
注意:
我们在开源项目 vector-db-benchmark (opens new window) 中,持续更新MyScale和其他向量数据库产品的基准测试结果。
普遍认为,关系型数据库无法与专用向量数据库的性能相媲美。例如,与Pinecone等专用向量数据库相比,带有向量扩展的PostgreSQL在性能上存在显著劣势。这就是为什么今天有这么多专用向量数据库可用的原因。人们之所以更喜欢关系型数据库,是因为它具有生产就绪性、强大的功能集、支持和社区、集成、安全性以及熟悉且功能强大的SQL语言等各种原因。在专用向量数据库中,所有这些功能都在某种程度上受到了影响。
如果我们有一个关系型数据库可以与甚至超越专用向量数据库的性能相媲美呢?
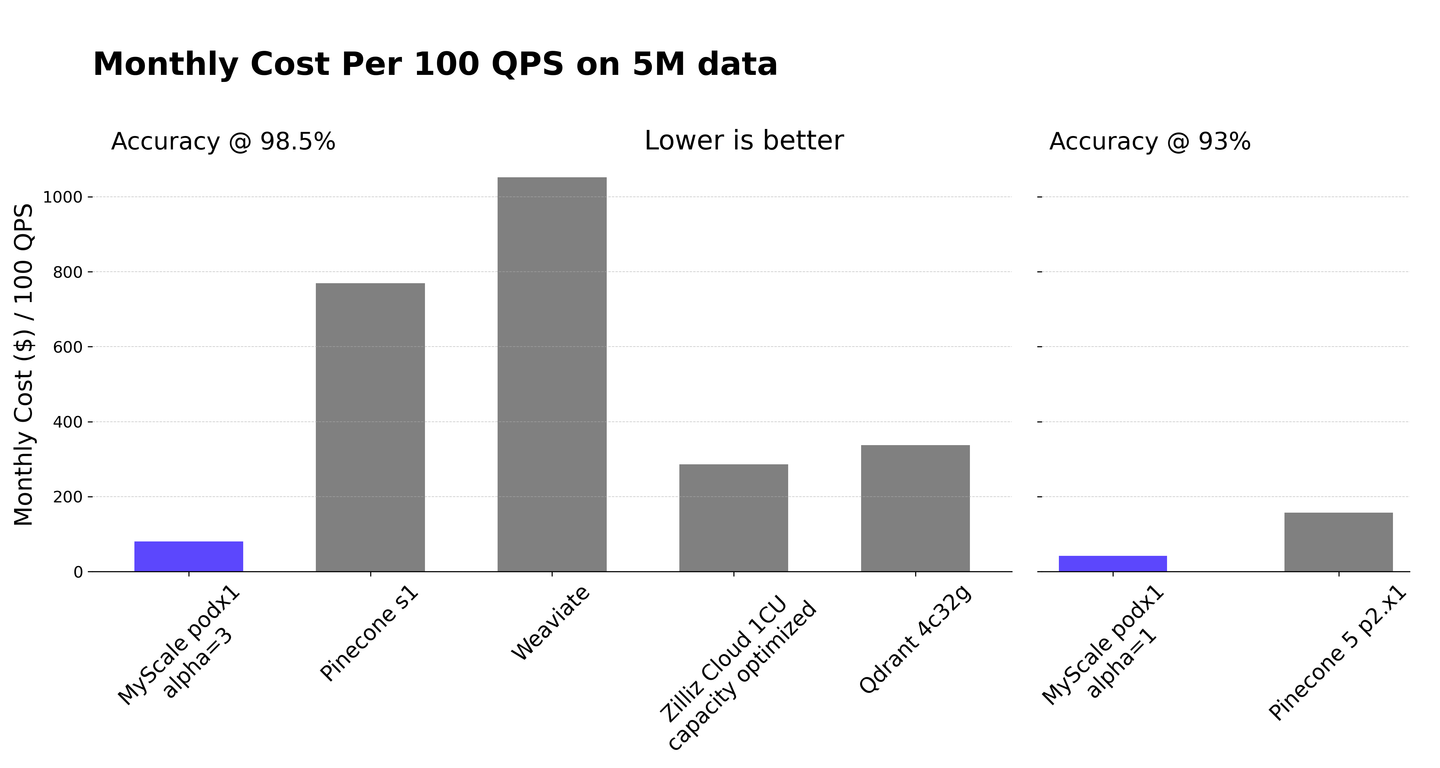
我们非常高兴地宣布,MyScale的重大升级正好实现了这一目标。首次,关系型数据库可以在向量性能方面超越最先进的专用向量数据库,同时保留了所有关系型数据库和SQL的优势。在与领先的专用向量数据库Pinecone进行直接比较时,MyScale在查询速度上比Pinecone的s1 pod快10倍,在数据密度上比其p2 pod快5倍。 在考虑到成本效益时,MyScale在各种精度水平上比其他性能最佳的专用向量数据库更具成本效益,提高了3.6倍。 下图中有所体现。尽管Pinecone是一种领先的数据库,但在这种情况下,成本效益的比较是与一系列最佳性能的专用向量数据库进行的,而不仅仅是Pinecone。
这是通过无缝地将结构化数据和向量与一系列涉及算法和系统工程的创新相结合来实现的:
- 算法创新。 向量数据库的核心是最近邻搜索算法。与大多数依赖于相同一组算法(如IVF和HNSW或其变体)的向量数据库不同,这些数据库具有类似的性能限制。MyScale实现了一种名为MSTG(多尺度树图)的专有算法,其性能优于IVF和HNSW,有时甚至超过10倍。
- 系统工程。 MyScale构建在ClickHouse之上。我们喜欢ClickHouse的高性能和广泛的功能集。然而,它也存在一些众所周知的问题和系统开销。我们进行了许多系统改进和错误修复,以使向量与ClickHouse配合使用(其中一些已经贡献给ClickHouse社区,例如轻量级删除)。
现在可以通过MyScale获得的性能升级,使用户能够创建更强大的AI应用程序。MyScale包括以下关键功能:
- 高数据容量和性能: 在MyScale中,单个标准pod支持500万个768维数据点,具有高准确性,每秒可实现超过150个查询(QPS)。
- 快速数据摄入: 在不到30分钟的时间内摄入500万个数据点,最大限度地减少等待时间,使您能够更快地提供向量数据。
- 支持多个索引: 您可以在每个MyScale pod中创建具有唯一向量索引的多个表(请参阅向量参考 (opens new window))。通过利用此功能和高数据容量,您可以在一个MyScale集群中高效地管理异构向量数据,进一步降低系统复杂性和成本。
- 简单的数据导入和备份: 支持Parquet或压缩tar文件等标准格式,您可以使用单个SQL命令轻松地从S3或其他兼容的对象存储系统导入/导出数据 (opens new window)。
