
如果你想要快速构建 AI 应用,Dify 是你的新优选;如果你希望在 Dify 中找到理想的 AI 应用数据库底座,那么 MyScaleDB (opens new window) 将是你的最佳选择。是的,Dify 的最新版本中已经集成了 SQL 向量数据库 MyScaleDB,并支持向量检索、全文检索和混合检索。现在,开发者不仅能利用 MyScaleDB 强大的 SQL 能力与向量搜索功能,还能通过 Dify 的直观界面轻松编排和调试 prompt,快速创建智能客服、文本生成等多种 AI 应用。此次集成让 AI 应用开发变得前所未有的简单有趣,为 AI 社区注入了更多活力与创意。
# What is Dify
Dify (opens new window) 是新一代开源的大型语言模型应用模型开发平台,旨在帮助开发者更简单、快速地构建和运营AI应用。它具有以下主要特点和功能:
- 可视化 Prompt 编排:通过界面化编写和调试 prompt,使开发者能够快速创建AI应用。
- 数据集管理:支持上传和管理企业知识库或产品文档,用于构建基于特定领域知识的AI应用。
- API 集成:提供封装友好的 API,可以轻松集成到现有系统中。
- 开箱即用的 WebApp:提供可直接使用的网页应用界面,也支持二次开发。
- 多模型支持:集成了多种大语言模型,如 OpenAI GPT 系列、Anthropic Claude 系列等,方便开发者选择和比较。
- 低代码开发:提供可视化界面,使得非技术人员也能参与 AI 应用的创建和优化。
- 运营和分析工具:包括数据标注、日志分析等功能,帮助持续改进 AI 应用的性能。
Dify 的设计理念是让 AI 应用开发变得像使用云计算服务一样简单,开发者无需深入了解底层技术细节,就能快速将创意转化为实际可用的 AI 应用。它适合用于构建各种场景的AI应用,如智能客服、基于企业知识库的问答系统、文本生成工具等。
