
更新(2023-10-17):查看我们的新博客文章比较MyScale与Postgres和OpenSearch:对整合向量数据库的探索 (opens new window),以了解MyScale和PostgreSQL之间的全面比较。
人工智能和机器学习应用的快速增长,特别是涉及大规模数据分析的应用,增加了对能够高效存储、索引和查询向量嵌入的向量数据库的需求。因此,向量数据库(如MyScale、Pinecone和Qdrant)继续得到开发和扩展,以满足这些需求。
与此同时,传统数据库也在不断改进其向量数据存储和检索能力。例如,著名的关联数据库PostgreSQL及其pgvector扩展提供了类似的功能,尽管效果不如经过优化的向量数据库。
使用通用数据库(如PostgreSQL)存在性能、准确性和其他方面的显著差异。这些差异可能导致性能和数据规模方面的瓶颈。为了解决这些问题,建议升级到更高效的向量数据库,如MyScale。
MyScale与其他专门的向量数据库的区别在于,它能够在不影响高性能的情况下提供完整的SQL支持。这使得从PostgreSQL迁移到MyScale的过程更加顺畅和简单。
为了证明这一点,让我们考虑一个使用PostgreSQL数据库存储向量数据但存在性能和数据规模瓶颈的用例。因此,作为解决方案,我们决定升级到MyScale。
# 从PostgreSQL迁移数据到MyScale
从PostgreSQL升级到MyScale的核心部分是从旧数据库迁移数据到新数据库。让我们看看如何完成这一过程。
注意:
为了演示如何从PostgreSQL迁移数据到MyScale,我们必须设置两个数据库,即使我们的用例中已经有向量数据存储在PostgreSQL数据库中。
在开始之前,重要的是要注意我们将使用以下环境和数据集:
# 环境
| 数据库 | 级别 | 数据库版本 | 扩展版本 |
|---|---|---|---|
| Supabase上的PostgreSQL (opens new window) | 免费(最多500MB的数据库空间) | 15.1 | pgvector 4.0 |
| MyScale (opens new window) | 开发(最多500万个768维向量) | 0.10.0.0 |
# 数据集
我们使用了LAION-400-MILLION开放数据集 (opens new window)中的前100万行(确切数量为1,000,448行)作为演示,以展示迁移后数据规模继续增加的情况。
注意:
该数据集包含4亿条记录,每条记录由一个512维向量组成。
# 将数据加载到PostgreSQL
如果您已经了解PostgreSQL和pgvector,可以通过点击此处跳过迁移过程,直接进入迁移过程。
第一步是通过按照以下逐步指南操作将数据加载到PostgreSQL数据库中:
# 创建PostgreSQL数据库并设置环境变量
按照以下步骤在Supabase中创建带有pgvector的PostgreSQL实例:
- 转到Supabase网站 (opens new window)并登录。
- 创建一个组织并命名。
- 等待组织及其数据库创建完成。
- 启用
pgvector扩展。
以下GIF进一步描述了此过程。

一旦创建了PostgreSQL数据库并启用了pgvector,下一步是配置以下三个环境变量,以使用psql建立与PostgreSQL的连接:
export PGHOST=db.qwbcctzfbpmzmvdnqfmj.supabase.co
export PGUSER=postgres
export PGPASSWORD='********'
此外,运行以下脚本以增加内存和请求持续时间限制,确保我们运行的任何SQL查询不会被中断:
$ psql -c "SET maintenance_work_mem='300MB';"
SET
$ psql -c "SET work_mem='350MB';"
SET
$ psql -c "SET statement_timeout=4800000;"
SET
$ psql -c "ALTER ROLE postgres SET statement_timeout=4800000;";
ALTER ROLE
# 创建PostgreSQL数据表
执行以下SQL语句以创建PostgreSQL数据表。确保向量列(text_embedding和image_embedding)的类型为vector(512)。
注意:
向量列必须与数据的向量维度保持一致。
$ psql -c "CREATE TABLE laion_dataset (
id serial,
url character varying(2048) null,
caption character varying(2048) null,
similarity float null,
image_embedding vector(512) not null,
text_embedding vector(512) not null,
constraint laion_dataset_not_null_pkey primary key (id)
);"
# 将数据插入PostgreSQL表中
将数据分批插入500K行。
注意:
我们只插入了前500K行,以测试数据插入的成功程度,然后再添加其余的数据。
$ wget https://myscale-datasets.s3.ap-southeast-1.amazonaws.com/laion_dataset.sql.tar.gz
$ tar -zxvf laion_dataset.sql.tar.gz
$ cd laion_dataset
$ psql < laion_dataset_id_lt500K.sql
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
...
