
在数据库开发的早期阶段,数据存储在基本表中。这种方法很简单,但随着数据量的增长,管理和检索信息变得越来越困难和缓慢。然后引入了关系数据库,提供了更好的存储和处理数据的方式。
关系数据库中的一个重要技术是索引,它与图书馆存储图书的方式非常相似。与查找整个图书馆不同,您可以直接找到所需书籍所在的特定部分。数据库中的索引以类似的方式工作,加快了查找所需数据的过程。
在本博客中,我们将介绍向量索引的基础知识以及使用不同技术实现的方法。
# 什么是向量嵌入
向量嵌入只是从图像、文本和音频转换而来的数值表示。简单来说,针对每个项目创建一个单独的数学向量,捕捉该项目的语义或特征。这些向量嵌入更容易被计算系统理解,并与机器学习模型兼容,以理解不同项目之间的关系和相似性。
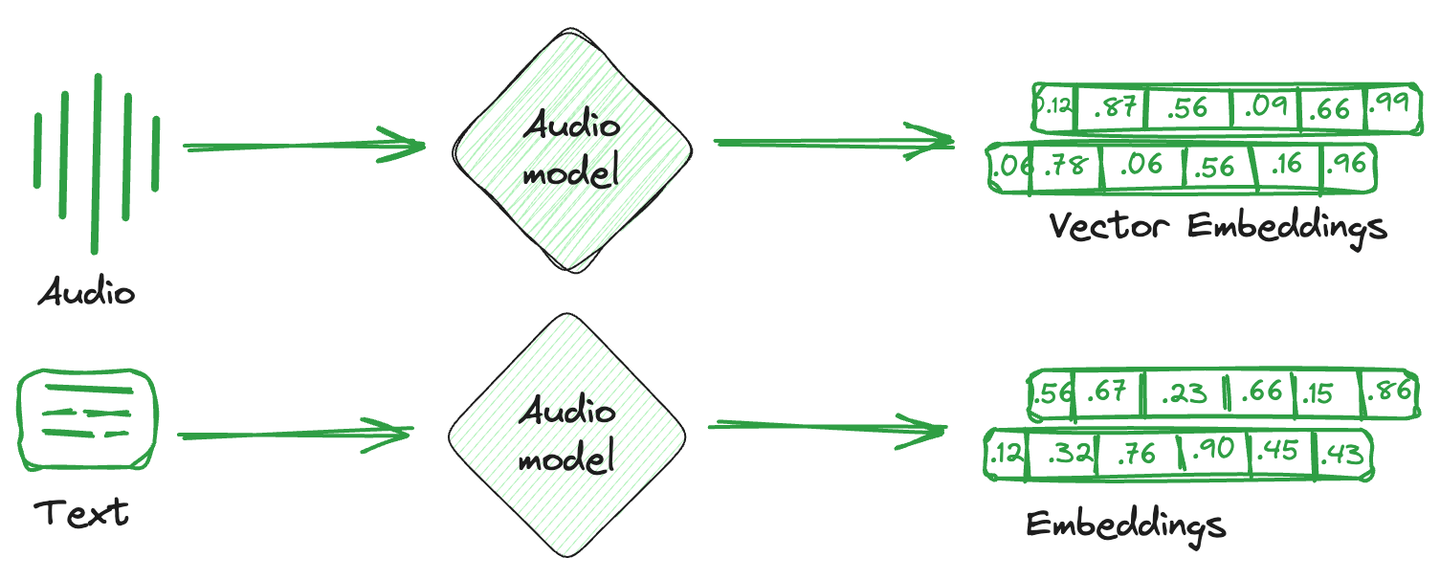
用于存储这些嵌入向量的数据库称为向量数据库。这些数据库利用嵌入的数学属性,将相似的项目存储在一起。使用不同的技术来将相似的向量存储在一起,将不相似的向量分开。这些就是向量索引技术。
