
![]()
LlamaIndex (opens new window) 是一个数据框架,旨在使用大型语言模型(LLM)实现应用程序,简化解析、存储和检索各种类型的文档数据,并为LLM应用程序增加巨大的价值。这种机制通常被称为检索增强生成(RAG)。
为了帮助您了解如何使用LlamaIndex来实现这种机制,本文将构建一个简单的文档查询引擎来演示整个过程。
# MyScale
虽然LlamaIndex可以处理各种类型的源数据,但它不存储或索引这些数据。我们仍然需要一个存储系统。MyScale (opens new window) 是一个支持SQL且易于使用的向量数据库,其免费版本支持多达500万个向量数据点。最重要的是,LlamaIndex支持MyScale向量数据库 (opens new window)。您可以使用MyScaleVectorStore和MyScaleReader连接到MyScale数据库以存储和查询数据,并通过LlamaIndex执行以下数据操作:
| 向量存储 | 类型 | 元数据过滤 | 混合搜索 | 删除 | 存储文档 |
|---|---|---|---|---|---|
| MyScale | 云 | ✓ | ✓ | ✓ | ✓ |
这套操作提供了全面的功能。现在,让我们开始使用这些操作构建我们的LLM应用程序。
# 准备工作
注意:
本文提到的所有相关代码都可以在GitHub上的存储库myscale/llama_index_myscale (opens new window)中找到。
# 数据
我们使用了MyScale官方文档(MyScale Docs (opens new window))的Markdown格式作为我们的原始数据。您也可以在GitHub (opens new window)上查看和下载这些文件。
# 依赖项
- Python 3.8.18
- LlamaIndex 0.9.5
- MyScale
# 流程图
构建检索增强生成(RAG)应用程序涉及多个处理步骤,如下图所示。首先,我们必须离线处理原始数据,包括根据特定标准或规则将存储在平面文件中的文本数据拆分为数据节点。完成此步骤后,我们需要计算每个数据节点的向量表示。最后,我们必须将数据存储在数据库中。
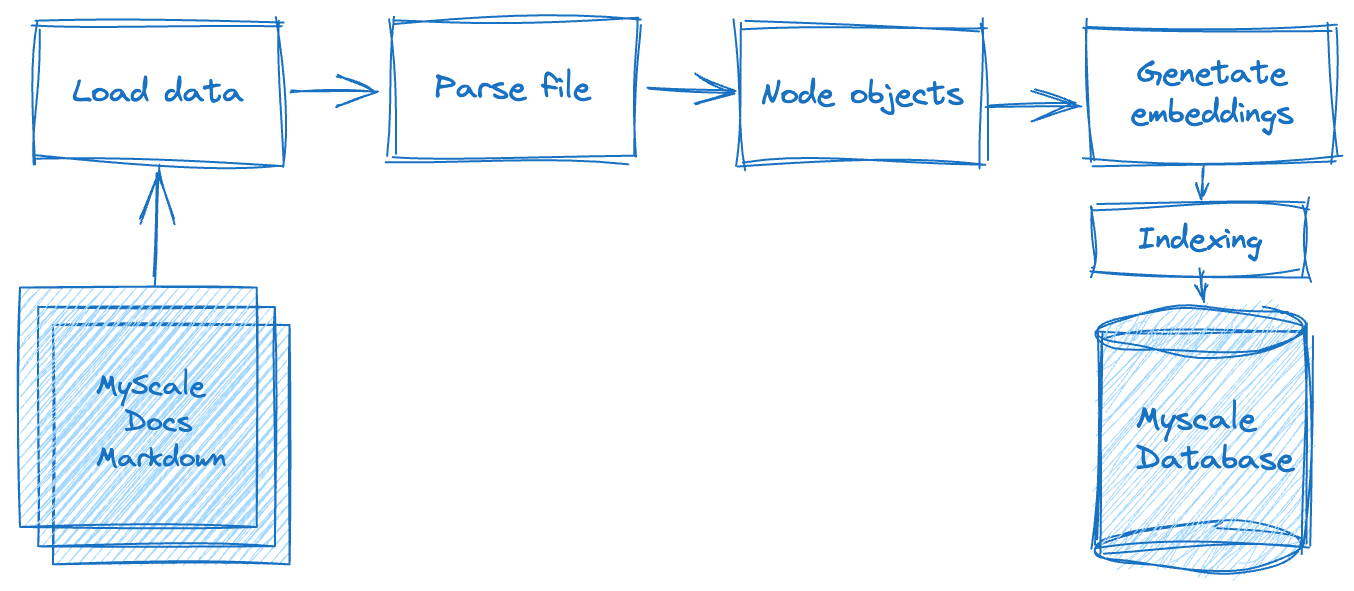
在第二阶段-数据检索阶段,我们基于此查询查询和合并相关文档数据。然后,该数据由LLM系统请求并返回,返回预期的结果。
现在,让我们探索如何将LlamaIndex与MyScale集成以完成这些步骤。
# 加载数据
在此阶段,我们需要读取下载的文档文件,将其转换为MyScale文档对象,并利用LlamaIndex的丰富文档处理功能,包括处理Markdown、PDF、Word文档、PowerPoint演示文稿、图像、音频和视频。对于.md文档,使用MarkdownReader,如下所示:
# utils.py
from llama_index import download_loader
from llama_index import Document
from typing import Dict, List, Union
from pathlib import Path
UnstructuredReader = download_loader("MarkdownReader")
loader = UnstructuredReader()
def load_and_parse_files(file_row: Dict[str, Path]) -> List[Dict[str, Document]]:
documents = []
file = file_row["path"]
if file.is_dir():
return []