# What is MyScaleDB
MyScaleDB 是一个开源的高性能 SQL 向量数据库 (opens new window),基于 ClickHouse 构建,完全兼容 SQL 语法,支持向量搜索、全文搜索、带过滤条件的向量搜索和 SQL-向量联合查询。MyScaleDB 统一了 SQL 数据库、数据仓库、向量数据库和全文搜索引擎,提供高效的多模态数据管理。
在 LLM 应用的可观测性方面, MyScaleDB AI 数据库擅长存储海量的 agent 执行记录数据,并通过 MyScaleDB Telemetry (opens new window) 收集和分析 RAG 系统在 MyScaleDB 上运行时的各种数据且提供有价值的分析。这有助于用户根据这些数据分析优化 agent 工作流程,调优模型,不断提高系统的可靠性和性能。
MyScaleDB 专为构建和扩展 AI 应用而设计,其目标是在保证强大的数据处理能力的同时,帮助开发者使用熟悉的 SQL 更简单、高效地构建和扩展 AI 应用。它适用于需要处理大规模向量数据,并结合结构化数据进行复杂查询的AI应用场景。
# 在 Dify 中使用 MyScaleDB
# 创建 MyScaleDB Cluster
Dify 支持开源版 MyScaleDB 或 企业版 MyScaleDB Cloud (opens new window),如果希望使用开源版 MyScaleDB,可以跳过本节;如果希望使用 MyScaleDB Cloud,请首先访问 https://console.MyScaleDB.com (opens new window) 注册并登录,然后点击右上角的 New Cluster 按钮,开始创建 MyScaleDB Cluster。
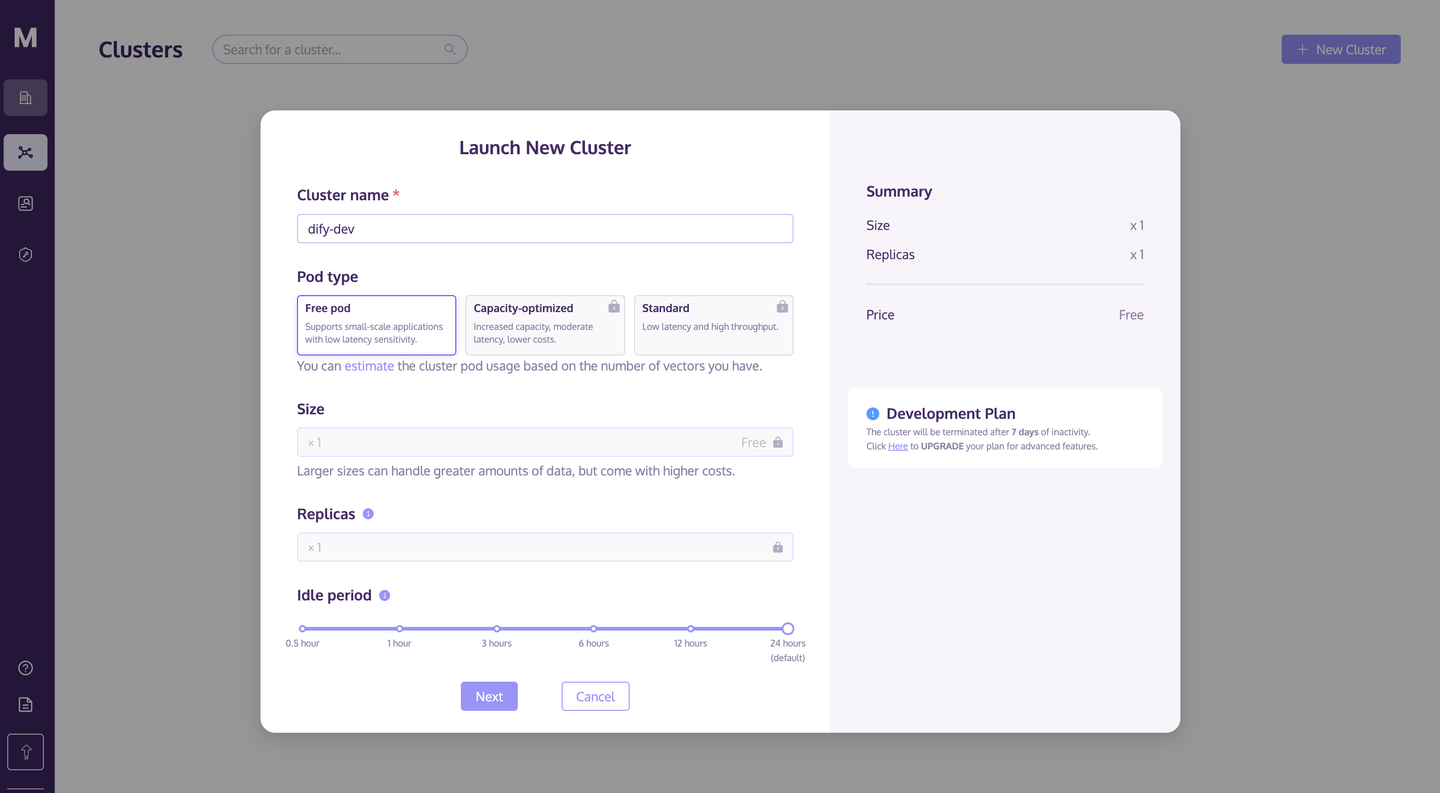
输入 Cluster name 后,点击 Next 按钮,等待 Cluster 启动完成
