
向量搜索可以在大量文本、图像和其他数据中快速定位语义上相似或相关的候选。然而,在实际应用场景中,纯向量搜索通常是不够的。
实际数据通常包含时间、类别、用户 ID 和其他关键词等属性。对这些属性应用一个或多个过滤条件可以显著提高检索增强生成(RAG)系统的准确性,同时为大规模多租户系统奠定基础。基于 ClickHouse 数据库开发的 MyScale 支持各种 SQL 数据类型,实现了高准确性和高效率的带有任意过滤比例的搜索。
本文讨论了过滤向量搜索的重要性,以及实现它的技术,包括预过滤和后过滤,以及行存储和列存储。
# 过滤向量搜索对于提高 RAG 系统的准确性至关重要
过滤搜索在支持高准确性的 LLM/AI 应用中起着至关重要的作用。在文档内容较少的场景中,纯向量检索通常可以返回相对准确的候选项。然而,随着文档数量的增加,检索的召回率通常会迅速下降。在金融、大型企业应用等复杂文档系统中,相关内容通常非常丰富。在这些情况下,纯向量检索往往会返回许多相似但不正确的段落,从而对 LLM 的最终响应的准确性产生负面影响。
例如,在金融分析场景中,用户可能会问:“<某公司> 的管理风格是什么?”当 <某公司> 是一个不太常见的公司名称时,纯向量检索通常会返回许多相似但不准确的内容,比如关于类似公司管理风格的段落,这会阻碍LLM对响应的准确生成。
然而,如果我们事先知道与 <某公司> 相关的文档标题中包含了这个关键词,我们可以使用 WHERE title ILIKE '%<某公司>%' 进行预过滤,从而将搜索结果缩小为只包含相关文档。此外,LLM可以自动提取 <某公司>,例如作为函数调用中的参数或从查询文本生成 SQL WHERE 子句,确保系统灵活易用。
