
在提到数据库时,关系数据库 (opens new window)因其简单性和易用性,长期以来一直是数据存储的默认选择。然而,在当今以数据为驱动的互联网行业中,非结构化数据(如文本、图像和音频)的存储需求日益增多,使得向量数据库 (opens new window)成为了一个可行的替代方案。
向量数据库与传统数据库有显著的功能差异。传统数据库仅限于整数和字符串等原始数据类型,而向量数据库以向量为单位进行数据存储和管理。这使得向量数据库能够高效处理非结构化数据,变得非常受欢迎。目前市场上有大量公司提供向量数据库产品和向量搜索服务,而 MyScale 以其独特的SQL 向量数据库在市场中脱颖而出。我们的一系列文章将对MyScale (opens new window)和其他一些热门向量数据库进行全面比较,首当其冲的就是Pinecone。Pinecone (opens new window)是一个闭源的,专门用于高维向量数据高效处理的向量数据库。它在存储、索引和查询向量嵌入方面表现出色,是相似性搜索和需要实时和高维向量操作的机器学习应用的理想解决方案。
在对比MyScale和Pinecone之前,我们需要先对与向量数据库相关的重要概念进行简答说明。
# 为什么向量搜索很重要
向量可以表示多种事物:值数组、文本数据、空间数据、图像等等。我们都知道如何简单地执行基本的向量算术或进行点积运算以找到它们的对齐/相似性。
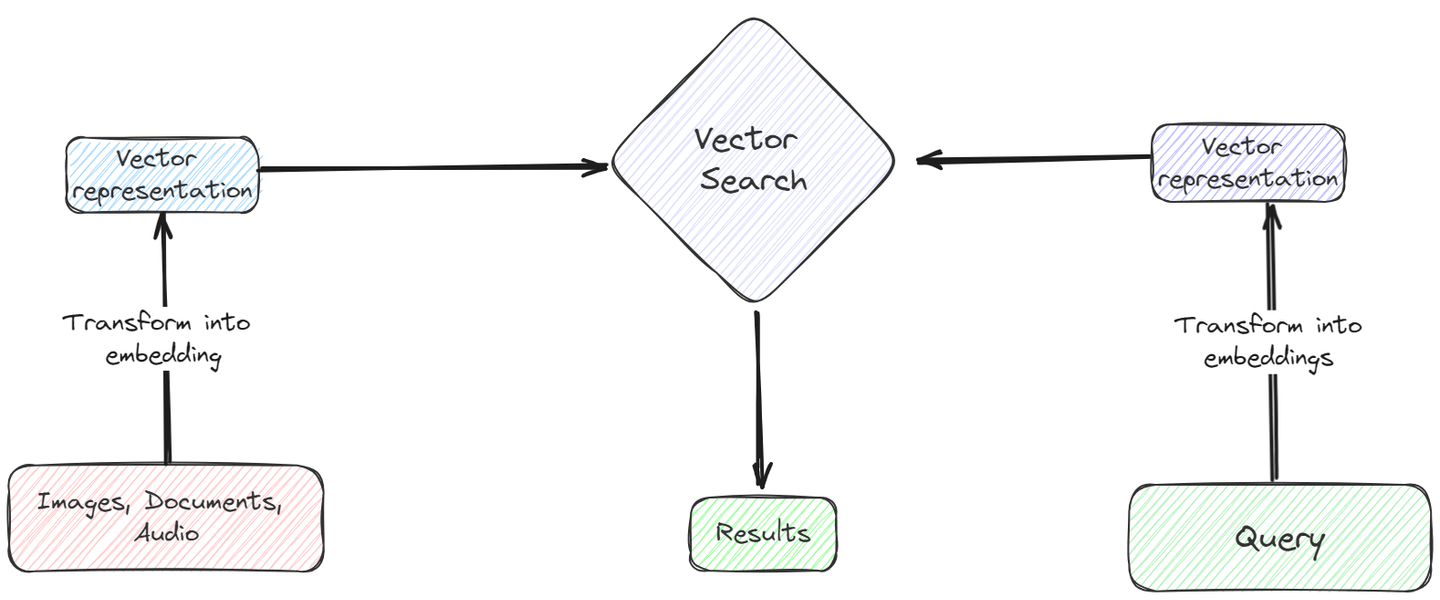
通过使用一些合适的嵌入,非结构化数据可以以向量的形式存储在向量数据库中。然后,我们可以使用余弦相似度或欧氏距离等原始相似度度量快速高效地执行向量的相似性搜索。与传统数据库的搜索模式相比,这种向量搜索 (opens new window)更快速、更经济,非常适合在短时间内处理大量非结构化数据。
# 什么是SQL向量数据库
除了专业向量数据库外,一些SQL数据库还通过扩展功能提供了向量搜索功能。这些集成解决方案被称为SQL向量数据库 (opens new window),旨在在结构化数据环境中提供基于向量的相似性搜索功能,并在统一的数据库框架内管理向量和结构化数据。
MyScale是一个扩展了ClickHouse功能的开源选项的SQL向量数据库。它是唯一一个在速度和性能方面甚至能够超越专门的向量数据库 (opens new window)的集成数据库。
# 在LLM领域的重要性
随着LLM的出现,相关的应用在不同细分领域中快速扩展。这些基础模型可以通过多种方法适应应用程序的特定要求,这些方法可以广义地分为两类:微调 (opens new window)和RAG (opens new window)。
在微调中,我们使用现有模型并对其进行微调以适应新的/相关的数据。由于涉及机器学习,这在计算上非常昂贵。尽管市场上有LoRA等技术,但开发者仍然需要一些强大的GPU来进行LLM的微调。
而RAG和微调截然不同,RAG不涉及传统的学习过程。相反,它使用向量嵌入进行向量搜索。这种方法利用原始相似度度量,使搜索过程显著加快。
