
生成AI(GenAI)的迭代速度呈指数增长。其中一个结果是上下文窗口的扩展,即一个大型语言模型(LLM)一次可以使用的标记数量,用于生成响应。
2024年2月发布的Google Gemini 1.5 Pro创下了迄今为止最长的上下文窗口记录:100万个标记,相当于1小时的视频或70万个单词。Gemini在处理长上下文方面的出色表现使一些人宣称“检索增强生成(RAG)已经死了”。他们说,LLM已经是非常强大的检索器,为什么要花时间构建一个弱检索器并处理与RAG相关的问题,如分块、嵌入和索引?
增加的上下文窗口引发了一场辩论:在这些改进下,RAG是否仍然需要?或者它可能很快就会过时?
# RAG的工作原理
LLM不断推动机器理解和实现的界限,但它们受到一些问题的限制,例如对未见数据的准确响应困难或与最新信息保持同步。这些问题导致了幻觉的产生,而RAG就是为了解决这些问题而开发的 (opens new window)。
RAG将LLM的能力与外部知识源相结合,以产生更具见解和准确性的响应。当接收到用户查询时,RAG系统首先处理文本以理解其上下文和意图。然后,它从知识库 (opens new window)中检索与用户查询相关的数据,并将其与查询一起作为上下文传递给LLM。它只传递相关数据而不是整个知识库,因为LLM有上下文限制 (opens new window),即模型一次可以考虑或理解的文本量。
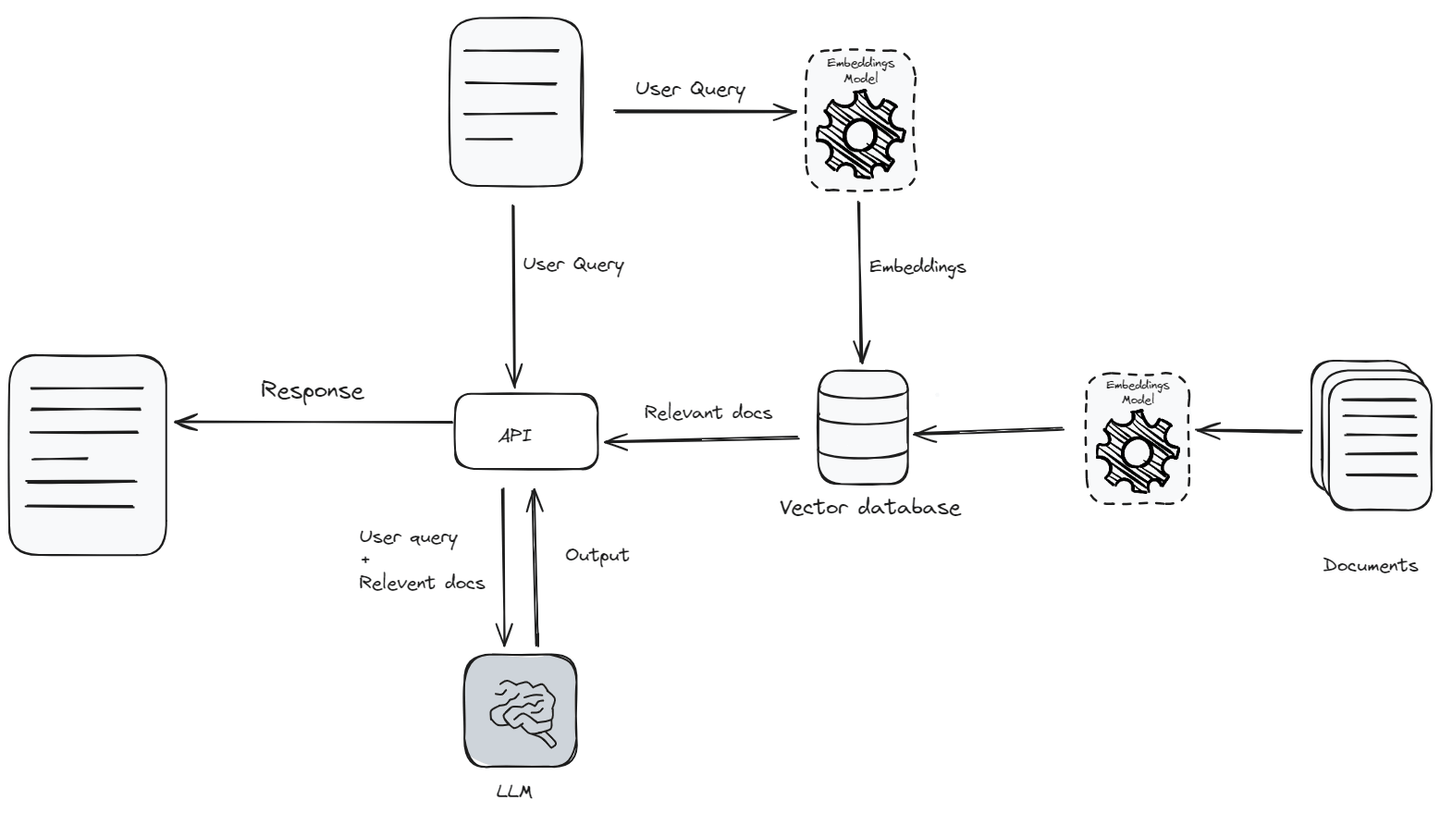
首先,将查询 (opens new window)转换为向量嵌入 (opens new window),使用嵌入模型 (opens new window)。然后,将该嵌入向量与文档向量数据库进行比较,识别出最相关的文档。这些相关文档与原始查询结合,为LLM生成更准确的响应提供了丰富的上下文。这种混合方法使模型能够使用外部来源的最新信息,使LLM能够生成更具见解和准确性的响应。
# 为什么长上下文窗口可能是RAG的终结
LLM的上下文窗口不断增加将直接影响这些模型的输入和生成响应的方式。通过增加LLM一次可以处理的文本量,这些扩展的上下文窗口增强了模型理解更全面的叙述和复杂思想的能力,提高了生成响应的整体质量和相关性。这提高了LLM处理更长文本的能力,使其能够更有效地把握上下文及其细节。因此,随着LLM在处理和整合广泛上下文方面变得更加熟练,对于提高响应准确性和相关性的RAG的依赖可能会减少。
# 准确性
RAG通过根据相似度得分 (opens new window)提供相关文档作为上下文来提高模型的能力。然而,RAG不会实时适应或从上下文中学习。相反,它检索与用户查询相似的文档,这些文档可能并不总是最具上下文适应性的,可能导致响应不准确。