# 什么是向量索引
向量索引不仅仅是存储数据,还涉及智能地组织向量嵌入以优化检索过程。这种技术涉及先进的算法,以可搜索和高效的方式整齐地排列高维向量。这种排列不是随机的,而是以一种将相似向量分组在一起的方式进行的,通过向量索引可以快速准确地进行相似性搜索和模式识别,特别适用于搜索大型和复杂的数据集。
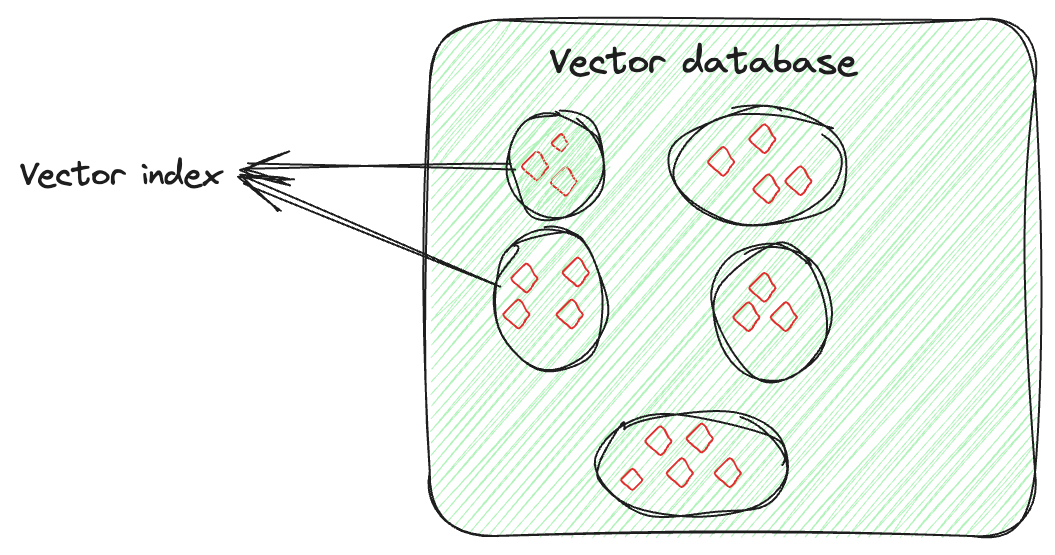
假设您对每个图像都有一个向量,捕捉其特征。向量索引将这些向量组织起来,使得更容易找到相似的图像(这里)。您可以将其想象为将每个人的图像分开组织。因此,如果您需要从特定事件中找到某个人的照片,您只需浏览该人的集合,很容易找到图像。
# 常见的向量索引技术
根据具体要求使用不同的索引技术。让我们讨论其中一些。
# 倒排文件(IVF)
这是最基本的索引技术。它使用K-means聚类等技术将整个数据分成多个簇。数据库中的每个向量都分配给特定的簇。这种结构化的向量排列使用户能够更快地进行搜索查询。当出现新的查询时,系统不会遍历整个数据集。相反,它会识别最近或最相似的簇,并在这些簇中搜索特定的文档。
