
向量搜索是基于向量表示在数据集中寻找相似向量或数据点的方法。然而,在现实世界的场景中,纯向量搜索往往是不够的。向量通常带有元数据,并且用户经常需要对这些元数据应用一个或多个过滤器。这就引入了过滤向量搜索。
过滤向量搜索在复杂的检索场景中变得越来越重要。您可以应用过滤机制来过滤掉多维嵌入的前k个/范围之外的不需要的向量。
在本博客中,我们首先讨论了实现过滤向量搜索的技术挑战。然后,我们提供了一个解决方案,介绍了MyScale如何使用我们的专有算法MSTG以及ClickHouse对结构化数据进行快速过滤来优化过滤向量搜索。
# 实现过滤向量搜索的技术挑战
随着现代应用程序中大型数据集中数据类型的多样性增加,选择适当的过滤向量搜索方法和向量索引算法对于提高搜索结果的质量和提供更准确的搜索结果非常重要。现在,让我们深入探讨这些挑战。
# 预过滤与后过滤
根据过滤在向量搜索过程中发生的时间,过滤搜索可以分为预过滤和后过滤两种,如下图所示。
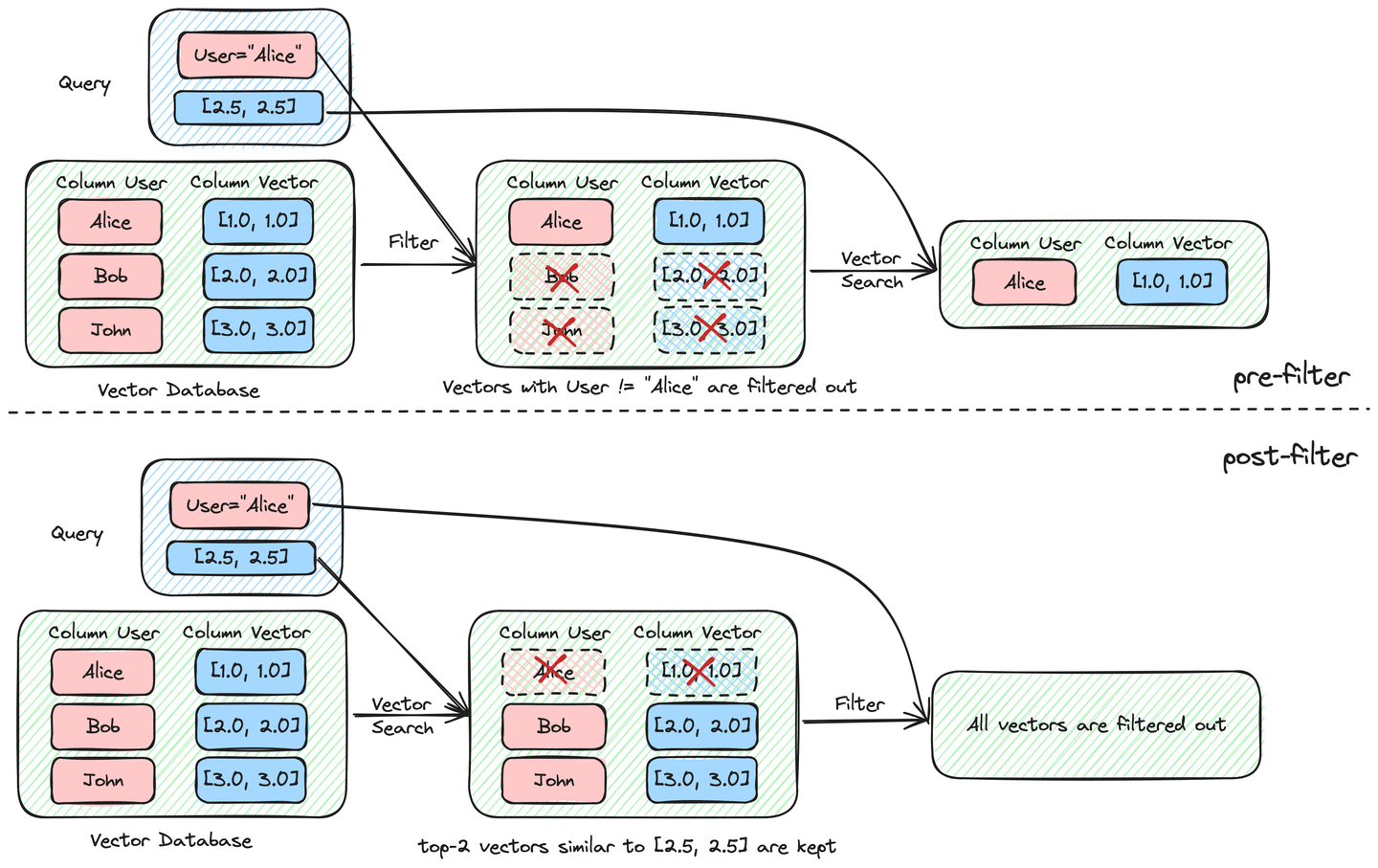 使用预过滤时,我们得到了预期的输出("Alice",[1.0,1.0])。然而,后过滤没有产生任何结果。
使用预过滤时,我们得到了预期的输出("Alice",[1.0,1.0])。然而,后过滤没有产生任何结果。
# 预过滤
预过滤向量搜索是一种在对数据集进行主要向量搜索查询之前对潜在匹配项进行初始筛选的技术。其目的是在早期阶段缩小搜索空间并消除不合格或不必要的结果,从而提高后续向量搜索的效率和准确性。这种方法在数据集庞大且计算资源需要谨慎使用的场景中特别有益。
