
最近,人们对大型语言模型(LLMs) (opens new window)及其多样化的应用场景,从聊天机器人 (opens new window)到内容生成,产生了很多关注。然而,尽管这些模型有多种应用,但在实际部署中,LLMs面临着重大挑战,特别是在不同硬件设备上高效运行方面。这些模型计算量大,需要大量内存,使得在处理能力有限的设备上运行它们变得困难,比如智能手机和平板电脑。这种限制可能会阻碍LLMs的广泛采用。
为了解决这些挑战,研究人员引入了量化作为一种可行的解决方案。量化通过将高精度参数转换为低精度格式,减少模型的内存使用和大小,使其能够在不牺牲性能的情况下在不同设备上运行。
在本文中,我们将深入探讨LLMs的原理、它们对自然语言处理任务的变革性影响以及在不同硬件平台上优化这些模型的重要性。我们还将讨论优化挑战,并强调量化作为在各种设备上部署LLMs的强大方法。
# LLMs的工作原理及量化的必要性
LLMs通过在包括书籍、文章和网络内容在内的大量数据集上进行训练来运作。它们通过调整数百万甚至数十亿个参数来理解和生成人类语言,这些参数本质上是模型在训练过程中微调以最小化预测误差的权重。这些权重占用了大量内存,这对于计算资源有限的设备来说是一个重大挑战。
例如,一个具有50亿个参数的模型在使用16位精度时需要约10 GB的内存来加载,这对于计算能力有限的设备来说是不切实际的。这就是量化变得必要的地方。通过降低模型参数的精度,量化可以减少内存使用和计算负载,而不会显著影响性能。这个过程涉及将高精度权重和激活(例如16位浮点数或32位浮点数)转换为低精度(例如8位整数)。
# 量化概述:
量化对于在各种硬件平台上高效部署LLMs至关重要。它通过将高精度权重和激活(例如32位浮点数)转换为低精度(例如8位整数),减少了模型的大小和计算需求。这种精度降低导致模型大小更小、计算更快、内存使用更低,使得在智能手机和物联网设备等边缘设备上运行模型成为可能,而准确性的损失不大。
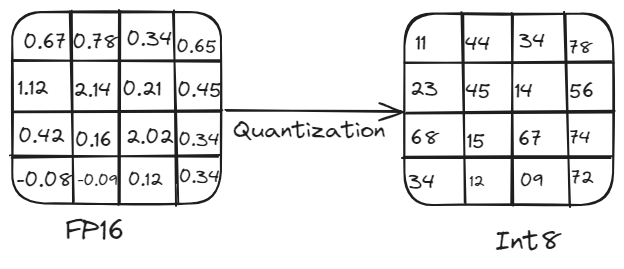
量化过程
# 量化的执行方法
量化可以使用两种主要方法进行:对称量化和非对称量化。
# 对称量化
这种方法将正值和负值都对称地缩放到零周围。所有值使用相同的比例因子,简化了计算,但有时会导致具有偏斜分布的值的表示效率较低。
假设我们有一个范围从-6到5的浮点数。为了量化这些值,我们找到最大的绝对值,即6。我们使用这个值来缩放整个范围。在8位表示中,范围是从-128到127。因此,我们将-6映射到-128,0映射到0,5映射到约106。这样,缩放就是以零为中心的对称缩放。
Q=round(SX)
这里,S是比例因子(例如6/128)。
# 非对称量化
这种方法对不同范围的值使用不同的比例因子。它提供了更大的灵活性,通常可以获得更好的模型性能,但实现起来可能更复杂。
假设我们有一个范围从0到10的浮点数。在8位表示中,这个范围可以直接映射到0到255,利用了量化值的整个范围。这里,零点用于正确对齐范围,确保整个范围被有效地利用。
X=Q×S+Z
这里,S是比例因子,Z是零点调整。
# 量化的模式
量化有两种主要模式:训练后量化和量化感知训练。
# 训练后量化(PTQ)
这种方法涉及将已经以完整精度(通常为32位浮点数)训练的模型转换为较低精度格式(例如8位整数)。该过程简单快速,因为它不需要重新训练模型。然而,由于模型最初并不是在较低精度下进行训练的,所以其准确性可能会稍微降低。这是因为模型的权重和激活被近似为适应较小位表示,这可能引入一些量化误差。
