
在快速发展的 LLM 应用程序领域,实现强大的可观察性对于确保最佳性能和可靠性至关重要。 然而,由于 LLM 应用程序的复杂性和规模,追踪和存储运行时事件并不容易。为了解决这些挑战, 我们发布了 MyScale Telemetry (opens new window),它与 LangChain Callbacks (opens new window) 集成。
该回调无缝捕获基于 LangChain 的 LLM 应用程序的跟踪数据,并将其存储在 MyScaleDB (opens new window) 中, 从而便于诊断问题、优化性能和了解模型行为。MyScale Telemetry 提供了类似于 LangSmith (opens new window) 的功能, 包括追踪和评估 LLM 应用程序,并作为 LangSmith 的开源替代方案。此外,由于 MyScaleDB 兼容 ClickHouse, MyScale Telemetry 可以直接与 ClickHouse 一起使用。
在接下来的章节中,我们将详细介绍 MyScale Telemetry 的功能和用法。
# MyScale Telemetry 的工作原理
将 MyScale Telemetry 与 LangChain 集成非常简单。 回调处理程序会自动为 LangChain 应用程序的每个运行时事件创建一个嵌套跟踪。 这些运行时事件包括:
on_chain_starton_chain_endon_llm_starton_llm_endon_chat_model_starton_retriever_starton_retriever_endon_tool_starton_tool_endon_tool_erroron_chain_erroron_retriever_erroron_llm_error
然后,收集的运行时事件数据会被组织成跟踪数据,类似于 OpenTelemetry 跟踪数据 (opens new window),并存储在 MyScale 数据库中的专用跟踪数据表中。 表结构如下:
CREATE TABLE your_database_name.your_table_name
(
`TraceId` String CODEC(ZSTD(1)),
`SpanId` String CODEC(ZSTD(1)),
`ParentSpanId` String CODEC(ZSTD(1)),
`StartTime` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`EndTime` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`Duration` Int64 CODEC(ZSTD(1)),
`SpanName` LowCardinality(String) CODEC(ZSTD(1)),
`SpanKind` LowCardinality(String) CODEC(ZSTD(1)),
`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),
`SpanAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`StatusCode` LowCardinality(String) CODEC(ZSTD(1)),
`StatusMessage` String CODEC(ZSTD(1)),
INDEX idx_trace_id TraceId TYPE bloom_filter(0.001) GRANULARITY 1,
INDEX idx_res_attr_key mapKeys(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_res_attr_value mapValues(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_span_attr_key mapKeys(SpanAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_span_attr_value mapValues(SpanAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_duration Duration TYPE minmax GRANULARITY 1
)
ENGINE = MergeTree()
PARTITION BY toDate(StartTime)
ORDER BY (SpanName, toUnixTimestamp(StartTime), TraceId);
然后,用户可以分析这些跟踪数据,有效地调试和改进他们的 LLM 应用程序。 MyScale Telemetry 在提供丰富的可观察性洞察力的同时,确保最小的性能影响, 使开发人员能够深入了解应用程序的行为和性能。
# 示例用法
我们将通过一个完整的示例来指导您如何开始使用 MyScale Telemetry。 此示例包括设置 MyScaleDB (opens new window) 和 Grafana 仪表板 (opens new window) 以存储和监视跟踪数据, 以及使用 Ragas (opens new window) 进行评估。 按照以下步骤进行设置和有效使用:
# 设置 MyScaleDB 和 Grafana
首先,使用 Docker Compose 设置 MyScaleDB 和 Grafana 实例。
docker-compose.yml 文件可以在 这里 (opens new window) 找到。运行以下命令启动容器:
docker-compose up -d
# 安装所需的软件包
接下来,使用 pip 安装 MyScale Telemetry 软件包以及 LangChain 和 LangChain OpenAI 集成和 Ragas:
pip install myscale-telemetry langchain_openai ragas
# 构建一个简单的链式结构
然后,构建一个简单的 LangChain 链式结构,并将其与 MyScaleCallbackHandler 集成以进行跟踪数据收集。
import os
from myscale_telemetry.handler import MyScaleCallbackHandler
from operator import itemgetter
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.vectorstores import MyScale
from langchain_community.vectorstores.myscale import MyScaleSettings
from langchain_core.runnables import RunnableConfig
# 设置 OpenAI 和 MyScale Cloud/MyScaleDB 的环境变量:
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_KEY"
os.environ["MYSCALE_HOST"] = "YOUR_MYSCALE_HOST"
os.environ["MYSCALE_PORT"] = "YOUR_MYSCALE_HOST"
os.environ["MYSCALE_USERNAME"] = "YOUR_MYSCALE_USERNAME"
os.environ["MYSCALE_PASSWORD"] = "YOUR_MYSCALE_PASSWORD"
# 使用 MyScale 和 OpenAI embeddings 创建一个向量存储和检索器:
texts = [
"Harrison worked at Kensho.",
"Alice is a software engineer.",
"Bob enjoys hiking on weekends.",
"Claire is studying data science.",
"David works at a tech startup.",
"Eva loves playing the piano.",
"Frank is a graphic designer.",
"Grace is an artificial intelligence researcher.",
"Henry is a freelance writer.",
"Isabel is learning machine learning."
