
在本文中,我们将比较 MyScale,一个提供完整 SQL 支持的集成向量数据库,与两个传统数据库:PostgreSQL 和 OpenSearch。这两个数据库最近都在其工具箱中添加了向量相似性搜索功能。
注意:
我们在开源项目 vector-db-benchmark (opens new window) 中,持续更新MyScale和其他向量数据库产品的基准测试结果。
大型语言模型(LLM)的出现增加了将对话界面集成到各种应用程序中的兴趣,例如搜索引擎、代码生成器和数据分析工具。向量相似性搜索是一项关键技术,通过“检索增强生成(RAG)”来提高 LLM 的性能。
市场上有各种各样的向量数据库产品;有些是专门为向量索引而设计的专用向量数据库,而其他一些是集成向量数据库或扩展支持向量搜索的通用数据库。
此外,与专用向量数据库相比,集成向量数据库具有以下几个明显优势:
- 它们将向量和结构化数据存储在同一个数据库中,便于进行更复杂的过滤搜索以及 SQL 和向量联合查询。
- 它们使用强大且广泛使用的查询语言(如 SQL)进行结构化和向量数据分析。
- 它们利用通用数据库的成熟工具和集成。
- 它们减少了专用技能和专用数据库的许可成本的额外劳动力成本。
我们要比较的三个集成向量数据库如下:
- MyScale是一个基于 ClickHouse 开发的集成向量数据库,结合了向量相似性搜索和完整的 SQL 支持;
- PostgreSQL通过其pgvector (opens new window)扩展提供向量搜索支持;
- OpenSearch在2.9.0 版本 (opens new window)中引入了神经(向量)搜索。
如下所述,我们的全面基准评估显示,MyScale 在过滤向量搜索准确性、性能、成本效益和索引构建时间方面远远超过其他产品。重要的是,MyScale 是唯一经过测试在各种过滤比率下都能提供良好的搜索准确性和 QPS 的产品。
此外,MyScale 在性能上也超过了专用向量数据库,请参阅此文章 (opens new window)和我们的开源基准 (opens new window)获取更多详细信息。如下图所示,将完整的 SQL 支持与高性能的向量搜索相结合,使 MyScale 成为管理 AI/LLM 相关数据(包括结构化和向量化数据)的一个引人注目的选择:
# 基准设置
我们对 MyScale、OpenSearch 和两个 Postgres 向量搜索扩展进行了基准测试。具体信息如下。
| 数据库 | Pod 类型 | 月费用(美元) | 备注 |
|---|---|---|---|
| MyScale (opens new window) | Pod 尺寸:x1 | 120 | 目前免费提供开发层 (opens new window)。 |
| 带有pgvector (opens new window)的 Postgres | db.r6g.xlarge (opens new window)(4C 32GB) | 329 | 亚马逊 RDS for PostgreSQL |
| 带有pgvecto.rs (opens new window)的 Postgres | db.r6g.xlarge (opens new window)(4C 32GB) | 329 | 亚马逊 RDS for PostgreSQL |
| AWS OpenSearch Service (opens new window) | r6g.2xlarge.search (opens new window)(8C 64GB) | 488 | 亚马逊 OpenSearch Service 域 |
