
使用大型语言模型(LLM)开发可扩展和优化的AI应用程序仍处于发展阶段。基于LLM构建应用程序由于涉及大量手动工作(如提示编写)而变得复杂且耗时。提示编写是任何LLM应用程序中最重要的部分,因为它帮助我们从模型中提取最佳结果。然而,编写优化的提示需要开发人员大量依赖试错方法,浪费了大量时间,直到达到所需的结果为止。
传统的手动编写提示的方法耗时且容易出错。开发人员经常花费大量时间调整提示以达到所需的输出,面临以下问题:
- 脆弱性:提示可能会因微小的更改而中断或表现不一致。
- 手动调整:需要大量手动工作来优化提示。
- 处理不一致:相似任务的不同提示导致结果不一致。
# 什么是DSPy?
DSPy(Declarative Self-improving Language Programs)是由Omer Khattab及其在斯坦福NL的团队设计的框架。它旨在通过优先考虑编程而不是手动提示编写来解决提示编写的一致性和可靠性问题。它提供了一种更具声明性、系统化和编程化的方法来构建数据流水线,使开发人员能够在不关注低级细节的情况下创建高级工作流程。
DSPy标志
它允许您定义要实现的目标,而不是如何实现它。为了实现这一目标,DSPy取得了以下进展:
- 提示的抽象化:DSPy引入了签名的概念。签名旨在用类似模板的结构取代手动提示编写。在这个结构中,我们只需要为任何给定任务定义输入和输出。这将使我们的数据流水线更具弹性和适应模型或数据的变化。
- 模块化构建块:DSPy提供了封装常见提示技术(如思维链或ReAct)的模块。这消除了为这些技术手动构建复杂提示的需要。
- 自动优化:DSPy支持内置的优化器,也称为“电视提示器”,它会自动选择最适合您特定任务和模型的提示。这个功能消除了手动提示调整的需要,使流程更简单高效。
- 编译器驱动的适应:DSPy编译器优化整个流水线,根据您的数据和验证逻辑调整提示或微调模型,确保即使组件发生变化,流水线仍然有效。
# DSPy程序的构建块
让我们探索构成DSPy程序基础的基本组件,并了解它们如何相互作用以创建强大高效的NLP流水线。
# 签名
签名用作定义您希望LLM执行的任务的蓝图。与编写确切的提示不同,您通过描述任务的输入和输出来定义任务。
例如,摘要文本的签名可能如下所示:text -> summary。这告诉DSPy您想要输入一些文本,并获得简洁的摘要作为输出。更复杂的任务可能涉及多个输入,例如问答签名:context, question -> answer。签名是灵活的,可以根据需要自定义附加信息,例如输入和输出字段的描述。
class GenerateAnswer(dspy.Signature):
"""使用简短的事实性答案回答问题。"""
context = dspy.InputField(desc="可能包含相关事实")
question = dspy.InputField()
answer = dspy.OutputField(desc="通常在1到5个单词之间")
# 模块:LLM行为的构建块
模块是封装特定LLM行为或技术的预构建组件。它们是您用于组装LLM应用程序的构建块。例如,ChainOfThought模块鼓励LLM逐步思考,使其在复杂的推理任务上表现更好。ReAct模块允许LLM与计算器或数据库等外部工具进行交互。您可以将多个模块链接在一起,创建复杂的流水线。
# 方法1:将类传递给ChainOfThought模块
chain_of_thought = ChainOfThought(TranslateText)
每个模块都接受一个签名,并使用ChainOfThought之类的defined方法根据定义的输入和输出构建必要的提示。这种方法确保提示被系统地生成,保持一致性,并减少手动提示编写的需求。
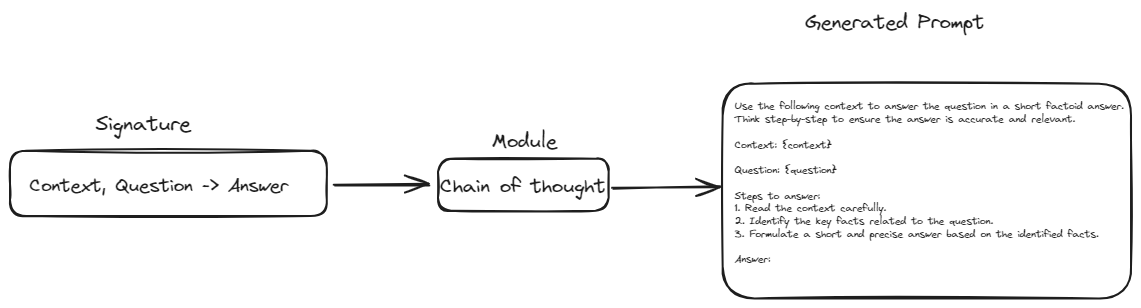
通过这种方式,模块接受签名,应用其特定的行为或技术,并生成与任务要求相一致的提示。签名和模块的集成允许使用最少的手动干预构建复杂而灵活的LLM应用程序。
# 电视提示器(优化器):提示的密友
电视提示器就像LLM的教练一样。它们使用先进的技术为您特定的任务和模型找到最佳提示。它们通过自动尝试不同的提示变体并根据您定义的度量标准评估其性能来实现这一点。例如,电视提示器可能使用准确性作为问答任务的度量标准,或使用ROUGE分数作为文本摘要的度量标准。
from dspy.teleprompt import BootstrapFewShot
# 简单的电视提示器示例
teleprompter = BootstrapFewShot(metric=dspy.evaluate.answer_exact_match)
# DSPy编译器:主要协调器
DSPy编译器是整个操作的核心。它接受您的整个程序(包括签名、模块、训练数据和验证逻辑),并对其进行优化以实现最佳性能。编译器自动处理应用程序中的更改的能力使DSPy非常强大和适应性强。
from dspy.teleprompt import BootstrapFewShot
# 带有问题和答案对的小训练集
trainset = [dspy.Example(question="阿尔伯特·爱因斯坦以开发什么而闻名?",
