
RAG (opens new window)的第一步是检索每个查询的多个文档,通常这些文档与查询无关。因此,我们需要一些外部技术来改进这些结果。最终,搜索的强大程度取决于其结果的相关性。
在应用向量搜索时,由于一些原因,常常会丢失一些语义信息。例如,文档需要被分解为较小的子文档,这可能导致上下文信息的丢失。因此,RAG模型可能难以有效地在多个检索到的文档之间建立信息连接。[1]
为了解决这些挑战,我们在RAG框架内使用文档重新排序技术。有多种方法可以用于重新排序检索到的文档。
# 什么是文档重新排序
随着RAG领域的不断发展,重新排序的作用已经成为释放RAG的全部潜力的关键组成部分。重新排序不仅仅是对检索结果的简单重新组织,它是一个战略性过程,可以显著提高呈现给用户的信息的相关性、多样性和个性化程度。
通过利用额外的信号和启发式方法,RAG的重新排序阶段可以对初始的文档检索进行精细化处理,确保最相关和有价值的数据排在前面。此外,重新排序还可以采用迭代的方法,逐步改进结果,以获得更准确和更具上下文的输出。
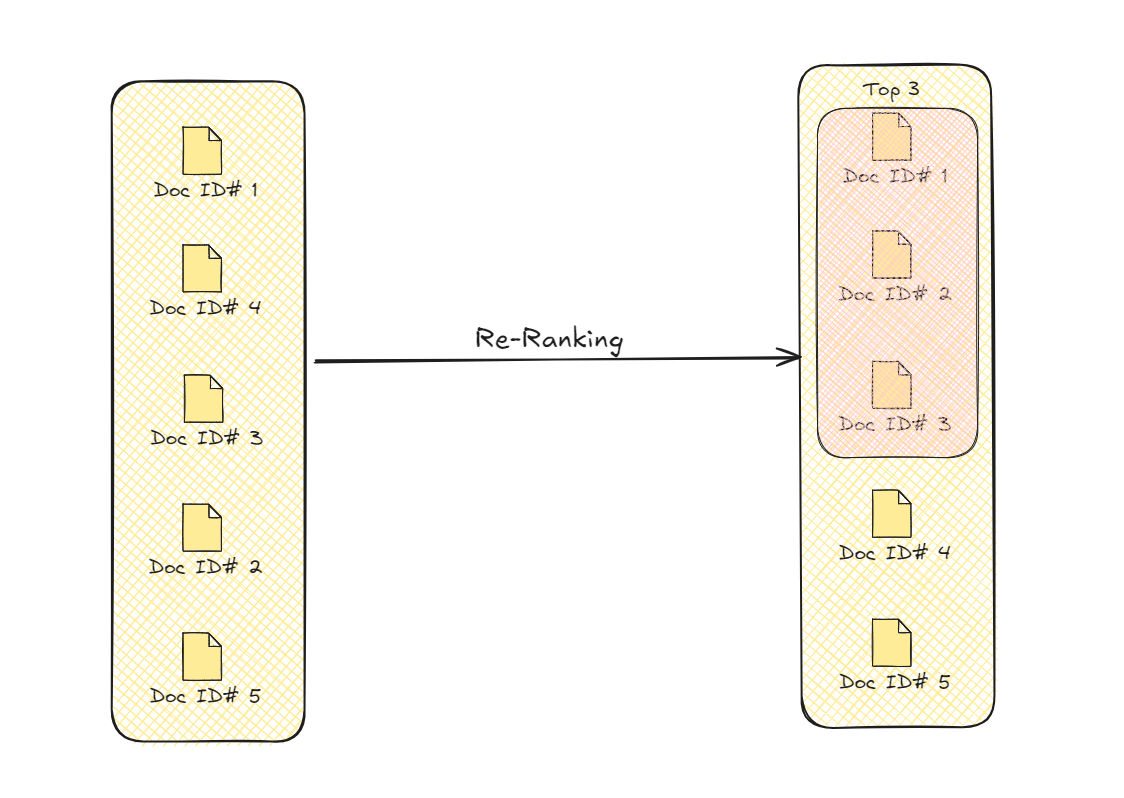
重新排序文档
这个过程通过优先选择与查询更加相关的文档来改进检索结果。这种增强的选择提高了模型用于生成最终输出的信息的整体质量和准确性。
# 使用Transformer进行重新排序
使用Transformer模型 (opens new window)进行文档重新排序甚至在RAG之前就有了历史。2020年,研究人员改编了一个预训练的(seq2seq (opens new window)) Transformer模型用于文档重新排序。[2] 这个系统将文档作为输入,并返回其是否相关。在过滤掉相关文档(即“true”标记)之后,他们使用Softmax (opens new window)作为概率函数对其进行重新排序。
::: 注意注意: 由于这些序列到序列模型也返回一个序列,因此它被修改为仅返回“true”或“false”。 :::
# 使用LLMs
利用LLMs的全能能力来改进RAG在当今已经很常见了[4-7]。
在一种方法中,研究人员使用GPT-3 [4]仅使用提示来执行排序,并将其命名为LRL(使用LLM的列表式重新排序器) (opens new window)。他们使用的提示非常简单。

排序后的重新排序文档
为了增加文档相关性的置信度,还使用了一个提示进行分类,并将其命名为PRL(带有LLM的逐点重新排序器) (opens new window)。

使用LLMs进行重新排序
在更加方法论的方法中[5],使用LLaMA (opens new window)进行文档重新排序。这种方法(RankLLaMA (opens new window))将排序函数应用于检索到的文档:
在应用重新排序函数之后,我们使用InfoNCE损失进一步优化它(我们之前在对比学习的MoCo中 (opens new window)已经见过它)。
# 使用交叉编码器
交叉编码器是另一种常用于文档重新排序的Transformer类型。顾名思义,交叉编码器对查询和(每个)文档进行编码,并输出两者之间的交叉相似性/相关性。

