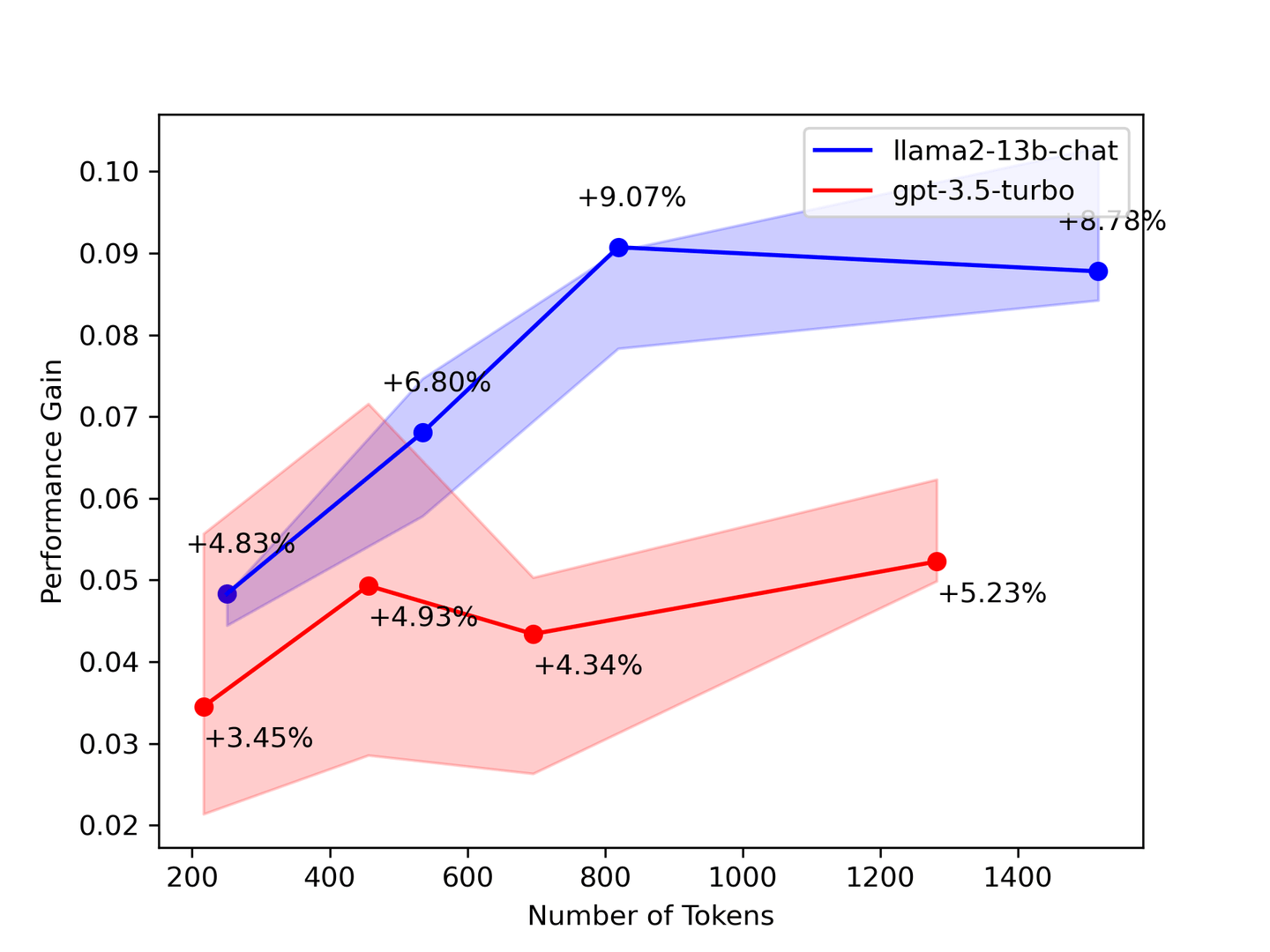
表2: 上下文数量与性能提升
上面的基准测试表明,您需要尽可能多的上下文。在大多数情况下,LLM 将从所有提供的上下文进行学习。理论上,随着检索到的文档数量增加,模型会提供更好的答案。然而,我们的基准测试显示,一些数字随着检索到的上下文越多而下降。
为了验证我们的基准测试结果,斯坦福大学的一篇论文名为:迷失在中间:语言模型如何使用长上下文 (opens new window) 表明 LLM 只关注上下文的开头和结尾。因此,从检索系统中选择更少但更准确的上下文来增强您的 LLM。
# 3. 较小的模型对知识更渴望
LLM越大,存储的知识越多。较大的LLM往往具有更大的存储和理解信息的能力,这通常意味着更广泛的通常理解的事实知识库。我们的基准测试结果也表明了同样的情况:较小的LLM缺乏知识,并且对知识更渴望。
我们的结果报告,llama2-13b-chat 显示的知识增加比 gpt-3.5-turbo 更显著,这表明上下文将更多的知识注入到LLM中以进行信息检索。此外,这些结果暗示 gpt-3.5-turbo 已经获得了它已经知道的信息,而 llama2-13b-chat 仍在从上下文中学习。
# 最后但同样重要的是...
几乎每个LLM都使用维基百科语料库作为训练数据集,这意味着 gpt-3.5-turbo 和 llama2-13b-chat 都应该熟悉添加到提示中的上下文。因此,引发的问题是:
- 这个基准测试中的增加是由于什么原因?
- LLM是否真的通过使用提供的上下文来学习?
- 还是这些额外的上下文有助于回忆从训练集数据中学到的记忆?
我们目前没有对这些问题的答案。因此,仍然需要进行研究。

# 为共同构建RAG基准做出贡献
通过贡献来帮助他人
为了帮助其他人进行研究,我们只能涵盖有限的一组评估。但我们知道还需要更多。每个基准测试的结果都很重要,无论是现有测试的复制还是基于新的RAG的新发现。
为了帮助每个人创建用于测试其RAG系统的基准测试,我们已经开源了我们的端到端基准测试框架 (opens new window)。要分叉我们的存储库,请查看我们的GitHub页面!
该框架包括以下工具:
- 一个通用的分析器,可以测量检索和LLM生成的时间消耗。
- 一个图执行引擎,允许您构建复杂的检索流水线。
- 一个统一的配置,您可以在其中一次性写下所有的实验设置。
您可以创建自己的基准测试。我们相信RAG可以成为AGI的可能解决方案。因此,我们为社区构建了这个框架,以使一切都可以跟踪和可重现。
欢迎提交PR!
# 总结
我们在本文中使用不同的LLM和向量搜索算法构建了一个简单的RAG系统,并在MMLU的一个小子集上进行了评估,并在本文中描述了我们的过程和结果。我们还将评估框架捐赠给了社区,并呼吁进行更多的RAG基准测试。我们将继续进行基准测试,并将最新结果更新到GitHub和MyScale博客中,因此请在 Twitter (opens new window) 上关注我们或加入我们的 Discord (opens new window) 以获取最新信息。