考虑这样一个场景:您有一个庞大的图像数据库,并且希望检索与给定查询图像密切匹配的图像。您可以根据简单特征(如颜色直方图、宽高比或低级描述符)对潜在候选项进行预过滤,而不是对整个图像数据集进行详细的向量搜索。例如,您可以预过滤具有与查询图像相似的颜色分布或形状的图像。
总之,预过滤是一种战略性的方法,通过智能地缩小搜索操作的范围来提高相似性搜索的整体性能。
注意:
MyScale的过滤搜索实现中始终使用预过滤。
# 后过滤
与预过滤不同,后过滤是一种在对数据集执行纯向量搜索查询后,在获得初始结果后应用额外的过滤或细化步骤的技术。然而,这种方法存在一定的限制和缺点,可能会影响搜索结果的效率和准确性。由于过滤器应用于减少的结果集,这些结果可能是不可预测的。在过滤器高度限制的情况下,仅针对数据集大小的一小部分数据点进行目标定位,可能导致初始向量搜索中没有匹配项。
流行的向量数据库,如PostgreSQL/pgvector和OpenSearch,采用了这种方法,导致过滤搜索的准确性较低,如我们之前的博客所示。
# HNSW在过滤搜索中的性能不佳的原因
尽管HNSW等流行的图算法在未经过滤的向量搜索中表现良好,但在过滤向量搜索中,其性能可能显著下降。
让我们首先定义过滤向量搜索的过滤比如下:
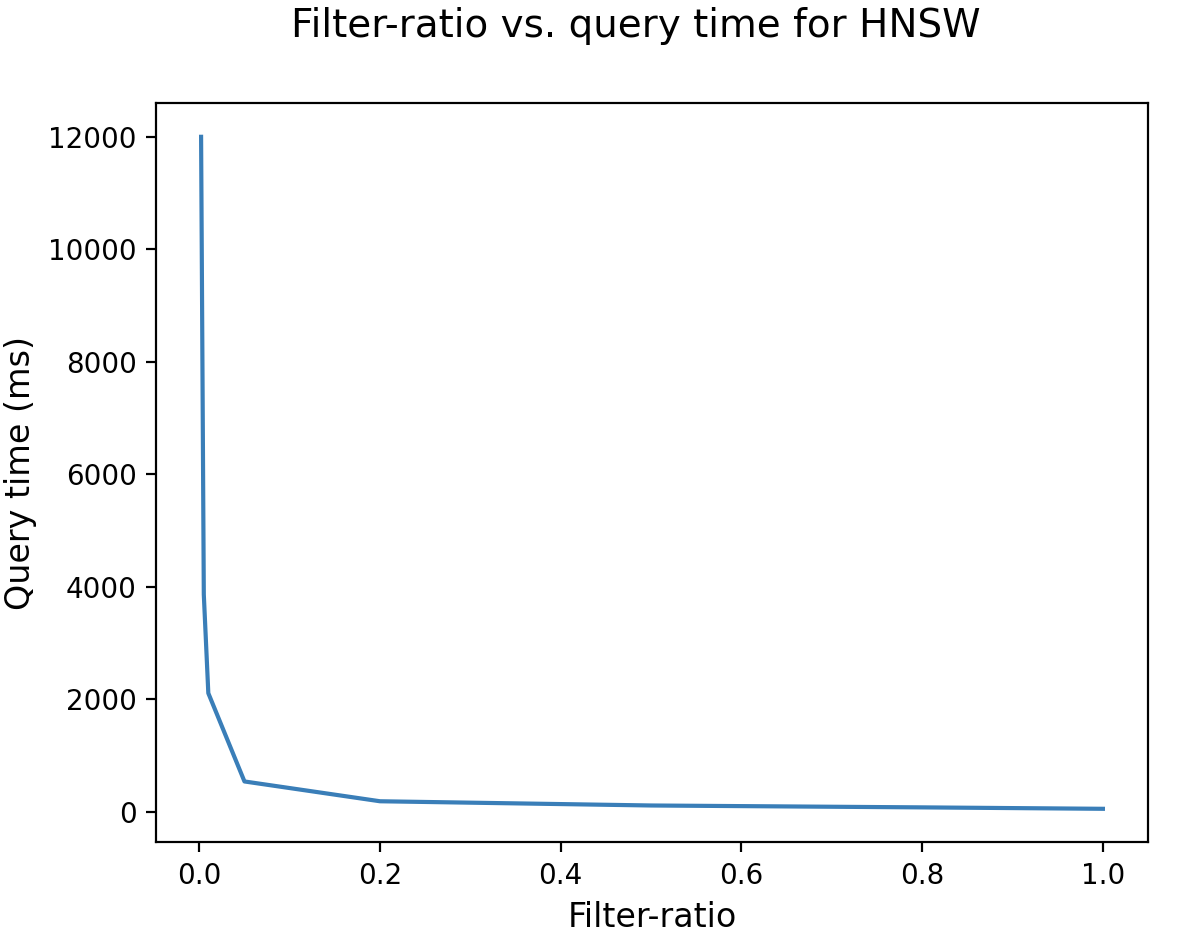
当过滤比较低时,过滤变得非常严格。如下图所示,当过滤比低于1%时,HNSW算法的性能较差,需要几秒钟的时间:
让我们分析一下当过滤比较低时,为什么HNSW的性能不佳,首先看一下它的搜索过程。在这个向量搜索过程中,基层节点搜索是最耗时的过程。与大多数图算法中的节点搜索类似,HNSW使用一个候选集来存储要访问的节点,使用一个顶级候选集来存储潜在的顶级节点。终止搜索的条件包括:
- 顶级候选集的数量已经满足算法要求,并且
- 顶级候选集与查询向量之间的最大距离小于候选集与查询向量之间的最小距离。
与普通的向量搜索过程相比,HNSW-with-filtered-search在将节点添加到潜在的顶级候选集列表之前,会检查节点是否在选择集中。
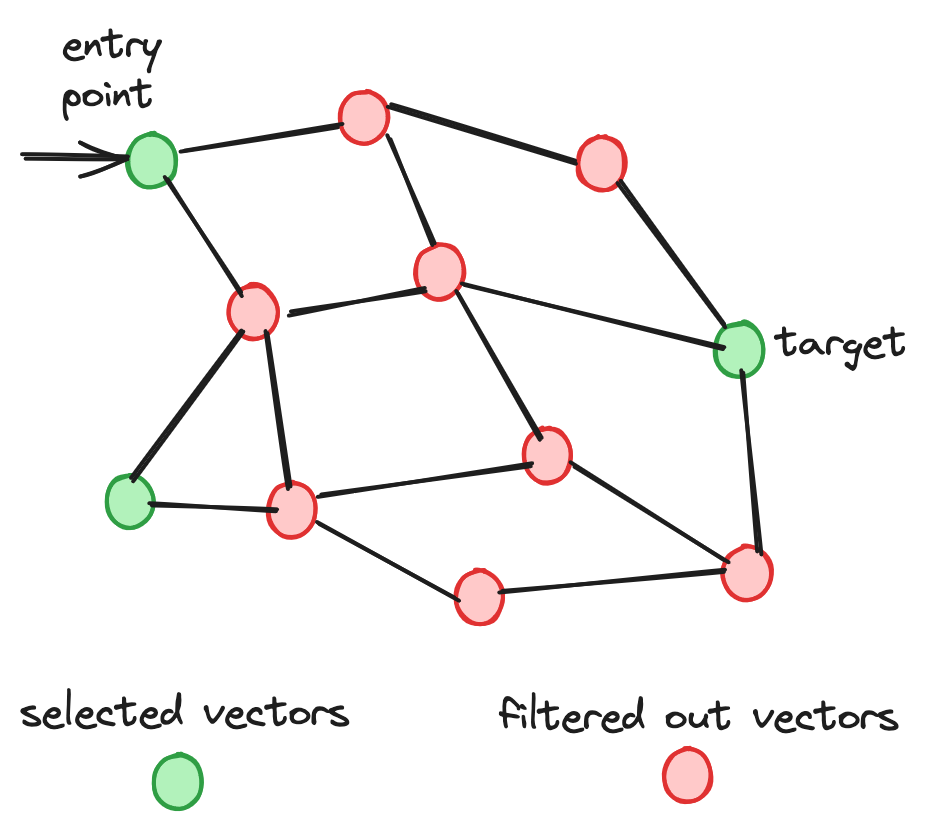
低过滤比对索引来说是一个重要的挑战,因为它很难识别足够数量的顶级候选集。这个限制导致了大量的节点遍历。此外,由于在图中进行高效的遍历以定位过滤后的最近邻居是困难的,这个挑战变得更加复杂。
使用HNSW进行过滤向量搜索的常见优化技术是在过滤比率低于特定阈值时切换到暴力搜索。然而,我们不推荐这种方法,因为对于大规模向量(例如包含数亿甚至数十亿个向量的数据库)来说,这种方法是不切实际的。在这种情况下,即使1%的过滤比率也需要计算查询向量与数据库中数百万个向量之间的距离。
# MyScale中的高级过滤向量搜索
既然我们已经确定了问题,让我们努力寻找解决方案。MyScale是一个SQL向量数据库,它将基于ClickHouse的快速SQL执行引擎与用于快速过滤结构化数据的专有算法MSTG相结合,以优化过滤向量搜索。