我们使用了 500 万个 768 维向量,这些向量是从LAION 2B images (opens new window)数据集生成的,用于向量搜索和过滤向量搜索测试。
注意:
完整的代码、数据集和结果可以在我们的基准页面 (opens new window)上找到。
我们选择了每个数据库中能够容纳所有向量的最小 Pod 类型。
由于最新版本的 pgvector 和 pgvector.rs 尚未被任何 PostgreSQL 云服务广泛采用,我们在运行基准测试时选择了自主托管。但是,为了比较,我们在上表中包含了亚马逊 RDS for PostgreSQL 的定价信息。
注意:
PostgresSQL 云服务(如Supabase (opens new window)和TimeScaleDB (opens new window))可能会在类似的硬件配置上花费更多。
对于 OpenSearch,我们选择了 r6g.2xlarge.search(64GB 内存),因为我们在尝试在 r6g.xlarge.search(32GB 内存)实例上构建向量索引时遇到了问题。正如摘要所示,MyScale 仍然是最具成本效益的集成向量数据库。
# 基准结果
我们总结了以下发现:
# 向量搜索
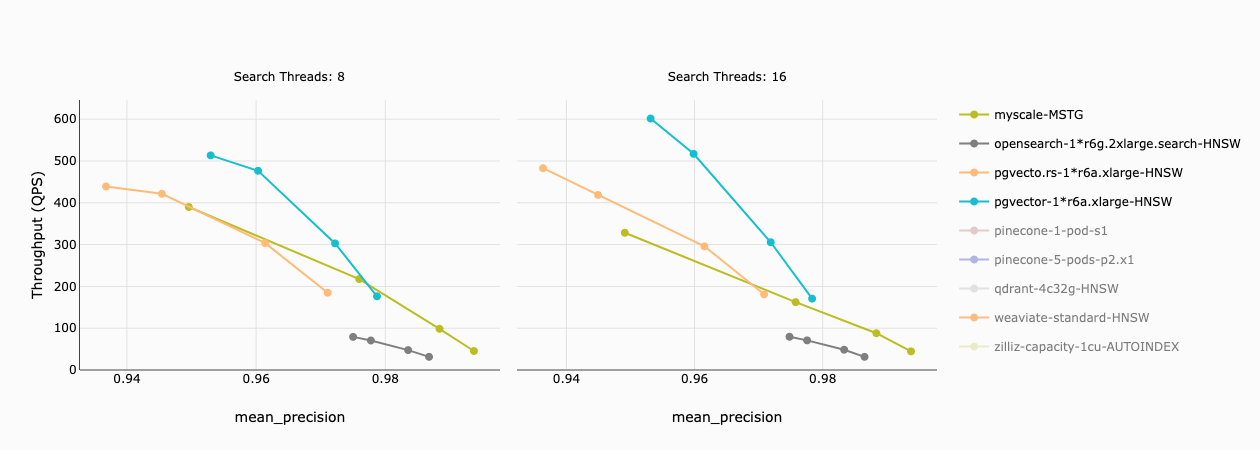
下图中,x 轴表示精度,y 轴表示每个向量数据库的吞吐量(QPS)。我们发现:
- MyScale 和两个 Postgres 扩展在 97% 精度下的吞吐量相似;
- pgvector 和 pgvecto.rs 可以在较低精度下实现更高的吞吐量,但成本显著高于 MyScale;
- OpenSearch 在所有精度下的速度都落后于其他数据库。
# 过滤向量搜索
在实际场景中,纯向量搜索很少足够。向量通常附带元数据,用户通常需要对此元数据应用一个或多个过滤器。
下图描述了 MyScale(以及其他集成向量数据库)在过滤比率为 1% 的数据集上的吞吐量。1% 的过滤比率意味着在应用过滤条件后,仍然保留 50K 个向量(1% x 5M 个向量)。
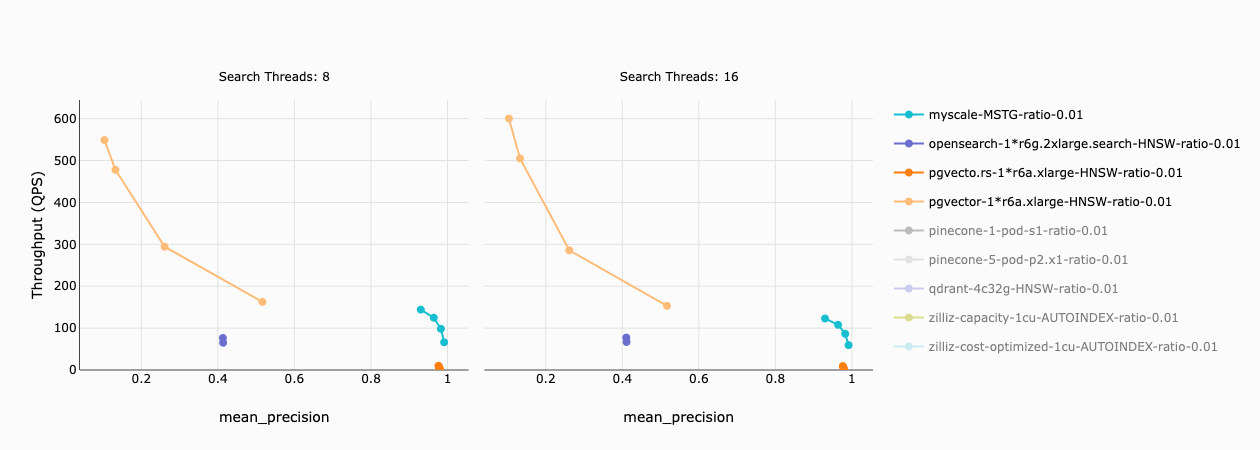
我们的研究结果揭示了以下信息:
- pgvector 和 OpenSearch 的精度很低(小于 50%),在实践中几乎无法使用。
- pgvecto.rs 的吞吐量相对较低(小于 10 QPS)。
- 只有 MyScale 保持健康的吞吐量(66 - 144 QPS)和精度(93% - 99%)。
在这些数据库中实现过滤向量搜索时,有两种主要方法。
# 后过滤
这种方法首先进行向量搜索,然后删除不符合过滤条件的结果。不幸的是,使用此方法存在两个重大缺点:
- 首先,搜索中的元素数量是不可预测的,因为过滤器应用于已经减少的候选列表。
- 其次,如果过滤器非常严格,即仅与数据集大小相比仅匹配很小比例的数据点,则原始向量搜索可能根本不包含任何匹配项。
# 先过滤
pgvector 和 OpenSearch 的低精度归因于它们使用的后过滤方法。相比之下,MyScale 和 pgvector.rs 使用一种称为先过滤的不同方法。首先应用过滤器,然后将位图传递给向量索引以执行向量搜索。
在我们的基准测试中,pgvector.rs 使用的 HNSW 算法在过滤比率较低时表现不佳。此外,PostgreSQL 的基于行的存储对于先过滤中所需的大规模扫描操作不友好,这进一步加剧了性能不佳的问题。而 MyScale 通过结合 ClickHouse 的快速列式 SQL 执行引擎 (opens new window)和我们专有的MSTG 向量索引算法 (opens new window)解决了这个问题。