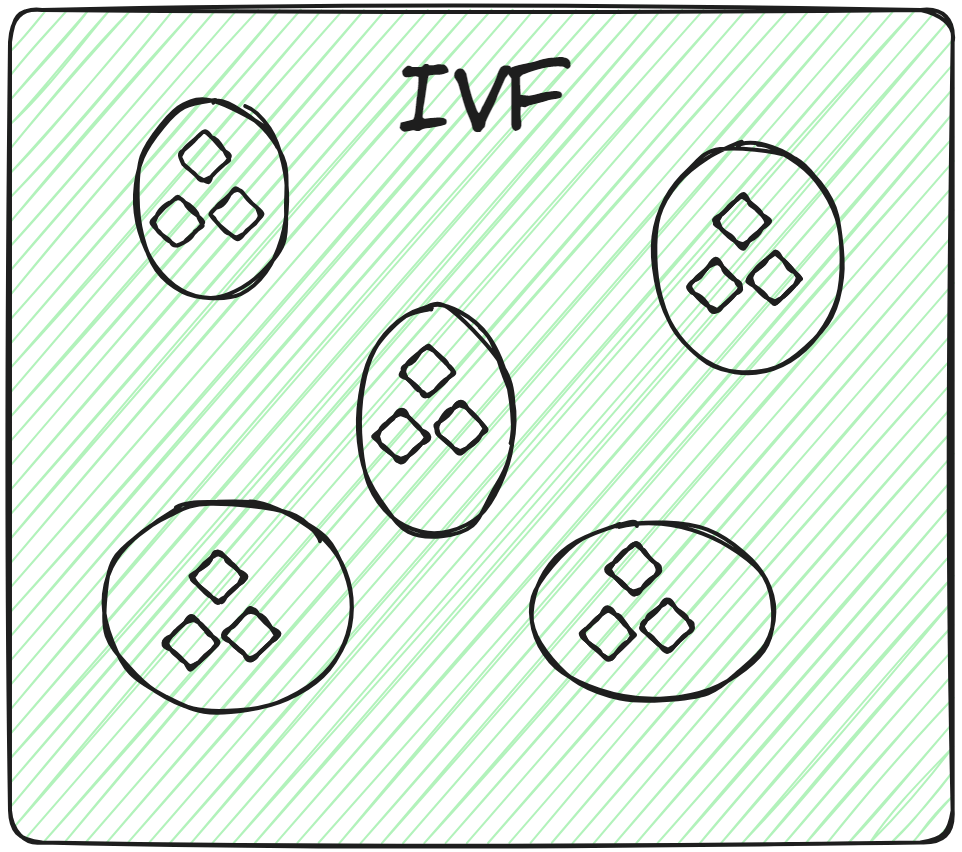
因此,仅在相关簇内部进行蛮力搜索,而不是在整个数据库中进行搜索,不仅提高了搜索速度,还大大减少了查询时间。
# IVF的变体:IVFFLAT、IVFPQ和IVFSQ
根据应用的具体要求,使用不同的IVF变体。让我们详细讨论一下。
# IVFFLAT
IVFFLAT (opens new window)是IVF的简化形式。它将数据集分成簇,但在每个簇内部,它使用平坦结构(因此称为“FLAT”)来存储向量。IVFFLAT旨在优化搜索速度和准确性之间的平衡。
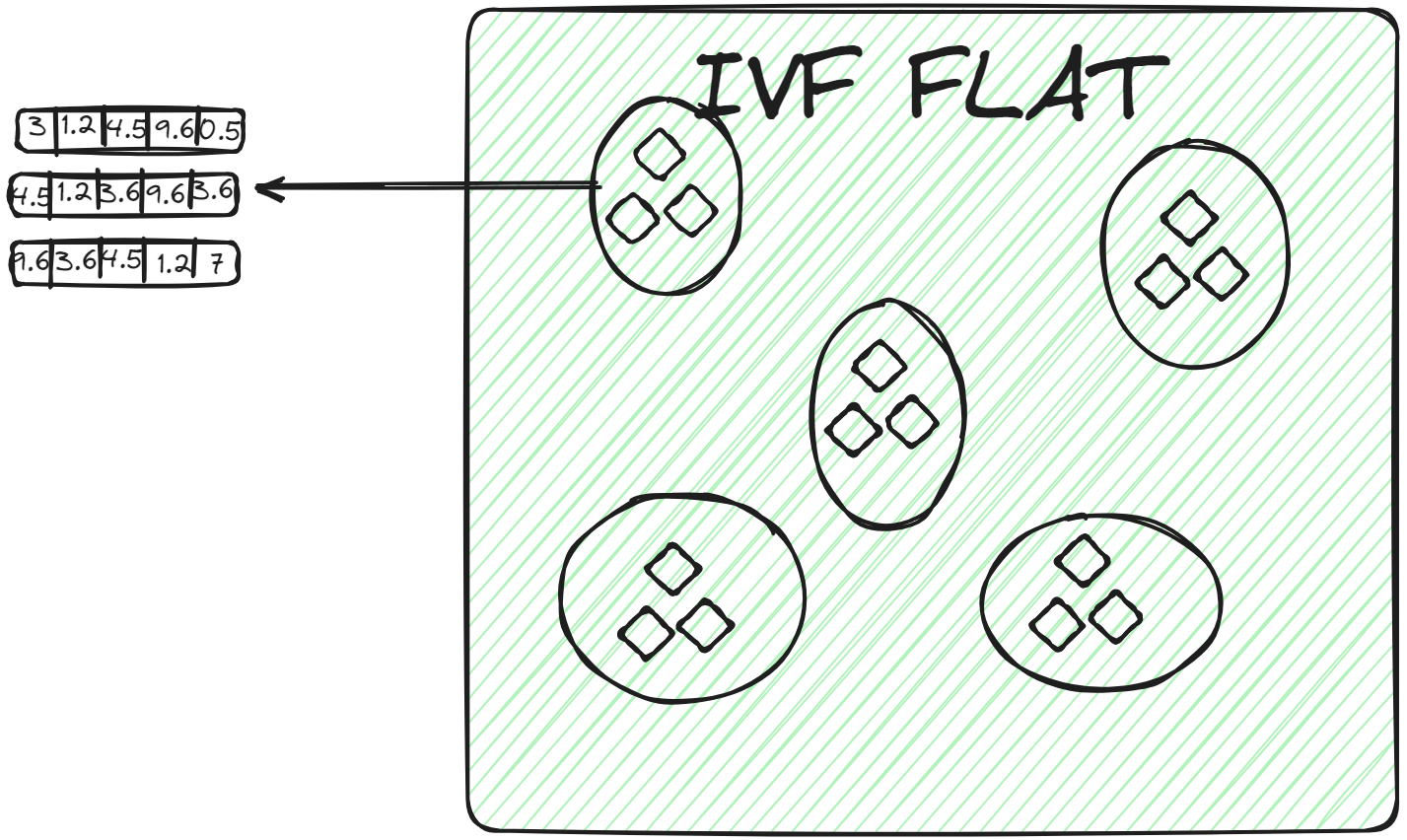
在每个簇中,向量以简单的列表或数组的形式存储,没有额外的细分或分层结构。当将查询向量分配给一个簇时,通过进行蛮力搜索,在簇的列表中检查每个向量,并计算其与查询向量的距离,找到最近的邻居。IVFFLAT用于数据集不是非常大且搜索过程需要高准确性的场景。