]
myscale_settings = MyScaleSettings()
myscale_settings.index_type = 'SCANN'
vectorstore = MyScale.from_texts(texts, embedding=OpenAIEmbeddings(), config=myscale_settings)
retriever = vectorstore.as_retriever()
# 设置 LLM 和提示模板:
model = ChatOpenAI()
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# 创建链式结构
chain = (
{
"context": itemgetter("question") | retriever,
"question": itemgetter("question"),
}
| prompt
| model
| StrOutputParser()
)
# 集成 MyScaleCallbackHandler 以在链式执行过程中捕获跟踪数据:
chain.invoke({"question": "where did harrison work"}, config=RunnableConfig(
callbacks=[
MyScaleCallbackHandler()
]
))
成功运行后,您将能够在 MyScaleDB 的 otel.otel_traces 表中找到相应的跟踪数据。
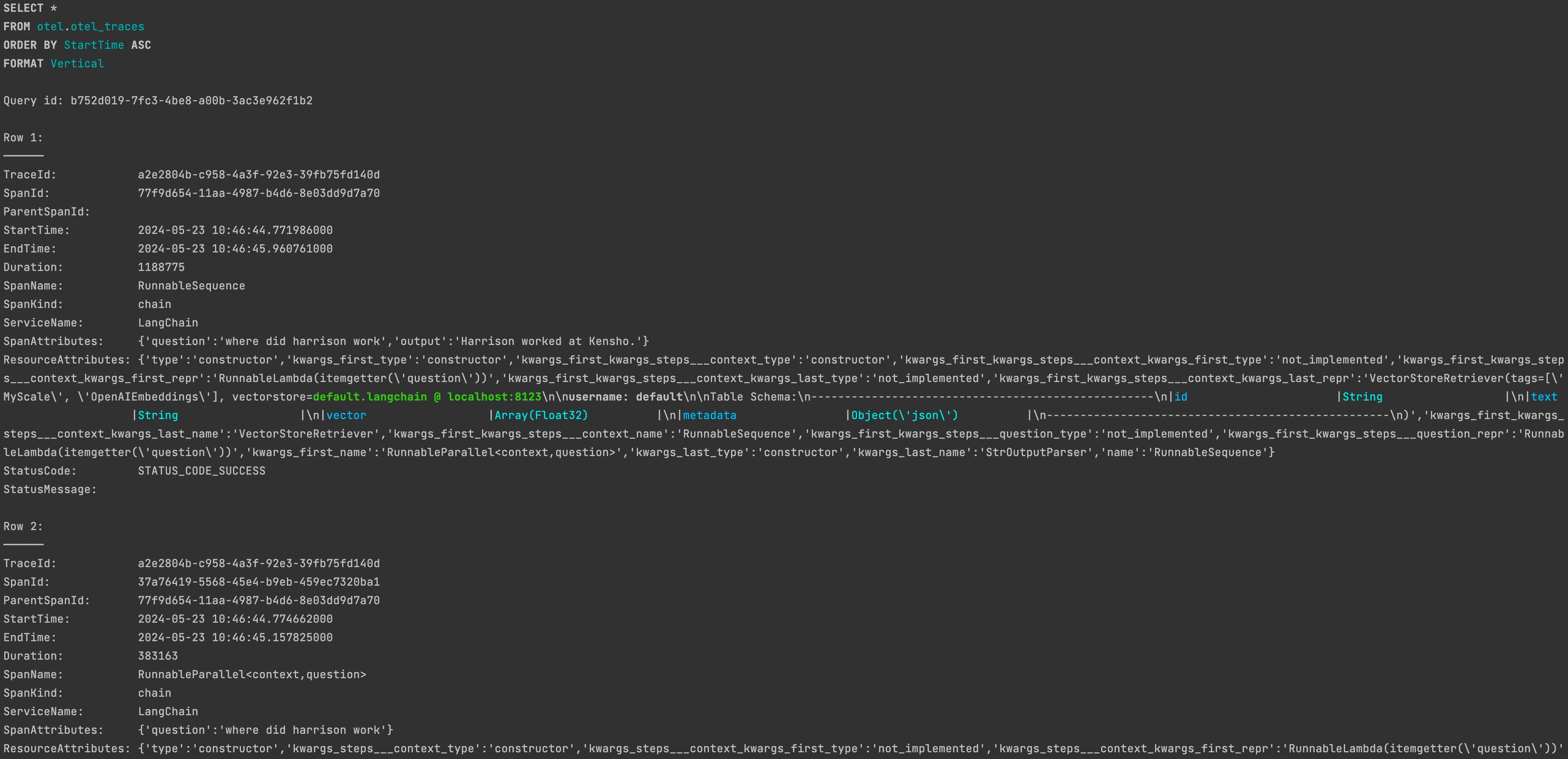 有关自定义
有关自定义 MyScaleCallbackHandler 的详细信息,请参阅文档:MyScale Telemetry 自定义参数 (opens new window)。
# 可观察性
为了方便清晰地显示通过 MyScale Telemetry 从 LLM 应用程序运行时收集的跟踪数据,我们还提供了一个 Grafana 跟踪仪表板 (opens new window)。 该仪表板允许用户监视与 LangSmith 类似的 LLM 应用程序的状态,使调试和改进其性能更加容易。
Docker Compose 示例会在 http://localhost:3000 (opens new window) 启动一个 Grafana 实例。使用用户名 admin 和密码 admin 进行登录。
# 设置跟踪仪表板
在使用 MyScale Telemetry Handler 收集跟踪数据后,按照以下步骤设置 MyScale 跟踪仪表板:
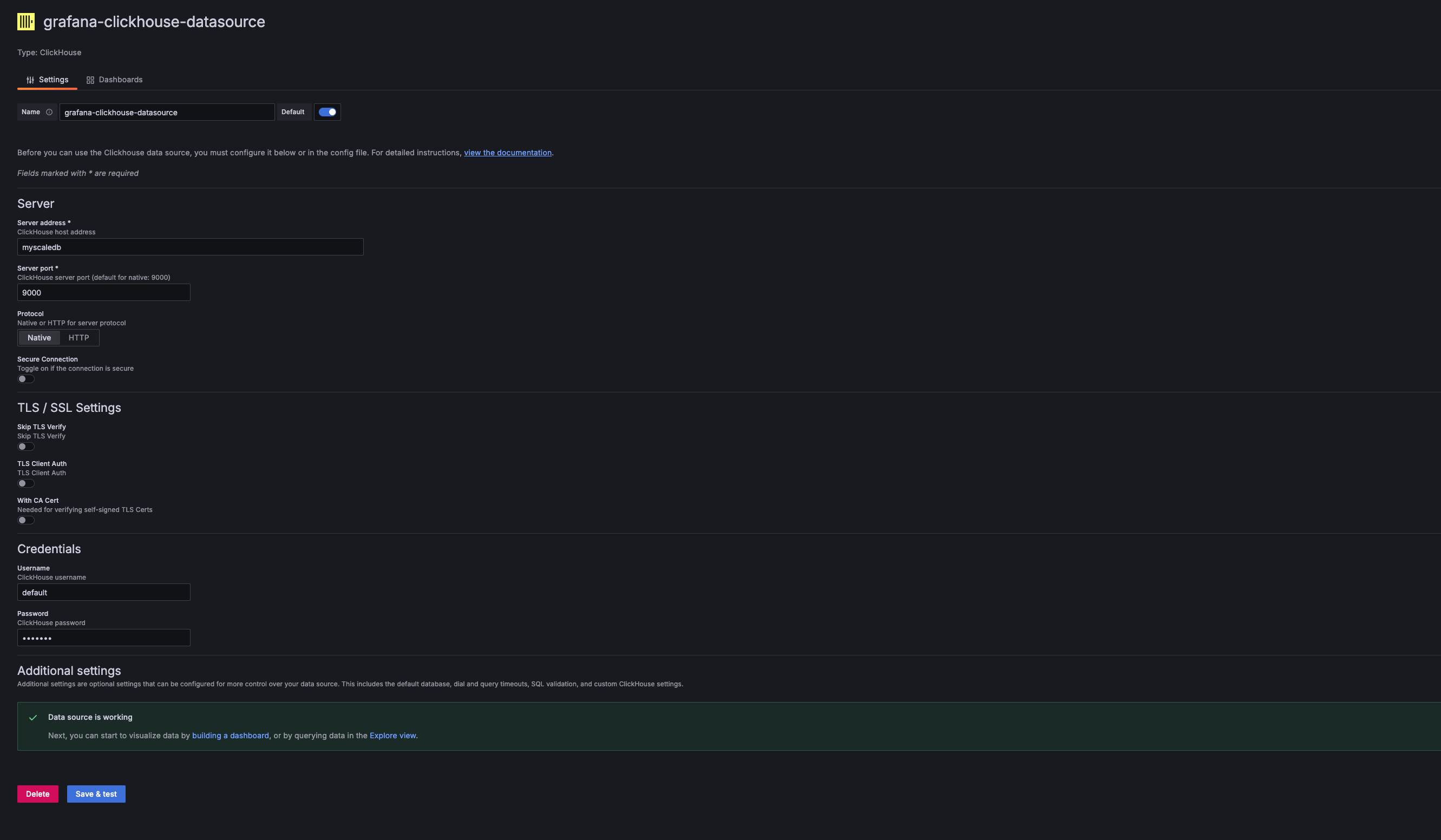
在 Grafana 中添加新的 ClickHouse 数据源:
在 Grafana 数据源设置中,添加一个新的 ClickHouse 数据源。服务器地址、服务器端口、用户名和密码应与使用的 MyScaleDB 的主机、端口、用户名和密码相对应。 对于提供的 Docker Compose 示例,这些值是:
- Address:
myscaledb - Port:
9000 - Username:
default - Password:
default
- Address:
导入 MyScale 跟踪仪表板:
添加 ClickHouse 数据源后,您可以导入 MyScale 跟踪仪表板 (opens new window)。
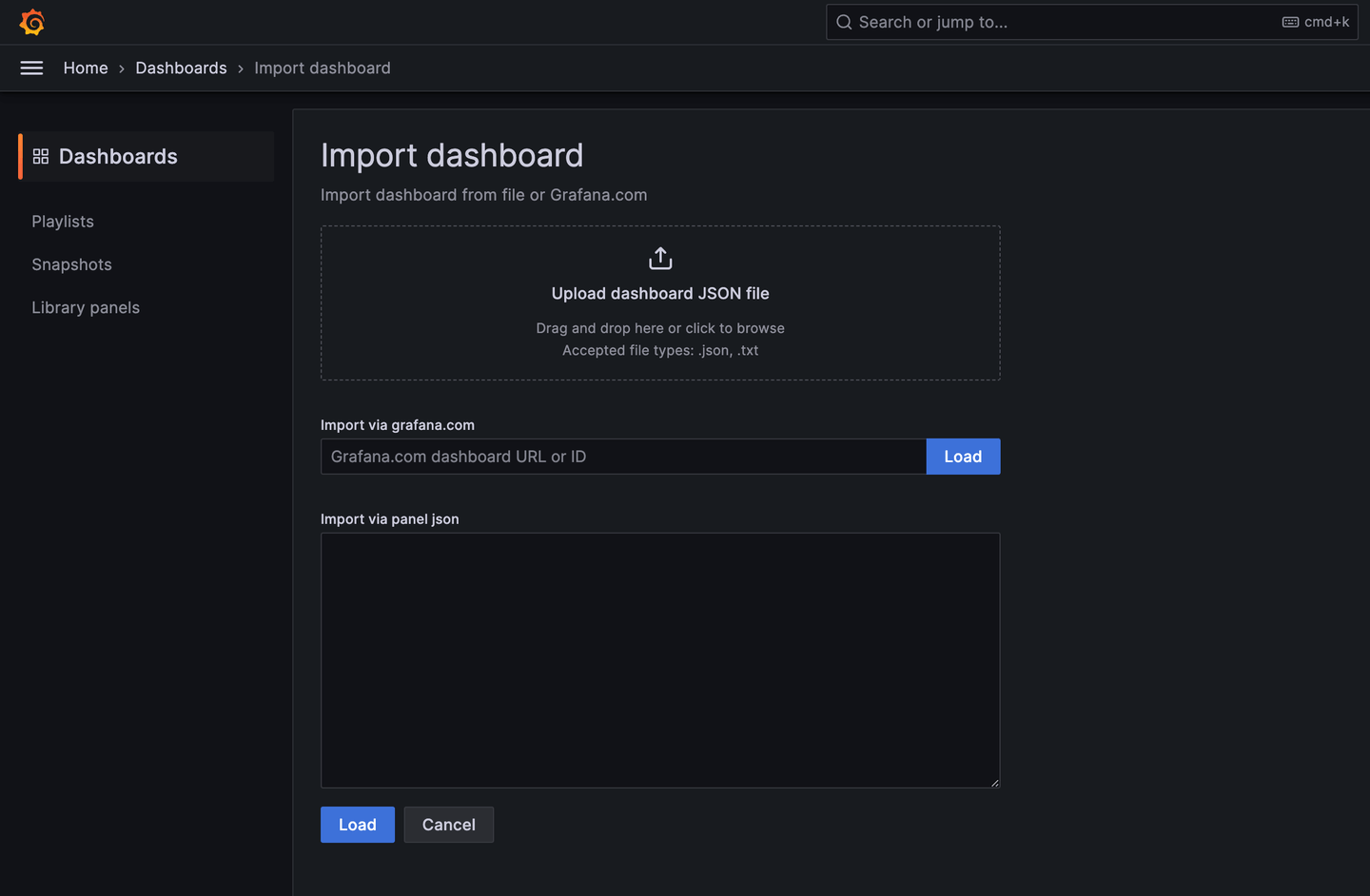
配置仪表板:
导入后,选择 MyScale 集群(Clickhouse 数据源名称)、数据库名称、表名称和要分析的跟踪的 TraceID。然后,仪表板将显示所选跟踪的跟踪表和跟踪详细信息面板。
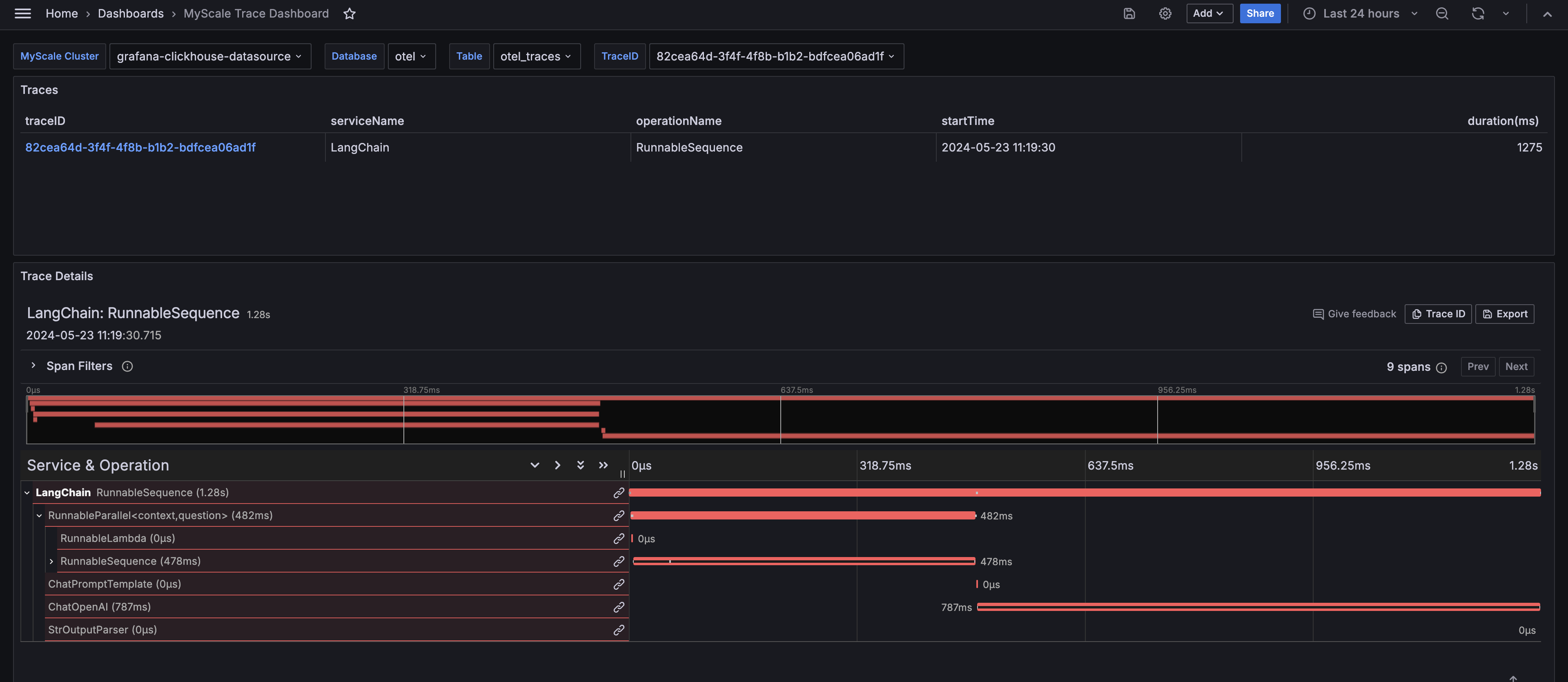
# MyScale 跟踪仪表板的洞察力
MyScale 跟踪仪表板提供了对 LLM 应用程序运行时行为的全面洞察,类似于 LangSmith。它显示了有助于调试、优化和理解应用程序性能的关键信息。
# 函数执行时间
仪表板显示了 LangChain 应用程序中每个函数的执行时间,帮助您识别性能瓶颈。

# 输入和输出
仪表板提供了对链式结构的整体输入和输出的详细视图,便于跟踪数据在应用程序中的流动。

# DB 检索器返回值
它显示了数据库检索器返回的具体数据,让您可以验证正在获取和使用的正确数据。

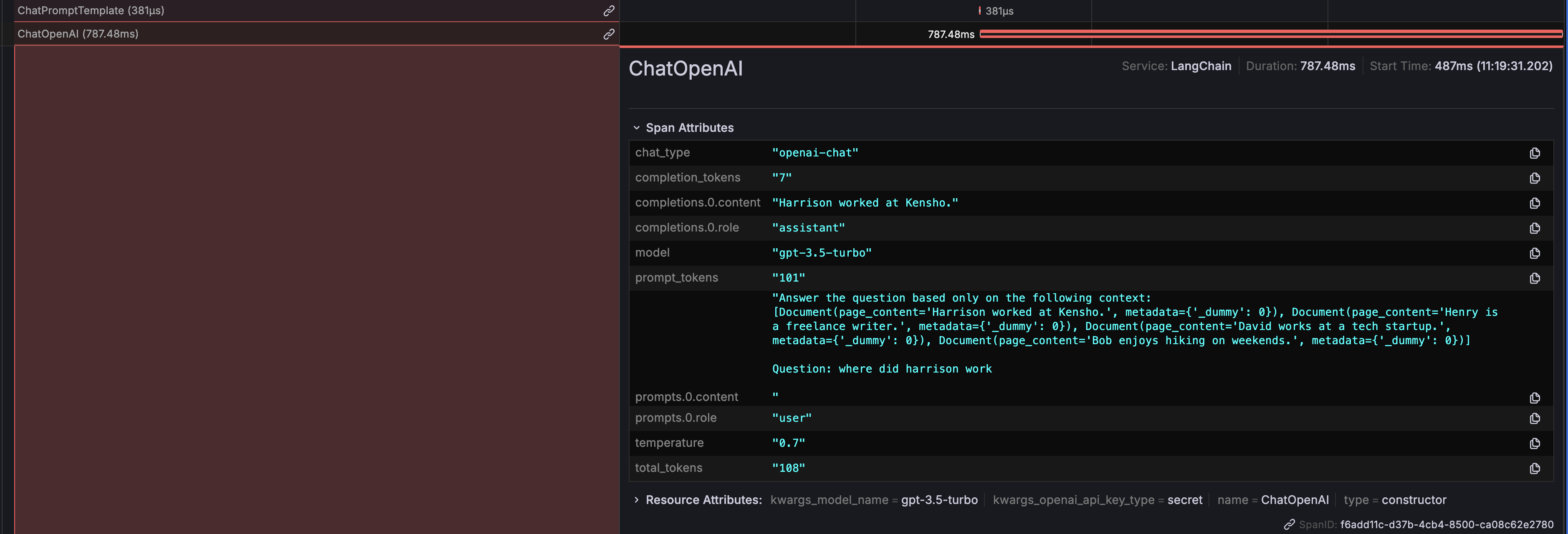
# 提示信息
您可以查看生成并发送给 LLM 的确切提示,这对于确保所提出的问题的正确性和相关性非常重要。

