
大型语言模型 (opens new window)(LLM)已经在自然语言处理(NLP)领域引起了革命,引入了一种与技术互动的新方式。先进的模型,如GPT (opens new window)和BERT (opens new window),开创了语义理解的新时代。它们使计算机能够处理和生成类似人类的文本,弥合了人类沟通和机器解释之间的差距。LLM现在正在驱动多个应用程序,包括情感分析、机器翻译、问答、文本摘要、聊天机器人、虚拟助手等。
尽管LLM具有实际应用,但它们也面临着一些挑战。它们被设计为通用模型,这意味着它们可能缺乏特定性。此外,由于它们是基于过去的数据进行训练的,它们可能无法始终提供最新的信息。这可能导致LLM生成不正确或过时的响应,从而导致所谓的“幻觉 (opens new window)”现象。当模型由于训练数据的缺陷而产生错误或生成不可预测的信息时,就会出现这种现象。
检索增强生成 (opens new window)(RAG)系统用于解决特定性缺乏和实时更新等问题,提供了增强LLM负责部署的潜在解决方案。
# 什么是RAG
2020年,Meta的研究人员提出了检索增强生成(RAG)的概念,将LLM的自然语言生成 (opens new window)(NLG)能力与信息检索(IR)组件相结合,以优化输出。在响应查询之前,它引用了可靠的知识源,这是其训练数据源之外的一个可靠知识源。它扩展了LLM的能力,无需重新训练模型,从而以一种经济高效的方式提高输出的相关性、准确性和可用性。
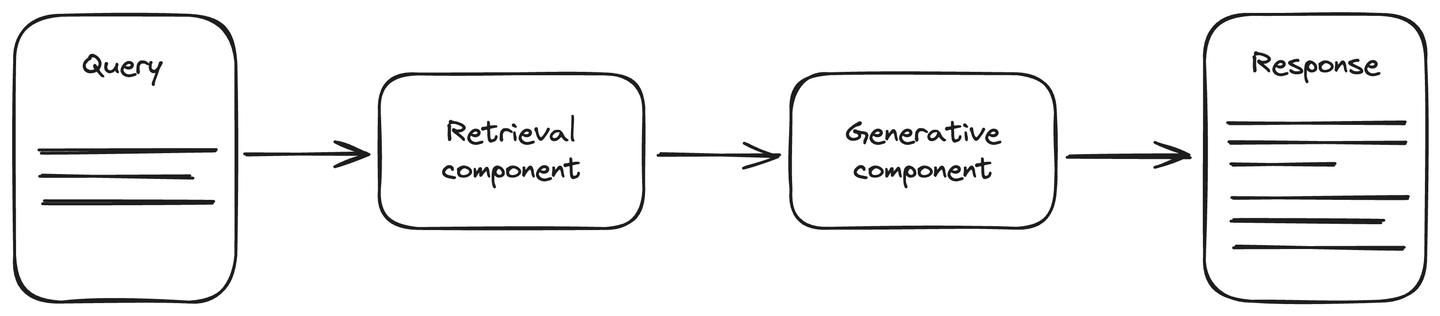
RAG架构包括一个最新的数据源,以增强生成AI任务的准确性。它分为两个主要组件:检索和生成组件。检索组件连接到一个数据源,通常是一个向量数据库,用于检索有关查询的更新信息。将这些信息与查询一起提供给生成组件。生成组件是一个LLM模型,根据提供的信息生成响应。RAG改进了LLM的理解能力,生成的响应更准确、更及时。