使用交叉编码器进行重新排序
如您所见,不可能将每个文档与查询进行交叉匹配,因此我们会将文档缩小为一个较小的池子进行交叉匹配。有两种常用的预选方法:
- 使用双编码器
- 使用稀疏搜索方法(如BM25)
交叉编码器 (opens new window)在RAG之前就已经表现出比双编码器 (opens new window)更好的性能,因为它们具有更高的精度和改进的上下文理解能力。[6] 它们现在广泛用于RAG的文档重新排序并不令人意外。以下是使用HuggingFace (opens new window)和PyTorch (opens new window)的基本实现。
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
tokenizer = AutoTokenizer.from_pretrained("cross-encoder/ms-marco-TinyBERT-L-6")
model = AutoModelForSequenceClassification.from_pretrained("cross-encoder/ms-marco-TinyBERT-L-6")
def ReRank(query, documents):
scores = []
for doc in documents:
inputs = tokenizer(query, doc, return_tensors="pt", padding=True, truncation=True, max_length=512)
with torch.no_grad():
outputs = model(**inputs)
scores.append(outputs.logits.squeeze().item())
rankedDocs = [doc for _, doc in sorted(zip(scores, documents), reverse=True)]
return rankedDocs
对于一个示例查询,我们可以这样使用它:
query = "哪个月份最适合去巴厘岛旅游?"
# 假设我们的文档在docs变量中作为一个列表。
rankedDocs = ReRank(query, docs)
print(rankedDocs)
# 使用图进行重新排序
如果您是一名学者,可能会使用Litmaps (opens new window)和Connected Papers (opens new window),它们是一些关于语义关系的良好图形示例。在这些图中,文档使用节点表示,而边表示它们的语义关系。
Litmaps和Connected Papers
构建这种文档图后,我们使用GNNs (opens new window)进行消息传递,根据邻居节点更新节点特征。它使模型能够从相关文档提供的上下文中学习,增强其在直接与查询的连接较弱时识别相关内容的能力。
# 抽象意义表示(AMR)
虽然文档图构建和消息传递机制对于GNN用户来说并不陌生,但抽象意义表示(AMR) (opens new window)值得一提。