MyScale目前处于测试版阶段,提供免费的开发者层级,并计划推出商业计划。据我们所知,MyScale是第一个支持500万个768维向量数据点的免费计划,具有高性能搜索。
# 将MyScale与领先的向量数据库服务进行基准测试
在本文中,我们对MyScale与其他广泛使用的向量数据库服务进行了全面的基准测试比较。基准测试的代码和结果可在此处 (opens new window)公开获取,并将定期更新。本文包含了关键发现的简明总结。
此基准测试选择的服务包括Pinecone、Qdrant、Weaviate和Zilliz Cloud等行业领先者。我们根据数据摄入时间、搜索QPS(每秒查询数)和平均延迟这三个关键参数对这些服务进行了评估。用于测试的数据集包含从LAION 2B图像 (opens new window)生成的500万个768维向量。此数据集也是公开可访问的 (opens new window)。
在此基准测试中,我们主要关注具有高容量的服务。因此,当一个服务提供多个pod配置时,我们选择具有最大数据密度的配置。例如,Pinecone的s1 pod和Zilliz Cloud的容量优化1CU,它们都提供了500万向量数据容量。此外,MyScale、Weaviate和Zilliz Cloud等服务提供了用于平衡搜索速度和准确性的各种调优选项。在MyScale的情况下,我们选择了alpha=3的配置,该配置提供了98.5%的前10个召回率,并将其与具有类似准确性水平的其他服务进行了比较。所有测试都使用四个并行客户端连接进行。