本节将探讨我们选择在ClickHouse上构建MyScale的原因,ClickHouse作为最快的开源分析数据库而闻名,并解释我们对向量算法的增强,以实现高效的过滤搜索。这些优化使得MyScale具有高性能、灵活和稳健的过滤向量搜索能力。
注意:
MyScale是一个具有完整SQL支持的集成向量数据库。
# 利用ClickHouse进行过滤向量搜索
选择ClickHouse作为MyScale的基础是基于其在处理大规模数据方面的高效性能。ClickHouse的优秀数据扫描速度对于高性能的过滤向量搜索至关重要。以下设计极大地提高了其效率:
- 列式存储: 与传统的行式数据库不同,ClickHouse将数据存储在列中,使得读取和处理数据更快。这种设计对于聚合函数和过滤器特别有益,因为它只从磁盘中高效地读取所需的列,减少了I/O操作。
- 矢量化查询执行: ClickHouse以批处理方式处理数据,而不是逐行处理。这种矢量化的方法使其能够同时对多个数据点执行操作,显著加快查询执行速度。这对于大规模数据集上的过滤向量搜索特别有优势。
- 高级索引: ClickHouse采用了诸如跳过索引之类的复杂索引技术。数据库在查询过程中快速跳过不相关的数据块,从而在查询时进行更快的过滤,因为数据库花费更少的时间扫描无关数据。
- 并行处理: ClickHouse的架构支持并行处理,使其能够将工作负载分布到多个核心和节点上。这种并行化对于高效处理大规模查询和过滤非常重要,确保即使在处理大型和复杂数据集时也能实现高性能。
