
传统的图像分类模型,如卷积神经网络(CNN),多年来一直是计算机视觉任务的基石。这些模型通过在大型标记数据集上进行训练来运作,其中每个图像都与特定的类别标签相关联。通常,这些模型依赖于N-shot学习,这意味着它们需要大量标记图像(N个示例)来实现高准确性。
然而,这些传统模型面临着几个重要挑战。首先,它们需要大量标记数据,这在时间和成本上都是耗费的。此外,传统模型在泛化方面存在困难,特别是当示例数(N)较少时。
此外,这些模型在对未见数据进行分类方面能力有限。如果模型没有在特定类别上进行训练,它很难准确分类该类别的图像。这个限制在新类别频繁出现或标记数据稀缺的情况下成为一个重要瓶颈。
这些挑战清楚地表明我们需要更智能的模型,能够在更少的数据下做更多的事情。这就是CLIP的优势所在。与传统模型不同,CLIP不需要针对每个类别进行特定训练才能识别它。它使用一个庞大的图像-文本对数据集和对比学习来判断图像中的内容,即使它以前没有见过这种类型的图像。这使得CLIP非常有用,特别是在传统模型无法胜任的情况下。
# CLIP
OpenAI于2021年推出了CLIP,这是一个将图像和文本放置在共享向量空间中的模型。通过使用对比学习,CLIP学会了判断哪些图像-文本对是相关的,哪些不相关。这种能力使其能够在不同类别之间进行泛化,即使它以前没有遇到过这些类别。因此,CLIP在零样本分类方面非常有效,它可以根据纯文本描述准确地识别新类别。
- 零样本分类 (opens new window):这种方法使模型能够在训练过程中不需要任何标记示例的情况下对新类别进行分类。它被称为“零样本”,因为它不需要任何训练数据,仅依靠文本描述进行预测。
- N样本分类 (opens new window):在这种情况下,模型需要每个类别N个标记示例才能学会正确分类它们。这里的“N”表示模型需要看到的示例数量来理解每个类别。
# CLIP如何用于零样本分类
CLIP的架构以一种简单而强大的方式处理零样本分类。CLIP的核心是两个编码器:一个用于图像,一个用于文本。这些编码器将输入的图像和文本描述转换为共享向量空间中的高维向量或嵌入。
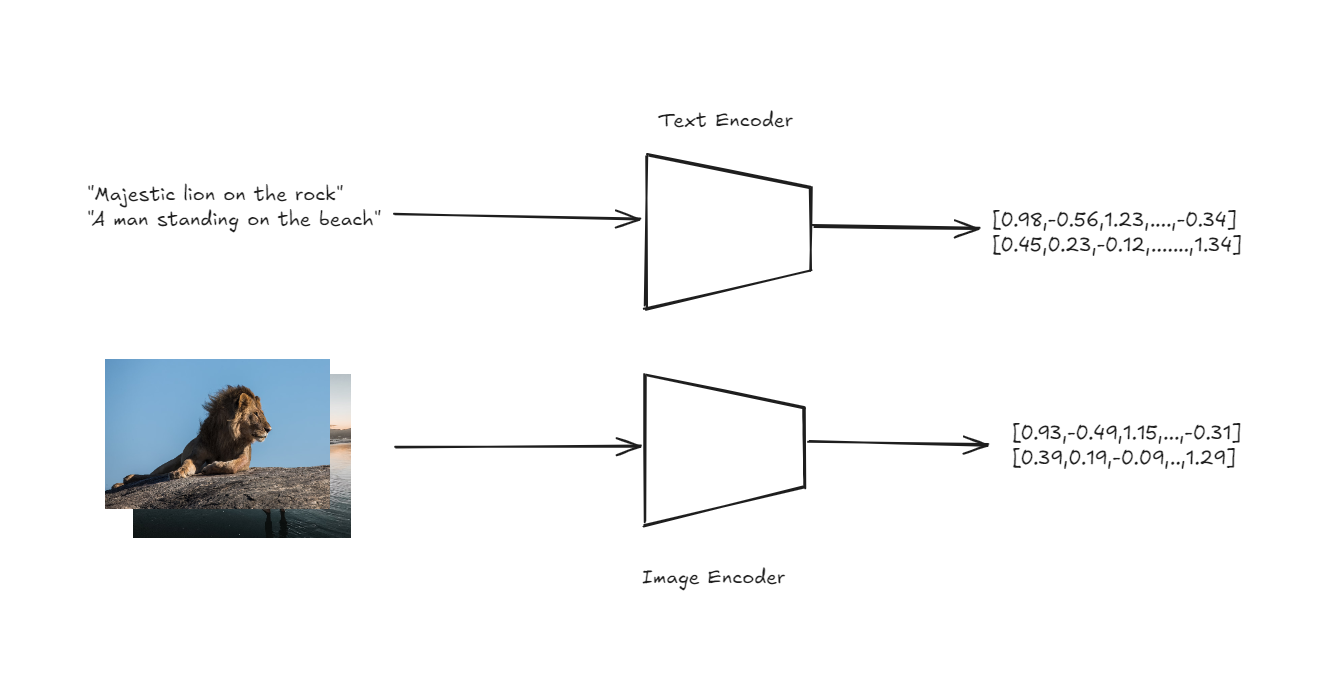
文本和图像编码器以获取嵌入
这里的关键创新在于图像和文本都以相同的空间表示,使得可以直接比较两种模态之间的差异。
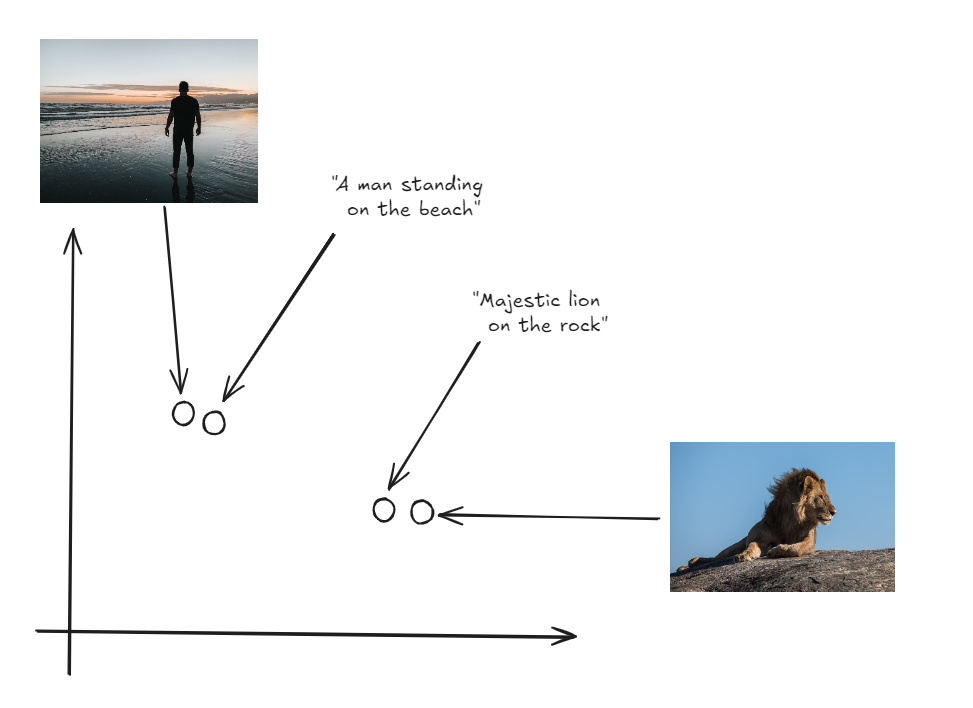
图像和标签在相同的向量空间中
为了进行零样本分类,CLIP首先为与不同类别相对应的一组文本描述生成嵌入(例如,“一张猫的照片”,“一张狗的照片”)。然后,它为输入图像生成一个嵌入。模型计算图像嵌入和每个文本嵌入之间的余弦相似度。余弦相似度测量两个向量之间的夹角的余弦值,表示它们的接近程度。选择与图像嵌入具有最高余弦相似度的文本描述作为预测标签。这个过程使得CLIP能够根据文本描述将图像分类到在训练过程中从未明确见过的类别中。
**注意:**相同的方法可以应用于构建使用CLIP的图像搜索应用 (opens new window)。
# 实际示例
现在,当我们在“Imagenette”数据集上测试CLIP模型进行零样本分类时,它表现出色,准确率超过99%。这个结果表明,CLIP可以与甚至超过传统图像分类模型的性能。