相关文章:对RAG的期望 (opens new window)
# 如何设置RAG系统的检索组件
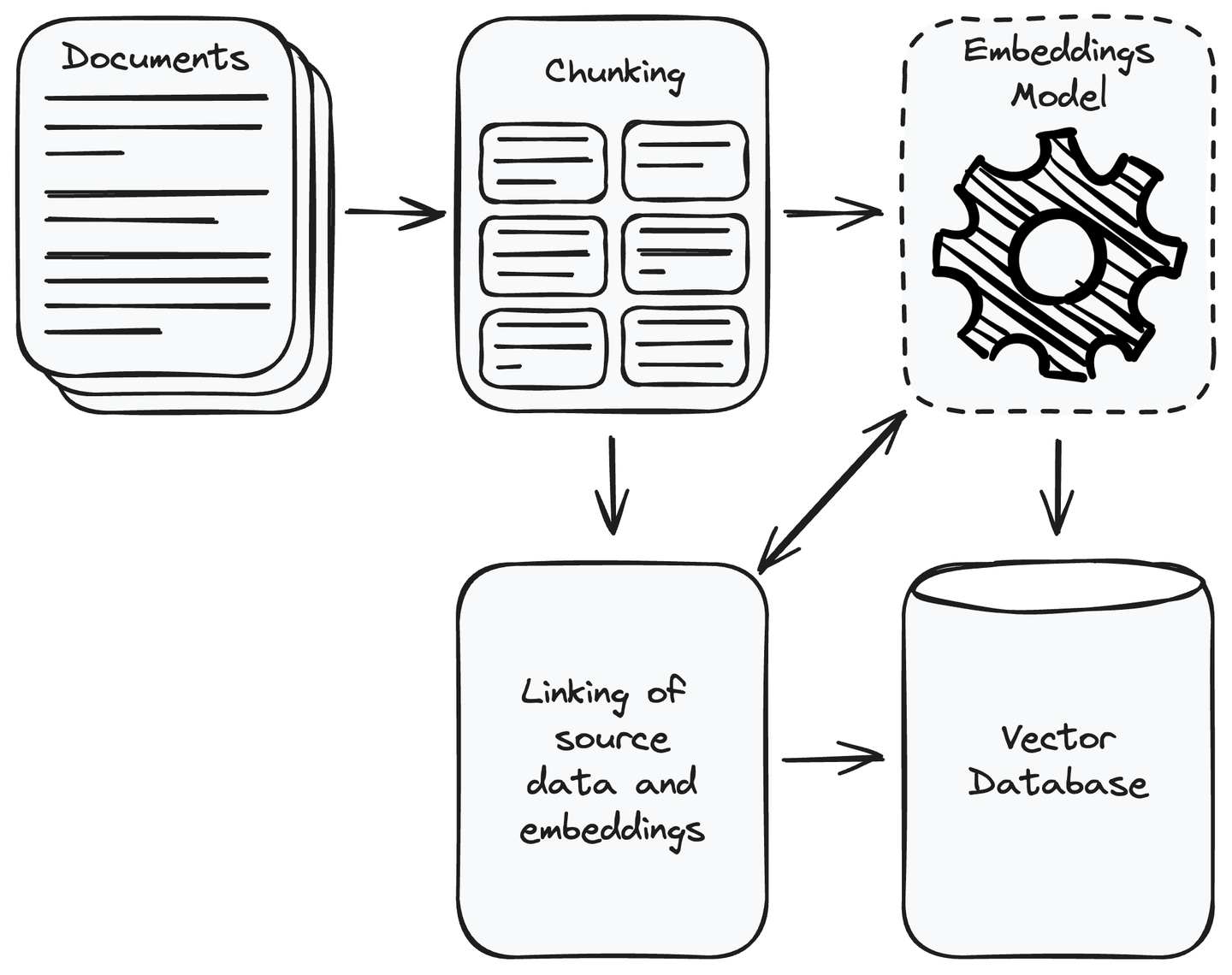
首先,您必须收集应用程序所需的所有数据。完成数据收集后,删除不相关的数据。将收集到的数据分成可管理的较小块,并使用嵌入模型 (opens new window)将这些块转换为向量表示。向量是数值表示,其中语义上相似的内容彼此更接近。它使系统能够理解并将用户查询与数据源中的相关信息进行匹配。将向量存储在向量数据库中,并将源数据的块与其嵌入链接起来。这将有助于检索与用户查询相似的向量的数据块。
MyScale (opens new window)是一个基于ClickHouse (opens new window)的云向量数据库,将常规SQL查询与向量数据库的强大功能相结合。这使您可以使用常规SQL查询保存和查找高维数据,如图像特征或文本嵌入。MyScale特别适用于需要比较向量的AI应用程序。它专为处理大量AI和机器学习任务中的向量数据的开发人员提供了经济实惠和实用的解决方案。
此外,MyScale的设计更经济、更快速、更准确。为了鼓励用户体验其优势,MyScale在免费层提供500万个免费向量存储。这使其成为开发人员在AI和机器学习项目中探索向量数据库的成本效益和用户友好的解决方案。
相关文章:构建一个启用RAG的聊天机器人 (opens new window)
# RAG系统如何工作
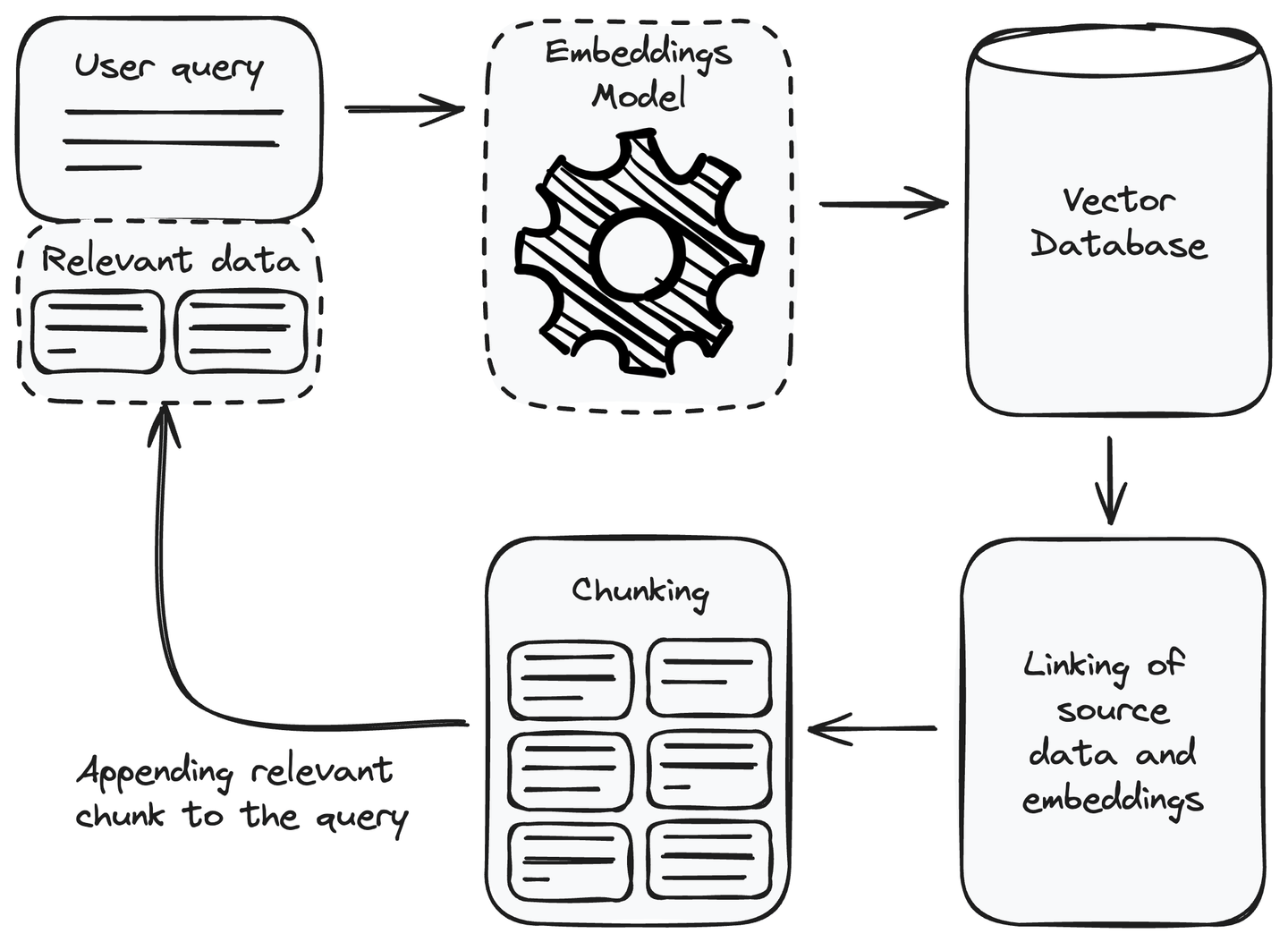
在设置检索组件之后,我们现在可以在RAG系统中利用它。为了响应用户查询,我们可以使用它来检索相关信息,并将其作为上下文附加到用户查询中,然后将其传递给语言模型进行响应生成。让我们了解如何使用检索组件获取相关信息。