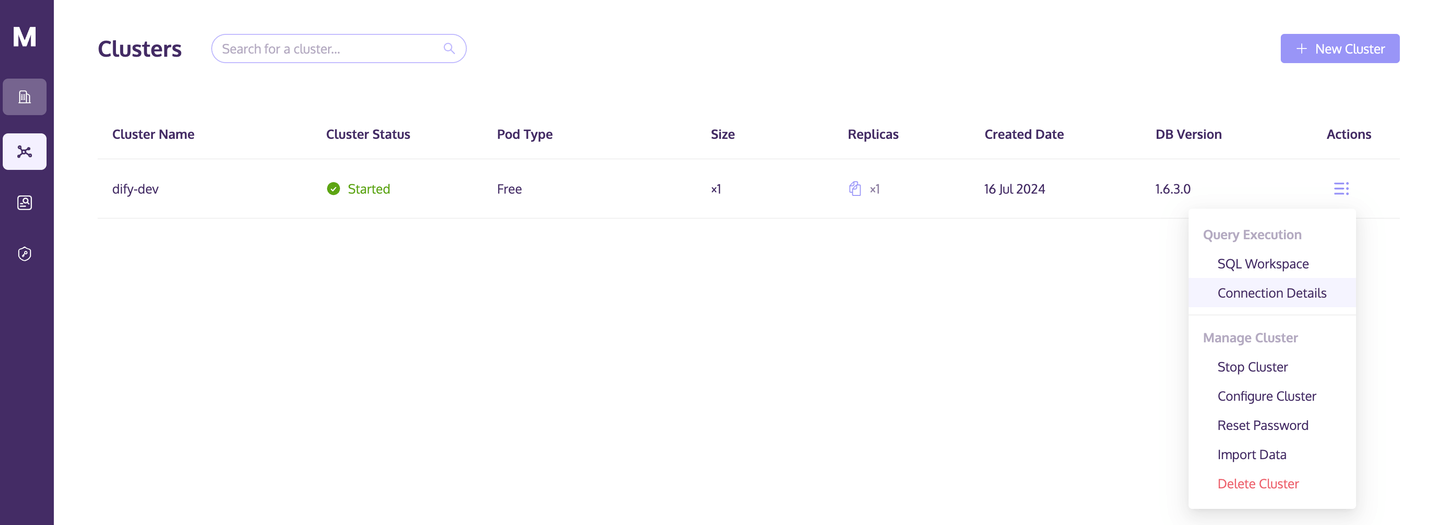
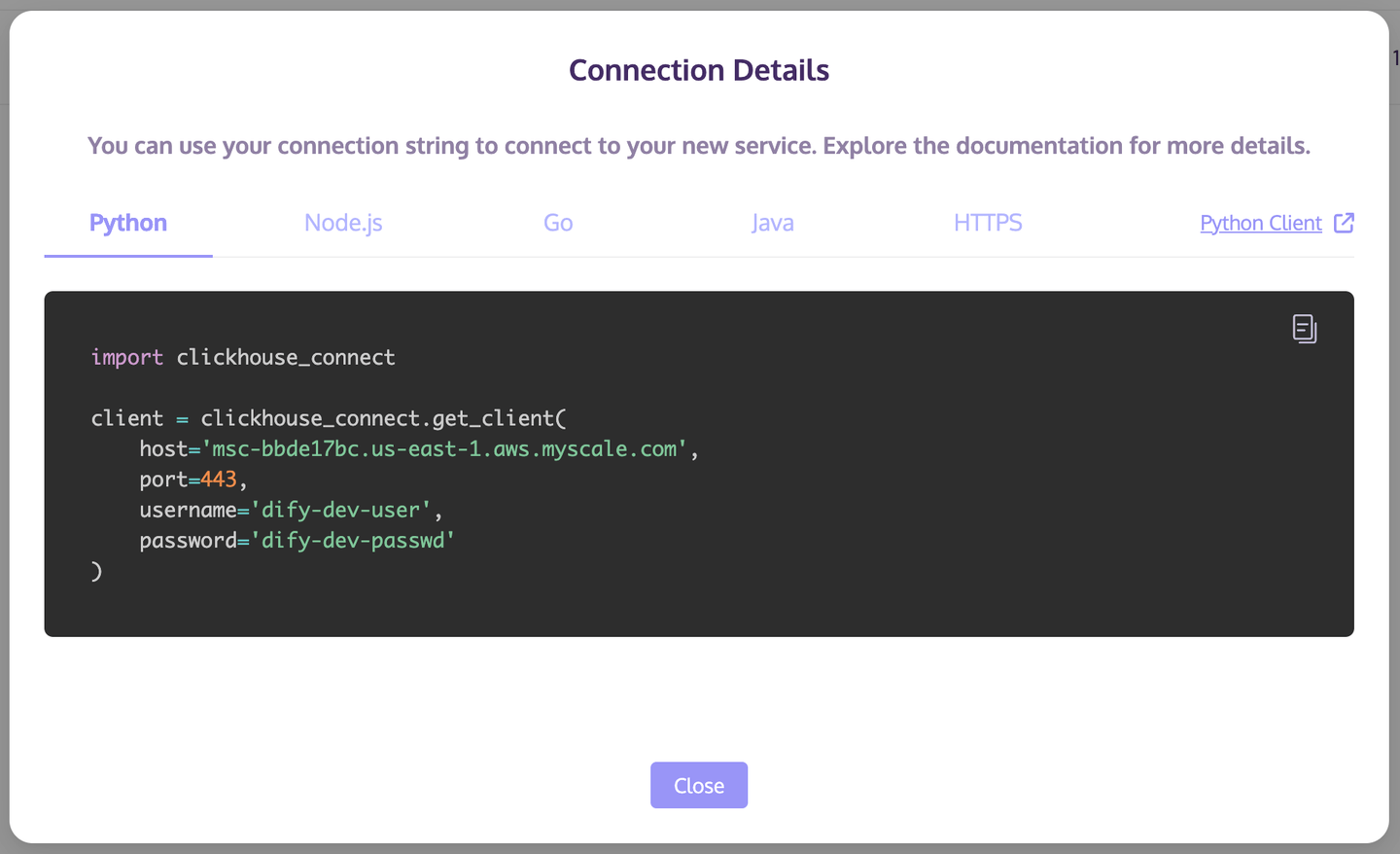
把鼠标移至 Cluster 右侧的 Actions 按钮,点击弹出列表中的 Connection Details,记录 Python 标签页中的 host/port/username/password 信息,用于后续配置 Dify 对 MyScaleDB Cluster 的访问
# 配置和运行 Dify
在 Dify 中使用 MyScaleDB,首先需要部署 Dify 社区版,推荐参考官方文档 (opens new window)
使用 docker compose 启动 dify 之前,修改 .env 文件,填写 MyScaleDB 相关配置:
- 首先将
VECTOR_STORE改为MyScaleDB
VECTOR_STORE=MyScaleDB
- 如果使用 MyScaleDB.com (opens new window) 的云服务,按照网页上获取到的信息修改对应配置(
MyScaleDB_DATABASE可以不改);如果希望使用开源版 MyScaleDB DB,下列配置可以保持不变:
MyScaleDB_HOST=MyScaleDB
MyScaleDB_PORT=8123
MyScaleDB_USER=default
MyScaleDB_PASSWORD=
MyScaleDB_DATABASE=dify
- 如果需要支持多语言,比如中文的文档,请参考 MyScaleDB 官方文档 (opens new window) 配置
MyScaleDB_FTS_PARAMS参数。例如使用中文分词器,MyScaleDB 中创建全文索引的 SQL 如下(文本信息在 MyScaleDB 表中的 column name 为text):
ALTER TABLE [table_name] ADD INDEX text_idx text