answer="相对论理论").with_inputs('question'),
dspy.Example(question="阿尔伯特·爱因斯坦的相对论理论产生了哪个著名的方程式?",
answer="E = mc²").with_inputs('question'),
dspy.Example(question="阿尔伯特·爱因斯坦在1921年获得了哪个著名奖项?",
answer="诺贝尔物理学奖").with_inputs('question'),
dspy.Example(question="阿尔伯特·爱因斯坦在哪一年移居美国?",
answer="1933").with_inputs('question'),
dspy.Example(question="爱因斯坦在1905年发表了哪项重要的科学工作,有时被称为他的奇迹年(annus mirabilis)?",
answer="包括光电效应、布朗运动、狭义相对论和质能等价理论在内的四篇开创性论文").with_inputs('question'),]
# 设置一个基本的电视提示器,它将编译我们的RAG程序。
teleprompter = BootstrapFewShot(metric=dspy.evaluate.answer_exact_match)
compiled_rag = teleprompter.compile(RAG(), trainset=trainset)
DSPy编译器接受基本提示、训练示例和DSPy程序,生成一个经过优化和性能最佳的提示。该过程涉及在输入上模拟程序的各个版本,并对每个模块的示例跟踪进行引导,以优化您的任务的流水线。
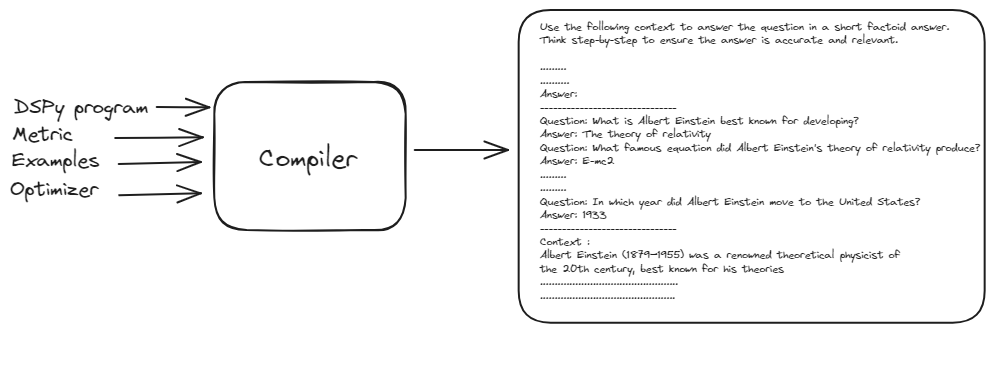
这个自动优化过程消除了手动提示调整的需求,使DSPy变得强大和适应性强,最终提供了高效和有效的NLP流水线。
# 使用DSPy和MyScaleDB构建RAG模型的实际示例
现在我们已经了解了DSPy的基础知识,让我们创建一个实际应用程序。我们将构建一个问答RAG流水线,并使用MyScaleDB作为向量数据库。
# 1. 从维基百科加载文档
我们首先通过使用langchain_community.document_loaders模块中的WikipediaLoader从维基百科加载与“阿尔伯特·爱因斯坦”相关的文档。
from langchain_community.document_loaders.wikipedia import WikipediaLoader
loader = WikipediaLoader(query="阿尔伯特·爱因斯坦")
# 加载文档
docs = loader.load()
# 2. 将文档转换为纯文本
接下来,我们使用Html2TextTransformer将加载的文档转换为纯文本。
from langchain_community.document_transformers import Html2TextTransformer
html2text = Html2TextTransformer()
docs_transformed = html2text.transform_documents(docs)
# 获取清理后的文本
cleaned_text = docs_transformed[0].page_content
text = ' '.join([page.page_content.replace('\\t', ' ') for page in docs_transformed])
# 3. 将文本拆分为块
使用CharacterTextSplitter将文本拆分为可管理的块。这有助于处理大型文档,并确保模型能够高效处理它们。
import os
from langchain_text_splitters import CharacterTextSplitter
# 将API密钥设置为环境变量
os.environ["OPENAI_API_KEY"] = "your_openai_api_key"
# 将文本拆分为块
text = ' '.join([page.page_content.replace('\\\\t', ' ') for page in docs])
text_splitter = CharacterTextSplitter(
separator="\\n",
chunk_size=300,
chunk_overlap=50,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.create_documents([text])
splits = [item.page_content for item in texts]
# 8. 定义嵌入模型
我们使用transformers库定义一个嵌入模型。我们将使用all-MiniLM-L6-v2模型将文本转换为向量嵌入。
import torch
from transformers import AutoTokenizer, AutoModel
