
自从大型语言模型(LLM)和先进的聊天模型发布以来,人们已经使用了各种技术来从这些人工智能系统中产生期望的输出。其中一些方法涉及改变模型的行为,以更好地与期望相一致,而其他方法则侧重于增强用户查询LLM的能力,以提取更精确和相关的信息。
像检索增强生成(RAG) (opens new window)、提示工程 (opens new window)和微调 (opens new window)是最常用的技术。我们之前已经详细讨论了如何在 MyScale 上进行检索增强生成(RAG) (opens new window)和微调。在微调中,我们讨论了两种技术,使用openai进行微调 (opens new window)和使用hugging face进行微调 (opens new window)。
注意:
如果您还没有阅读我们的RAG和微调博客,建议在开始本文之前先阅读它们。
今天的讨论有点不同,我们从探索转向比较,一起看看每种技术的优缺点。通过对比,大家将了解何时以及如何有效地使用这些技术。接下来让我们进入正题。
# 提示工程(Prompt Engineering)
提示是与任何大型语言模型进行交互的最基本方式。这就像给出指示。当你使用提示 (opens new window)时,你告诉模型你希望它给你提供什么样的信息。这也被称为提示工程。这有点像学习如何提出正确的问题以获得最佳答案。但是它有一定的局限性。这是因为模型只能返回它在训练 (opens new window)中已经了解的内容。
提示工程的好处在于它非常直观。你不需要成为技术专家才能做到这一点,这对大多数人来说非常好。但是,由于它在很大程度上依赖于模型的原始学习,它可能无法始终提供你所需的最新或最具体的信息。在处理一般主题或仅需要快速答案而不涉及太多细节时,这是最好的选择。
# 优点:
- 易于使用:提示工程对用户友好,不需要高级技术技能,适用于广泛的用户群体。
- 成本效益:由于使用的是预训练模型 (opens new window),与微调相比,提示工程的计算成本较低。
- 灵活性:可以快速调整提示以探索不同的输出,无需重新训练模型。
# 缺点:
- 不一致性:模型的响应质量和相关性可能会根据提示的措辞而有很大差异。
- 定制能力有限:定制模型的响应能力受限于创造有效提示的创造力和技巧。
- 依赖模型的知识:输出仅限于模型在初始训练过程中学到的内容,对于高度专业化或最新信息,效果较差。
# 微调(Fine-Tuning)
微调是指对语言模型进行更新和特殊训练。可以将其视为更新手机上的应用程序以获得更好的功能。但在这种情况下,应用程序(模型)需要大量的新信息和时间来正确学习所有内容。这有点像模型回到学校。
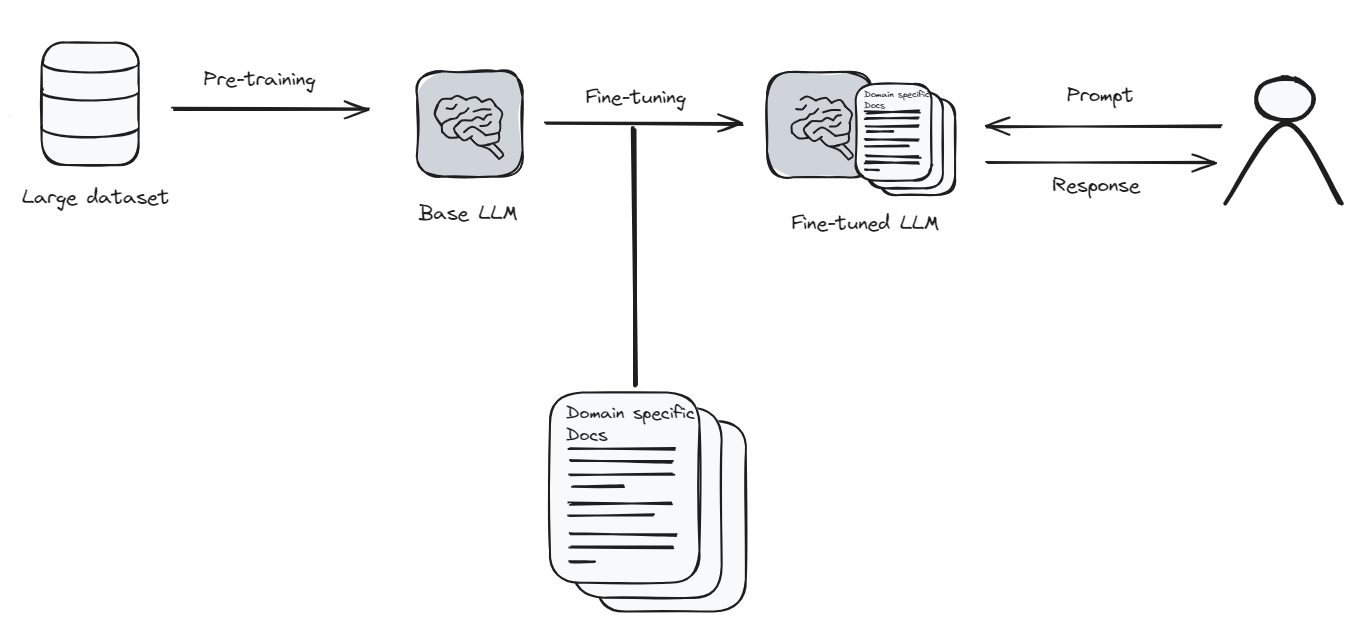
由于微调需要大量的计算资源和时间,因此可能会很昂贵。但是,如果你需要语言模型非常了解特定主题,那么微调是值得的。这就像教模型成为你感兴趣的领域的专家。在微调之后,模型可以给出更准确、更接近你寻找的答案。