有了如此令人印象深刻的结果,很明显CLIP为图像分类任务提供了一个强大的替代方案。现在,让我们深入探讨如何在实际场景中实现这个模型。
注意:您可以在Github (opens new window)上找到完整的笔记本。
# 安装所需的库
首先,我们需要安装必要的库。使用以下命令安装所需的软件包:
pip install datasets transformers
Hugging Face的datasets库为您提供了大量可用于机器学习项目的准备就绪的数据集,非常有帮助。
transformers库也是由Hugging Face提供的,是您使用强大的预训练模型的首选。在我们的案例中,我们将使用它来加载和使用CLIP模型。
# 导入依赖项
安装完库之后,我们可以导入所需的依赖项。这些包括处理数据、使用CLIP模型和可视化结果的关键模块。
import torch
import numpy as np
from datasets import load_dataset
from tqdm.auto import tqdm
from transformers import AutoProcessor, CLIPModel, AutoTokenizer
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import seaborn as sns
我们将使用matplotlib和seaborn来创建和显示可视化结果,这将帮助我们更好地解释和展示我们的数据。
# 加载CLIP模型
为了进行零样本分类,我们加载CLIP模型。如果GPU可用,模型将加载到GPU上,否则将回退到CPU。我们还加载相关的处理器和分词器。
device = "cuda" if torch.cuda.is_available() else "cpu"
model = CLIPModel.from_pretrained("openai/clip-vit-large-patch14").to(device)
processor = AutoProcessor.from_pretrained("openai/clip-vit-large-patch14")
tokenizer = AutoTokenizer.from_pretrained("openai/clip-vit-large-patch14")
AutoProcessor负责处理图像和文本数据,使其与CLIP模型兼容。AutoTokenizer将文本转换为模型可以理解的格式,生成进一步处理所需的标记。
注意:在本博客中,我们使用了Google Colab中提供的免费GPU,这大大加快了处理时间。
# 加载Imagenette数据集
我们继续加载“Imagenette”数据集,这是较大的“ImageNet”数据集的一个较小子集。该子集包含10个类别,使得进行快速实验更加容易:
imagenette = load_dataset(
'frgfm/imagenette',