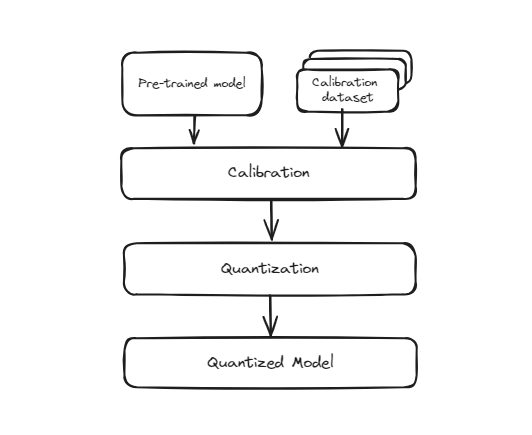
训练前量化
然而,在此转换过程中,权重的精度降低可能会导致模型在准确识别数字方面略有下降。这在模型大小和推理速度至关重要的场景中特别有用,例如移动应用、嵌入式系统和边缘计算。尽管可能会稍微降低准确性,但效率和可扩展性的好处通常是值得的。
# 量化感知训练(QAT)
这种技术将量化直接纳入神经网络的训练过程中。QAT在训练过程中考虑了较低精度,而不是先训练模型,然后将其转换为较低精度。这意味着在训练过程中,模型的权重和激活被“伪量化”以模拟较低精度的效果。这有助于模型学习如何在量化值的约束下有效运行,从而在实际转换为较低精度时获得更好的性能。QAT需要更多的计算资源和时间,因为模型在训练过程中经历了额外的步骤,但通常比训练后量化(PTQ)具有更高的准确性。
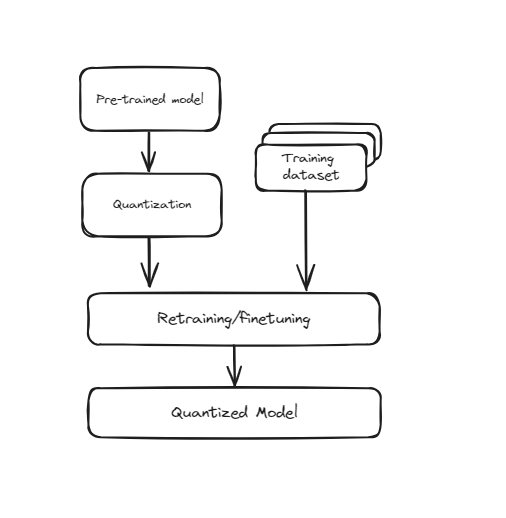
训练感知量化
这对于需要保持高准确性的应用程序特别有用,例如图像识别、自然语言处理和其他人工智能任务。尽管训练时间和资源需求增加,但在较低精度下改进的性能和准确性使得QAT成为在资源受限环境中部署高性能模型的有价值的技术。
# 量化的优缺点
优点:
- 模型占用的存储空间更小,更易于分发和部署。
- 低精度计算更快,提高实时性能。
- 适用于电池供电设备。
缺点:
- 量化可能引入误差,降低模型的准确性。
- 特别是对于非对称量化和QAT。
- 并非所有硬件都能高效支持所有类型的量化。

# 量化的实际示例
在这个示例中,我们将演示如何使用transformers和torch库对预训练的DistilBERT模型进行动态量化。这将有助于减小模型大小,并使其适用于计算资源有限的设备上部署。
让我们创建一个Python脚本来加载预训练的DistilBERT模型,执行动态量化,并比较原始模型和量化模型的大小。以下是逐步代码解释:
- 导入所需库
首先,我们需要安装transformers和torch库来执行量化。您可以在终端中运行以下命令来完成安装:
pip install transformers torch
torch库用于处理PyTorch模型和量化任务,而transformers库用于加载预训练的DistilBERT模型和分词器。此外,os模块用于与操作系统进行交互,例如读取和写入文件。
import torch
from transformers import DistilBertModel, DistilBertTokenizer
import os
- 加载预训练模型和分词器
然后,我们使用transformers库的DistilBertModel和DistilBertTokenizer类加载预训练的DistilBERT模型和分词器。模型名称distilbert-base-uncased用于指定DistilBERT的特定变体。
model_name = 'distilbert-base-uncased'
model = DistilBertModel.from_pretrained(model_name)
tokenizer = DistilBertTokenizer.from_pretrained(model_name)