到这里我们基本已经了解了所有基本概念。现在让我们开始比较两个数据库,MyScale和Pinecone。
# 托管
在选择数据库解决方案时,托管是一个关键方面,它对性能、可扩展性和管理产生重大影响。强大的托管选项可以确保数据库能够处理不同的负载、保持可访问性并且易于维护。此外,了解托管选项有助于用户在使用自己的资源在本地部署数据库和云托管服务之间做出选择。
两种选项都可以通过在云中创建项目来以云为基础的模式使用。Pinecone仅作为专有云服务运行; 而MyScale同时提供云版本MyScale Cloud (opens new window),和在Github (https://github.com/myscale/myscaledb) 上提供的开源版本。用户可以使用以下Docker命令启动开源版本:
docker run --name MyScale --net=host myscale/MyScale:1.6
此外,MyScale Cloud还额外提供免费套餐,让您可以快速注册并开始 (opens new window)实验。有关更多详细信息,请查看快速入门文档 (opens new window)。
# 核心功能
# 查询语言和API支持
在采用新的数据库技术时,用户的一个关键考虑因素是其与现有开发工作流程的集成易用性和对查询语言的熟悉程度。幸运的是,MyScale通过使用业内在关系型数据库中广泛使用的SQL来解决这个问题。
MyScale的优势不只于此,它还提供了集成的各种开发工具,如Python客户端 (opens new window)、Node.js (opens new window)、Go客户端 (opens new window)、ClientJDBC驱动程序 (opens new window)和HTTPS接口 (opens new window)。
TL;DR:
Pinecone和MyScale都提供了各种语言的SDK,但MyScale在全面支持SQL方面具有明显优势。
# 支持的数据类型
Pinecone专门用于存储向量。而MyScale则更加灵活,允许我们存储从文本到图像等不同的数据类型。
我们可以创建一个具有标量和向量属性的表用于进行无缝切换。由于使用了SQL API ,这个过程就像创建一个普通的关系型数据库表一样简单。以下SQL代码将创建一个具有长度为512的body_vector的表。
CREATE TABLE default.wiki_abstract(
id UInt64,
body String,
title String,
url String,
body_vector Array(Float32),
CONSTRAINT check_length CHECK length(body_vector) = 512
)
ENGINE = MergeTree
ORDER BY id;
此外,由于它使用了表格格式,行长度没有限制。因此,MyScale的文档大小没有限制,这明显优于市场上的竞争对手。