# 初始化嵌入模型的标记器和模型
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
def get_embeddings(texts: list) -> list:
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt", max_length=512)
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1)
return embeddings.numpy().tolist()
# 7. 获取嵌入
我们使用上述嵌入模型为文本块生成嵌入。
import pandas as pd
all_embeddings = []
for i in range(0, len(splits), 25):
batch = splits[i:i+25]
embeddings_batch = get_embeddings(batch)
all_embeddings.extend(embeddings_batch)
# 使用文本块和它们的嵌入创建DataFrame
df = pd.DataFrame({
'page_content': splits,
'embeddings': all_embeddings
})
# 8. 连接到向量数据库
我们将使用MyScaleDB (opens new window)作为向量数据库来开发此示例应用程序。您可以通过访问MyScale的注册 (opens new window)页面 (opens new window)创建一个免费帐户。之后,您可以按照快速入门教程 (opens new window)开始一个新的集群并获取连接详细信息。
import clickhouse_connect
client = clickhouse_connect.get_client(
host='your-cloud-host',
port=443,
username='your-user-name',
password='your-password'
)
将连接详细信息复制并粘贴到Python笔记本中,然后运行代码块。它将连接到您在云上的MyScaleDB集群。
# 9. 创建表并推送数据
让我们分解在MyScaleDB集群上创建表的过程。首先,我们将创建一个名为RAG的表。该表将有三列:id、page_content和embeddings。id列将保存每行的唯一id,page_content列将存储文本内容,embeddings列将保存相应页面内容的嵌入。
# 创建表
client.command("""
CREATE TABLE IF NOT EXISTS default.RAG (
id Int64,
page_content String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 384
) ENGINE = MergeTree()
ORDER BY id
""")
# 将数据插入表中
batch_size = 100
num_batches = (len(df) + batch_size - 1) // batch_size
for i in range(num_batches):
batch_data = df[i * batch_size: (i + 1) * batch_size]
client.insert('default.RAG', batch_data.values.tolist(), column_names=batch_data.columns.tolist())
print(f"已插入第{i+1}/{num_batches}批数据。")
创建表后,我们将数据以批的形式保存到新创建的RAG表中。
# 10. 使用MyScaleDB配置DSPy
我们将DSPy和MyScaleDB连接起来,并将DSPy配置为默认使用我们的语言和检索模型。
import dspy
import openai
from dspy.retrieve.MyScaleRM import MyScaleRM
# 设置OpenAI API密钥
openai.api_key = "your_openai_api_key"
# 配置LLM
lm = dspy.OpenAI(model="gpt-3.5-turbo")
# 配置检索模型
rm = MyScaleRM(client=client,
table="RAG",
local_embed_model="sentence-transformers/all-MiniLM-L6-v2",
vector_column="embeddings",
metadata_columns=["page_content"],
k=6)
# 配置DSPy默认使用以下语言模型和检索模型
dspy.settings.configure(lm=lm, rm=rm)
注意:这里使用的嵌入模型应与上面定义的模型相同。
# 11. 定义签名
我们定义GenerateAnswer签名,以指定我们的问答任务的输入和输出。