'320px',
split='validation',
revision="4d512db"
)
使用Hugging Face的datasets库中的load_dataset函数下载和准备“Imagenette”数据集。该数据集的版本由320像素大小的图像组成,并分为验证集以评估模型的性能。
# 分析数据集
我们首先打印数据集中存在的类别标签,以了解我们要处理的类别:
labels = imagenette.features["label"].names
print(f"数据集中的类别标签:{labels}")
上述代码将打印以下结果:
数据集中的类别标签:['tench', 'English springer', 'cassette player', 'chain saw', 'church', 'French horn', 'garbage truck', 'gas pump', 'golf ball', 'parachute']
# 可视化类别分布
为了更好地了解不同类别之间的图像分布情况,我们创建一个条形图。
plt.figure(figsize=(10, 6))
sns.barplot(x=labels, y=class_counts, palette='viridis')
plt.xticks(rotation=45, ha='right')
plt.title('Imagenette数据集中的类别分布')
plt.xlabel('类别标签')
plt.ylabel('图像数量')
plt.show()
上述代码将生成一个类似于以下的条形图: 该图显示了Imagenette数据集中的类别分布不均匀。然而,对于我们来说,这种不平衡并不是一个问题,因为我们不是在训练中使用数据集,而是用于零样本分类。
# 选择和处理图像
然后,我们遍历数据集以选择图像及其对应的标签。这一步将数据准备为后续的嵌入生成做准备。
selected_images = []
selected_labels = []
for example in tqdm(imagenette):
label = example["label"]
selected_images.append(example["image"])
selected_labels.append(label)
# 准备文本输入
对于零样本分类,我们使用分词器将类别标签转换为文本输入。这些输入将被输入模型以生成文本嵌入。
text_inputs = tokenizer([f"一张{c}的照片" for c in labels], return_tensors="pt", padding=True).to(device)
将字符串格式化为"一张{label}的照片"的原因是CLIP模型是在类似的文本-图像对上进行训练的。这种表述有助于模型更好地将文本与相应的图像匹配。
# 生成文本嵌入
使用CLIP模型,我们为每个类别标签生成文本嵌入。这些嵌入将与图像嵌入进行比较,以对图像进行分类。
with torch.no_grad():