# 评估成本效益:纯向量搜索 vs. 过滤向量搜索
在选择数据库时,不仅要考虑原始性能,还要考虑投资带来的价值。成本效益,特别是在 95% 精度等较高精度下,成为进行大规模向量搜索的企业的关键标准。
# 纯向量搜索
为了清楚地了解成本效益,我们通过检查每个数据库的月费用与其在大约 95% 精度下可以实现的每秒查询数(QPS)之间的关系,得出了每个数据库每 100 QPS 的成本。如下结果所示,MyScale 在成本效益方面表现出色,至少超过最接近的竞争对手 1.8 倍。
| 数据库 | 每 100 QPS 的月费用(美元) |
|---|---|
| MyScale | 30 |
| pgvector | 54 |
| pgvecto.rs | 79 |
| OpenSearch | 613 |
# 过滤向量搜索(1% 过滤比率)
然而,许多实际场景需要更多的纯向量搜索。通常会对数据集应用过滤器,缩小结果范围。当我们评估 1% 过滤比率的过滤向量搜索的成本效益时,情况发生了变化。**值得注意的是,pgvector 和 OpenSearch 无法实现高于 50% 的精度。**这种低准确性在大多数情况下无法使用,因此在此分析中标记为 N/A。
| 数据库 | 每 100 QPS 的月费用(美元) |
|---|---|
| MyScale | 96 |
| pgvector | N/A |
| pgvecto.rs | 3290 |
| OpenSearch | N/A |
总之,尽管 MyScale 在纯向量搜索中仍然是领先者,但在过滤向量搜索中,它的优势更加明显。MyScale 以极高的性能以及较低的成本提供了顶级的性能,为企业提供了最佳的投资回报。高精度、成本效益和性能的结合使 MyScale 成为有效利用集成向量数据库的明智选择。
# 索引构建时间
在向量插入向量数据库后,用户必须在执行向量搜索之前创建向量索引。构建索引所需的时间对于快速搜索结果至关重要,下表描述了四种不同向量数据库的构建时间:
| 数据库 | 上传和构建时间 |
|---|---|
| MyScale | 32 分钟 |
| Pgvector | 10.9 小时 |
| Pgvecto.rs | 80 分钟 |
| OpenSearch | 45 分钟 |
这些结果显示,MyScale 是构建时间最快的明显领先者,而 pgvector 由于缺乏并行构建支持而在构建 HNSW 向量索引时非常慢。快速构建索引对于应用程序需要插入和更新大量向量(例如大规模在线聊天、文档编辑等)非常重要,还减少了索引构建和向量搜索之间的资源争用。
# 结论
经过详尽的分析,MyScale 始终超越竞争对手,在过滤向量搜索和快速索引构建时间方面展现出卓越的性能。在所有经过测试的产品中,MyScale 是唯一一个在各种过滤比率下都能提供高搜索准确性和 QPS 的集成向量数据库。MyScale 与其他产品的区别在于其出色的成本效益,使其成为强大的集成向量数据库选择和经济上明智的选择。对于希望利用集成向量数据库能力的组织来说,MyScale 凭借其卓越的性能、精度和性价比的结合成为顶级竞争者。

# 进一步探索
为了更深入地了解 MyScale 在性能方面与专用向量数据库的匹配情况,我们建议阅读这篇文章 (opens new window)。
对于那些考虑将其向量数据从 PostgreSQL 迁移到 MyScale 的人来说,这篇指南 (opens new window)提供了宝贵的见解和逐步说明。



