
本文基于 MyScale CEO 在2023年AI大会 (opens new window)上的主题演讲。
# 向量数据库+LLM是构建GenAI应用的关键技术栈
在快速发展的人工智能技术世界中,将大型语言模型(LLM)如 GPT 与向量数据库相结合已成为开发尖端人工智能应用的基础设施技术栈的关键部分。这种创新性的组合使得处理非结构化数据成为可能,为更准确的结果和实时访问最新信息铺平了道路。许多模型,如 OpenAI 的 GPT、Bard、Anthropic 以及开源模型如 LLaMA,已经彻底改变了我们解决问题的方式。
然而,LLM 在实际应用中存在严重的局限性。首先,它们可能缺乏其训练数据之外的特定或最新信息,导致出现所谓的“幻觉”或信息限制现象,即模型生成不正确或奇怪的回应。
尽管微调可以调整LLM的行为,但向量数据库是解决信息限制(或幻觉)的关键,它可以增强模型的知识。这就是为什么LLM + 向量数据库已成为构建生成式人工智能应用的关键技术栈。
# 困境:便利性与向量性能之间的权衡
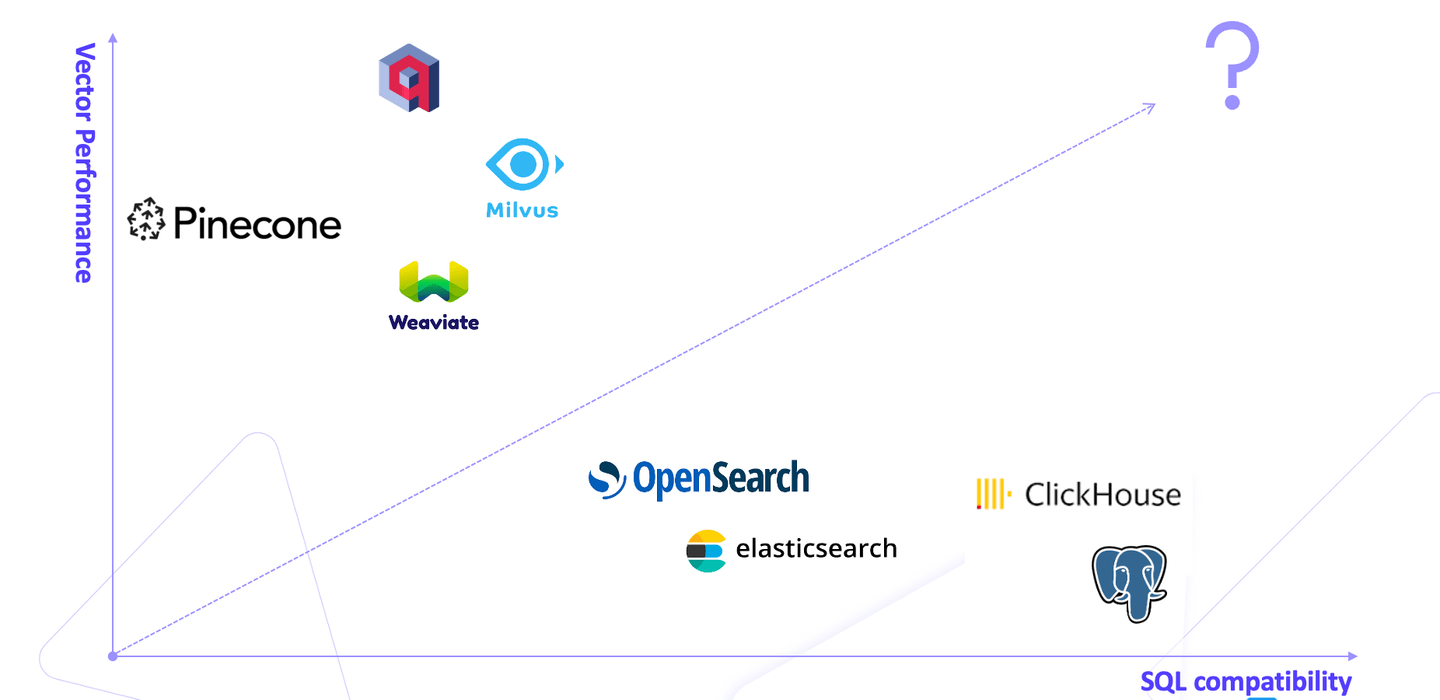
市场上充斥着各种向量数据库,每个数据库都属于以下两个类别之一:专用向量数据库(如Pinecone)提供高向量性能,关系数据库(如PostgreSQL)提供便利性。这使用户陷入两难境地,即在可靠性的关系数据库和高性能向量操作的专用数据库之间进行选择。
想象一下,用户依赖于 PostgreSQL 的便利性和可靠性,但需要进行向量搜索。然而,在 PostgreSQL 和 Pinecone 之间进行接口交互非常不方便和繁琐,导致增加了复杂性和潜在的数据一致性问题。
# 理想解决方案:MyScale - 一种关系向量数据库
这就是MyScale (opens new window)发挥作用的地方,它是一种解决方案,弥合了传统关系数据库和高性能向量数据库之间的差距。与 Milvus、Qdrant 和Weaviate 等专有向量数据库不同,MyScale 基于开源的SQL兼容 ClickHouse 数据库构建,允许用户使用 SQL 运行向量搜索,从而消除了在不同类型的数据库之间切换的不便。
人们普遍认为关系数据库无法提供与向量数据库相匹配的性能。MyScale 打破了这个误解。它为用户面临的这种困境提供了一个平衡、优化和简化的解决方案。它在保留关系数据库所有优点的同时,超越了专用向量数据库的性能。

这只是个开始!