# 索引
向量数据库中使用了多种索引算法,如IVF和KD树。Pinecone使用了Hierarchical Navigable Small Worlds(HNSW)算法和FreshDiskANN算法。FreshDiskANN专为高效的实时更新而设计,支持大规模数据集的高召回率和性能。
而MyScale引入了多尺度树图(MSTG) (opens new window),这是一种将分层树聚类和基于图的搜索相结合的算法。MSTG提供更快的搜索速度和更少的资源消耗,显著优于现有算法。如果给用户一个选择MyScale而不是Pinecone的理由,MSTG具有充足的说服力。
# 过滤向量搜索
Pinecone具有元数据过滤功能,支持每个向量最多40KB的元数据。这些元数据可以包括字符串、数字和布尔值,从而实现详细的基于属性的搜索。Pinecone的单阶段过滤机制将搜索限制在满足指定条件的项目上,通过避免蛮力搜索使过程更快速、更准确。
MyScale使用MSTG算法与ClickHouse的高级索引和并行处理能力来优化过滤向量搜索 (opens new window)。此外,还采用了预过滤策略,在主要向量搜索之前缩小数据集范围,提高性能和准确性。ClickHouse的列式存储、向量化查询执行、高级索引和并行处理使其成为MyScale处理大型数据集的理想基础。这使它在保持速度和精度的同时不会出现后过滤的缺点。
TL;DR:
Pinecone在具有丰富的元数据支持的详细属性搜索方面表现出色。而MyScale通过预过滤策略和基于SQL的架构,在处理大型数据集方面提供了更优越的性能和可扩展性。
# 全文搜索
MyScale还提供了高级的全文搜索 (opens new window)(FTS)功能,使用Tantivy库,包括模糊搜索和通配符搜索,以及基于BM25算法的相关性评分。这个功能使MyScale能直观、高效地访问非结构化文本数据,允许用户根据主题或核心内容进行搜索。MyScale现在提供了一个强大高效的解决方案,用于复杂的文本搜索需求。要创建一个基本的FTS索引,可以按照以下步骤进行操作:
-- 创建全文搜索索引
ALTER TABLE [table_name] ADD INDEX [index_name] [column_name]
TYPE fts;
-- 进行查询
SELECT
id,
title,
body,
TextSearch(body, 'non-profit institute in Washington') AS score
FROM default.en_wiki_abstract
ORDER BY score DESC
LIMIT 5;
相比之下,Pinecone仅可用于向量搜索,而不具备内置的全文搜索功能。
TL;DR:
MyScale的全文搜索功能使其成为需要全面数据查询和分析的应用程序的更优选择。
# LLM API集成
在这方面,它们之间没有太大区别,因为它们都支持常见的API,如LangChain、LlamaIndex等。为了给出更好的想法,这里提供一个使用LangChain和MyScale的基本代码。