AMR是句子的语义图表示,抽象地捕捉其意义,重点放在表达的概念及其关系上,而不是句法细节上。与自然语言的一般形式相比,AMR图具有更结构化的语义信息。它在基于图的文档重新排序中特别有用,因为它使得可以将丰富的语义和结构信息编码到重新排序过程中。
# G-RAG
最近提出了一种利用AMR进行RAG重新排序的方法。G-RAG [1] 在他们的设置中,研究人员构建AMR,获取前100个文档,并使用它们构建文档图。G-RAG不使用传统的交叉熵损失,而是使用成对排名损失直接优化相关性排序,这与重新排序的目标更加一致。
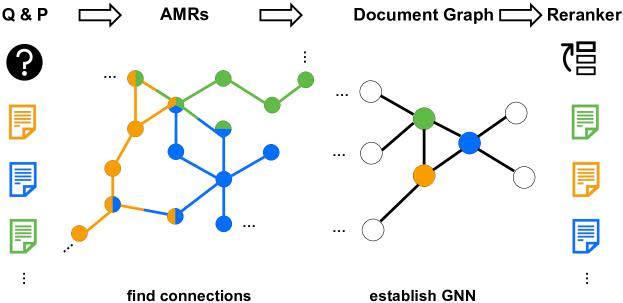
G-RAG
# MyScale的两阶段检索
MyScaleDB使用两阶段检索过程来优化信息检索。该过程包括:
初始检索:使用向量搜索等方法快速检索一组广泛相关的文档。
重新排序:然后使用交叉编码器等先进技术对检索到的文档进行细化和排序,以确保根据用户的查询呈现最相关的结果。
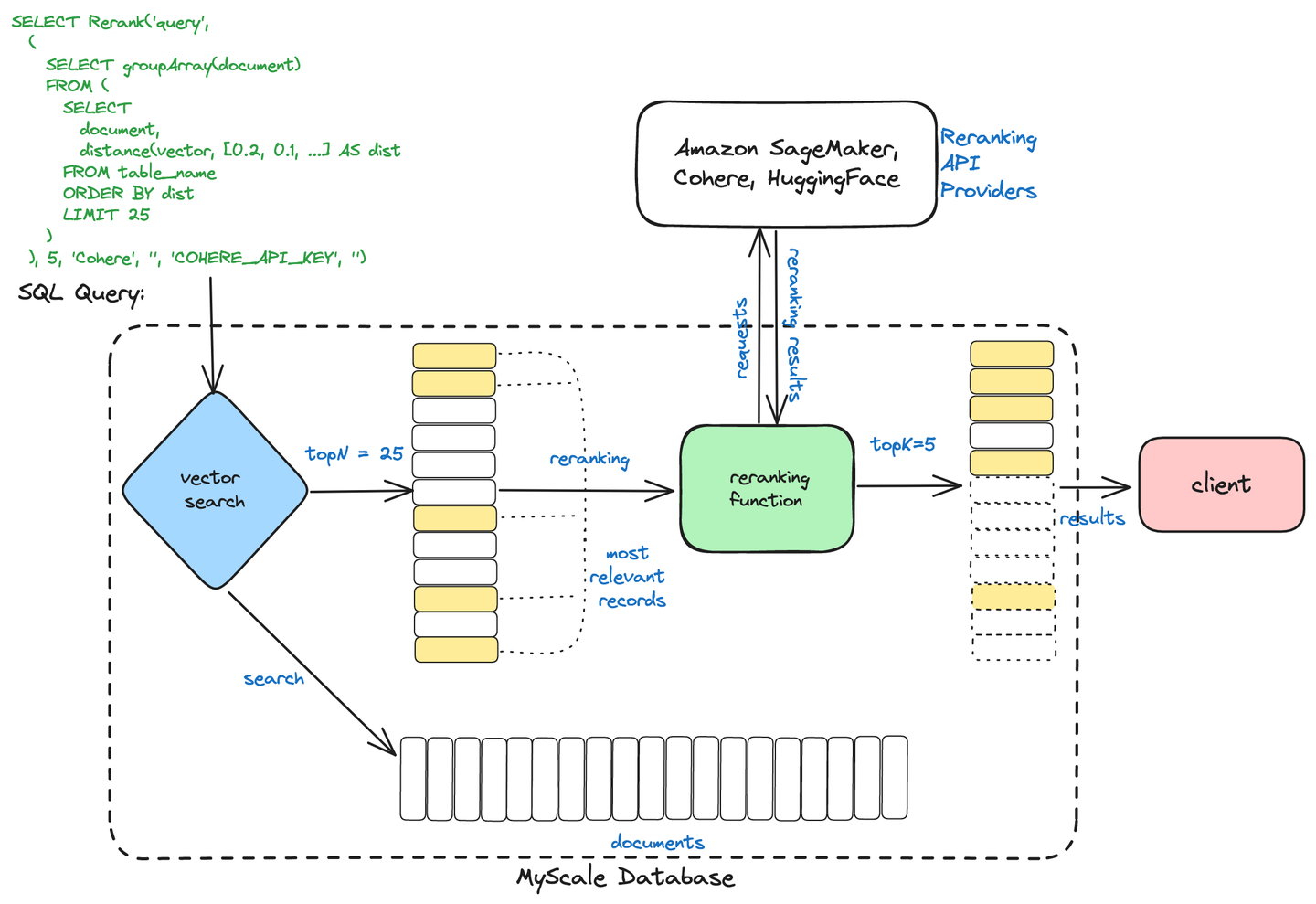
两阶段检索
这种方法通过将高效的检索与精确的排序相结合,帮助MyScaleDB提供更快速、更准确的搜索结果。
::: 注意注意: 您可以在我们的博客中阅读更多关于MyScale的两阶段检索 (opens new window)的内容。 :::
# 使用MyScale和Cohere进行重新排序
我们将通过一个完整的示例来结束。在这个示例中,我们将使用MyScale向量数据库来对RAG流水线中的文档进行重新排序。对于嵌入,我们在这里使用的是Cohere,但也可以使用其他服务,如OpenAI或BedRock。
from langchain_community.vectorstores import MyScale, MyScaleSettings
from langchain_cohere import CohereEmbeddings
config = MyScaleSettings(host='host-name', port=443, username='your-user-name', password='your-passwd')
index = MyScale(CohereEmbeddings(), config)
现在我们将文档添加到MyScale中。在将其添加到数据库之前,需要将其(加载和)拆分。
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
documents = TextLoader("../../file.txt").load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
texts = text_splitter.split_documents(documents)
index.add_documents(texts)
正如我们之前所见,我们需要在应用重新排序之前获取文档的一个子集,所以获取x个文档的子集。
retriever = index.as_retriever(search_kwargs={"k": 20})
query = "地球上离其中心最远的地方是哪里?"