另一方面,通过利用语言模型的长上下文窗口,将所有数据放入其中,LLM的注意机制 (opens new window)可以生成更好的答案。语言模型内部的注意机制专注于所提供上下文的不同部分,以生成精确的响应。此外,这种机制可以进行微调 (opens new window)。通过调整LLM模型以减少损失,它变得越来越好,从而产生更准确和上下文相关的响应。
# 信息检索
从知识库中检索信息以增强LLM的响应时,往往很难找到完整和相关的数据以用于上下文窗口。关于检索到的数据是否完全回答了用户的查询,始终存在不确定性。如果所选择的信息不足或与用户的实际意图或对话的上下文不符,这种情况可能导致低效和错误。
# 外部存储
传统上,LLM无法同时处理大量信息,因为它们在处理上下文时受到限制。但是,它们的新增能力使它们能够直接处理大量数据,消除了每个查询的单独存储的需求。这简化了架构,加快了对外部数据库的访问速度,并提高了AI的效率。
# 为什么RAG将继续存在
LLM中扩展的上下文窗口可能为模型提供更深入的见解,但也带来了更高的计算成本和效率等挑战。RAG通过选择性地检索只有最相关的信息来解决这些挑战,这有助于优化性能和准确性。
# 复杂的RAG将持续存在
毫无疑问,简单的RAG,其中数据被分成固定长度的文档并根据相似性进行检索,正在消失。然而,复杂的RAG系统不仅持续存在,而且发展迅速。
复杂的RAG包括更广泛的功能,例如查询重写 (opens new window)、数据清理 (opens new window)、反思 (opens new window)、优化的向量搜索 (opens new window)、图搜索 (opens new window)、重新排序器 (opens new window)和更复杂的分块技术。这些增强不仅在改进RAG的功能,而且在扩展其能力。
# 超越上下文长度的性能
将LLM的上下文窗口扩展到包含数百万个标记看起来很有前景,但实际实现仍存在问题,包括时间、效率和成本等多个因素。
时间: 随着上下文窗口的增大,响应时间的延迟也会增加。随着上下文窗口的扩大,LLM处理更多标记的时间增加,导致延迟和响应时间增加。许多LLM应用程序需要快速响应。从处理更大的文本块导致的额外延迟可能会严重影响LLM在实时场景中的性能,成为实现更大上下文窗口的主要瓶颈。
效率: 研究表明,与提供大量未经筛选的数据相比,LLM在提供较少但更相关的文档时取得更好的结果。最近的一项斯坦福研究 (opens new window)发现,最先进的LLM在从广泛上下文窗口中提取有价值信息时经常遇到困难。当关键数据埋在大文本块的中间时,这种困难尤为明显,导致LLM忽略重要细节,导致数据处理效率低下。
成本: LLM中上下文窗口的扩大导致计算成本增加。处理更多的输入标记需要更多的资源,从而导致运营费用增加。例如,在ChatGPT等系统中,重点是限制处理的标记数量以控制成本。
RAG直接优化了这三个因素中的每一个。通过仅传递相似或相关的文档作为上下文(而不是将所有内容都放入其中),LLM更快地处理信息,这不仅减少了延迟,还提高了响应的质量,并降低了成本。