from langchain_community.vectorstores import MyScale
docsearch = MyScale.from_documents(docs, embeddings)
output = docsearch.similarity_search("How LLMs operate?", 3)
# 定价
Pinecone和MyScale都提供免费套餐。这很不错,因为新用户通常希望在能够达成共识之前先尝试一种新工具是否可用(或不可用)。对于新用户来说,Pinecone的免费套餐提供了高达2GB的存储空间,可以处理大约每个向量具有1536维的30万个向量。
另一方面,MyScale提供了免费存储空间,可容纳高达500万个768维向量,或者大约250万个1536维向量。这比Pinecone的免费套餐要高得多,使MyScale成为需要管理更大数据集而不希望有初始成本的用户的更优选择。
Pinecone和MyScale都根据用户的需求提供性能和存储优化的Pod。这种灵活性使用户能够根据自己的特定需求选择最佳解决方案。而在定价方面,MyScale也比Pinecone便宜很多。
# 容量优化Pod的定价
以下表格适用于需要更高存储容量的用户。它展示了MyScale和Pinecone在容量优化类别下提供的定价和容量选项。
| Pod类型(MyScale) | Pod大小 | MyScale基本价格(每小时美元) | MyScale预估容量 | Pod类型(Pinecone) | Pinecone基本价格(每小时美元) | Pinecone近似容量 |
|---|---|---|---|---|---|---|
| 容量优化Pod | x 1 | 0.094美元/小时 | 1000万个向量 | s1 | 0.11美元 | 500万个向量 |
| 容量优化Pod | x 2 | 0.189美元/小时 | 2000万个向量 | s1 | 0.22美元 | 1000万个向量 |
| 容量优化Pod | x 4 | 0.378美元/小时 | 4000万个向量 | s1 | 0.44美元 | 2000万个向量 |
| 容量优化Pod | x 8 | 0.756美元/小时 | 8000万个向量 | s1 | 0.89美元 | 4000万个向量 |
| 容量优化Pod | x 16 | 1.511美元/小时 | 1.6亿个向量 | - | - | - |
| 容量优化Pod | x 32 | 3.022美元/小时 | 3.2亿个向量 | - | - | - |
MyScale的容量优化Pod价格合理,提供更高的容量。与Pinecone相比,MyScale以更低的每小时成本存储更多的向量。
# 性能优化Pod的定价
以下表格适用于性能优先级高于容量的用户。它展示了MyScale和Pinecone在性能优化类别下提供的定价和容量选项。