# 成本性能比
这项基准测试研究的一个重要组成部分是成本性能比的评估,它衡量了每月成本与服务每百个单位的QPS(每秒查询数)之间的比率。它量化了实现500万向量数据点上的100 QPS所需的每月成本。我们的分析突出了MyScale的卓越成本性能比,它比其他向量数据库便宜了3.6倍以上。尽管Pinecone的s1具有较高的数据密度,但其较低的QPS导致成本性能比较低。Weaviate的成本效益受到其定价结构的限制,该结构按查询数量进行缩放。即使以每月最低查询率为一次,基本成本仍为192美元/月,而平均QPS为5时,成本将上升到690美元/月,这是用于计算成本效益的前图中的值。尽管Zilliz Cloud具有大量的数据存储容量,但其QPS较低,对其成本性能比产生了负面影响。Qdrant云需要32GB内存才能高效管理500万个数据点,从而增加了成本。尽管调查了许多HNSW调优参数,并选择了m=32和ef_c=256以获得最佳性能,但每秒查询数(QPS)不足以获得令人满意的成本性能比。
为了进行全面比较,我们还对Pinecone的p2 pod进行了研究。每个p2 pod支持100万个768维数据,我们选择了5个p2.x1扩展配置,以容纳数据并尽量降低成本。Pinecone的p2的前10个召回率约为93%,低于其他向量数据库服务的性能,但与MyScale的alpha=1设置的性能相当。因此,我们在右图中对Pinecone p2进行了单独比较。在这种情况下,MyScale比5个p2.x1更具成本效益,提高了3.7倍。本文的其余部分主要强调高准确性设置,与向量数据库服务的普遍标准一致。