# 构建ANN索引
下一步是创建使用近似最近邻搜索(ANN)的索引。
注意:
将lists参数设置为1000,因为预期的数据表中的行数为100万行。(https://github.com/pgvector/pgvector#indexing (opens new window))
$ psql -c "CREATE INDEX ON laion_dataset
USING ivfflat (image_embedding vector_cosine_ops)
WITH (lists = 1000);";
CREATE INDEX
# 执行SQL查询
最后一步是通过执行以下SQL语句来测试一切是否正常:
$ psql -c "SET ivfflat.probes = 100;
SELECT id, url, caption, image_embedding <=> (SELECT image_embedding FROM laion_dataset WHERE id=14358) AS dist
FROM laion_dataset WHERE id!=14358 ORDER BY dist ASC LIMIT 10;"
如果您的结果集与我们的结果集相似,则可以继续进行。
| id | url | caption | dist |
|---|---|---|---|
| 134746 | Pretty Ragdoll cat on white background Royalty Free Stock Image | 0.0749262628626345 | |
| 195973 | cat sitting in front and looking at camera isolated on white background Stock Photo | 0.0929287358264965 | |
| 83158 | Abyssinian Cat Pictures | 0.105731256045087 | |
| 432425 | Russian blue kitten Stock Images | 0.108455925228164 | |
| 99628 | Norwegian Forest Cat on white background. Show champion black and white Norwegian Forest Cat, on white background royalty free stock image | 0.111603095925331 | |
| 478216 | himalayan cat: Cat isolated over white background | 0.115501832572401 | |
| 281881 | Sealpoint Ragdoll lying on white background Stock Images | 0.121348724151614 | |
| 497148 | Frightened black kitten standing in front of white background | 0.127657010206311 | |
| 490374 | Lying russian blue cat Stock Photo | 0.129595023570348 | |
| 401134 | Maine coon cat on pastel pink Stock Image | 0.130214431419139 |
# 将其余数据插入PostgreSQL表中
将其余数据添加到PostgreSQL表中。这对于验证pgvector在规模上的性能非常重要。
$ psql < laion_dataset_id_ge500K_lt1m.sql