通过使用这些结构化属性进行过滤,我们在金融文档分析和企业知识库等实际应用中观察到了从 60% 到 90% 的准确率提升。因此,为了确保 RAG 系统内的高准确性查询,我们需要一种灵活和通用的结构化+向量数据建模和查询方法,以及无论过滤比例如何都能保证高准确性和高效率的向量检索。

# 过滤向量搜索是实现大规模多用户系统的基础
过滤向量搜索在大规模文档问答、具有语义记忆的虚拟角色聊天和社交网络等应用中是基础,其中系统需要支持来自数百万用户的数据查询,每个查询通常涉及单个或少量用户的数据。
这要求在大规模向量数据集上以非常低的过滤比例实现异常高的查询准确性。专门为此类应用设计的向量数据库,如 Pinecone、Weaviate 和 Milvus,引入了namespace 机制,开发人员可以将每个用户的数据放在单独的命名空间中,以确保查询准确性。
然而,这种方法限制了灵活性,因为单个查询只能在一个命名空间内搜索。例如,在社交网络中,用户可能需要查询与他们的朋友相关的内容,涉及到数百到数千个朋友的数据的查询。在上下文分析和推荐系统中通常需要复杂的过滤查询,基于时间、作者、关键词等。
在这些情况以及其他情况下,使用WHERE条件进行过滤查询提供了更灵活的方法。此外,通过使用数据分区和通过主键对数据进行排序,可以通过提高数据局部性来进一步提高查询效率。
下面的图示描述了一个实际示例,展示了在表创建过程中使用两行 SQL 来实现这些技术(即 ORDER BY (user_id, message_id) 和 PARTITION BY sipHash64(user_id) % 100)。
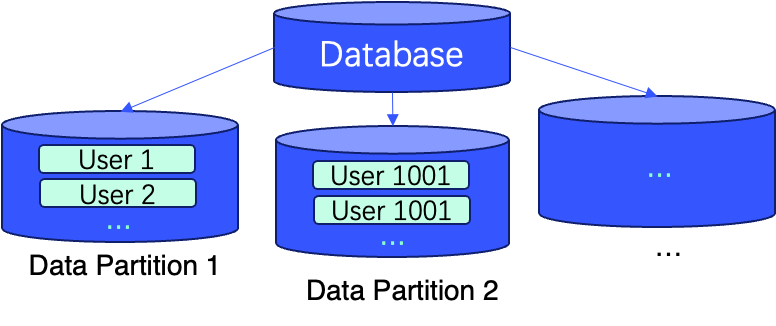
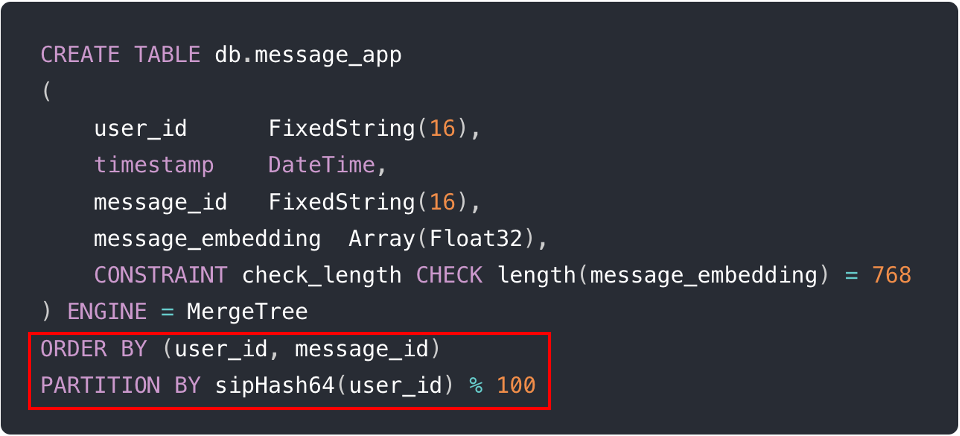
注意:
有关更多详细信息,请参阅我们的多租户文档 (opens new window)。