# IVFPQ
IVFPQ (opens new window)是IVF的高级变体,代表带有产品量化的倒排文件。它也将数据分成簇,但是每个簇中的向量被分解为较小的向量,并且每个部分使用产品量化进行编码或压缩。
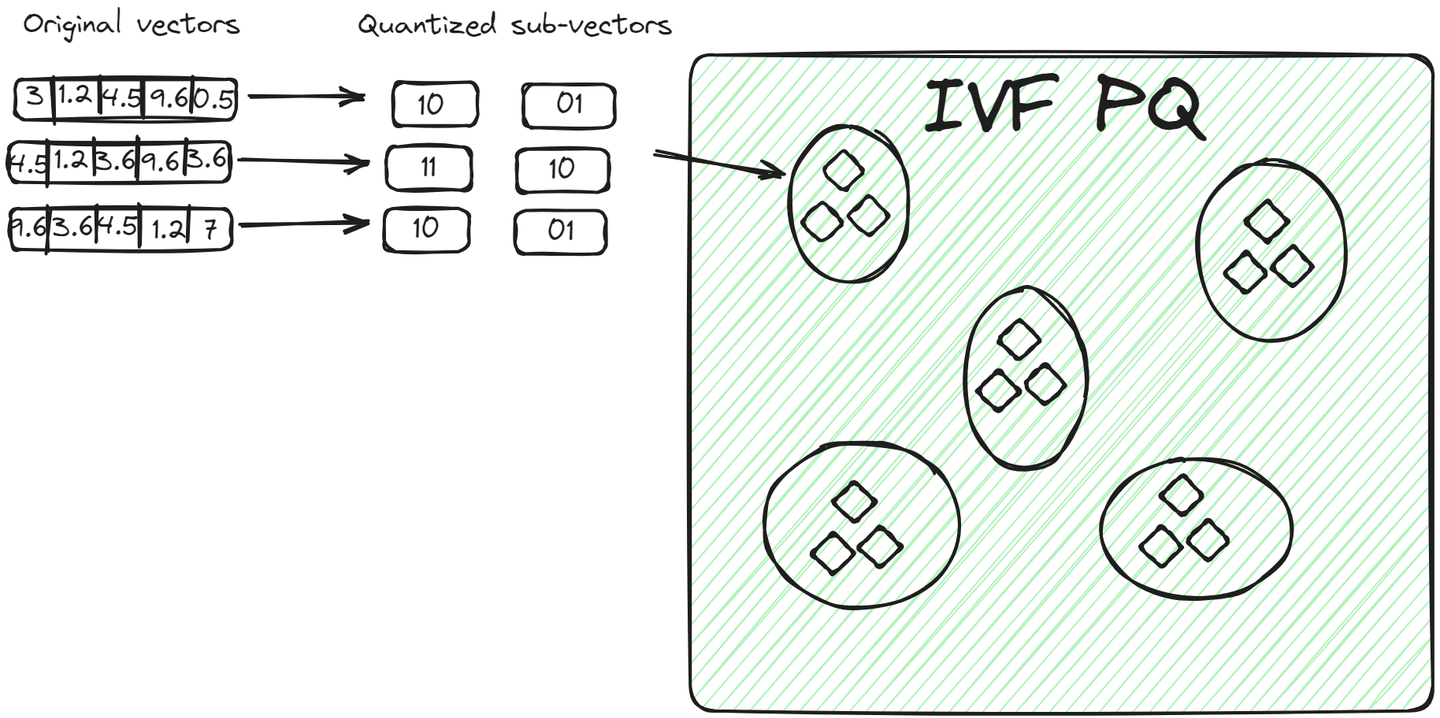
对于查询向量,一旦确定了相关簇,算法会将查询的量化表示与簇内向量的量化表示进行比较。由于通过量化实现了降维和减小了尺寸,所以这种比较比比较原始向量更快。 与前一种方法相比,这种方法有两个优点:
- 向量以紧凑的方式存储,占用的空间比原始向量少。
- 查询过程更快,因为它不比较所有原始向量,而是比较编码向量。
# IVFSQ
带有标量量化的文件系统(IVFSQ) (opens new window)与其他IVF变体一样,也将数据分成簇。然而,其主要区别在于其量化技术。在IVFSQ中,每个簇中的每个向量都经过标量量化处理。这意味着将向量的每个维度单独处理。
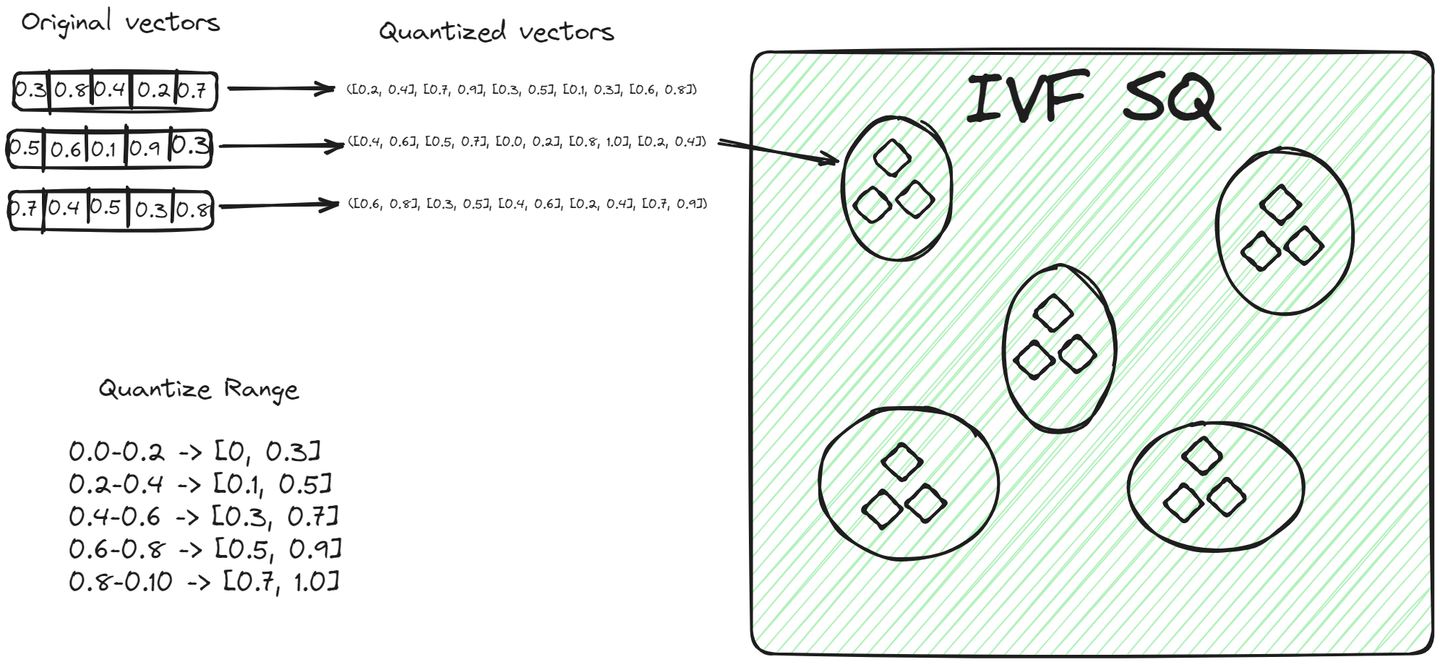
