
向量技术使我们能够超越耗时耗资源的传统学习方式,并使用更加快速且高效的简单搜索。向量数据库非常适合存储高维向量数据,例如数值、文本或图像数据。像 MyScale 这样的 SQL 向量数据库,借助 SQL 的强大功能以及 MSTG 索引等出色特性,使用户无需担忧复杂的数据处理和其他后端操作。
Amazon Bedrock (opens new window) 是一项托管服务,允许我们使用基础模型(包括文本和图像)构建 AI 应用程序。它提供了诸如 AWS 的可扩展性、允许私下微调模型等优势,可以像使用 Scikit-learn 或 NLTK 等常规 Python 库一样轻松调用。这些服务。
本文演示了如何使用 Amazon Bedrock 和 MyScale (opens new window) 构建电子书的语义搜索应用程序。传统的电子阅读器(例如 Acrobat Reader、Kindle、Apple Books 或其他阅读器)通常将搜索限制为精确的关键字匹配。利用 Amazon Bedrock 的基础模型生成 embedding 向量以及 MyScale 的向量数据库功能,我们可以创建更智能的搜索功能,实现基于语义理解的检索,而不仅仅局限于关键词匹配。通过结合 Bedrock 的 AI 模型和 MyScale 的高效存储及搜索能力,用户可以在各种应用场景中增强文本搜索的有效性,从而提升整体用户体验。
# 安装所需库
首先,我们需要创建一个 Python 虚拟环境并安装相关库,这里我们使用 Conda 为项目创建一个环境:
conda create --name AWS python=3.12
激活环境后,我们将安装相应的库:
pip install boto3 langchain-aws clickhouse-connect
# 连接 MyScale
登录 MyScale 后,可以在控制台 (opens new window)上运行集群并获取连接字符串。然后使用以下代码连接到数据库:
import clickhouse_connect
client = clickhouse_connect.get_client(
host='your-host-name-here',
port=443,
username='your-user-name-here',
password='your-password-here')
注意:
有关更详细的分步说明,您可以按照快速入门指南 (opens new window)获取连接详细信息。
# 测试连接
为了测试连接和库的安装情况,我们可以创建一个示例表:
# 创建一个包含 128 维浮点向量的表。
client.command("""
CREATE TABLE default.TestTable (
id UInt32,
data Array(Float32),
CONSTRAINT check_length CHECK length(data) = 128,
date Date,
label Enum8('person' = 1, 'building' = 2, 'animal' = 3)
)
ORDER BY id
""")
#['0', 'chi-msc-af209a77-msc-af209a77-0-0', 'OK', '0', '0']
# 获取并打印当前数据库中所有表的名称。
res = client.query("SHOW TABLES").named_results()
print([r['name'] for r in res])
# ['TestTable']
# 选择合适的 Embedding 模型
接下来,我们需要选择合适的 embedding 模型。连接 Amazon Bedrock 有两种方法:一是通过 AWS 官网创建 IAM 用户,另一种是直接使用 MyScale 的 EmbedText 函数,后者提供了一种更快捷的方式来调用 Bedrock。
# 连接 Amazon Bedrock
Amazon Bedrock 是 AWS 的众多服务之一。它托管了许多用于构建生成式 AI 应用程序的基础模型。RAG 是 Bedrock 的专业领域之一。选择 Bedrock 的一些原因包括:
- AWS 托管:AWS 的托管服务质量出色,可以忽略扩展性、安全性、正常运行时间等问题。
- 简单 API:API 使用起来非常简单。
- 按需付费:无需购买大型托管计划,可根据需求灵活付费。
# 账户创建
首先,需要创建一个 IAM 用户(在本例中为 bedrock_test)来使用 Bedrock。
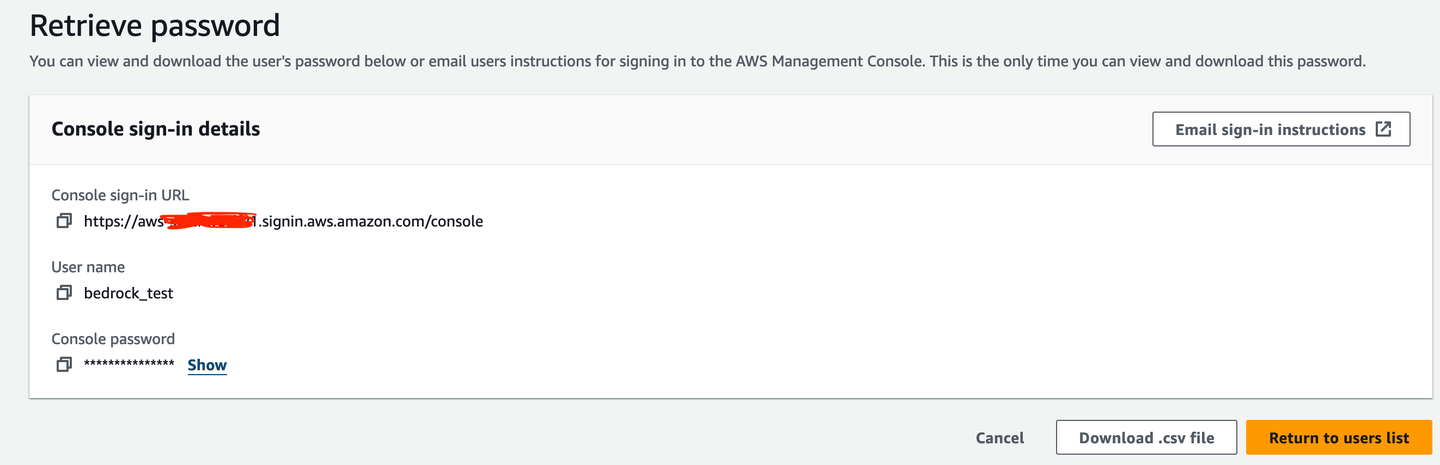
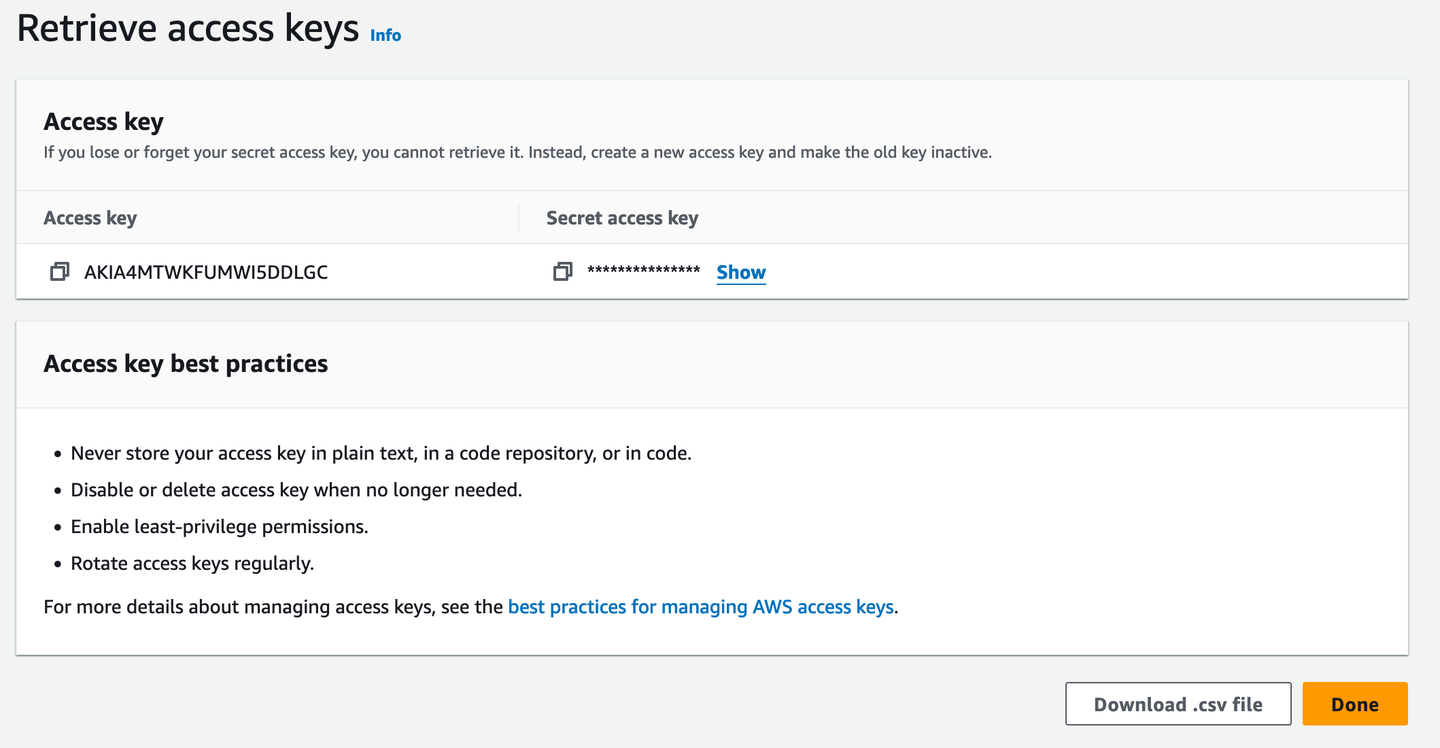
然后,获取一个访问密钥以进行终端访问。