# MyScale 支持任意比例的高准确性、高效率的过滤搜索
MyScale通过结合列存储、预过滤和高效的搜索算法,在任意过滤比例下实现了高准确性、高效率的过滤搜索。它的每个查询的成本效率比其他产品低 4 倍至 10 倍。
例如,MyScale 在我们的开源基准测试 (opens new window)中实现了最高的搜索速度和准确性,超过了准确性和速度不足的类似系统,同时价格更低 5 倍。这种精确而高效的过滤搜索能力是生产级 RAG 系统的重要基础。
注意:
有关更多结果,请参阅 MyScale 与 pgvector 和 OpenSearch 的比较文章 (opens new window)。
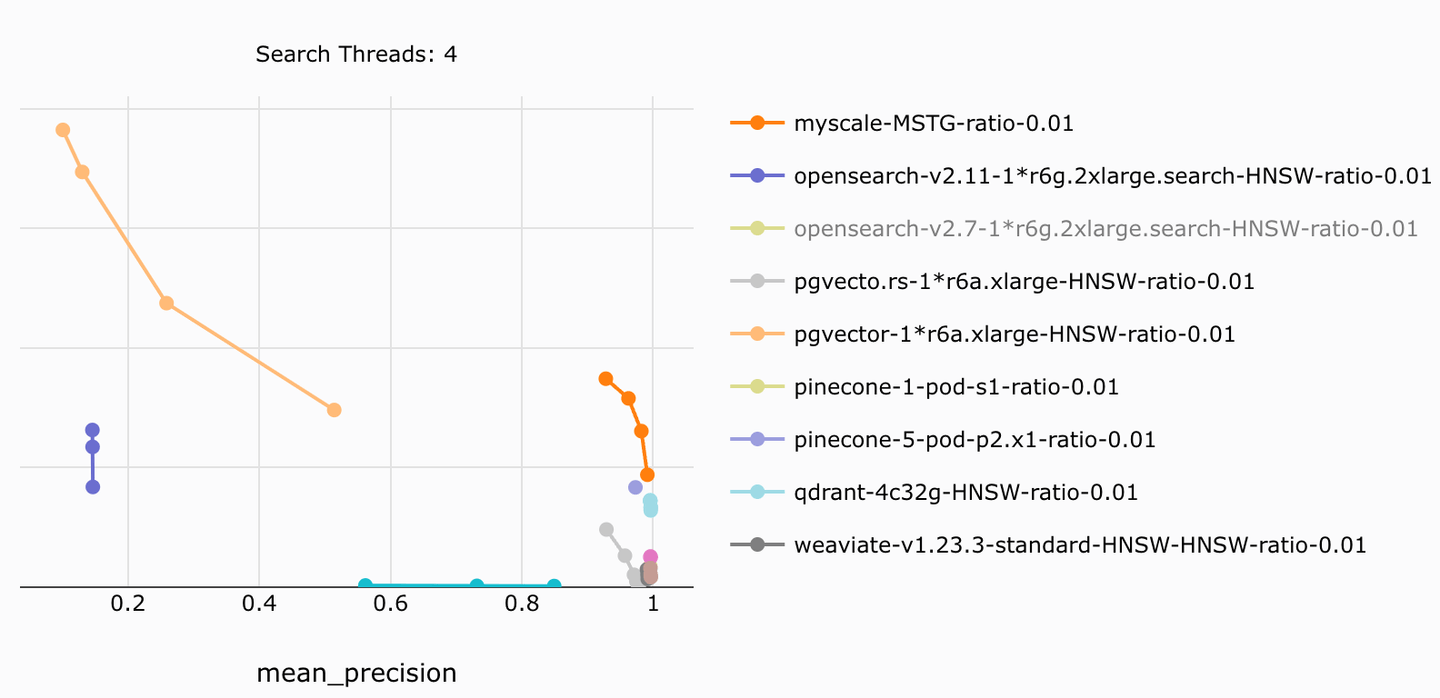
如上所述,MyScale 是基于广泛使用的 ClickHouse SQL 数据库开发的,支持各种数据类型和函数 (opens new window),如数值、日期时间、地理空间、JSON、字符串等。与 Pinecone、Weaviate 和 Qdrant 等专门的向量数据库相比,这显著提高了过滤查询的能力。
此外,由于 LLM 在 SQL 方面非常熟练,它们可以自动将自然语言转换为 SQL WHERE条件。这意味着没有技术背景的用户可以使用自然语言执行过滤查询,进一步提高 RAG 系统的灵活性和准确性。我们在LangChain 的 MyScale Self Query (opens new window) 中实现了类似的技术,该技术已广泛应用于生产系统中。

# 过滤向量搜索背后的技术
尽管在许多场景中,过滤向量搜索的实现对于精确和高效的过滤向量搜索涉及许多技术细节的选择,例如预过滤与后过滤、行存储与列存储以及图形与树算法。通过集成预过滤、列存储和多尺度树图算法等技术,MyScale 在过滤向量搜索中实现了出色的准确性和速度。