简单来说,对于向量的每个维度,我们设置一个预定义的值或范围。这些值或范围有助于确定向量属于哪个簇。然后,将向量的每个分量与这些预定义的值进行匹配,以确定其在簇中的位置。这种将每个维度分解和量化的方法使得过程更加简单。对于低维数据特别有用,因为它简化了编码并减少了存储所需的空间。
# HNSW 算法
HNSW (opens new window) 算法是一种高效存储和获取数据的复杂方法。它的图形结构受到两种不同技术的启发:概率跳表和可导航小世界(NSW)。
为了更好地理解HNSW,让我们首先尝试理解与该算法相关的基本概念。
# 跳表
跳表是一种高级数据结构,结合了链表的快速插入能力和数组的快速检索特性。它通过多层结构实现,其中数据在多个层次上组织,每个层次包含数据点的子集。
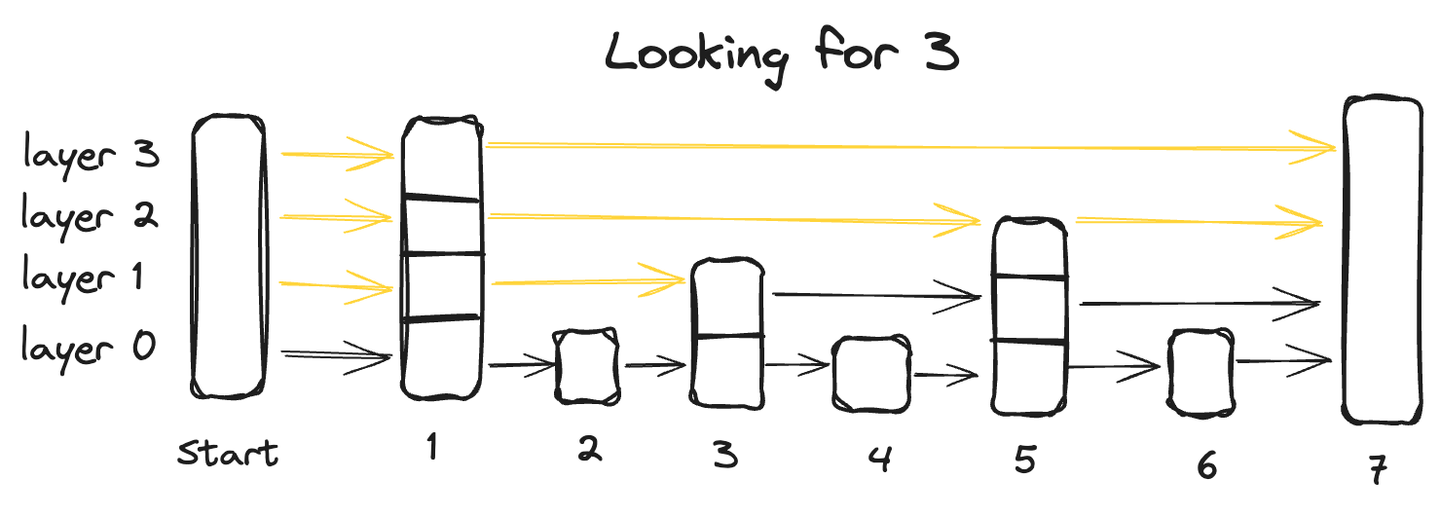
从包含所有数据点的底层开始,每个后续层都跳过一些点,因此数据点越来越少,最上层的数据点最少。
在跳表中搜索数据点时,我们从最高层开始,从左到右依次探索每个数据点。在任何时候,如果查询的值大于当前数据点,则返回到下一层的前一个数据点,并从左到右继续搜索,直到找到准确的点。
# NSW
NSW 类似于近似图,其中节点根据彼此的相似性连接在一起。使用贪婪算法搜索最近的点。
我们始终从预定义的入口点开始,该点连接到多个附近的节点。我们确定这些节点中与查询向量最接近的节点,并移动到该节点。该过程迭代,直到没有比当前节点更接近查询向量的节点,这是算法的停止条件。
现在,让我们回到主题,看看它是如何工作的。
# HNSW的开发过程
在HNSW中,我们从跳表中获得灵感,并创建类似跳表的层次结构。但是对于数据点之间的连接,它在节点之间创建了类似图的连接。每个层次的节点不仅与当前层次的节点相连,还与较低层次的节点相连。顶层的节点很少,而向下移动到较低层次时,强度增加。最后一层包含数据库的所有数据点。这就是HNSW架构的样子。
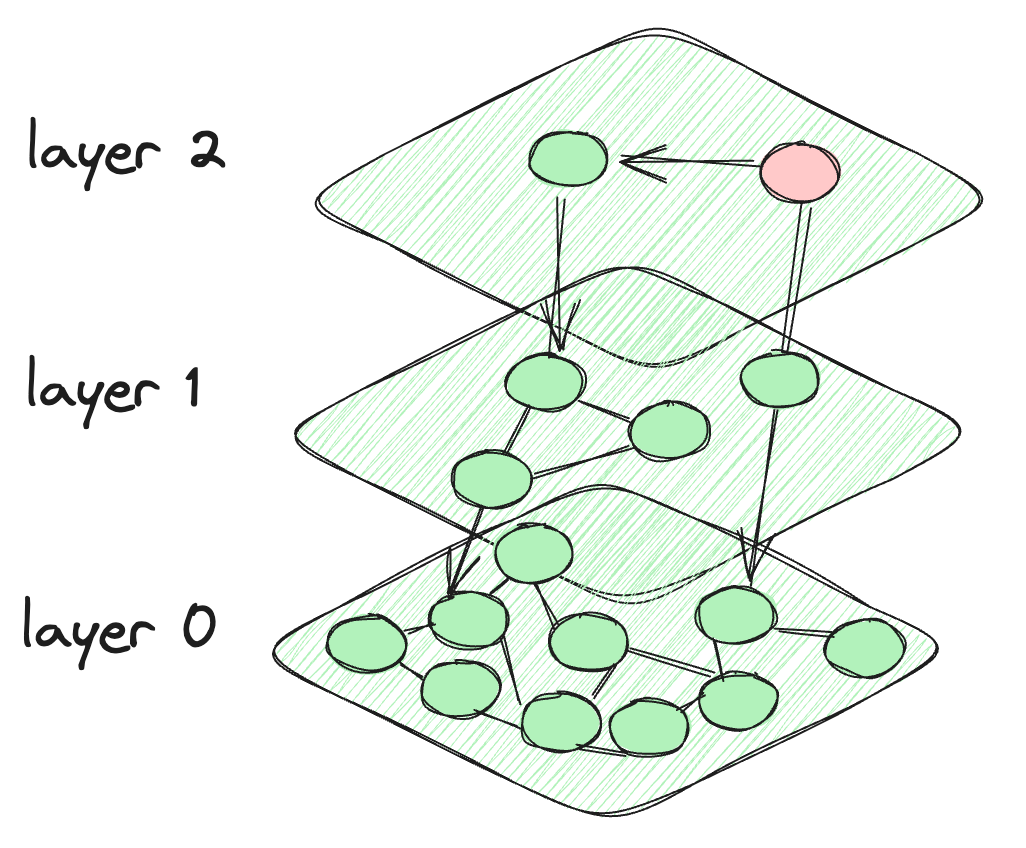
HNSW算法的架构