# ChatOpenAI 输出
还显示了 ChatOpenAI 生成的输出,清楚地展示了 LLM 如何响应提示。
此外,还显示了令牌使用详细信息,帮助您监视和优化与 LLM 的 API 调用相关的成本。
# 使用 Ragas 进行评估
存储在 MyScaleDB 中的跨度数据可以用于使用 Ragas (opens new window) 分析和评估 RAG 管道,Ragas 是一个流行的开源 RAG 评估框架。
以下 Python 代码演示了如何使用 Ragas 对跟踪进行评分,评估检索到的上下文和生成的答案:
import os
from datasets import Dataset
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy, context_utilization
from clickhouse_connect import get_client
def score_with_ragas(query, chunks, answer):
test_dataset = Dataset.from_dict({"question": [query], "contexts": [chunks], "answer": [answer]})
result = evaluate(test_dataset, metrics=[faithfulness, answer_relevancy, context_utilization])
return result
def evaluate_trace(question, topk, client, database_name, table_name):
trace_id, answer = client.query(
f"SELECT TraceId, SpanAttributes['output'] as Answer FROM {database_name}.{table_name} WHERE SpanAttributes['question'] = '{question}' AND ParentSpanId = ''"
).result_rows[0]
span_dict = client.query(
f"SELECT SpanAttributes FROM {database_name}.{table_name} WHERE TraceId = '{trace_id}' AND SpanKind = 'retriever'"
).result_rows[0][0]
contexts = [span_dict.get(f"documents.{i}.content") for i in range(topk)]
print(score_with_ragas(question, contexts, answer))
test_question = "where did harrison work"
client = get_client(
host=os.getenv("MYSCALE_HOST"),