# 预过滤与后过滤
在过滤向量搜索中,实现元数据过滤有两种方法:预过滤和后过滤。
预过滤首先使用元数据选择满足条件的向量,然后搜索这些向量。这种方法的优点是,如果用户需要k个最相似的文档,数据库可以保证返回k个结果。
另一方面,后过滤涉及先进行向量搜索以获取m个结果,然后对这些结果应用元数据过滤。这种方法的缺点是,m个结果中有多少满足元数据过滤条件是不确定的,可能导致最终结果少于k个。当满足过滤条件的向量稀缺时,后过滤的准确性显著降低。PostgreSQL 的向量检索插件 pgvector 采用了这种方法,在符合条件的数据比例较低时准确性显著降低。
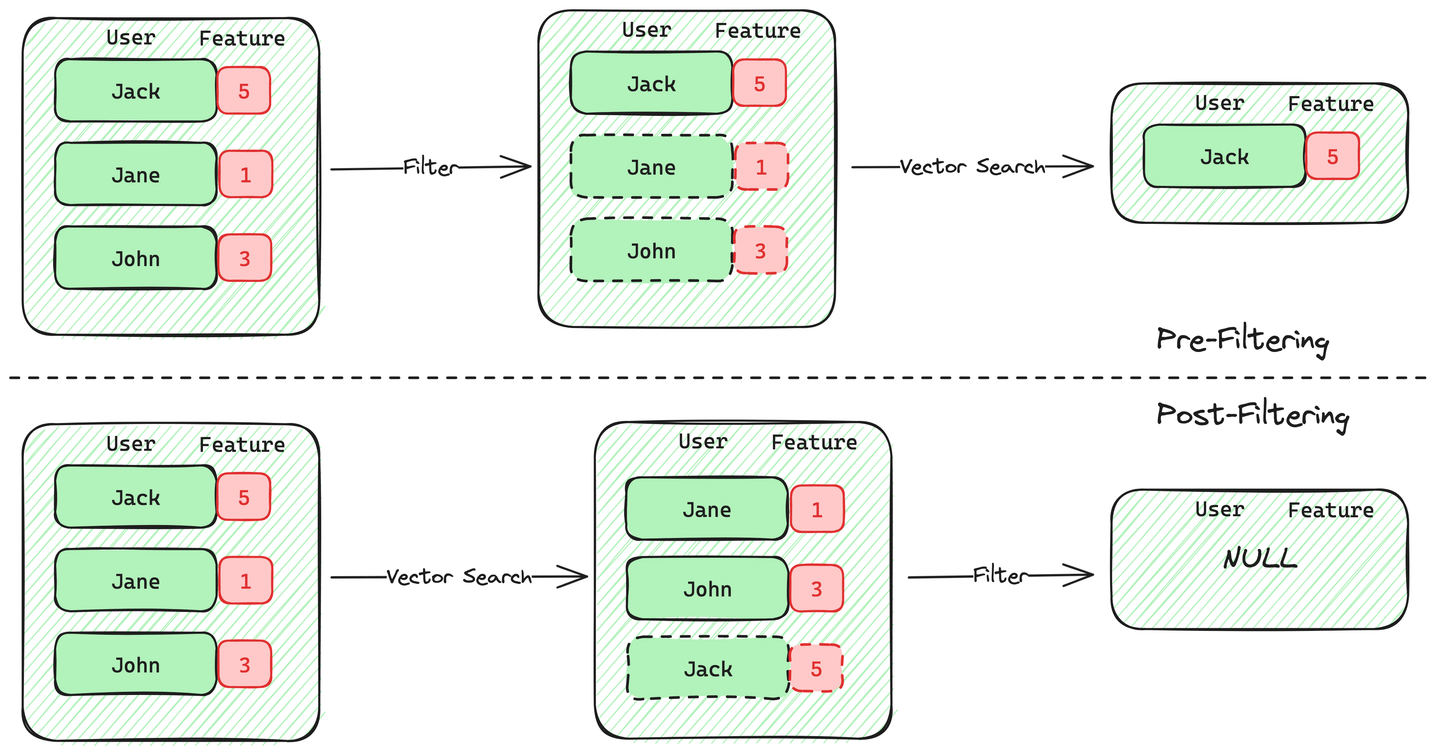
预过滤的挑战在于在满足条件的向量数量较少时,高效地过滤数据并在向量索引中保持搜索效率。
例如,广泛使用的 HNSW(Hierarchical Navigable Small World)算法在过滤比例低(例如,过滤后只剩下1%的向量)时,搜索效果显著下降。为了解决这个问题,行业内常见的解决方案是在过滤比例低于特定阈值时采用暴力搜索。例如,Pinecone、Milvus 和 ElasticSearch 都采用了这种方法,但是这可能会严重影响大型数据集的性能。MyScale 通过结合高效的预过滤和算法创新,在任意过滤比例下保证了高准确性和高效率。
# 行存储与列存储
在采用预过滤策略时,高效扫描元数据对检索性能至关重要。数据库存储通常分为行存储和列存储两种类型。
行存储通常用于事务性数据库,如 MySQL 或 PostgreSQL,对于事务处理,特别是点读和写入,更加友好。相比之下,列存储数据库(如ClickHouse)对于分析处理,特别是扫描多列数据、批量数据插入和压缩存储方面非常高效。
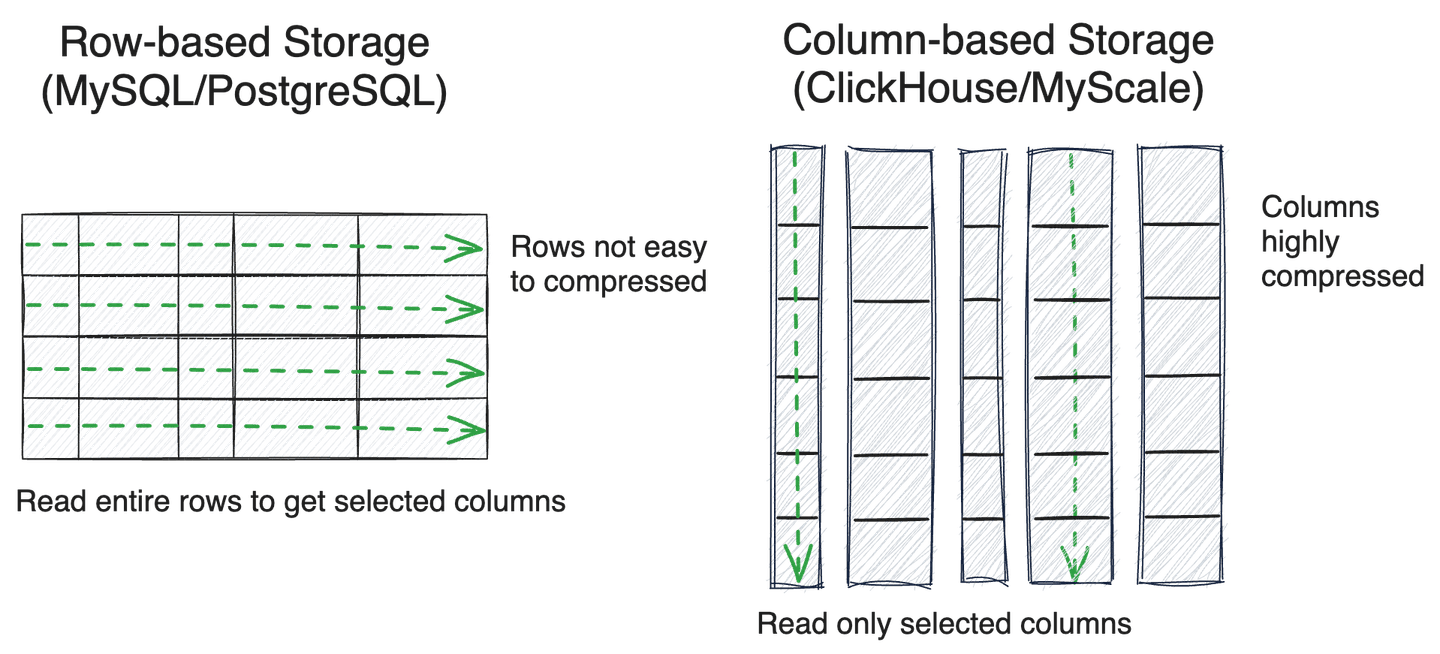