# HNSW中的搜索查询如何工作
算法从最顶层的预定义节点开始。然后计算当前层次的连接节点与下一层次的连接节点之间的距离。如果到达下一层中的某个节点的距离小于当前层中的节点的距离,则算法转移到较低层次。这个过程一直持续到达到最后一层或到达与所有其他连接节点的距离最小的节点。最后一层,即第0层,包含所有数据点,提供了数据集的全面和详细的表示。这一层对于确保搜索涵盖所有潜在最近邻点至关重要。
# HNSW的不同变体:HNSWFLAT和HNSWSQ
就像IVFFLAT和IVFSQ一样,一个存储原始向量,另一个存储量化范围,HNSWFLAT和HNSWSQ也是如此。在HNSWFLAT中,原始向量按原样存储,而在HNSWSQ中,向量以量化形式存储。除了数据存储中的这个关键差异外,HNSWFLAT和HNSWSQ的整体过程和方法在索引和搜索方面是相同的。

# MSTG 算法
IVF将向量数据集分成众多的簇,而 HNSW 为向量数据构建了一个分层图。然而,这些方法的一个显著限制是,当在大规模数据集中索引规模大幅增长时,需要将所有向量数据存储在内存中。虽然像DiskANN这样的方法可以将向量存储卸载到SSD,但它建立索引速度较慢,而且在筛选搜索性能方面非常低。
Multi-Scale Tree Graph(MSTG)由MyScale (opens new window)自主开发,通过将分层树聚类与图遍历相结合,利用快速的NVMe SSD存储器,克服了这些限制。MSTG显著减少了IVF/HNSW的资源消耗,同时保持了卓越的性能。它构建快速,搜索快速,在不同的筛选搜索比例下保持了速度和准确性,同时资源和成本效益高。
# 结论
向量数据库彻底改变了数据存储的方式,不仅提供了增强的速度,还在人工智能和大数据分析等各个领域提供了巨大的实用性。在指数级数据增长的时代,特别是在非结构化形式的数据中,向量数据库的应用是无限的。定制的索引技术进一步增强了这些数据库的功能和效果,例如提高了过滤向量搜索的性能。MyScale使用独特的MSTG算法优化了过滤向量搜索 (opens new window),为复杂的大规模向量搜索提供了强大的解决方案。立即尝试MyScale (opens new window),体验先进的向量搜索。