TYPE fts('{"text":{"tokenizer":{"type":"chinese", "case_sensitive":false}}}');
相对应地修改 MyScaleDB_FTS_PARAMS 为:
MyScaleDB_FTS_PARAMS='{"text":{"tokenizer":{"type":"chinese", "case_sensitive":false}}}'
- 修改完毕后,启动 Dify。
docker compose up -d
- 在浏览器中访问 http://localhost (opens new window) 使用 Dify。
在 Dify 知识库 (opens new window)中,用户可以选择使用 MyScaleDB,且 MyScaleDB 同时支持向量检索、全文检索和混合检索。用户可以在创建知识库时选择其中一种检索方式 (opens new window)。

# 对企业以及开发人员的好处
# 开发门槛极低
Dify 通过简化开发流程、提供可视化工具和各种开箱即用的功能,创造低代码开发环境,让开发者甚至非技术人员都能参与 AI 应用的创建和优化。而 MyScaleDB 完全兼容 SQL,开发者可以使用熟悉的 SQL 语法进行向量搜索、全文搜索、带过滤条件的向量搜索和 SQL-向量联合查询等操作,无需学习复杂的新工具或框架。另外,MyScaleDB 还提供了统一的平台来管理和处理结构化数据、向量数据、文本等多种类型的数据,简化了开发流程。两者的结合大大降低了 AI 应用开发和运营的门槛,使得更多开发者能够快速构建和扩展 AI 应用。
# 高性能和可扩展性
Dify 内置了高质量的 RAG(检索增强生成)引擎,可以有效提升基于知识库的 AI 应用的准确性和响应速度。Dify 的设计支持应用的快速扩展,可以随着业务需求的增长轻松扩展AI应用的规模和功能。另外,Dify 还提供包括提示词工程、上下文管理、日志分析和数据标注等功能,帮助用户持续优化 AI 应用。