这些功能使得ClickHouse成为实现快速高效的过滤向量搜索的理想平台。这种集成提供了ClickHouse强大的分析能力和处理复杂、元数据丰富的向量数据所必需的细致向量数据库功能的最佳结合。
# 多尺度树图算法
多尺度树图(MSTG)是MyScale开发的一种新的向量索引。与HNSW等流行算法仅依赖于分层图和倒排文件索引(IVF)的两级树结构不同,MSTG在设计中结合了分层图和树结构的优点。
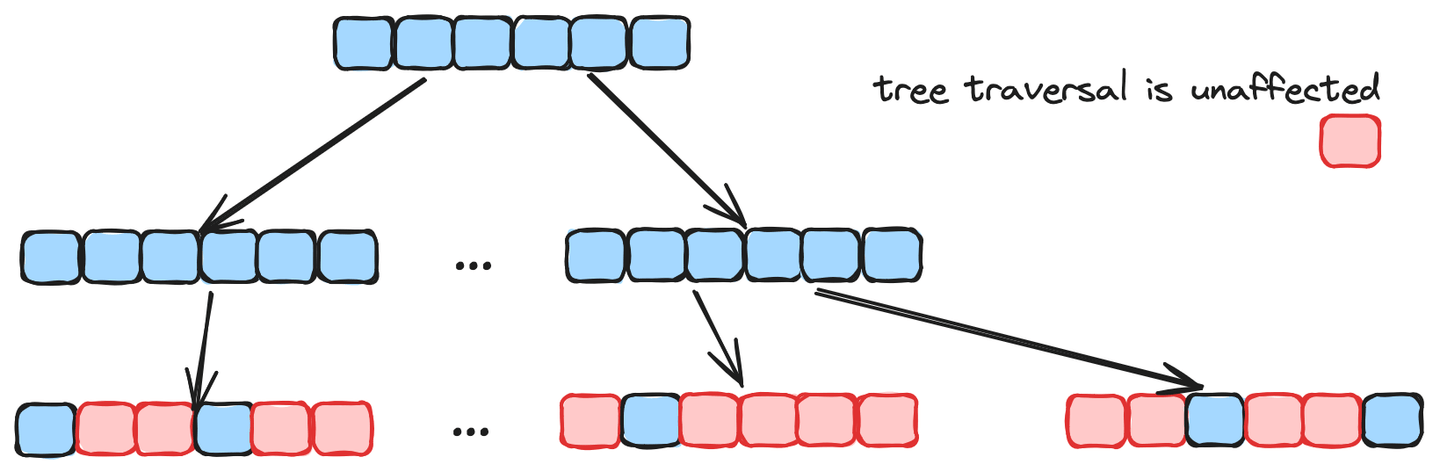
图算法在初始收敛方面表现出色,通常在未经过滤的搜索中更快。然而,在过滤搜索中,它的效率严重受到影响。另一方面,树算法在未经过滤的搜索中较慢且准确性较低,但树遍历不受过滤元素的影响,并保持对过滤搜索的性能,如下图所示。因此,在MSTG中将这两种算法结合起来,可以实现高性能和高准确性,并实现快速的索引构建时间。此外,MSTG还使用SIMD(单指令多数据)加速了预过滤和向量距离计算,极大地提高了现代CPU上的计算吞吐量。

# 结论
向量搜索根据向量表示寻找相似的数据点,但现实世界的场景需要更多的纯向量搜索。带有元数据的向量通常需要过滤向量搜索,这对于复杂的检索场景至关重要。
MyScale对过滤向量搜索的创新方法,将ClickHouse的强大分析能力与专有的MSTG算法相结合,为复杂的大规模向量搜索提供了强大的解决方案。这种集成提供了速度和精度,使MyScale成为向量数据库技术的领导者。
您可以在以下内容中找到MyScale与其他竞争对手之间的基准报告:



