
检索增强生成(RAG) (opens new window)在我们与数据交互的方式上进行了革命性的改变,提供了无与伦比的相似性搜索性能。它擅长根据简单查询检索相关信息。然而,当处理更复杂的任务时,如基于时间的查询或复杂的关系数据库查询,RAG往往表现不佳。这是因为RAG主要设计用于从外部源生成带有相关信息的增强文本,而不是执行精确的、基于条件的检索。这些限制限制了它在需要精确和条件化数据检索的场景中的应用。
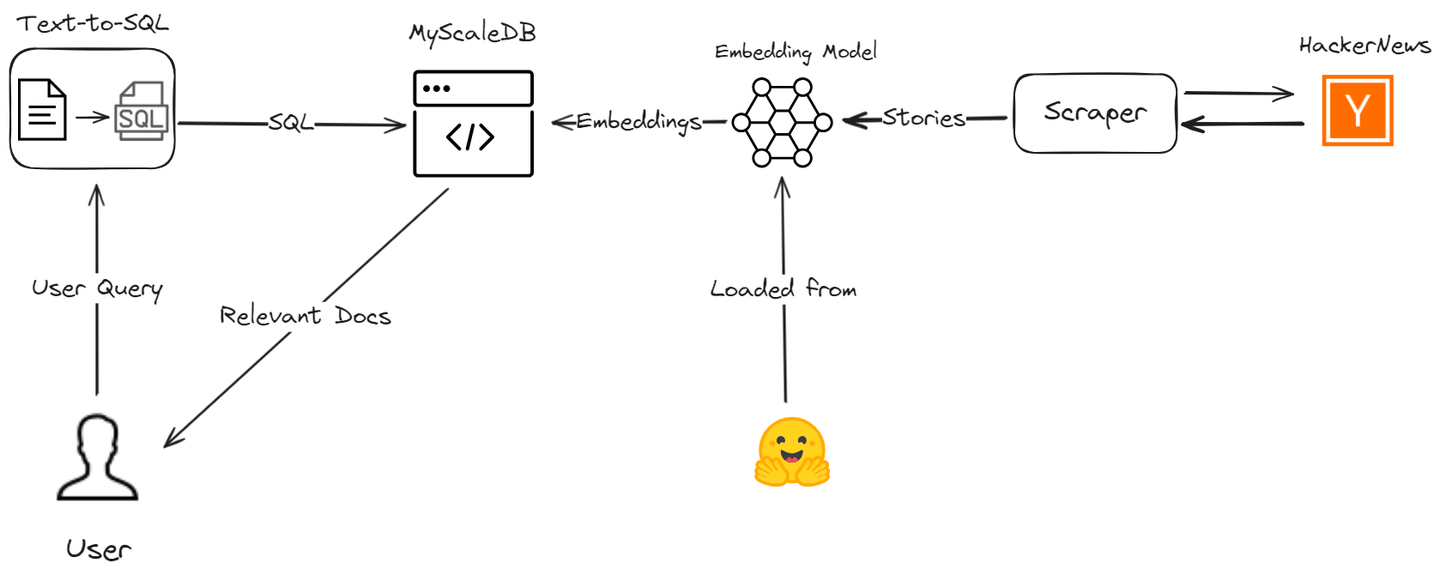
我们基于SQL向量数据库的高级RAG模型将有效地处理各种查询类型。它不仅处理简单的相似性搜索,还擅长处理基于时间的查询和复杂的关系查询。
让我们讨论如何通过使用MyScale和LangChain创建一个AI助手来克服这些RAG限制,从而提高数据检索过程的准确性和效率。我们将从Hacker News上爬取最新的故事,并引导您完成整个过程,以演示如何使用高级SQL向量查询增强您的RAG应用程序。
# 工具和技术
我们将使用多种工具,包括MyScaleDB、OpenAI、LangChain、Hugging Face和HackerNews API来开发这个有用的应用程序。
- MyScaleDB (opens new window):MyScale是一个SQL向量数据库,可以高效地存储和处理结构化和非结构化数据。
- OpenAI (opens new window):我们将使用OpenAI的聊天模型来生成文本到SQL查询。
- LangChain:LangChain将帮助构建工作流,并与MyScale和OpenAI无缝集成。
- Hugging Face (opens new window):我们将使用Hugging Face的嵌入模型来获取文本嵌入,这些嵌入将存储在MyScale中进行进一步分析。
- HackerNews (opens new window) API:此API将获取HackerNews的实时数据进行处理和分析。
# 准备工作
# 设置环境
在编写代码之前,我们必须确保安装了所有必要的库和依赖项。您可以使用pip安装这些库:
pip install requests clickhouse-connect transformers openai langchain
这个pip命令应该安装此项目所需的所有依赖项。
# 导入库并定义辅助函数
首先,我们导入必要的库并定义将用于从Hacker News获取和处理数据的辅助函数。
import requests
from datetime import datetime, timedelta
import pandas as pd
import numpy as np
# 从特定的端点获取故事ID
def fetch_story_ids(endpoint):
url = f'https://hacker-news.firebaseio.com/v0/{endpoint}.json'
response = requests.get(url)
return response.json()
# 根据ID获取特定项的详细信息
def get_item_details(item_id):
item_url = f'https://hacker-news.firebaseio.com/v0/item/{item_id}.json'
item_response = requests.get(item_url)
return item_response.json()
# 递归地获取故事的评论
def fetch_comments(comment_ids, depth=0):
comments = []
for comment_id in comment_ids:
comment_details = get_item_details(comment_id)
if comment_details and comment_details.get('type') == 'comment':
comment_text = comment_details.get('text', '[deleted]')
comment_by = comment_details.get('by', 'Anonymous')
indent = ' ' * depth * 2
comments.append(f"{indent}Comment by {comment_by}: {comment_text}")
if 'kids' in comment_details:
comments.extend(fetch_comments(comment_details['kids'], depth + 1))
return comments
# 将评论列表转换为单个字符串
def create_comment_string(comments):
return ' '.join(comments)
# 将时间限制设置为12小时前
time_limit = datetime.utcnow() - timedelta(hours=12)
unix_time_limit = int(time_limit.timestamp())
这些函数从Hacker News获取故事ID,获取特定项的详细信息,递归地获取故事的评论,并将评论列表转换为单个字符串。
# 获取和处理故事
接下来,我们获取来自Hacker News的最新和热门故事,并对它们进行处理以提取相关数据。
# 获取最新和热门故事的ID
latest_stories_ids = fetch_story_ids('newstories')
top_stories_ids = fetch_story_ids('topstories')
# 获取前20个热门故事
top_stories = [get_item_details(story_id) for story_id in top_stories_ids[:20]]
# 获取过去12小时内的所有最新故事
latest_stories = [get_item_details(story_id) for story_id in latest_stories_ids if get_item_details(story_id).get('time', 0) >= unix_time_limit]
# 准备DataFrame的数据
data = []
def process_stories(stories):
for story in stories:
if story:
story_time = datetime.utcfromtimestamp(story.get('time', 0))
if story_time >= time_limit:
story_data = {
'Title': story.get('title', 'No Title'),
'URL': story.get('url', 'No URL'),
'Score': story.get('score', 0),
'Time': convert_unix_to_datetime(story.get('time', 0)),
'Writer': story.get('by', 'Anonymous'),
'Comments': story.get('descendants', 0) # 正确处理评论数
}
# 获取评论(如果有的话)
if 'kids' in story:
comments = fetch_comments(story['kids'])
story_data['Comments_String'] = create_comment_string(comments)
else:
story_data['Comments_String'] = ""
data.append(story_data)
# 处理最新和热门故事
process_stories(latest_stories)
process_stories(top_stories)
# 创建DataFrame
df = pd.DataFrame(data)
# 确保正确的数据类型
df['Score'] = df['Score'].astype(np.uint64)
df['Comments'] = df['Comments'].astype(np.uint64)
df['Time'] = pd.to_datetime(df['Time'])
我们使用上述定义的辅助函数从Hacker News获取最新和热门故事。我们处理获取的故事以提取标题、URL、分数、时间、作者和评论等相关信息。我们还将评论列表转换为单个字符串。
# 初始化Hugging Face模型以生成嵌入
我们将使用预训练模型生成故事标题和评论的嵌入。这一步对于创建检索增强生成(RAG)系统至关重要。
import torch
from transformers import AutoTokenizer, AutoModel
# 初始化嵌入的分词器和模型
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
# 在创建DataFrame之后生成嵌入
empty_embedding = np.zeros(384, dtype=np.float32) # 假设嵌入大小为384
def generate_embeddings(texts):
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt", max_length=512)
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1)
return embeddings.numpy().astype(np.float32).flatten()
我们使用Hugging Face transformers库加载预训练模型来生成嵌入,并为故事标题和评论生成嵌入。
# 处理长评论
为了处理超过模型最大标记长度的长评论,我们将它们分割成可管理的部分。
# 处理长评论的函数
def handle_long_comments(comments, max_length):
parts = [' '.join(comments[i:i + max_length]) for i in range(0, len(comments), max_length)]
return parts
这个函数将长评论分割成适合模型最大标记长度的部分。
# 处理嵌入的故事
最后,我们处理每个故事,为标题和评论生成嵌入,并创建最终的DataFrame。
# 处理每个故事以生成标题和评论的嵌入,并创建最终的DataFrame
final_data = []
for story in data:
title_embedding = generate_embeddings([story['Title']]).tolist()
comments_string = story['Comments_String']
if comments_string and isinstance(comments_string, str):
max_length = tokenizer.model_max_length # 使用模型的最大标记长度
if len(comments_string.split()) > max_length:
parts = handle_long_comments(comments_string.split(), max_length)
for part in parts:
part_comments_string = ' '.join(part)
comments_embeddings = generate_embeddings([part_comments_string]).tolist() if part_comments_string else empty_embedding.tolist()