# 优点:
- 定制能力:允许进行广泛的定制,使模型能够生成针对特定领域或风格的响应。
- 提高准确性:通过在专门的数据集上进行训练,模型可以生成更准确和相关的响应。
- 适应性:微调的模型可以更好地处理特定领域或原始训练中未涵盖的最新信息。
# 缺点:
- 成本:微调需要大量的计算资源,比提示工程更昂贵。
- 技术技能:这种方法需要对机器学习 (opens new window)和语言模型架构 (opens new window)有更深入的了解。
- 数据要求:有效的微调需要大量且精心策划的数据集,这可能很具有挑战性。
相关文章:如何构建推荐系统 (opens new window)
# 检索增强生成(RAG)
检索增强生成(RAG)将常规语言模型与类似知识库 (opens new window)的东西结合在一起。当模型需要回答问题时,它首先从知识库中查找并收集相关信息,然后根据该信息回答问题。这就像模型快速检查信息库以确保给出最佳答案。
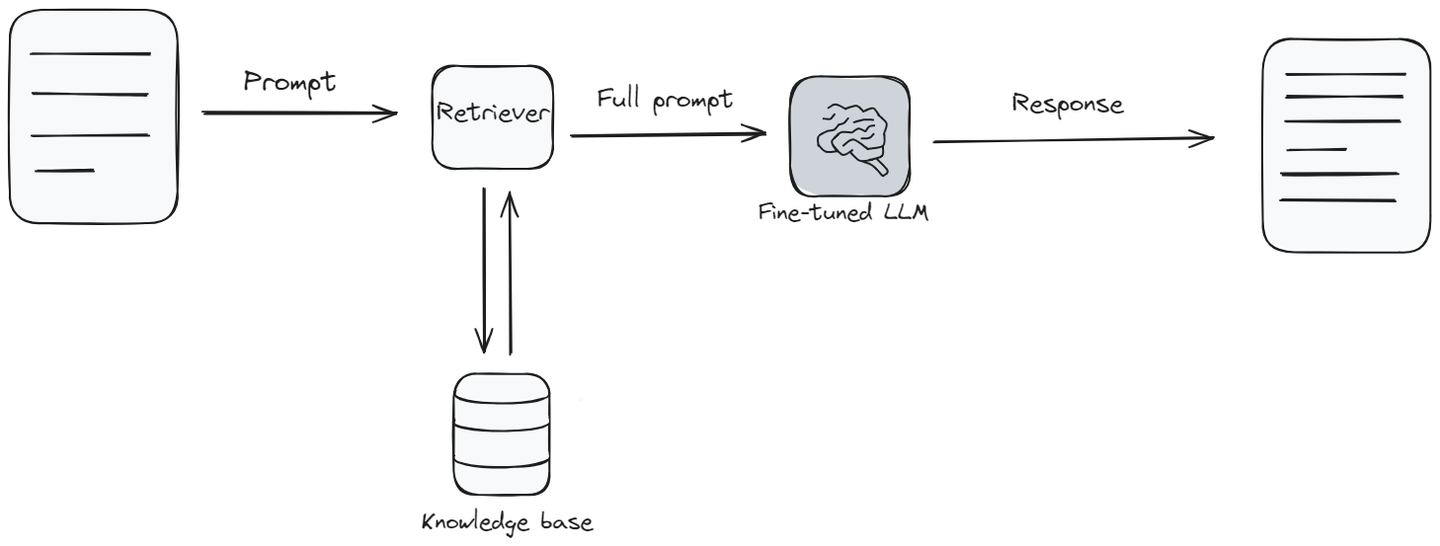
RAG在需要最新信息或涉及比模型最初学习的主题范围更广的答案时特别有用。在设置和成本方面,它介于两者之间。在效果,RAG的表现很好,因为它帮助语言模型给出最新且更详细的答案。但是,与微调一样,它需要额外的工具和信息才能发挥良好的效果。
RAG系统的成本、速度和响应质量严重依赖于向量数据库,这就使向量数据库成为RAG系统的非常重要的一部分。比如,SQL 向量数据库 MyScale (opens new window),在成本几乎是其他向量数据库的一半的同时,性能提高了3倍 (opens new window)。最重要的是,开发者无需学习任何外部工具或语言即可访问MyScale,你可以通过简单的SQL语法访问它,这使其成为开发人员的理想选择。
# 优点:
- 动态信息:通过利用外部数据源,RAG可以提供最新和高度相关的信息。
- 平衡:在提示工程的易用性和微调的定制性之间提供了一个折中方案。
- 上下文相关性:通过额外的上下文增强模型的响应,从而产生更具见解和细致的输出。
# 缺点:
- 复杂性:实施RAG可能很复杂,需要在语言模型和检索系统之间进行集成。
- 资源密集型:虽然比完全微调要求的资源少,但RAG仍需要相当大的计算能力。
- 数据依赖性:输出的质量严重依赖于检索到的信息的相关性和准确性。
# 提示工程 vs 微调 vs RAG
现在我们来对比一下提示工程、微调和检索增强生成(RAG)。下面的表格详细地展示了它们之间的区别,有助于大家决定哪种方法可能最适合自己的需求。
| 特征 | 提示工程 | 微调 | 检索增强生成(RAG) |
|---|---|---|---|
| 所需技能水平 | 低:需要基本了解如何构建提示。 | 中等到高:需要了解机器学习原理和模型架构。 | 中等:需要了解机器学习和信息检索系统。 |