| Pod类型(MyScale) | Pod大小 | MyScale基本价格(每小时美元) | MyScale预估容量 | Pod类型(Pinecone) | Pinecone基本价格(每小时美元) | Pinecone近似容量 |
|---|---|---|---|---|---|---|
| 标准Pod | x 1 | 0.167美元/小时 | 500万个向量 | P2 | 0.17美元 | 100万个向量 |
| 标准Pod | x 2 | 0.333美元/小时 | 1000万个向量 | P2 | 0.33美元 | 200万个向量 |
| 标准Pod | x 4 | 0.667美元/小时 | 2000万个向量 | P2 | 0.67美元 | 400万个向量 |
| 标准Pod | x 8 | 1.333美元/小时 | 4000万个向量 | P2 | 1.33美元 | 800万个向量 |
| 标准Pod | x 16 | 2.667美元/小时 | 8000万个向量 | - | - | - |
| 标准Pod | x 32 | 5.333美元/小时 | 1.6亿个向量 | - | - | - |
在性能优化Pod方面,MyScale的基本价格和Pinecone P2的相当,但MyScale的解决方案更具成本效益,可以在提供相同性能的情况下以更低的每小时成本存储更多的向量。
TL;DR:
在存储优化Pod方面,MyScale以更具成本效益的方式提供了与Pinecone的5个p2 Pod相媲美的性能。这使得MyScale成为需要高容量管理数据集的用户的理想选择。
# 基准测试
现在,我们将通过一些关键指标对MyScale和Pinecone的性能进行基准测试比较。在整个比较过程中,我们将使用带有MSTG的MyScale,同时使用Pinecone的两个变体(1个节点和5个pods)。
# 吞吐量(每秒查询数)
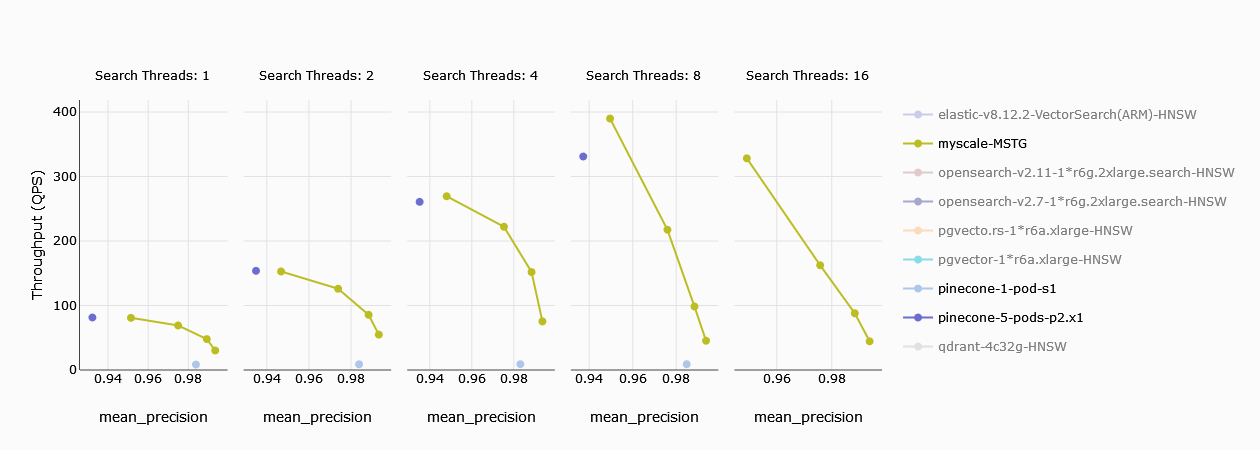
吞吐量是系统性能的一个基本衡量标准,客户会关注每秒处理的查询数量。在单线程搜索中,Pinecone的s1 pod明显落后于MyScale。然而,Pinecone的5个p2 pods可以处理与MyScale相当的每秒查询量。当线程数增加到2时,两者性能差距拉大,而在8线程时,即使是5个p2 pods也落后于MyScale的吞吐量。
注意:在图表中,黄色代表MyScale,四个不同的点表示不同的精度级别。更高的精度需要更多的计算。Pinecone的一个限制是无法像MyScale那样调整精度,因此最大召回率仅为94%。
TL;DR:
Pinecone的s1 pod无法与MyScale竞争,但5个p2 pods可以匹敌其性能。由于Pinecone无法调节精度,导致其召回率无法达到99%,而MyScale则可以。
# 平均查询延迟
下一个关注的指标是平均查询延迟,它衡量处理查询所需的平均时间。在我们的测试中,Pinecone的s1 pod无法与MyScale匹敌,而5个p2 pods才能具有竞争力。
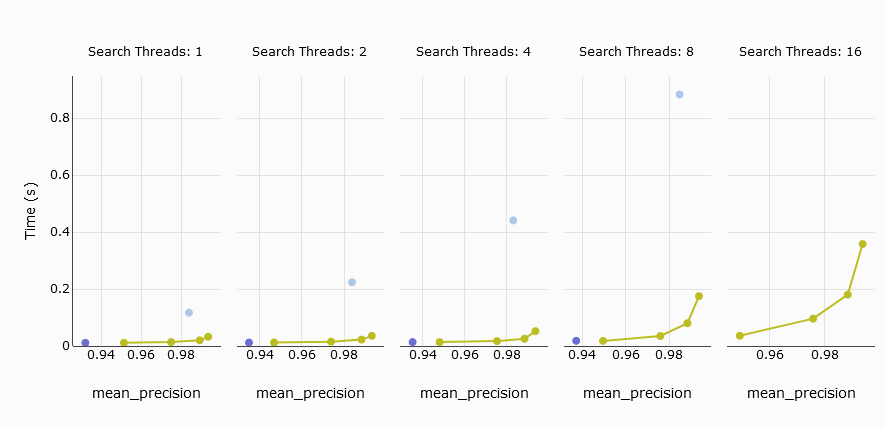