final_data.append({
'Title': story['Title'],
'URL': story['URL'],
'Score': story['Score'],
'Time': story['Time'],
'Writer': story['Writer'],
'Comments': story['Comments'],
'Comments_String': part_comments_string,
'Title_Embedding': title_embedding,
'Comments_Embedding': comments_embeddings
})
else:
comments_embeddings = generate_embeddings([comments_string]).tolist() if comments_string else empty_embedding.tolist()
final_data.append({
'Title': story['Title'],
'URL': story['URL'],
'Score': story['Score'],
'Time': story['Time'],
'Writer': story['Writer'],
'Comments': story['Comments'],
'Comments_String': comments_string,
'Title_Embedding': title_embedding,
'Comments_Embedding': comments_embeddings
})
else:
story['Title_Embedding'] = title_embedding
story['Comments_Embedding'] = empty_embedding.tolist()
final_data.append(story)
# 创建最终的DataFrame
final_df = pd.DataFrame(final_data)
# 确保最终DataFrame中的正确数据类型
final_df['Score'] = final_df['Score'].astype(np.uint64)
final_df['Comments'] = final_df['Comments'].astype(np.uint64)
final_df['Time'] = pd.to_datetime(final_df['Time'])
在这一步中,我们处理每个故事,为标题和评论生成嵌入,如果需要,处理长评论,并使用所有处理后的数据创建最终的DataFrame。
# 连接到MyScaleDB并创建表
MyScaleDB是一个高级SQL向量数据库,通过高效处理复杂查询 (opens new window)和全文搜索(https://myscale.com/blog/zh/text-search-and-hybrid-search-in-myscale/)以及过滤向量搜索(https://myscale.com/blog/zh/optimizing-filtered-vector-search/)等相似性搜索,增强了RAG模型。
我们将使用clickhouse-connect连接到MyScaleDB,并创建一个表来存储爬取的故事。
import clickhouse_connect
client = clickhouse_connect.get_client(
host='your-host',
port=443,
username='your-username',
password='your-password'
)
client.command("DROP TABLE IF EXISTS default.posts")
client.command("""
CREATE TABLE default.posts (
id UInt64,
Title String,
URL String,
Score UInt64,
Time DateTime64,
Writer String,
Comments UInt64,
Title_Embedding Array(Float32),
Comments_Embedding Array(Float32),
CONSTRAINT check_data_length CHECK length(Title_Embedding) = 384
) ENGINE = MergeTree()
ORDER BY id
""")
这段代码导入clickhouse-connect库,并使用提供的凭据连接到MyScaleDB。如果存在,它会删除现有的default.posts表,并创建一个具有指定模式的新表。
注意:MyScaleDB提供了一个免费的向量存储Pod,可以存储500万个向量。因此,您可以在RAG应用程序中开始使用MyScaleDB,而无需进行任何初始付款。
# 插入数据并创建向量索引
现在,我们将处理后的数据插入到MyScaleDB表中,并创建一个索引以实现高效的数据检索。
batch_size = 20 # 根据您的需求进行调整
num_batches = len(final_df) // batch_size
for i in range(num_batches):
start_idx = i * batch_size
end_idx = start_idx + batch_size
batch_data = final_df[start_idx:end_idx]
client.insert("default.posts", batch_data, column_names=['Title', 'URL', 'Score', "Time",'Writer', 'Comments','Title_Embedding','Comments_Embedding'])
print(f"Batch {i+1}/{num_batches} inserted.")