最好将其下载为 .csv 文件,以防忘记访问密钥。
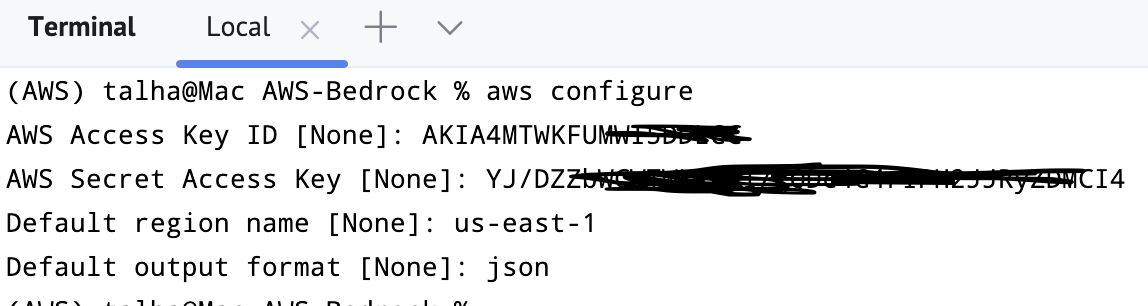
可以通过在终端中键入 aws configure 来验证它。它将询问凭据、默认输出格式和区域。
# Python API
使用以下代码连接 Bedrock 服务,通常我们会选择 us-east-1 地区:
import boto3
bedrockInterface = boto3.client(service_name="bedrock-runtime", region_name='us-east-1')
运行成功,这意味着 Bedrock 客户端/接口已安装和配置。到目前为止,一些准备工作已经完成:
- 设置并连接 MyScale
- 设置并连接 Bedrock
# 选择模型
在实现基于 embedding 模型的语义搜索之前,需要选择合适的模型。与通常需要时间并立即授予的数据请求不同,对于模型的访问,请转到侧边栏的底部找到相应的选项。
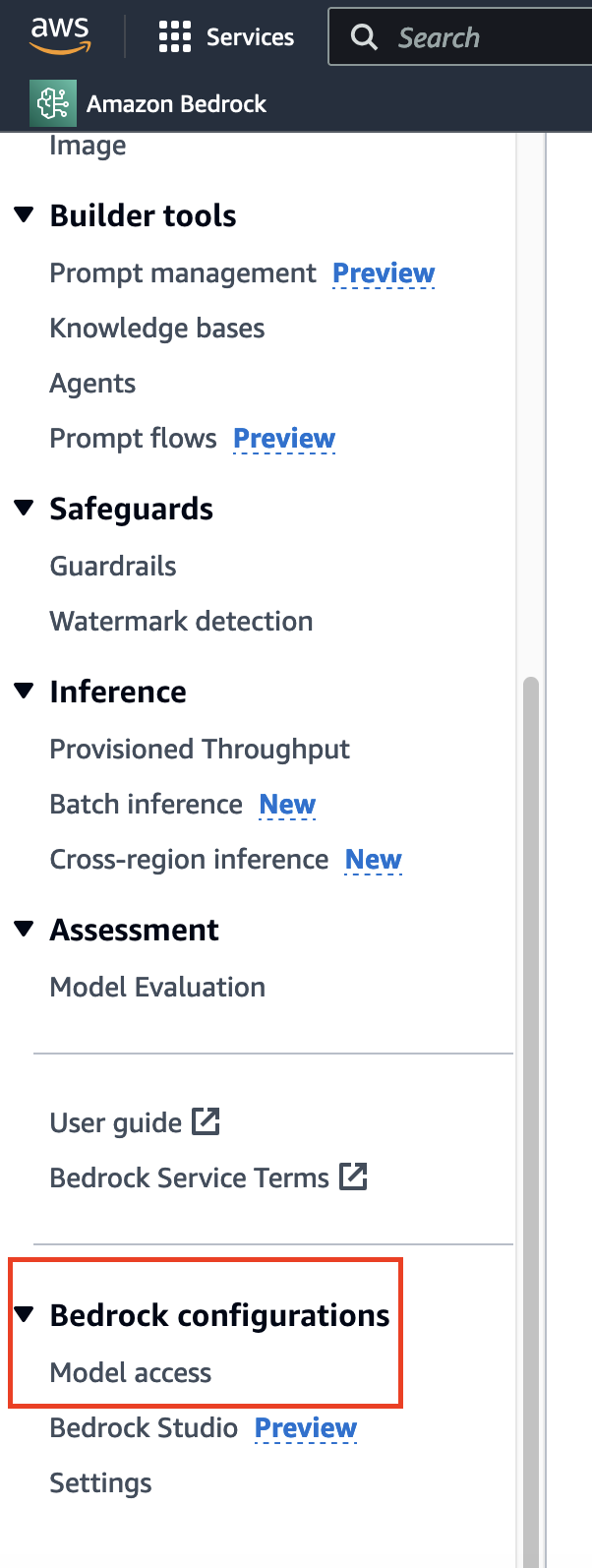
在这里,我们已经获得了访问权限,因此会看到大多数模型的“访问已授予”。如果是第一次使用它,你可以单击“修改模型访问权限”并启用对相应模型的访问权限。

注意:
某些模型的可用性取决于你选择的区域。
# 使用 Titan Embedding 模型
在本教程中,我们使用 Titan Embeddings (opens new window) 模型。首先,应用我们刚刚创建的客户端/接口的 invoke_model() 方法来使用该模型。由于我们已将 JSON 指定为操作模式,因此我们必须确保输入和输出均采用此格式。
import json
query = "Why number 42 is so significant in the literature?"
query_json = json.dumps({
"inputText": query,
})
现在可以调用 invoke_model()。如我们所见,输出是一个字典。
output = bedrockInterface.invoke_model(modelId="amazon.titan-embed-text-v1", body=query_json)
# 输出
{'ResponseMetadata': {'RequestId': 'dcbcb135-8b6b-4da4-adbd-523c8c240da6',