在幕后,MyScale 通过一系列算法和系统工程创新,无缝地集成了结构化数据和向量。与其他依赖 IVF 或 HNSW 作为核心算法的向量数据库不同,我们开发了自己的算法。我们帮助用户以非常高的性能进行向量化和搜索结构化数据和向量嵌入。
# 应用场景:释放MyScale的潜力
现在让我们考虑以下两个使用案例,描述SQL+向量的好处:
# 1. BitCap - MyScale允许用户运行复杂查询
第一个使用案例来自 BitCap,一家知名的数字资产管理公司。他们需要对大量数据进行向量搜索,并在特定数据类型(例如时间戳)上进行过滤。
在这种情况下,数据规模庞大,BitCap 需要能够使用 SQL 语法进行精确的过滤搜索。值得注意的是,不仅向量搜索,对于许多实际应用程序来说,过滤搜索性能也非常关键。此外,BitCap需要支持多种数据类型,包括日期和字符串,以有效满足他们的要求。

此外,BitCap还有其他要求:
- 将我们的解决方案与 Langchain 集成
- 为自查询和其他要求严格的应用程序提供支持
MyScale使他们能够在单个查询中满足所有要求。因此,与其他替代方案相比,MyScale 是 BitCap 的最佳选择,因为它非常易于使用且性能卓越。
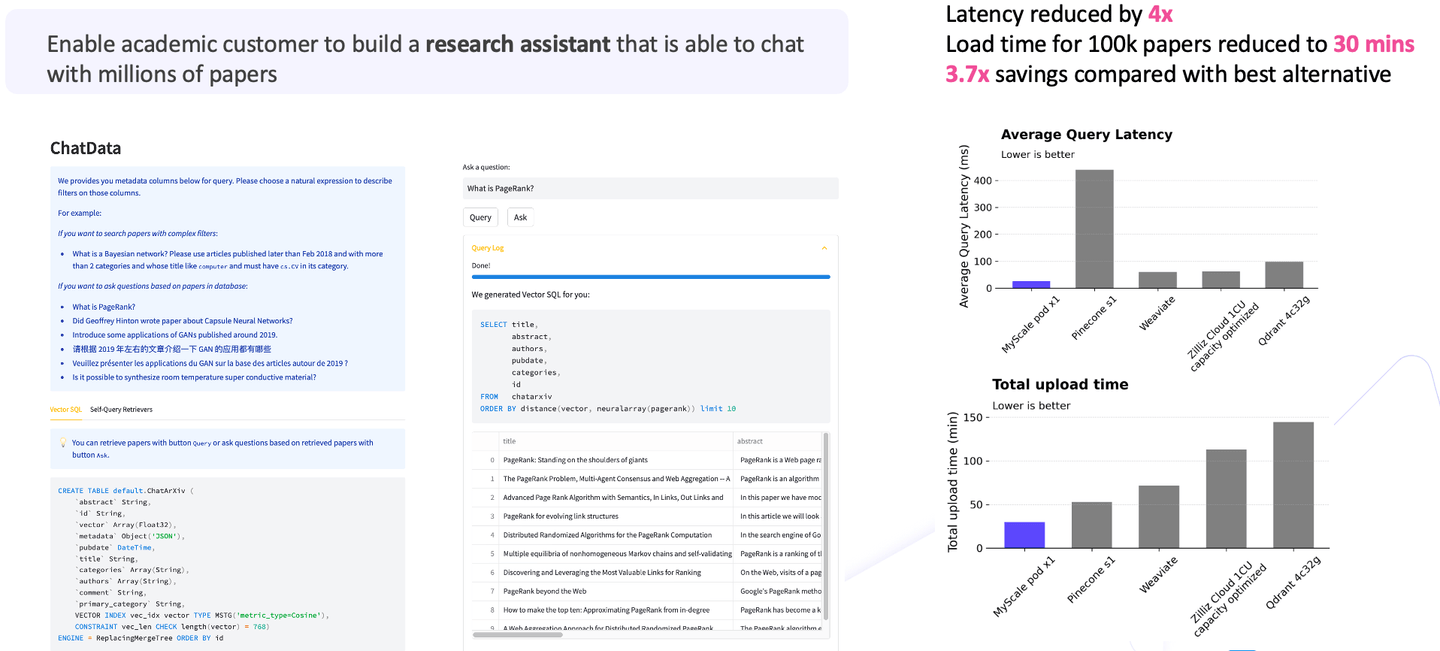
# 2. MyScale帮助学术用户实现最佳的成本效益
在第二个使用案例中,我们帮助学术用户创建了一个能够与数百万篇论文进行对话的研究助手。该场景涉及摄入一百万篇研究论文,并利用这些论文实现问答功能。
鉴于庞大的数据量,如果比较成本,你会发现大型语言模型占总成本的 80% 至 90%。同时,向量搜索是最初需求的重要组成部分。因此,当将向量搜索纳入考虑时,与其他选择相比 (opens new window),MyScale 将延迟降低了4倍,加载时间缩短到30分钟;总体而言,总成本节省超过其他选项的3倍。
从图表中可以看出,MyScale 具有高性能、低延迟和出色的成本效益。在处理大规模应用程序时,这些成就尤为显著。
从这些使用案例中,可以明确地看出,需要一个关系数据库来有效解决这个挑战。并且,为其配备最佳的向量功能将打开无限的可能性。

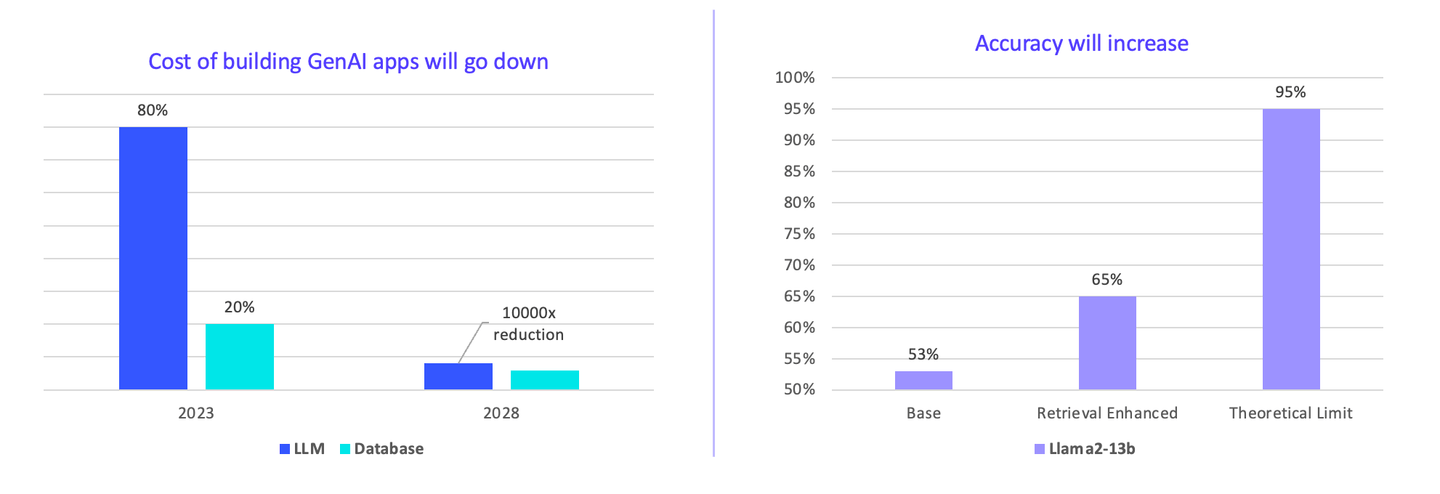
# 性能、成本和质量优化的潜力巨大
我认为企业目前在人工智能方面的开支过高。LLMs 占总成本的 80% 至 90%。然而,在未来,构建应用程序的成本将会降低。我们可以通过共识更快地降低价格。可以看出,成本降低的空间有10000倍。
这是如何实现的?
- 自己托管模型而不使用商业化API可以将成本降低10倍,
- 先进的缓存系统再贡献10倍,
- 其他技术共同贡献100倍。
并不是每个人都知道这些技术。
此外,向量搜索的准确性可能会提高。目前,基础模型是Llama2,通过向量数据库插件,准确性从53%显著提高到65%。
注意:
数据库已经在训练集中,但使用向量数据库可以显著提高性能。
如果使用更大的向量数据库,理论上的极限要高得多。与仅使用 GPU 提供 LLMs 相比,成本要低得多。我们认为这是未来的发展方向。
# 展望未来
SQL+向量关系数据库代表了赋能GenAI应用的一种创新方法。MyScale 弥合了关系数据库和向量数据库之间的差距,提供了便利性和高性能的能力,并证明了关系数据库在向量性能方面可以超越专用数据库,同时保留了SQL的所有优点。通过重新定义可能性和降低成本,MyScale 为 AI 应用打开了比以往更加易于访问和强大的未来。而且,成本降低和准确性提高的空间是巨大的,这是我们前进的方向。 如果您有更多问题或对我们的产品感兴趣,请随时联系我们的Discord (opens new window)或关注MyScale的Twitter (opens new window)。
谢谢!