client.command("""
ALTER TABLE default.posts
ADD VECTOR INDEX photo_embed_index Title_Embedding
TYPE MSTG
('metric_type=Cosine')
""")
这段代码以批处理方式将数据插入到default.posts表中,以有效地处理大量数据。在Title_Embedding列上创建向量索引。
# 设置查询生成的提示模板
我们设置一个提示模板,将自然语言查询转换为MyScaleDB SQL查询。
prompt_template = """
您是一个MyScaleDB专家。根据输入的问题,首先创建一个语法正确的MyScaleDB查询来运行,然后查看查询的结果并返回输入问题的答案。
MyScaleDB查询具有一个名为`DISTANCE(column, array)`的向量距离函数,用于计算与用户问题的相关性并按相关性对特征数组列进行排序。`DISTANCE(column, array)`函数只接受数组列作为其第一个参数,并将`Embeddings(entity)`作为其第二个参数。您还需要一个名为`Embeddings(entity)`的用户定义函数来检索实体的数组。
当查询要求根据某个关键字(例如“AI领域”或“批评”)获取最接近的行时,您必须使用此距离函数计算到向量列中实体的距离,并按距离排序以检索相关行。如果问题涉及时间限制(例如“过去7小时”),请使用`today()`函数获取当前日期和时间。
如果问题指定了要获取的示例数量,请使用该数字;否则,使用LIMIT子句查询最多{top_k}个结果,根据MyScale的规定。仅在必要时按照距离函数进行排序。不要查询表中的所有列;仅查询回答问题所需的列,并将每个列名用双引号(")括起来以将其标识为定界符标识符。
在构建查询时,请注意以下步骤:
1. 确定输入问题中的关键字(例如“最受欢迎的文章”,“过去7小时”,“AI领域”)。
2. 将关键字映射到特定的查询组件(例如“最受欢迎”映射到“Score DESC”)。
3. 如果问题涉及与关键字的相关性,请使用距离函数。否则,使用标准的SQL子句。
4. 如果问题明确提到标题或评论,请相应地计算距离。默认情况下,使用标题计算距离。
5. 使用`Embeddings(keyword)`获取关键字的嵌入,并仅在查询涉及关键字相关性搜索时在`DISTANCE`函数中使用它们。
6. 确保在明确提到评论时考虑评论列。
7. 在没有找到任何距离的查询中不要使用dist,并确保在计算了距离的其他列中使用按dist排序。
示例问题及其处理方式:
1. “在过去7小时内,最受欢迎的文章是什么?”
- 提取关键字:“最受欢迎的文章”,“过去7小时”。
- 将“最受欢迎的”映射到“Score DESC”。
- 构建查询以获取过去7小时内最受欢迎的文章:
- `SELECT DISTINCT "Title", "URL", "Score", DISTANCE("Title_Embedding", Embeddings('AI领域')) FROM posts1 WHERE Time >= today() - INTERVAL 7 HOUR ORDER BY Score DESC LIMIT {top_k}`
2. “给我一些人们在批评内容的评论。”
- 提取关键字:“评论”,“批评”。
- 将“批评”映射到DISTANCE函数。
- 构建查询以获取相关评论:
- `SELECT DISTINCT "Comments", "Score", DISTANCE("Comments_Embedding", Embeddings('批评')) as dist FROM posts1 ORDER BY dist LIMIT {top_k}`
3. “在过去6小时内,最受欢迎的故事是什么?”
- 提取关键字:“最受欢迎的故事”,“过去6小时”。
- 将“最受欢迎的”映射到“Score DESC”。
- 构建一个简单的查询以获取过去6小时内最受欢迎的故事:
- `SELECT DISTINCT "Title", "URL", "Score" FROM posts1 WHERE Time >= today() - INTERVAL 6 HOUR ORDER BY Score DESC LIMIT {top_k}`
4. “AI领域中的热门故事有哪些?”
- 提取关键字:“热门故事”,“AI领域”。
- 将“热门”映射到“Score DESC”。
- 构建查询以获取AI领域中的热门故事:
- `SELECT DISTINCT "Title", "URL", "Score", DISTANCE("Title_Embedding", Embeddings('AI领域')) as dist FROM posts1 ORDER BY dist,Score DESC LIMIT {top_k}`
5. “给我一些讨论最新LLM趋势的评论。”
- 提取关键字:“评论”,“最新LLM趋势”。
- 将“最新LLM趋势”映射到DISTANCE函数。
- 构建查询以获取讨论最新LLM趋势的评论:
- `SELECT DISTINCT "Comments", "Score", DISTANCE("Comments_Embedding", Embeddings('最新LLM趋势')) as dist FROM posts1 ORDER BY dist LIMIT {top_k}`
现在,让我们根据提供的输入创建查询。
======== 表信息 ========
{table_info}
问题:{input}
SQL查询:"
从查询中删除\n、\、"或任何类型的冗余字母,并小心不要查询不存在的列。
"""
def generate_final_prompt(input, table_info, top_k=5):
final_prompt = prompt_template.format(input=input, table_info=table_info, top_k=top_k)
return final_prompt
这段代码设置了一个提示模板,指导LLM根据输入的问题生成正确的MyScaleDB查询。
# 设置查询参数
我们设置查询生成的参数。
top_k = 5
table_info = """
posts1 (
id UInt64,
Title String,
URL String,
Score UInt64,
Time DateTime64,
Writer String,
Comments UInt64,
Title_Embedding Array(Float32),
Comments_Embedding Array(Float32)
)
"""
这段代码设置要检索的前k个顶级结果(top_k),定义表信息(table_info),并为问题设置一个空的输入字符串(input)。
# 设置模型
在这一步中,我们将设置OpenAI模型,将用户输入转换为SQL查询。
from langchain.chat_models import ChatOpenAI
model = ChatOpenAI(openai_api_key="open-ai-api-key")
# 将文本转换为SQL
这个方法首先根据用户输入和表信息生成最终的提示,然后使用OpenAI模型将文本转换为SQL向量查询。
def get_query(user_input):
final_prompt = generate_final_prompt(user_input, table_info, top_k)
response_text = model.predict(final_prompt)
return response_text
user_input="What are the most voted stories?"
response=get_query(user_input)
在这一步之后,我们将得到一个查询,类似于:
'SELECT DISTINCT "Title", "URL", "Score", DISTANCE("Title_Embedding", Embeddings(\'AI领域\')) as dist FROM posts1 ORDER BY dist, Score DESC LIMIT 5'
但是MyScaleDB的DISTANCE函数期望的是DISTANCE(column, array)。因此,我们需要将查询字符串中的Embeddings(\'AI领域\')部分转换为向量嵌入。
# 处理和替换查询字符串中的嵌入
这个方法将用于将Embeddings(“提取的关键字”)替换为一个float32数组。
import re
def process_query(query):
pattern = re.compile(r'Embeddings\(([^)]+)\)')
matches = pattern.findall(query)
for match in matches:
processed_embedding = str(list(generate_embeddings(match)))
query = query.replace(f'Embeddings({match})', processed_embedding)
return query
query=process_query1(f"""{response}""")
这个方法接受查询作为input,如果查询字符串中存在Embeddings方法,则返回更新后的查询。

# 执行查询
最后,我们执行查询,从向量数据库中检索相关的故事。
query=query.replace("\n","")
results = client.query(f"""{query}""")
for row in results.named_results():
print("Title ", row["Title"])
此外,您可以获取模型返回的查询,提取指定的列,并像上面那样使用它们来获取列。然后,可以将这些结果传递回聊天模型,创建一个完整的AI聊天助手。这样,助手可以根据直接从结果中提取的相关数据动态响应用户查询,确保无缝交互体验。
# 结论
简单的RAG由于其专注于简单的相似性搜索而具有有限的用途。然而,当与MyScaleDB、LangChain等高级工具结合使用时,RAG应用程序不仅可以满足,而且可以超越大规模大数据管理的需求。它们可以处理更广泛的查询,包括基于时间的查询和复杂的关系查询,显著提高当前系统的性能和效率。
如果您有任何建议,请通过Twitter (opens new window)或Discord (opens new window)与我们联系。