'HTTPStatusCode': 200,
'HTTPHeaders': {'date': 'Wed, 18 Sep 2024 03:05:53 GMT',
'content-type': 'application/json',
'content-length': '17180',
'connection': 'keep-alive',
'x-amzn-requestid': 'dcbcb135-8b6b-4da4-adbd-523c8c240da6',
'x-amzn-bedrock-invocation-latency': '68',
'x-amzn-bedrock-input-token-count': '12'},
'RetryAttempts': 0},
'contentType': 'application/json',
'body': <botocore.response.StreamingBody at 0x151b1c880>}
为了解码 body,我们再次使用 JSON 加载器。
# 输出
{'embedding': [-0.35351562,
-0.3203125,
-0.083496094,
0.04711914,
0.0034332275,
0.24902344,
-0.13183594,
-4.798174e-06,
-0.28320312,
.
.
.
0.7890625,
...],
'inputTextTokenCount': 12}
LangChain 提供了一个更简单的类 BedrockEmbeddings可以直接使用上面定义的 bedrockInterface。
from langchain_aws import BedrockEmbeddings
embeddingOutput = BedrockEmbeddings(client=bedrockInterface)
BedrockEmbeddings 包含许多方法。其中一个是 embed_query(),它接受一个文本字符串并返回 embedding 。由于我们使用的是 Titan 模型,因此应该预期长度为 1536 的 embedding 向量。
x = embeddingGenerator.embed_query("How is it going?")