# 将相关信息添加到查询中
每当我们收到一个用户查询时,我们需要执行的第一步是将用户查询转换为嵌入或向量表示。使用与设置检索组件时用于将数据源转换为嵌入的相同嵌入模型。将用户查询转换为向量表示后,使用任何度量方法(如欧氏距离 (opens new window)或余弦相似度 (opens new window))从向量数据库中找到相似的
# 使用LLM生成响应
现在,我们有了查询和相关的信息块。将用户查询与检索到的数据一起提供给LLM(生成组件)。LLM能够理解用户查询并处理提供的数据。它将根据从检索组件接收到的信息生成响应,以回答用户的查询。
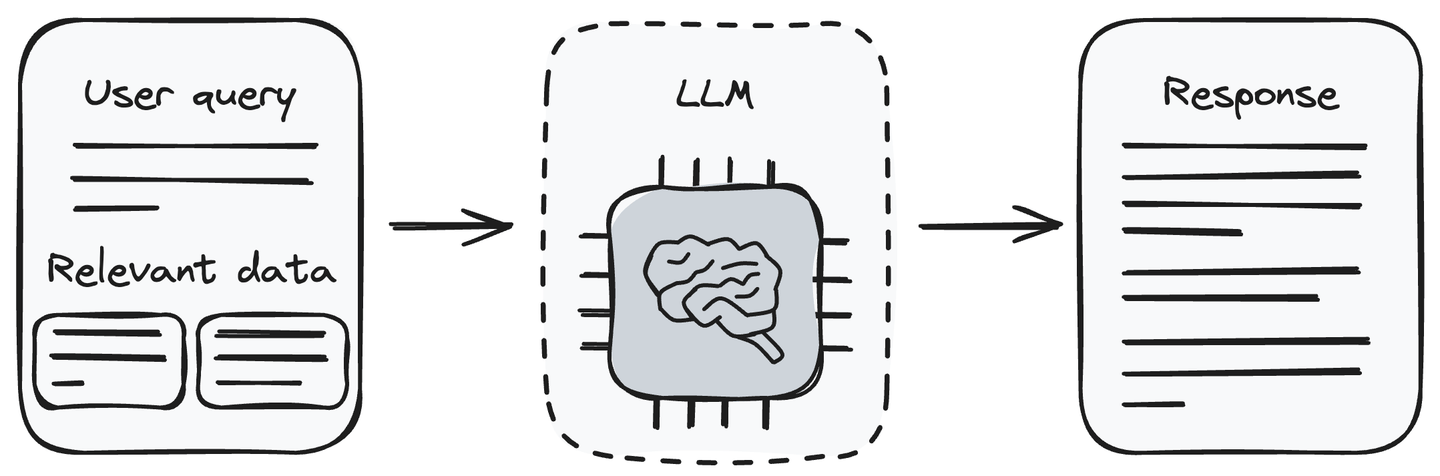
将相关信息与用户查询一起传递给LLM是一种解决LLM幻觉问题的方法。现在,LLM可以使用我们传递给它的信息生成对用户查询的响应。
注意:定期更新数据库以确保模型的准确性。
# 一些RAG应用
RAG系统可用于需要精确和上下文相关信息检索的不同应用程序。这有助于提高生成响应的准确性、及时性和可靠性。让我们讨论一些RAG系统的应用。
- 特定领域的问题回答:当RAG系统面对特定领域的问题时,它利用检索组件动态访问外部知识源、数据库或特定领域的文档。这使得RAG系统能够生成与指定领域内最新和准确信息相关的上下文相关响应。这在各种领域中都可能有所帮助,例如医疗保健、法律解释、历史研究、技术故障排除等。
- 事实准确性:事实准确性对于确保生成的内容或响应与准确和经过验证的数据一致非常重要。在可能出现不准确性的情况下,RAG优先考虑事实准确性,以提供与主题实际情况一致的信息。这对于各种应用程序都是必要的,包括新闻报道、教育内容以及任何可靠性和可信度至关重要的场景。
- 研究查询:RAG系统在解决研究查询方面非常有价值,它可以动态检索相关和最新的信息来自其知识源。例如,如果研究人员提出与特定科学领域的最新进展相关的查询,那么RAG系统可以利用其检索组件来访问最近的研究论文、出版物和相关数据,以确保研究人员获得上下文准确和当前的见解。
相关文章:如何构建一个推荐系统 (opens new window)