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
...
ERROR: cannot execute INSERT in a read-only transaction
ERROR: cannot execute INSERT in a read-only transaction
正如您从此脚本的输出(以及下面的图片)中可以看到的那样,插入其余数据会返回错误。Supabase将PostgreSQL实例设置为只读模式,防止超出免费级别限制的存储消耗。
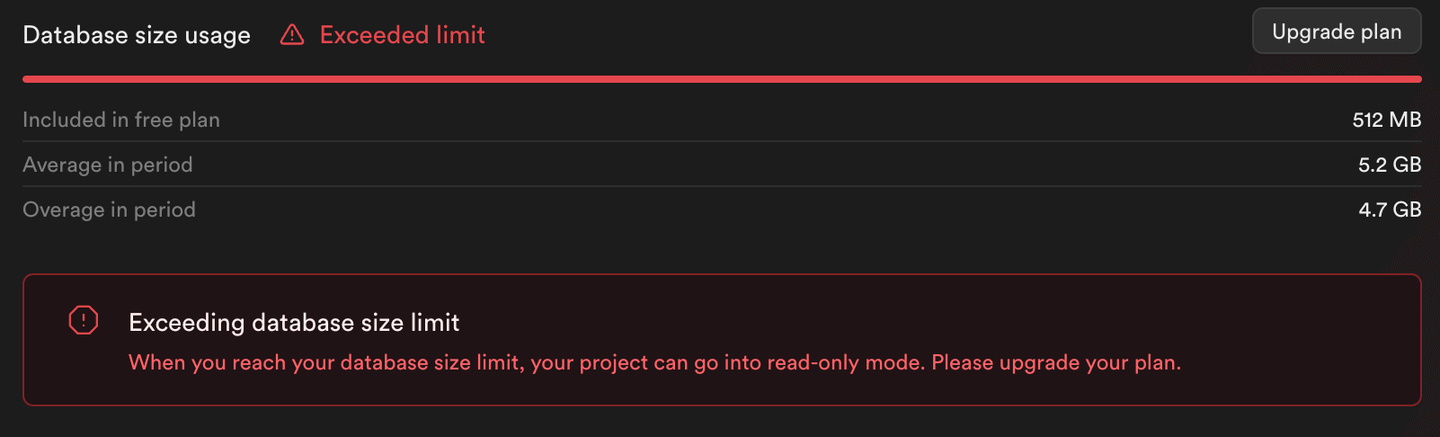
注意:
只有插入了500K行到PostgreSQL表中,而不是1M行。
# 迁移到 MyScale
现在,让我们通过以下逐步指南将数据迁移到MyScale:
注意:
MyScale不仅是一个高性能的集成向量数据库,而且基准测试报告显示,与其他专门的向量数据库相比,MyScale在搜索性能、准确性和资源利用方面都表现出色(/myscale-outperform-specialized-vectordb/)。MyScale的专有向量索引算法Multi-Scale Tree Graph(MSTG)使用本地NVMe SSD作为缓存磁盘,显著提高了支持的索引规模,相比于内存情况。
# 创建MyScale集群
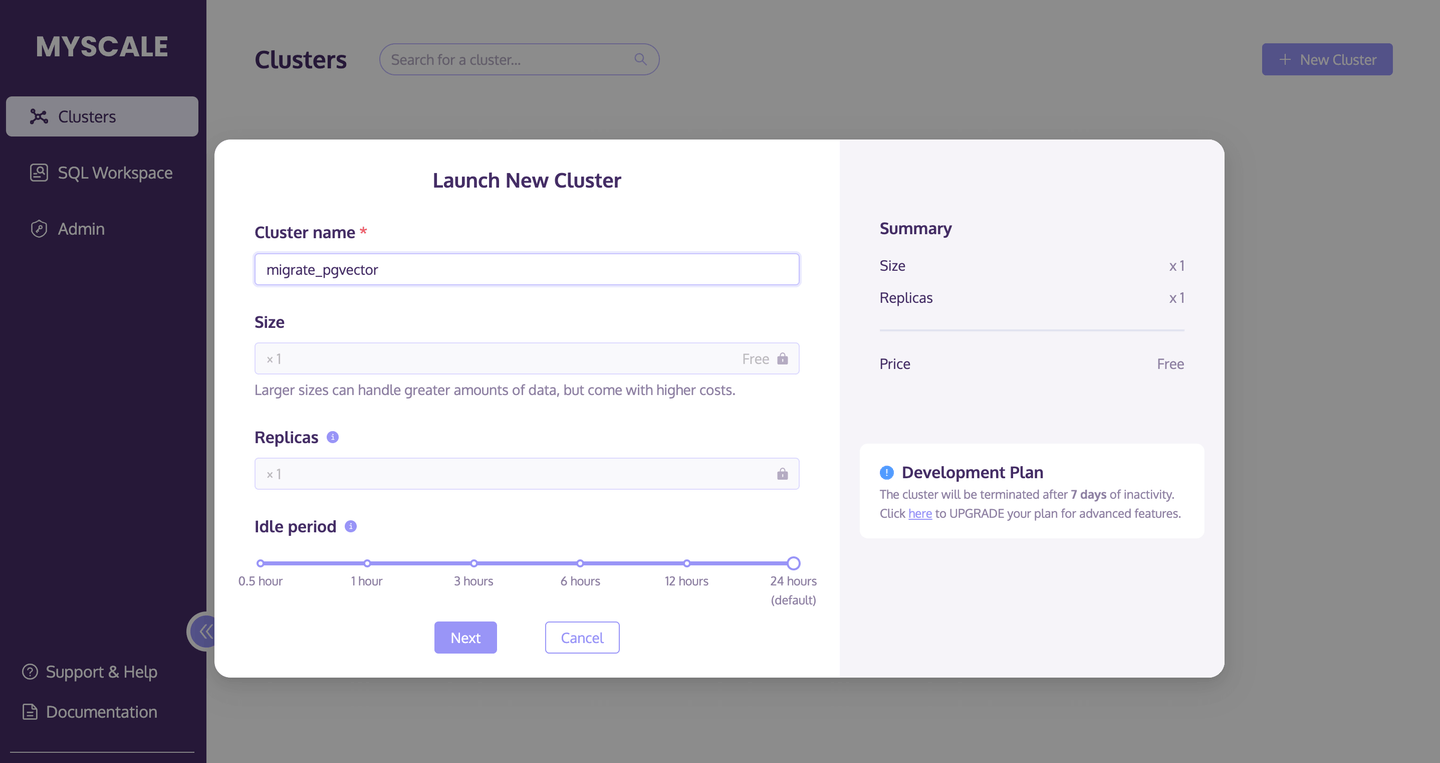
第一步是创建并启动一个新的MyScale集群。
- 转到Clusters页面 (opens new window),点击**+New Cluster**按钮来启动一个新的集群。
- 给集群命名。
- 点击Launch运行集群。
以下图片进一步描述了此过程:
# 创建数据表
一旦集群运行,执行以下SQL脚本以创建新的数据库表:
CREATE TABLE laion_dataset
(
`id` Int64,
`url` String,
`caption` String,
`similarity` Nullable(Float32),
`image_embedding` Array(Float32),
CONSTRAINT check_length CHECK length(image_embedding) = 512,
`text_embedding` Array(Float32),
CONSTRAINT check_length CHECK length(text_embedding) = 512
)
ENGINE = MergeTree
ORDER BY id;
# 从PostgreSQL迁移数据
在创建数据库表后,使用the PostgreSQL() table engine (opens new window)轻松从PostgreSQL迁移数据。
INSERT INTO default.laion_dataset
SELECT id, url, caption, similarity, image_embedding, text_embedding
FROM PostgreSQL('db.qwbcctzfbpmzmvdnqfmj.supabase.co:5432',
'postgres', 'laion_dataset',
'postgres', '************')
SETTINGS min_insert_block_size_rows=65505;
注意:
添加了min_insert_block_size_rows设置,以限制每批插入的行数,防止过多的内存使用。
# 确认插入的总行数
使用SELECT count(*)语句确认是否将所有数据从PostgreSQL表迁移到MyScale。
SELECT count(*) FROM default.laion_dataset;
以下结果集显示迁移成功,因为此查询返回500K(500000)行。