由于需要高效扫描元数据,许多专门的向量数据库,如 Milvus 和 Qdrant,也采用了列存储。经过多年对大规模结构化数据分析查询的优化,列式 SQL 数据库如 ClickHouse(有关更多信息,请参见 ClickBench (opens new window))在许多实际场景中表现更加出色,使用了跳过索引和 SIMD 操作等技术,显著提高了数据扫描效率。
通过广泛的用户研究,我们发现在 RAG 等 AI/LLM 应用中,小型写事务的需求较少,但高效的数据扫描和分析至关重要。因此,对我们来说,列存储是一个更合适的选择。
这是 MyScale 选择基于 ClickHouse 开发的一个关键原因。相应地,pgvector 和 pgvecto.rs 等系统由于 PostgreSQL 的行存储的限制,面临着过滤搜索准确性或速度的问题。
最后,列式数据库最大的挑战是它们的多列点读效率低,这是由于数据读取放大和解压缩开销导致的。好消息是,可以使用无压缩数据缓存等技术来解决这个问题。在结构化和向量数据的联合查询方面,也有很大的改进空间,例如 vbase (opens new window) 中的松弛单调性优化。
# 总结
通过在一个查询中结合结构化和向量数据,过滤向量搜索在高级 RAG 系统、大规模多用户系统等方面具有广泛而重要的应用。基于列式的 ClickHouse SQL 数据库开发的 MyScale 支持丰富的元数据类型和函数,以及灵活的自查询能力。
通过采用预过滤、列存储和算法优化,MyScale 在任意过滤比例下实现了高准确性和速度,为 LLM 应用奠定了坚实的数据基础。
如果您对过滤搜索有更多想法或希望分享您的想法,请关注我们的 Twitter (opens new window) 并加入我们的 Discord (opens new window) 社区。