以下是本文中测试的服务的摘要,有关每个服务的成本性能比,请参见前图。
| 准确性 | 服务 | QPS | 每月成本(美元) | 备注 |
|---|---|---|---|---|
| 98.5% | MyScale的标准pod(alpha=3) | 150 | 120 | 测试版,免费试用,标准层级即将推出 |
| Pinecone s1 | 9 | 69 | GCP基本价格 | |
| Weaviate | 66 | 690 | 计算的总月查询次数为5 * 3600 * 24 * 30 | |
| Zilliz Cloud 1CU容量优化 | 63 | 186 | - | |
| Qdrant 4c32g | 81 | 273 | HNSW m=32 ef_c=256 | |
| 93% | MyScale的标准pod(alpha=1) | 288 | 120 | - |
| Pinecone 5 p2.x1 | 331 | 518 | 5个p2 pod的水平扩展 |
让我们来看一些更具体的性能指标,例如QPS、平均查询延迟和数据摄入时间。
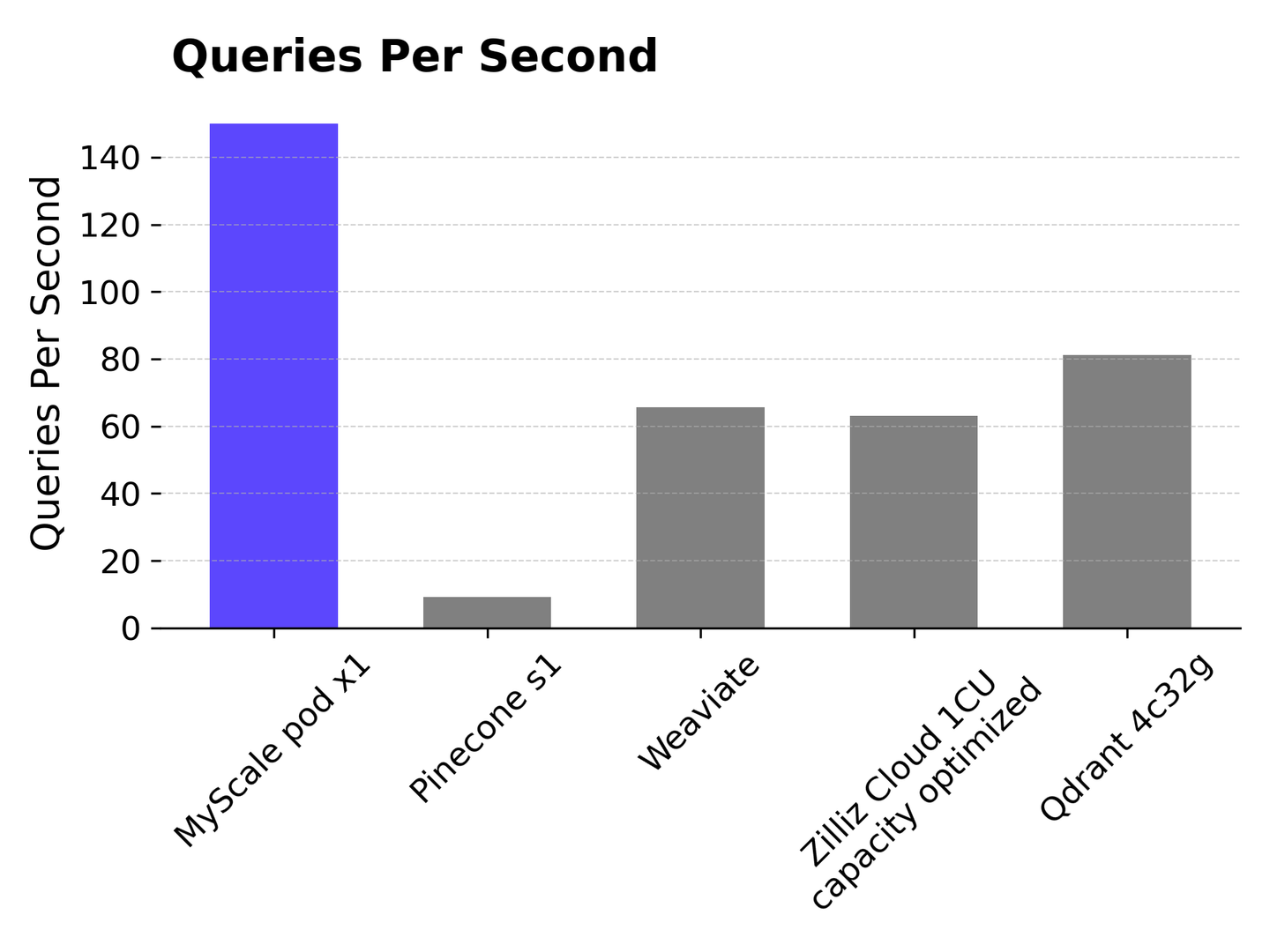
# 每秒查询数(QPS)
MyScale在LAION 500万数据集上的QPS方面超越其他向量数据库,具有98.5%的前10个召回率,实现了超过150个QPS。相比之下,Pinecone s1的QPS约为10,远低于MyScale。Weaviate和Zilliz Cloud的QPS都在65左右,而Qdrant的QPS为81。