len(x)
# 1536
# 在 MyScale 中保存 Embedding
现在我们可以开始将文本内容及其 embedding 存储在 MyScale 中了。首先,创建一个用于存储文本和嵌入向量的表:
client.command(""" CREATE TABLE IF NOT EXISTS BookEmbeddings (
id UInt64,
sentences String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 1536
) ENGINE = MergeTree()
ORDER BY id;
""")
# MyScale 的 EmbedText 功能
MyScale 提供了内置的 EmbedText (opens new window) 函数,可以直接调用多种 API,例如 Bedrock、Hugging Face、Open AI 等,来计算文本的 embedding 向量,并且可以作为用于计算文本输入嵌入的直接接口。比如,我们执行以下查询:
SELECT EmbedText('Call me Ishmael. Some years ago—never mind how long precisely—having little or no money in my purse, and nothing particular to interest me on shore, I thought I would sail about a little and see the watery part of the world.', 'Bedrock', '', 'xxxxxxxx', '{"model":"amazon.titan-embed-text-v1", "region_name":"us-east-1", "access_key_id":"xxxxxx"}')
由于它是一个标量函数,因此我们得到了这个直接输出。

现在,每次我们调用此函数时,除输入文本外的所有参数都是相同的。因此,我们可以自定义一个函数来封装 EmbedText 的常用参数:
CREATE FUNCTION EmbedTest AS (x) -> EmbedText(x, 'Bedrock', '', 'xxxx', '{"model":"amazon.titan-embed-text-v1", "region_name":"us-east-1", "access_key_id":"xxxxx"}')
# 生成电子书的 Embedding
以托尔斯泰的经典小说《安娜·卡列尼娜》 (opens new window)为例,我们可以从 Gutenberg (opens new window) 网站获取原文,并将其按章节分割后生成 embedding 向量:
import requests
url = "<https://www.gutenberg.org/files/1399/1399-0.txt>"
response = requests.get(url)
if response.status_code == 200:
bookText = response.content.decode('utf-8-sig')
start = bookText.find("CHAPTER I")
end = bookText.find("End of the Project Gutenberg EBook")
bookText = bookText[start:end]
chapters = re.split(r'(Chapter \\d+)', book_text)
splitChapters = ["".join(x) for x in zip(chapters[1::2], chapters[2::2])]
embeddingsMatrix = [embeddingGenerator.embed_query(chapter) for chapter in splitChapters]
import pandas as pd
df = pd.DataFrame({
'Text': splitChapters,
'Embedding': embeddingsMatrix
})
df_records = df.to_records(index=True)
client.insert("BookEmbeddings", df_records.tolist(), column_names=["id", "sentences", "embeddings"])
数据已成功插入,我们可以在 SQL 工作区(在 MyScale 控制台上)中确认。
# 索引
为了提高检索效率,我们可以为 embedding 向量创建索引:
client.command("""
ALTER TABLE BookEmbeddings
ADD VECTOR INDEX dist_idx embeddings
TYPE MSTG
""")
应用此索引可能需要一些时间(取决于数据)。
# 使用 MyScale 搜索小说
现在,我们可以利用 MyScale 的向量搜索功能,根据语义进行文本检索。例如,查找与“Levin's brother”最相关的章节:
query = "What happened to Levin's brother?"
queryEmbeddings = embeddingGenerator.embed_query(query)
results = client.command(f"""
SELECT id, sentences, embeddings,
distance(embeddings, {queryEmbeddings}) as dist
FROM BookEmbeddings
ORDER BY dist LIMIT 3
""")
在以下结果中,可以看到这 3 个章节与解决查询最相关。

再举一个例子,查找与“When Dolly went to meet Anna at her home?”最相关的章节:
query = "When Dolly went to meet Anna at her home?"
query_embeddings = embeddingGenerator.embed_query(query)
results = client.command(f"""
SELECT id, sentences, embeddings,
distance(embeddings, {query_embeddings}) as dist
FROM BookEmbeddings
ORDER BY dist LIMIT 3
""")
同样,从输出结果中可以看出向量搜索在检索方面做得非常好。

如果你想尝试不同度量标准,可以删除现有索引并添加余弦相似度索引。
query = "When Dolly went to meet Anna at her home?"
query_embeddings = embeddingGenerator.embed_query(query)
results = client.command(f"""
SELECT id, sentences, embeddings,
distance(embeddings, {query_embeddings}) as dist
FROM BookEmbeddings
ORDER BY dist LIMIT 3
""")

# 结论
使用 Amazon Bedrock 和 MyScale 进行向量搜索比大多数电子阅读器中传统的基于关键字的搜索有了明显的改进。借助语义搜索,即使用户不记得确切的术语,也可以找到相关内容,从而使阅读体验更加流畅。虽然此示例侧重于单部小说,但此方法可以应用于各种文本,从其他书籍到法律文件或官方文件。
值得注意的是,这里演示的整个过程都是使用 MyScale 的免费套餐完成的,该免费试用的版本提供了充足的资源用于测试和复现结果。通过结合 Bedrock 的 AI 模型的优势和 MyScale 高效的存储和搜索功能,用户可以在各种应用程序中更有效地处理文本搜索。