| 定价和资源 | 低:使用现有模型,计算成本较低。 | 高:训练需要大量计算资源。 | 中等:需要检索系统和模型交互的资源,但比微调少。 |
| 定制能力 | 低:受限于模型的预训练知识和用户构建有效提示的能力。 | 高:允许进行广泛的定制,以适应特定领域或风格。 | 中等:通过外部数据源进行定制,但取决于其质量和相关性。 |
| 数据要求 | 无:利用预训练模型而无需额外数据。 | 高:需要大量相关的数据集以进行有效的微调。 | 中等:需要访问相关的外部数据库或信息源。 |
| 更新频率 | 低:取决于基础模型的重新训练。 | 可变:取决于模型何时使用新数据进行重新训练。 | 高:可以整合最新信息。 |
| 质量 | 可变:高度依赖于构建提示的技巧。 | 高:针对特定数据集进行定制,产生更相关和准确的响应。 | 高:通过上下文相关的外部信息增强响应。 |
| 使用案例 | 一般查询、广泛主题、教育目的。 | 专业应用、行业特定需求、定制任务。 | 需要最新信息和涉及上下文的复杂查询的情况。 |
| 实施的便利性 | 高:使用现有工具和界面非常简单。 | 低:需要深入的设置和训练过程。 | 中等:涉及将语言模型与检索系统集成。 |
相关文章:RAG的工作原理 (opens new window)

# RAG - 提升你的AI应用的最佳选择
RAG是一种独特的方法,将传统语言模型的能力与外部知识库的精确性相结合。这种方法有几个突出的优点,使其在特定情境下特别有优势,相比仅仅使用提示工程或微调。
首先,RAG通过实时检索外部数据,确保提供的信息是最新和相关的。这对于需要最新信息的应用非常重要,例如新闻相关查询或快速发展的领域。
其次,RAG在定制和资源需求方面提供了一个平衡的方法。与完全微调相比,它不需要大量的计算资源,可以进行更灵活和资源高效的操作,使更多的用户和开发人员能够使用。
最后,RAG的混合性质弥合了LLM的广泛生成能力和知识库中可用的特定详细信息之间的差距。其输出不仅相关和详细,而且具有上下文丰富性。
优化的、可扩展的、具有成本效益的向量数据库解决方案可以极大地提高你的RAG应用的性能和功能。这就是为什么你需要MyScale (opens new window),一个基于SQL的向量数据库,它可以与主流的AI框架和语言模型平台(如OpenAI、Langchain、Langchain JS/TS和LlamaIndex)进行平滑集成。使用MyScale,RAG将变得更加快速和准确 (opens new window),这对于寻求最佳结果的用户非常有帮助。
# 结论
总之,选择提示工程、微调还是检索增强生成(RAG)将取决于你项目的具体要求、可用资源和期望的结果。每种方法都有其独特的优势和局限性。提示工程易于使用和成本效益,但定制能力有限。微调以更高的成本和复杂性提供详细的定制。RAG在提供最新和特定领域信息方面具有平衡性和中等复杂性。
如果你想与我们进一步讨论,请加入MyScale的Discord (opens new window)分享你的想法和反馈。