# 为什么不使用微调
除了使用更大的上下文窗口,RAG的另一种替代方法是微调。然而,微调可能既昂贵又繁琐。每次有新信息进来时更新LLM以使其保持最新状态是具有挑战性的。微调的其他问题包括:
- 训练数据限制: 无论LLM取得了多大的进展,总会有一些上下文在训练时不可用或被认为不相关。
- 计算资源: 要在数据集上对LLM进行微调并为特定任务进行定制,需要高计算资源。
- 需要专业知识: 开发和维护尖端AI并非易事。您需要专业的技能和知识,这可能很难获得。
其他问题包括收集数据,确保质量足够好以及模型部署。
# 比较RAG与微调或长上下文窗口
下面是RAG与微调或长上下文窗口技术的比较概述(因为后两者具有相似的特点,所以在此图表中将它们合并)。它突出了成本、数据时效性和可扩展性等关键方面。
| 特征 | RAG | 微调/长上下文窗口 |
| 成本 | 最低,无需训练 | 高,需要广泛的训练和更新 |
| 数据时效性 | 按需检索数据,确保实时性 | 数据可能很快过时 |
| 透明度 | 高,显示检索到的文档 | 低,不清楚数据如何影响结果 |
| 可扩展性 | 高,与各种数据源轻松集成 | 有限,扩展需要大量资源 |
| 性能 | 选择性数据检索提高性能 | 性能可能随着上下文大小的增加而下降 |
| 适应性 | 可以根据特定任务进行定制而无需重新训练 | 需要重新训练进行重大调整 |

# 使用向量数据库优化RAG系统
最先进的LLM可以同时处理数百万个标记,但数据结构的复杂性和不断变化使LLM难以有效管理异构企业数据。RAG解决了这些挑战,尽管检索准确性仍然是端到端性能的一个主要瓶颈。无论是LLM的大上下文窗口还是RAG,目标都是充分利用大数据,并确保大规模数据处理的高效性。
使用先进的SQL向量数据库(如MyScaleDB (opens new window))将LLM与大数据进行集成,可以增强LLM的效果,并从大数据中提取更好的智能。此外,它可以减少模型幻觉,提供数据透明度,并提高可靠性。MyScaleDB是一个基于ClickHouse (opens new window)的开源SQL向量数据库,专为大型AI/RAG应用程序量身定制。利用ClickHouse作为基础,并具有专有的MSTG算法,MyScaleDB在管理大规模数据方面展示了与其他向量数据库相比的卓越性能 (opens new window)。
LLM技术正在改变世界,长期记忆的重要性将持续存在。当大型企业将生成式AI投入生产时,他们需要控制成本,同时保持最佳的响应质量。RAG和向量数据库仍然是实现这一目标的重要工具。
欢迎您在GitHub (opens new window)上了解更多关于MyScaleDB的信息,或在我们的Discord (opens new window)上讨论LLM或RAG的更多内容。