# Skip all non-md files like png, jpg, etc., html.
if file.suffix.lower() == ".md":
loaded_doc = loader.load_data(file=file)
loaded_doc[0].extra_info = {"path": str(file)}
documents.extend(loaded_doc)
return [{"doc": doc} for doc in documents]
# 解析文档
在从这些文档中读取文本段落后,我们需要将它们封装成数据节点,以便进行下一步的向量化操作。为了确保格式一致性,我们继续使用MarkdownNodeParser。这部分的处理流程如下:
# utils.py
from llama_index.node_parser import MarkdownNodeParser
from llama_index.data_structs import Node
def convert_documents_into_nodes(documents: Dict[str, Document]) -> List[Dict[str, Node]]:
parser = MarkdownNodeParser()
document = documents["doc"]
nodes = parser.get_nodes_from_documents([document])
return [{"node": node} for node in nodes]
# 向量化
向量化是一个关键且耗时的步骤。这涉及对上一步返回的数据节点的文本内容进行向量化,并将向量存储在数据节点的“embedding”字段中。我们使用Hugging Face的sentence-transformers/all-mpnet-base-v2模型 (opens new window),可以从Hugging Face获取。LlamaIndex将自动帮助我们下载和应用这些嵌入到我们的应用程序中。
# utils.py
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
class EmbedNodes:
def __init__(self):
self.embedding_model = HuggingFaceEmbeddings(
# 使用all-mpnet-base-v2 Sentence_transformer。
# 这是LlamaIndex/Langchain的默认嵌入模型。
model_name="sentence-transformers/all-mpnet-base-v2",
model_kwargs={},
# 使用GPU进行嵌入,并指定足够大的批量大小以最大化GPU利用率。
# 删除"device": "cuda"以使用CPU。
encode_kwargs={"batch_size": 100}
)
def __call__(self, node_batch: Dict[str, List[Node]]) -> Dict[str, List[Node]]:
nodes = node_batch["node"]
text = [node.text for node in nodes]
embeddings = self.embedding_model.embed_documents(text)
assert len(nodes) == len(embeddings)
for node, embedding in zip(nodes, embeddings):
node.embedding = embedding
return {"embedded_nodes": nodes}
# 本地执行和存储在 MyScale 中
我们在上述过程中介绍了解析和向量化Markdown文档的主要操作。接下来,我们需要输出数据并构建索引。在LlamaIndex中,我们可以使用MyScaleVectorStore执行这些非复杂的操作,如下所示的Python脚本:
注意:
这段脚本包含了整个数据处理流程。
# create_vector_index.py
import clickhouse_connect
import utils
from pathlib import Path
from llama_index import VectorStoreIndex
from llama_index.vector_stores import MyScaleVectorStore
from llama_index.storage import StorageContext
all_docs_gen = Path("./docs.myscale.com/").rglob("*")
all_docs = [{"path": doc.resolve()} for doc in all_docs_gen]
blog_nodes = {"embedded_nodes": []}
for docs in all_docs:
loaded_docs = utils.load_and_parse_files(docs)
for doc in loaded_docs:
nodes = utils.convert_documents_into_nodes(doc)
newNodes = {"node": []}
for node in nodes:
newNodes["node"].append(node["node"])
embedNodes = utils.EmbedNodes()
tmpNodes = embedNodes(newNodes)
blog_nodes["embedded_nodes"].extend(tmpNodes["embedded_nodes"])
client = clickhouse_connect.get_client(
host='{MYSCALE_CLUSTER_URL}',
port=443,
username='{YOUR_USERNAME}',
password='{YOUR_PASSWORD}'
)
vector_store = MyScaleVectorStore(myscale_client=client)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
VectorStoreIndex(blog_nodes["embedded_nodes"], storage_context=storage_context)
为了重用性,函数load_and_parse_files、convert_documents_into_nodes和EmbedNodes被放置在utils.py中。
# 构建查询服务
一旦数据存储在MyScale中,我们可以使用MyScaleVectorStore和LLM的API来处理用户查询,如下所示的脚本query_myscale.py。以下是该脚本的内容,包括以下主要步骤:
此脚本包括以下主要步骤:
- 从终端读取用户输入的查询并将其向量化。
- 使用
llama_index.vector_stores.MyScaleVectorStore以混合搜索模式查询与查询相关的数据。此模式确保文本和向量距离都具有一定的相关性。 - 通过将上一步获取的文档发送给LLM生成最终结果,合成响应。
# query_myscale.py
import clickhouse_connect
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from llama_index.schema import NodeWithScore
from llama_index.vector_stores import MyScaleVectorStore, VectorStoreQuery