class GenerateAnswer(dspy.Signature):
"""使用简短的事实性答案回答问题。"""
context = dspy.InputField(desc="可能包含相关事实")
question = dspy.InputField()
answer = dspy.OutputField(desc="通常在1到5个单词之间")
# 12. 定义RAG模块
RAG模块集成了检索和生成步骤。它从集成数据库中检索相关段落,并根据上下文生成答案。
class RAG(dspy.Module):
def __init__(self, num_passages=3):
super().__init__()
self.retrieve = dspy.Retrieve(k=num_passages)
self.generate_answer = dspy.ChainOfThought(GenerateAnswer)
def forward(self, question):
context = self.retrieve(question).passages
prediction = self.generate_answer(context=context, question=question)
return dspy.Prediction(context=context, answer=prediction.answer)
forward方法接受问题作为输入,并利用检索器从集成数据库中找到相关块。然后,将这些检索到的块传递给ChainOfThought模块以生成基础提示。
# 13. 设置电视提示器
接下来,我们将使用BootstrapFewShot电视提示器/优化器来编译和优化我们的基本提示。
from dspy.teleprompt import BootstrapFewShot
# 带有问题和答案对的小训练集
trainset = [dspy.Example(question="阿尔伯特·爱因斯坦以开发什么而闻名?",
answer="相对论理论").with_inputs('question'),
dspy.Example(question="阿尔伯特·爱因斯坦的相对论理论产生了哪个著名的方程式?",
answer="E = mc²").with_inputs('question'),
dspy.Example(question="阿尔伯特·爱因斯坦在1921年获得了哪个著名奖项?",
answer="诺贝尔物理学奖").with_inputs('question'),
dspy.Example(question="阿尔伯特·爱因斯坦在哪一年移居美国?",
answer="1933").with_inputs('question'),
dspy.Example(question="爱因斯坦在1905年发表了哪项重要的科学工作,有时被称为他的奇迹年(annus mirabilis)?",
answer="包括光电效应、布朗运动、狭义相对论和质能等价理论在内的四篇开创性论文").with_inputs('question'),]
# 设置一个基本的电视提示器,它将编译我们的RAG程序。
teleprompter = BootstrapFewShot(metric=dspy.evaluate.answer_exact_match)
# 使用电视提示器编译RAG流水线
compiled_rag = teleprompter.compile(RAG(), trainset=trainset)
此代码使用上面定义的RAG类和优化器的示例生成LLM的最佳提示。
# 14. 运行流水线
最后,我们运行编译后的RAG流水线,根据存储在MyScaleDB中的上下文回答问题。
# 检索相关文档
retrieve_relevant_docs = dspy.Retrieve(k=5)
context = retrieve_relevant_docs("阿尔伯特·爱因斯坦是谁?").passages
# 提出查询
pred = compiled_rag(question="阿尔伯特·爱因斯坦是谁?")
这将生成如下输出:
['阿尔伯特·爱因斯坦(1879-1955)是20世纪著名的理论物理学家,以其狭义相对论和广义相对论理论而闻名........
.......
他的独创性使得“爱因斯坦”一词成为“天才”的代名词。']

# 结论
DSPy框架通过将硬编码的提示替换为可编程接口,从而革新了我们与LLM的交互方式,显著简化了开发过程。从手动提示编写过渡到更结构化、面向编程的方法论,提高了AI应用程序的效率、一致性和可扩展性。通过抽象提示工程的复杂性,DSPy允许开发人员专注于定义高级逻辑和工作流程,从而加速了复杂的基于AI的解决方案的部署。
MyScaleDB作为专为AI应用程序开发的向量数据库,在提升此类系统的性能方面发挥着重要作用。其先进的专有算法提高了AI应用程序的速度和准确性。此外,MyScaleDB具有成本效益,为新用户提供了高达500万个向量的免费存储空间。这使其成为初创公司和研究人员在没有初始投资的情况下利用强大数据库解决方案的有吸引力的选择。