- 定义量化函数
接下来,我们定义一个名为quantize_model的函数,该函数对模型执行动态量化。我们使用torch.quantization.quantize_dynamic函数将模型转换为量化版本,具体针对torch.nn.Linear层,并使用8位整数(qint8)精度。
def quantize_model(model):
quantized_model = torch.quantization.quantize_dynamic(
model, {torch.nn.Linear}, dtype=torch.qint8
)
return quantized_model
- 量化DistilBERT模型
然后,我们将quantize_model函数应用于DistilBERT模型,得到一个量化版本的模型。
quantized_model = quantize_model(model)
- 检查原始模型和量化模型的大小
最后,我们定义一个名为print_model_size的函数,用于检查和打印原始模型和量化模型的大小。我们使用torch.save函数将模型的状态字典保存到文件中,使用os.path.getsize函数获取文件大小(以兆字节MB为单位)。
def print_model_size(model, model_name):
torch.save(model.state_dict(), f'{model_name}.pt')
print(f'{model_name}的大小:{os.path.getsize(f"{model_name}.pt") / 1e6} MB')
然后,我们使用这个函数来打印原始DistilBERT模型和量化模型的大小。
print_model_size(model, 'original_distilbert')
print_model_size(quantized_model, 'quantized_distilbert')
代码的最终输出如下:
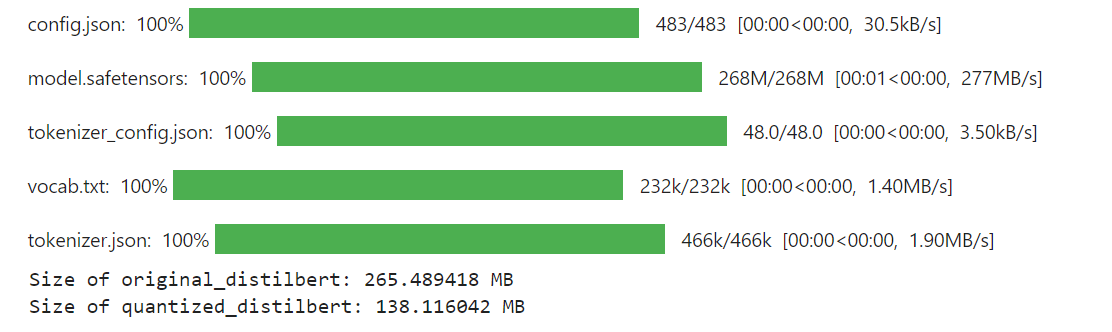
结果
如您所见,将量化应用于DistilBERT模型后,其大小从265 MB减小到138 MB。
# 量化如何帮助构建更好的RAG系统
量化使我们能够更有效地使用更大的模型,通过减小模型大小而不显著降低性能。随着模型的增大,LLMs自然表现得更好,并具有更先进的功能,但它们也需要大量的计算资源。通过量化,我们可以缩小这些大型模型,使我们能够在资源有限的环境中部署它们,同时仍然享受其增强的功能。
向量数据库可以与量化技术集成,通过提高效率和可扩展性,显著增强RAG系统。通过存储和搜索量化的嵌入向量,向量数据库实现了更快的检索、更低的内存使用和更低的计算成本。这使得RAG系统能够处理更大的数据集并更快地响应,同时保持可接受的准确性。与量化的LLMs的兼容性确保了整个流程的一致性,从而可能提高整体性能。MyScaleDB (opens new window)是一款SQL向量数据库,通过提供高效准确的数据检索,进一步增强了RAG的性能。它具有熟悉的SQL界面,价格实惠,速度快,针对生产级RAG应用进行了优化,是开发人员的不错选择。
如果您有任何建议,请通过Twitter (opens new window)或Discord (opens new window)与我们联系。