docs = retriever.invoke(query)
现在我们准备进行重新排序。我们将使用Cohere初始化一个语言模型,使用CohereRerank设置重新排序器,并将其与基本检索器组合在ContextualCompressionRetriever中。这个设置会压缩和重新排序检索结果,根据上下文相关性对输出进行细化。
from langchain.retrievers.contextual_compression import ContextualCompressionRetriever
from langchain_cohere import CohereRerank
from langchain_community.llms import Cohere
llm = Cohere(temperature=0)
compressor = CohereRerank()
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"在这里输入您的查询"
)
添加了重新排序器之后,您的RAG系统的响应将变得更加精细,这不仅可以改善用户体验,还可以减少使用的标记数量。

# 结论
RAG的重要性和广泛应用是一个公开的秘密。随着我们对支持检索增强生成(RAG)的先进技术进行深入探索的结束,很明显,这个领域正在快速发展,推动着数据驱动智能的可能性的界限。在本博客系列中,我们深入探讨了查询优化、向量搜索、分块策略、重新排序方法和一系列其他构成现代RAG系统基础的重要组件的复杂性。
通过掌握这些先进概念,您已经获得了解锁RAG项目全部潜力的知识和工具。从优化查询以实现快速检索相关信息,到利用先进的向量索引和搜索能力,您现在具备了构建真正能够改变决策过程的RAG系统的能力。
在您继续前进的过程中,请记住,检索增强生成领域在不断发展。保持警惕,继续学习,并探索像MyScale这样的创新解决方案,帮助您保持领先。数据驱动智能的未来充满希望,通过本博客系列中所获得的知识,您将成为这个令人兴奋的领域的先驱。
如果您想更多地讨论高级RAG技术,请加入我们的Discord (opens new window)与我们交流。
# 参考文献
- Dong, J., Fatemi, B., Perozzi, B., Yang, L. F., & Tsitsulin, A. (2024). Don't Forget to Connect! Improving RAG with Graph-based Reranking. ArXiv. https://arxiv.org/abs/2405.18414
- Nogueira, R., Jiang, Z., & Lin, J. (2020). Document Ranking with a Pretrained Sequence-to-Sequence Model. ArXiv. https://arxiv.org/abs/2003.06713
- Dengrong Huang, Zizhong Wei, Aizhen Yue, Xuan Zhao, Zhaoliang Chen, Rui Li, Kai Jiang, Bingxin Chang, Qilai Zhang, Sijia Zhang, et al. Dsqa-llm: Domain-specific intelligent question answering based on large language model. In International Conference on AI-generated Content, pages 170–180. Springer, 2023.
- Xueguang Ma, Xinyu Zhang, Ronak Pradeep, and Jimmy Lin. Zero-shot listwise document reranking with a large language model. arXiv preprint arXiv:2305.02156, 2023
- Xueguang Ma, Liang Wang, Nan Yang, Furu Wei, and Jimmy Lin. Fine-tuning llama for multi-stage text retrieval. arXiv preprint arXiv:2310.08319, 2023.
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS. https://arxiv.org/abs/2005.11401
- Zhang, L., Zhang, Y., Long, D., Xie, P., Zhang, M., & Zhang, M. (2023). A Two-Stage Adaptation of Large Language Models for Text Ranking. ArXiv. https://arxiv.org/abs/2311.16720
- Cunxiang Wang, Zhikun Xu, Qipeng Guo, Xiangkun Hu, Xuefeng Bai, Zheng Zhang, and Yue Zhang. Exploiting Abstract Meaning Representation for open-domain question answering. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Findings of the Association for Computational Linguistics: ACL 2023, pages 2083–2096, Toronto, Canada, July 2023b. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-acl.131.