| count() |
|---|
| 500000 |
# 构建数据库表索引
下一步是使用索引类型MSTG和metric_type(距离计算方法)为cosine来构建索引。
ALTER TABLE default.laion_dataset
ADD VECTOR INDEX laion_dataset_vector_idx image_embedding
TYPE MSTG('metric_type=cosine');
一旦此ALTER TABLE语句执行完毕,下一步是检查索引的状态。运行以下脚本,如果status返回为Built,则索引已成功创建。
SELECT database, table, type, status FROM system.vector_indices;
| database | table | type | status |
|---|---|---|---|
| default | laion_dataset | MSTG | Built |
# 执行ANN查询
运行以下脚本,使用刚刚创建的MSTG索引执行ANN查询。
SELECT id, url, caption,
distance('alpha=4')(image_embedding,
(SELECT image_embedding FROM laion_dataset WHERE id=14358)
) AS dist
FROM default.laion_dataset where id!=14358 ORDER BY dist ASC LIMIT 10;
如果以下结果表与PostgreSQL查询的结果一致,则数据迁移成功。
| id | url | caption | dist |
|---|---|---|---|
| 134746 | Pretty Ragdoll cat on white background Royalty Free Stock Image | 0.0749262628626345 | |
| 195973 | cat sitting in front and looking at camera isolated on white background | 0.0929287358264965 | |
| 83158 | Abyssinian Cat Pictures | 0.105731256045087 | |
| 432425 | Russian blue kitten Stock Images | 0.108455925228164 | |
| 99628 | Norwegian Forest Cat on white background. Show champion black and white... | 0.111603095925331 | |
| 478216 | himalayan cat: Cat isolated over white background | 0.115501832572401 | |
| 281881 | Sealpoint Ragdoll lying on white background Stock Images | 0.121348724151614 | |
| 497148 | Frightened black kitten standing in front of white background | 0.127657010206311 | |
| 490374 | Lying russian blue cat Stock Photo | 0.129595023570348 | |
| 401134 | Maine coon cat on pastel pink Stock Image | 0.130214431419139 |
# 将其余数据插入MyScale表中
让我们将其余数据添加到MyScale表中。