label_emb = model.get_text_features(input_ids=text_inputs['input_ids'], attention_mask=text_inputs['attention_mask'])
label_emb = label_emb.cpu().numpy()
# 批处理和图像嵌入生成
我们以批处理的方式处理选定的图像以生成图像嵌入。然后,将这些嵌入与文本嵌入进行比较,计算相似度分数。
preds = []
batch_size = 50
for i in tqdm(range(0, len(selected_images), batch_size)):
i_end = min(i + batch_size, len(selected_images))
images = processor(
images=selected_images[i:i_end],
return_tensors='pt'
)['pixel_values'].to(device)
with torch.no_grad():
img_emb = model.get_image_features(images)
img_emb = img_emb.cpu().numpy()
# 计算图像嵌入和文本嵌入之间的相似度分数
scores = np.dot(img_emb, label_emb.T)
preds.extend(np.argmax(scores, axis=1))
现在,我们得到了一组选定图像的预测标签。接下来,我们将探索模型的性能以及这些预测所提供的见解。
# 计算和显示准确率
最后,我们通过将预测的标签与实际标签进行比较,计算零样本分类的准确率。
accuracy = accuracy_score(selected_labels, preds)
print(f"Imagenette数据集上的零样本分类准确率:{accuracy * 100:.2f}%")
上述代码将给出以下输出:

正如我们所看到的,CLIP模型在Imagenette数据集上表现出色,准确率很高。这种强大的性能是由于高质量的图像和相对较少的类别数量,使得模型能够将图像与其相应的文本描述对齐。CLIP模型是在一个包含4亿个图像-文本对的庞大数据集上进行训练的,通常使用大小约为224x224像素的图像进行训练,这有助于它学会在广泛的视觉和文本数据范围内进行泛化。
然而,当使用低分辨率图像或具有更多类别的数据集时,模型的性能会有所变化。例如,当我们在CIFAR-10数据集上进行测试时,使用32x32像素的图像,准确率下降到94.76%。类似地,当在具有102个类别和不同图像质量的SaulLu/Caltech-101数据集上进行测试时,准确率较低,为81.21%。
注意:在这里,您可以找到关于SaulLu/Caltech-101 (opens new window)和CIFAR-10 (opens new window)的完整笔记本和结果。

尽管存在这些挑战,CLIP仍然是一个很好的选择,特别是当您有限或没有标记的训练数据时。它能够进行零样本分类,并处理各种任务而无需进行大量的重新训练,使其成为传统模型无法胜任的情况下的有价值的工具。