MyScaleDB 利用先进的 OLAP 数据库架构和自研的先进 MSTG 向量算法,不仅可以轻松地扩展应用,还能保证快速地向量搜索。MyScaleDB Telemetry 提供了类似于 LangSmith (opens new window) 的功能,用于改进 LLM 应用程序的可观察性和评估。通过与 LangChain Callbacks 无缝集成, 它捕获详细的跟踪数据并将其存储在 MyScaleDB 中,从而便于诊断问题、优化性能和了解应用程序行为。
# 高性价比
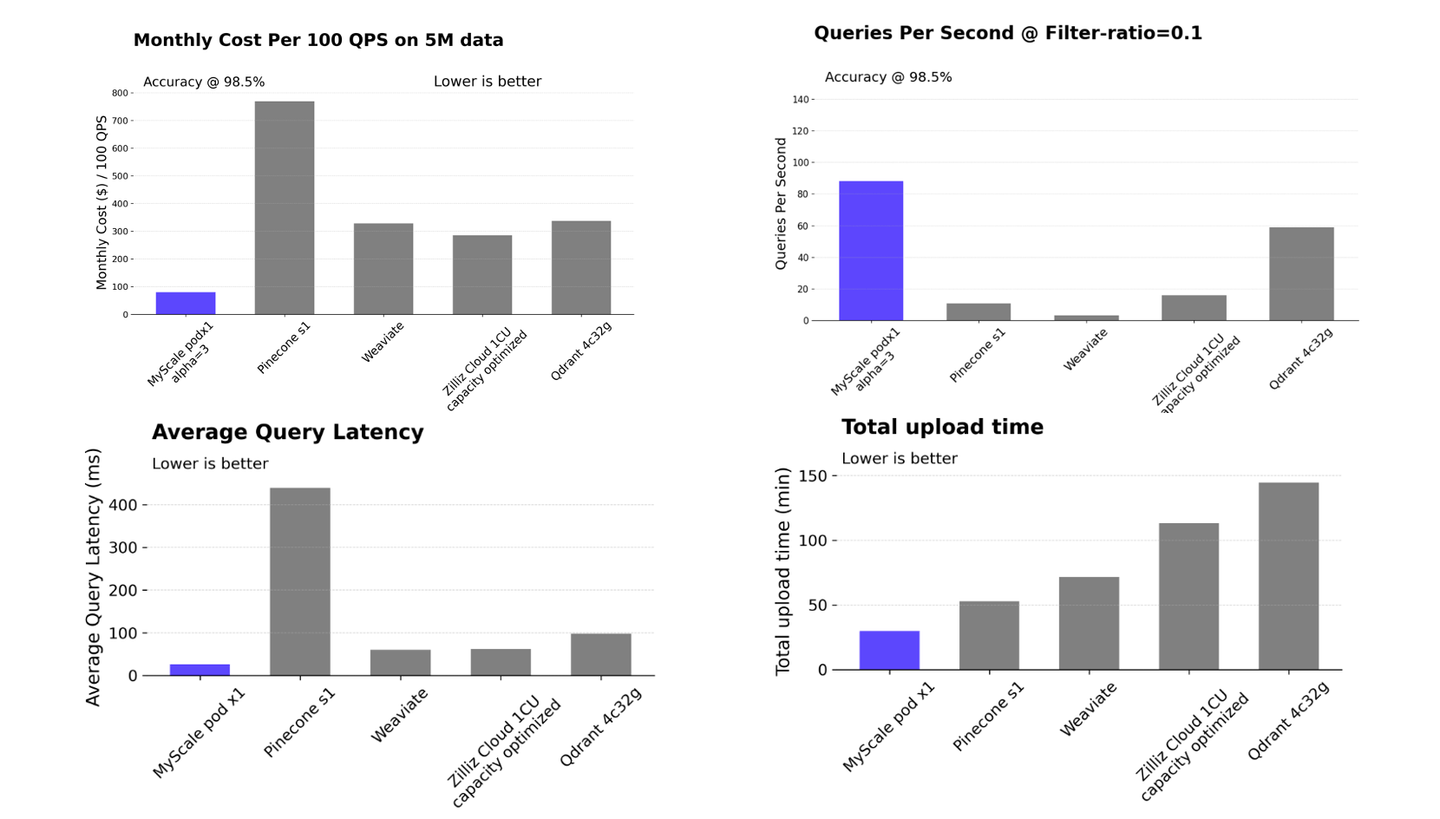
Dify 与多种向量数据库实现了集成,用户可以根据需求挑选合适的底层数据库。而 MyScaleDB 作为其集成的唯一 SQL 向量数据库,一方面实现了在同一个数据库中提供向量检索、全文检索和混合检索,无需额外启用 Elasticsearch;另一方面,对比其他专有向量数据库如 weaviate 和 Qdrant, MyScaleDB 基本的检索性能对处理大规模数据极具优势。
# 写在最后
展望未来,MyScaleDB 和 Dify 将继续深入合作,共同探索 AI 创新应用的更多新方向。我们相信,这种强强联手将为开发者带来更多便捷、高效的工具,推动 AI 技术在各个领域的广泛应用。MyScaleDB 也将一如既往地致力于高性能向量数据库的创新和发展,不断提升我们的技术能力和服务水平,为开源社区和 AI 生态系统注入更多活力与动能。让我们携手并进,共同推动 AI 时代的到来,创造更加智能和便捷的未来。
我们会在后续的文章中为大家详细展示如何使用 MyScaleDB 与 Dify 构建 AI 应用,敬请期待。如果你希望与我们继续讨论或分享 MyScaleDB 与 Dify 结合使用的案例,欢迎在 Discord (opens new window) 上联系我们。