from llama_index.vector_stores.types import VectorStoreQueryMode
# 在运行脚本之前,在此处添加您的OpenAI API密钥。
model = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")
client = clickhouse_connect.get_client(
host='{MYSCALE_CLUSTER_URL}',
port=443,
username='{YOUR_USERNAME}',
password='{YOUR_PASSWORD}'
)
# 输入查询
query = input("Query: ")
while len(query) == 0:
query = input("\nQuery: ")
# 嵌入查询
embedded_query = model.embed_query(query)
# 使用llama_index.vector_stores.MyScaleVectorStore发送查询到myscale
vector_store = MyScaleVectorStore(myscale_client=client)
vector_store_query = VectorStoreQuery(
query_embedding=embedded_query,
similarity_top_k=20,
mode=VectorStoreQueryMode.HYBRID
)
result = vector_store.query(vector_store_query)
scoreNodes = [NodeWithScore(node=result.nodes[i], score=result.similarities[i]) for i in range(len(result.nodes))]
# 合成响应
from llama_index.response_synthesizers import (
get_response_synthesizer,
)
synthesizer = get_response_synthesizer()
response_obj = synthesizer.synthesize(query, scoreNodes)
print(f"Response: {str(response_obj.response)}")
注意:
请将占位符(如{MYSCALE_CLUSTER_URL}、{YOUR_USERNAME}和{YOUR_PASSWORD})替换为您实际的MyScale集群信息。

# 执行脚本
执行脚本,在提示后输入查询,即可获得以下响应:
$ python query_myscale.py
Query: How to create a MyScale Cluster?
Response: To create a MyScale Cluster, you can follow these steps:
1. Go to the Clusters page.
2. Click on the "+ New Cluster" button.
3. Name your cluster.
4. Click "Launch" to run the cluster.
Once the cluster is created, it will start automatically. Please note that the cluster will be terminated if there is no activity for 7 days, and all data in the cluster will be deleted.
您可以输入各种与MyScale相关的问题。该应用程序旨在提供有价值的答案。
# 进一步探索
我们已经成功地使用MyScale和LlamaIndex构建了一个功能完善的LLM应用程序,展示了其有效的性能。那么,如何加快嵌入过程以应对十万甚至百万级的文档数据?
幸运的是,我们可以使用Ray,一个专为机器学习设计的框架,结合LlamaIndex和MyScale进行分布式计算,以提高数据处理效率。您可以参考Ray的官方文档,安装Ray (opens new window)或Ray on Kubernetes (opens new window),构建本地或基于Kubernetes的集群。
假设您已经在本地主机上拥有一个RayCluster Head或已在Kubernetes集群中启用了RayCluster Head的端口转发,您可以直接使用以下代码来通过并行计算改进嵌入处理,从而显著加快数据处理速度和效率:
# create_vector_index_by_ray.py
import clickhouse_connect
import utils
import ray
from pathlib import Path
from llama_index import VectorStoreIndex
from llama_index.vector_stores import MyScaleVectorStore
from llama_index.storage import StorageContext
from ray.data import ActorPoolStrategy
all_docs_gen = Path("./docs.myscale.com/").rglob("*")
all_docs = [{"path": doc.resolve()} for doc in all_docs_gen]
ds = ray.data.from_items(all_docs)
loaded_docs = ds.flat_map(utils.load_and_parse_files)
nodes = loaded_docs.flat_map(utils.convert_documents_into_nodes)
embedded_nodes = nodes.map_batches(
utils.EmbedNodes,
batch_size=100,
compute=ActorPoolStrategy(size=4),
num_gpus=0)
blogs_nodes = []
for row in embedded_nodes.iter_rows():
node = row["embedded_nodes"]
assert node.embedding is not None
blogs_nodes.append(node)
client = clickhouse_connect.get_client(
host='{MYSCALE_CLUSTER_URL}',
port=443,
username='{YOUR_USERNAME}',
password='{YOUR_PASSWORD}'
)
vector_store = MyScaleVectorStore(myscale_client=client)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
VectorStoreIndex(blogs_nodes, storage_context=storage_context)
这些过程,使用与本地执行和存储在 MyScale 中部分中描述的相同的输入和输出,也可以查询存储在MyScale数据库中的相关向量数据。然后,您可以使用query_myscale.py执行查询。
# 总结
MyScale和LlamaIndex是用于LLM处理的两个优秀工具。它们可以帮助您快速构建LLM应用程序。当面临大规模数据问题时,您可以使用Ray进行分布式处理,结合LlamaIndex和MyScale,极大地提高开发的便利性。
最后,对于大规模的RAG应用程序,请立即访问myscale.com (opens new window)设置您的集群!



