
MyScale最近推出了EmbedText (opens new window)函数,这是一个强大的功能,将SQL查询与文本向量化能力集成在一起,将文本转化为数值向量。这些向量有效地将人类感知的语义相似性映射到向量空间中的相似性。使用SQL熟悉的语法,EmbedText简化了向量化过程,提高了可访问性,使用户能够在MyScale中高效地执行文本向量化,与OpenAI (opens new window)、Jina AI (opens new window)、Amazon Bedrock (opens new window)等提供商实时和批处理场景下的合作。此外,通过利用自动批处理,大量数据的处理性能得到了极大的提升。这种集成消除了对外部工具或复杂编程的需求,简化了向量化过程,使其在MyScale数据库环境中进行。
# 介绍
EmbedText函数的定义为EmbedText(text, provider, base_url, api_key, others),具有高度可配置性,旨在实现实时搜索和批处理。
注意:
该函数的详细参数在我们的文档 (opens new window)中可用。
如下表所示,EmbedText函数支持以下八个提供商,每个提供商都具有独特的优势:
| 提供商 | 支持情况 | 提供商 | 支持情况 |
|---|---|---|---|
| OpenAI | ✔ | Amazon Bedrock | ✔ |
| HuggingFace | ✔ | Amazon SageMaker | ✔ |
| Cohere | ✔ | Jina AI | ✔ |
| Voyage AI | ✔ | Gemini | ✔ |
例如,OpenAI的text-embedding-ada-002模型 (opens new window)以其强大的性能而闻名。可以使用以下SQL命令在MyScale中使用该模型:
SELECT EmbedText('YOUR_TEXT', 'OpenAI', '', 'API_KEY', '{"model":"text-embedding-ada-002"}')
Jina AI的jina-embeddings-v2-base-en模型 (opens new window)支持长达8k的序列长度,提供了一种经济高效的嵌入维度选择。以下是如何使用该模型的示例:
SELECT EmbedText('YOUR_TEXT', 'Jina', '', 'API_KEY', '{"model":"jina-embeddings-v2-base-en"}')
注意:
该模型目前仅限于英文文本。
Amazon Bedrock Titan (opens new window)与OpenAI模型兼容,在AWS集成和安全功能方面表现出色,为AWS用户提供了全面的解决方案,如下代码片段所示:
SELECT EmbedText('YOUR_TEXT', 'Bedrock', '', 'SECRET_ACCESS_KEY', '{"model":"amazon.titan-embed-text-v1", "region_name":"us-east-1", "access_key_id":"ACCESS_KEY_ID"}')
# 创建专用函数
为了方便使用,您可以为每个提供商创建专用函数。例如,您可以使用OpenAI的text-embedding-ada-002模型定义以下函数:
CREATE FUNCTION OpenAIEmbedText ON CLUSTER '{cluster}'
AS (x) -> EmbedText(x, 'OpenAI', '', 'API_KEY', '{"model":"text-embedding-ada-002"}')
然后,可以简化OpenAIEmbedText函数的使用:
SELECT OpenAIEmbedText('YOUR_TEXT')
这种方法简化了嵌入过程,并减少了常见参数(如API密钥)的重复输入。
# 使用EmbedText进行向量处理
EmbedText在MyScale中彻底改变了向量处理,特别是对于向量搜索和数据转换。这个函数在将搜索查询和数据库列转化为数值向量方面起着关键作用,这是向量搜索和数据管理中的关键步骤。
# 提升向量搜索
在向量相似性搜索中,如我们的向量搜索指南 (opens new window)中所述,传统方法要求用户手动在SQL中输入查询向量。
SELECT id, distance(vector, [0.123, 0.234, ...]) AS dist
FROM test_embedding ORDER BY dist LIMIT 10
使用EmbedText简化了向量搜索过程,使其更直观,大大简化了用户体验,并将重点放在查询的形成上,而不是向量创建的机制上,如下代码片段所示:
SELECT id, distance(vector, OpenAIEmbedText('the text query')) AS dist
FROM test_embedding ORDER BY dist LIMIT 10
# 简化批处理转换
根据下图,我们可以看到批处理转换的典型工作流程涉及预处理和将文本数据存储为结构化格式。
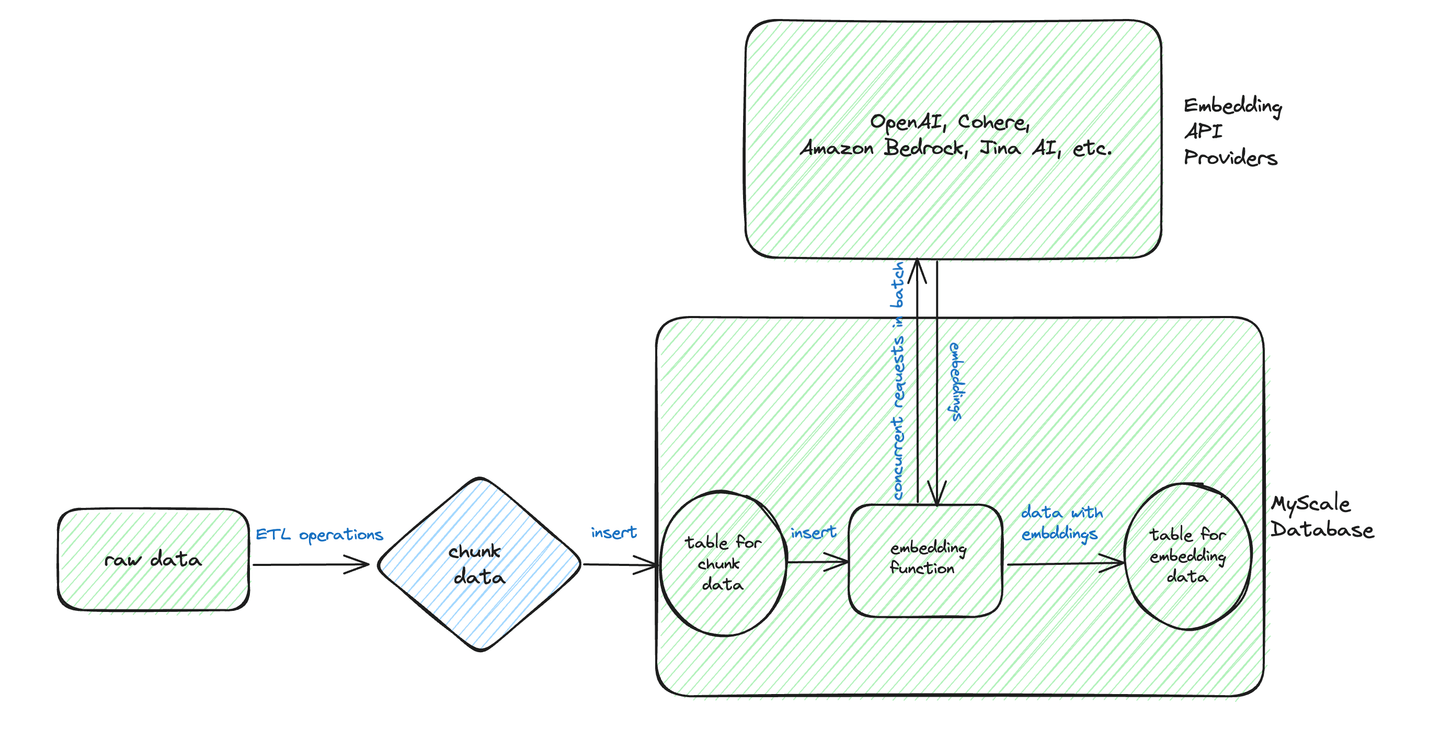
假设我们有以下包含原始数据的chunk_data表。
CREATE TABLE chunk_data
(
id UInt32,
chunk String,
) ENGINE = MergeTree ORDER BY id
INSERT INTO chunk_data VALUES (1, 'chunk1'), (2, 'chunk2'), ...
我们可以创建第二个表test_embedding,用于存储以下方式创建的向量嵌入——使用EmbedText函数。
CREATE TABLE test_embedding
(
id UInt32,
paragraph String,
vector Array(Float32) DEFAULT OpenAIEmbedText(paragraph),
CONSTRAINT check_length CHECK length(vector) = 1536,
) ENGINE = MergeTree ORDER BY id
将数据插入test_embedding变得简单。
INSERT INTO test_embedding (id, paragraph) SELECT id, chunk FROM chunk_data
或者,可以在插入过程中显式应用EmbedText。
INSERT INTO test_embedding (id, paragraph, vector) SELECT id, chunk, OpenAIEmbedText(chunk) FROM chunk_data
如上所述,EmbedText包括一个自动批处理功能,在处理多个文本时显著提高了处理效率。该功能在将数据发送到嵌入式API之前,在内部管理批处理过程,确保高效、简化的数据处理工作流程。在NVIDIA A10G GPU上使用BAAI/bge-small-en模型 (opens new window)的示例中,这种效率的例子可以达到每秒1200个请求。

# 结论
MyScale的EmbedText函数是一个实用且高效的文本向量化工具,简化了复杂的过程,使先进的向量搜索和数据转换变得民主化。我们的愿景是将这一创新无缝集成到日常数据库操作中,为AI/LLM相关的数据处理赋予广泛的用户群体以权力。