# 构建RAG系统的挑战
尽管RAG系统具有各种用例和优势,但它们也面临一些独特的限制。让我们将它们记录如下:
- 集成:将检索组件与基于LLM的生成组件集成可能很困难。当使用不同格式的多个数据源时,复杂性会增加。在将检索组件与生成组件集成之前,确保使用单独的模块保持所有数据源的一致性。
- 数据质量:RAG系统依赖于附加的数据源。RAG系统的质量可能不佳,原因有多种,例如使用低质量的内容,在多个数据源的情况下使用不同的嵌入,或者使用不一致的数据格式。确保保持数据质量。
- 可扩展性:随着外部数据量的增加,RAG系统的性能会受到影响。将数据转换为嵌入、比较相似数据块的含义以及实时检索可能会变得计算密集。这可能会减慢RAG系统的速度。为了解决这个问题,您可以使用MyScale,它通过在LAION 5M数据集上提供390个QPS(每秒查询数),95%的召回率和17ms的平均查询延迟来解决了这个问题。
# 结论
RAG是通过将知识库与LLM相结合来提高LLM能力的技术之一。您可以将其理解为具有语言生成能力的搜索引擎。这些系统在不需要重新训练或微调成本的情况下解决了LLM的幻觉问题。在响应用户查询时使用外部数据源提供更准确和最新的响应,特别是在处理事实、最新或定期更新的数据时。尽管RAG系统具有这些优点,但它们也有一些限制。
MyScale通过结合ClickHouse、先进的向量搜索算法和联合SQL向量优化,为大规模和复杂的RAG应用程序提供了强大的解决方案。它专为考虑到成本和可扩展性等所有因素的AI应用程序而设计。此外,它还与LangChain (opens new window)和LlamaIndex (opens new window)等知名AI框架进行集成。这些特点和功能使MyScale成为您下一个AI应用程序的最佳选择。
如果您有任何建议和反馈,请通过Twitter (opens new window)或Discord (opens new window)与我们联系。