# 从CSV/Parquet导入数据
好消息是,我们可以直接从Amazon S3存储桶中导入数据,使用以下MyScale方法:
INSERT INTO laion_dataset
SELECT * FROM s3(
'https://myscale-datasets.s3.ap-southeast-1.amazonaws.com/laion-1m-pic-vector.csv',
'CSV',
'id Int64, url String, caption String, similarity Nullable(Float32), image_embedding Array(Float32), text_embedding Array(Float32)')
WHERE id >= 500000 SETTINGS min_insert_block_size_rows=65505;
这将自动化数据插入过程,减少手动以500K行为一批添加行的时间。
# 确认插入的总行数
再次运行以下SELECT count(*)语句,以确认是否将S3存储桶中的所有数据导入到MyScale中。
SELECT count(*) FROM default.laion_dataset;
以下结果集显示已导入正确数量的行。
| count() |
|---|
| 1000448 |
注意:
MyScale的免费Pod最多可以存储500万个768维向量。
# 执行ANN查询
我们可以使用与上面相同的SQL查询,在包含100万行的数据集上执行查询。
为了提醒您,以下是SQL语句:
SELECT id, url, caption, distance('alpha=4')(image_embedding,
(SELECT image_embedding FROM laion_dataset WHERE id=14358)) AS dist
FROM default.laion_dataset WHERE id!=14358 ORDER BY dist ASC LIMIT 10;
以下是查询结果集,包括新添加的数据:
| id | url | caption | dist |
|---|---|---|---|
| 134746 | 漂亮的布偶猫在白色背景上的免版税库存图片 | 0.07492614 | |
| 195973 | 猫坐在前面,看着摄像机,孤立在白色背景上的库存照片 | 0.09292877 | |
| 693487 | 俄罗斯蓝猫,神秘的猫,友好的猫,弗朗西斯·辛普森,猫品种,猫品种 | 0.09316337 | |
| 574275 | 混种猫,Felis catus,6个月大的免版税库存照片 | 0.09820753 | |
| 83158 | 阿比西尼亚猫图片 | 0.10573125 | |
| 797777 | 橘色猫的男性猫名字 | 0.10775411 | |
| 432425 | 俄罗斯蓝猫的小猫库存图片 | 0.10845572 | |
| 99628 | 挪威森林猫在白色背景上。展示冠军黑白相间的... | 0.1116029 | |
| 864554 | 一只缅因猫小猫坐着,抬头看着,4个月大,孤立在白色背景上 | 0.11200631 | |
| 478216 | 喜马拉雅猫:孤立在白色背景上的猫 | 0.11550176 |

# 总结
本文讨论了将矢量数据从PostgreSQL迁移到MyScale的简单性。即使在通过从PostgreSQL迁移数据和导入新数据来增加MyScale中的数据量时,MyScale的性能仍然可靠,无论数据集的大小如何。俗话说得好:“越大越好”,在这方面是正确的。即使查询超大型数据集,MyScale的性能仍然可靠。
因此,如果您的业务遇到数据规模或性能瓶颈,我们强烈建议按照本文中概述的步骤将数据迁移到MyScale。