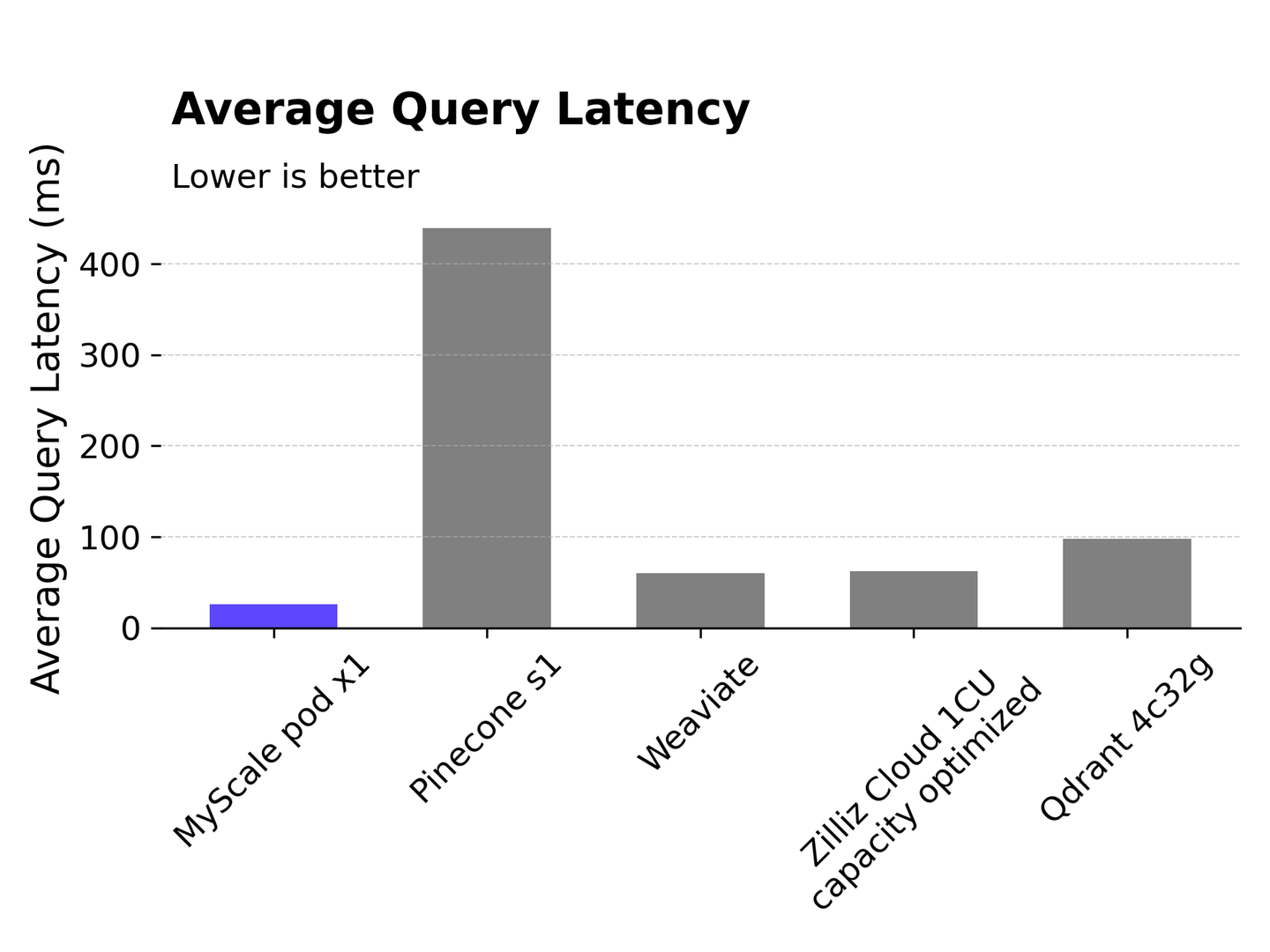
# 平均查询延迟
查询延迟是一个重要的性能指标,它是从客户端发送请求到接收响应的时间。MyScale在保持平均延迟低至25.8毫秒的同时,实现了150个QPS。Pinecone s1的延迟相对较高,超过400毫秒。Weaviate和Zilliz Cloud的延迟都在60毫秒左右,而Qdrant的延迟略高,约为100毫秒。
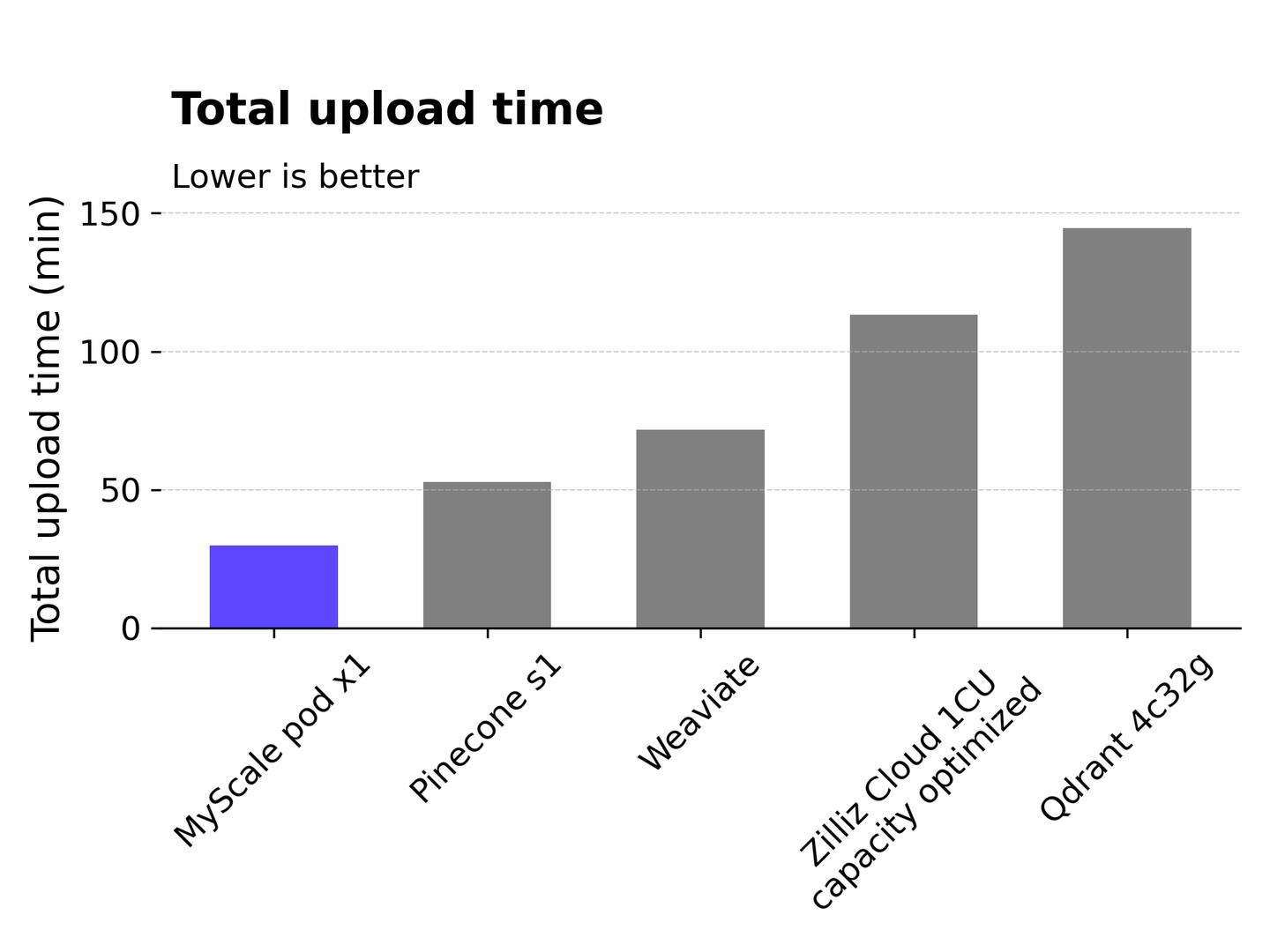
# 数据摄入时间
数据上传到向量索引准备就绪的时间称为数据摄入时间。索引创建可能需要很长时间,特别是对于基于图的算法(如HNSW)来说。在所有测试的服务中,MyScale在500万数据点的摄入时间方面最快,完成任务约30分钟。Pinecone s1大约需要53分钟,而Weaviate需要72分钟。Zilliz Cloud需要更长的时间,约113分钟,而Qdrant的摄入时间最长,需要145分钟来处理500万数据点。

# 结论
总之,基于ClickHouse的MyScale证明了可以通过实现3.6倍更高的成本效益来超越专用向量数据库,同时保留了关系型数据库和SQL的所有优势。而这只是个开始。
MyScale 现已正式推出,并提供免费的开发者版本。商业版本提供额外功能,包括增加的数据容量以及多重复制和多区域可用性。有关更多信息,请通过contact@myscale.com与我们联系,或加入我们的Discord (opens new window)。