port=int(os.getenv("MYSCALE_PORT")),
username=os.getenv("MYSCALE_USERNAME"),
password=os.getenv("MYSCALE_PASSWORD"),
)
evaluate_trace(test_question, 4, client, "otel", "otel_traces")
运行示例后,您将能够使用 Ragas 提供的分数评估您的 RAG 管道的性能。


# 结论
MyScale Telemetry 提供了一个强大的开源解决方案,用于改进 LLM 应用程序的可观察性和评估。通过与 LangChain Callbacks 无缝集成, 它捕获详细的跟踪数据并将其存储在 MyScaleDB 中,从而便于诊断问题、优化性能和了解应用程序行为。
Grafana 中的 MyScale 跟踪仪表板清晰地可视化了这些跟踪数据,帮助您有效地监视和调试 LLM 应用程序。关键洞察包括函数执行时间、输入和输出跟踪、 DB 检索器返回值、提示信息、ChatOpenAI 输出和令牌使用情况。
此外,将 Ragas 与 MyScale Telemetry 集成,可以全面评估 RAG 管道。使用存储在 MyScaleDB 中的跟踪数据,Ragas 可以评估忠实度、答案相关性和上下文利用率等指标, 确保高质量的结果和持续改进。
我们鼓励您尝试使用 MyScale Telemetry 和 Grafana 仪表板,充分利用这些强大的工具。如有任何问题或需要进一步帮助,请随时联系我们的支持团队。