为了让比较更有意义,我们排除了s1 pod,专注于对比5个p2 pods与MyScale的性能。结果显示,MyScale和Pinecone在多达4个线程时表现出相似的延迟。然而,当线程数达到8或更多时,MyScale的平均查询延迟会显著增加。
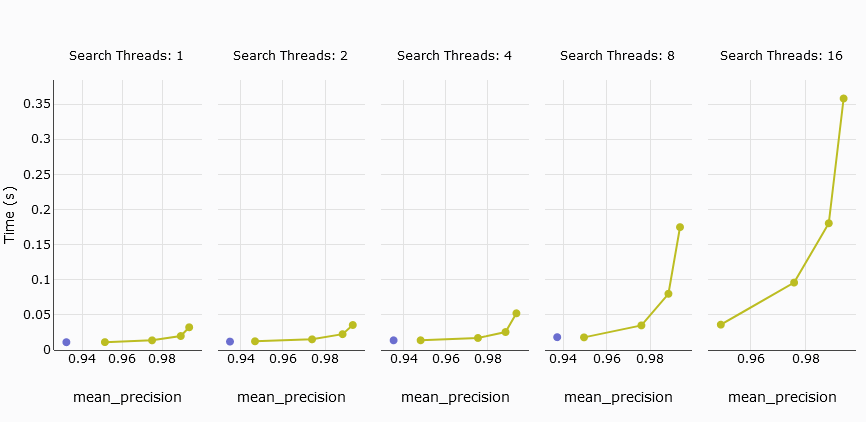
TL;DR:
在对比Pinecone的5个p2 pods与MyScale时,两者在低精度下表现出相似的平均查询延迟。然而,Pinecone无法调节精度,导致其召回率无法超过94%,而MyScale则可以。
# 数据导入时间
另一个有用的指标是数据导入时间——上传和构建数据库所需的时间。
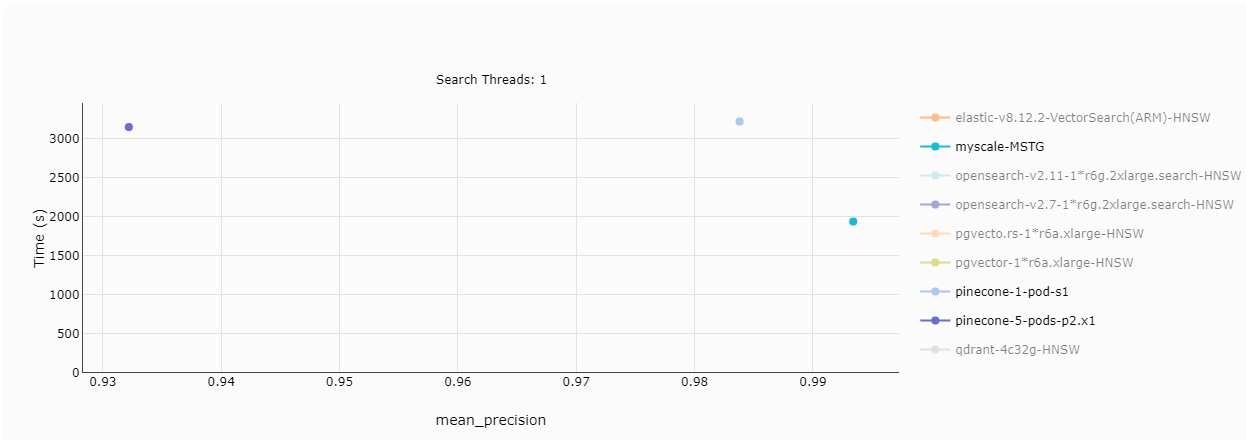
MyScale在处理500万个数据点时拥有更快的导入时间,约为30分钟。Pinecone s1则需要约53分钟。
# 成本比较
在本次测试中,我们使用了5个p2 pods,它们的性能相当于一个标准的MyScale pod。然而,5个p2 pods的月成本约为600美元,比MyScale贵5倍。这种显著的成本差异凸显了MyScale的优越性:它以更低的价格提供了相同的性能。
| 数据库 | Pod类型 | 月成本(美元) | 备注 |
|---|---|---|---|
| MyScale | 标准Pod,大小x1 | 120 | 提供与5个Pinecone p2 pods相当的吞吐量和延迟 |
| MyScale | 容量优化Pod | 68 | 成本效益高的容量优化选项 |
| Pinecone | s1.x1 Pod | 80 | 针对存储进行优化 |
| Pinecone | 5 x p2.x1 Pods | 600 | 通过水平扩展优化性能 |
尽管MyScale的平均Pod成本高于Pinecone的s1 pod,但它提供的吞吐量和延迟相当于Pinecone的5个p2 pods,而成本仅为其5分之一。
TL;DR:
MyScale的标准pod更加划算,提供的性能与Pinecone的5个p2 pods相当,但后者的成本却高出5倍。

# 结论
在比较MyScale和Pinecone时,MyScale凭借其基于SQL的集成、多样的数据类型支持和MSTG算法的卓越性能脱颖而出。MyScale具有更优秀的查询吞吐量和数据导入时间,更具成本效益的存储选项以及完善的全文搜索功能。这使得它成为管理大型、多样化数据集的绝佳选择。
Pinecone在详细的基于属性的搜索和丰富的元数据支持方面表现出色。然而,MyScale的开源性质、可扩展性和性能优势使其成为拥有更多功能的优秀选择。MyScale在性能、灵活性和成本方面的优势使其成为应对处理多样化和大规模数据管理需求的理想向量数据库。
感谢您的阅读,如果您有任何建议和问题,请通过**Twitter (opens new window)或Discord (opens new window)**与我们联系。



