
强大的大型语言模型(LLM)如GPT-4、Gemini 1.5和Claude 3在人工智能和技术领域产生了巨大影响。一些模型能够处理超过100万个标记 (opens new window),它们处理长上下文的能力令人印象深刻。然而:
- 许多数据结构对LLM来说过于复杂且不断演变,无法有效处理。
- 在上下文窗口中管理庞大、异构的企业数据是不切实际的。
检索增强生成(RAG)有助于解决这些问题,但检索准确性是端到端性能的一个主要瓶颈,许多向量数据库在复杂用例中无法良好扩展。一种解决方案是通过高级SQL向量数据库将LLM与大数据集成。LLM和大数据之间的这种协同作用不仅使LLM更加有效,还使人们能够从大数据中获得更好的智能。此外,它进一步减少了模型幻觉,同时提供数据透明性和可靠性。
# 向量数据库的当前状态
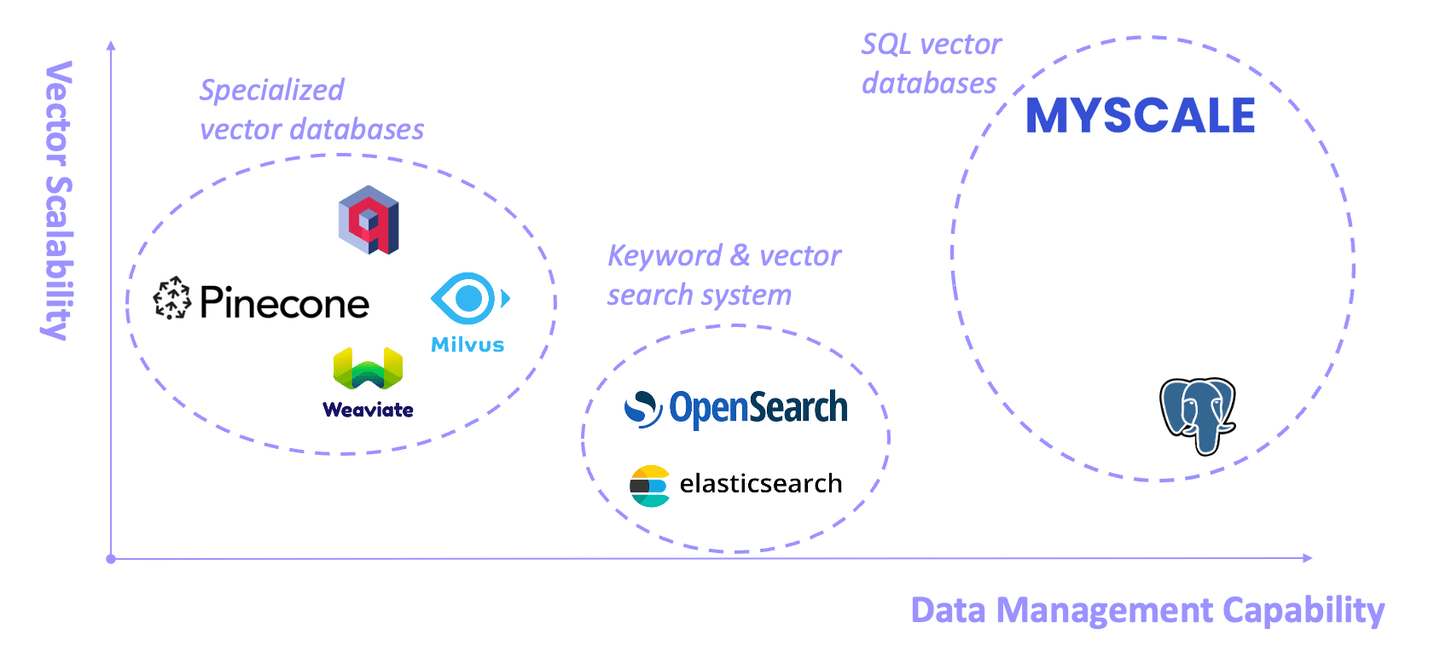
作为RAG系统的基石,向量数据库在过去一年中得到了快速发展。它们通常可以分为三类:专用向量数据库、关键词和向量检索系统以及SQL向量数据库。每种类型都有其优点和局限性。
# 专用向量数据库
一些向量数据库(如Pinecone、Weaviate和Milvus)从一开始就专为向量搜索而设计。它们在这个领域表现出色,但在一般数据管理能力方面有一定的局限性 (opens new window)。
# 关键词和向量检索系统
以Elasticsearch和OpenSearch为代表,这些系统由于其全面的基于关键词的检索能力而被广泛应用于生产环境。然而,它们消耗大量系统资源,并且关键词和向量混合查询的准确性和性能通常不尽如人意 (opens new window)。
# SQL向量数据库
SQL向量数据库 (opens new window)是一种将传统SQL数据库的能力与向量数据库的能力相结合的专用数据库类型。它通过SQL的帮助,提供了高效存储和查询高维向量的能力。
上图中展示了两个主要的SQL向量数据库:pgvector和MyScaleDB。pgvector是PostgreSQL的向量搜索插件。它易于入门,适用于管理小型数据集。然而,由于Postgres的行存储劣势和向量算法的限制,pgvector在大规模、复杂向量查询的准确性和性能方面往往较低。
MyScaleDB (opens new window)是一个基于ClickHouse(一种列存储SQL数据库)构建的开源SQL向量数据库。它旨在为GenAI应用提供高性能和具有成本效益的数据基础。MyScaleDB也是第一个在整体性能和成本效益方面超越专用向量数据库 (opens new window)的SQL向量数据库。

来源:https://myscale.github.io/benchmark (opens new window)
# SQL和向量联合数据建模的威力
尽管NoSQL和大数据技术的出现,SQL数据库在SQL诞生半个世纪后仍然主导着数据管理市场。即使像Elasticsearch和Spark这样的系统也添加了SQL接口。借助SQL支持,MyScaleDB作为一种SQL向量数据库,能够在向量搜索和分析方面实现高性能 (opens new window)。
在实际的AI应用中,将SQL和向量集成可以增强数据建模的灵活性并简化开发。例如,一个大规模的学术产品使用MyScaleDB对大量科学文献数据进行智能问答。主要的SQL模式包括10多个表,其中几个表具有向量和基于关键词的倒排索引结构,通过主键和外键连接。该系统处理涉及结构化、向量和关键词数据的复杂查询以及跨多个表的连接查询。这对于专用向量数据库来说是一项具有挑战性的任务,往往导致迭代速度慢、查询效率低和维护成本高。
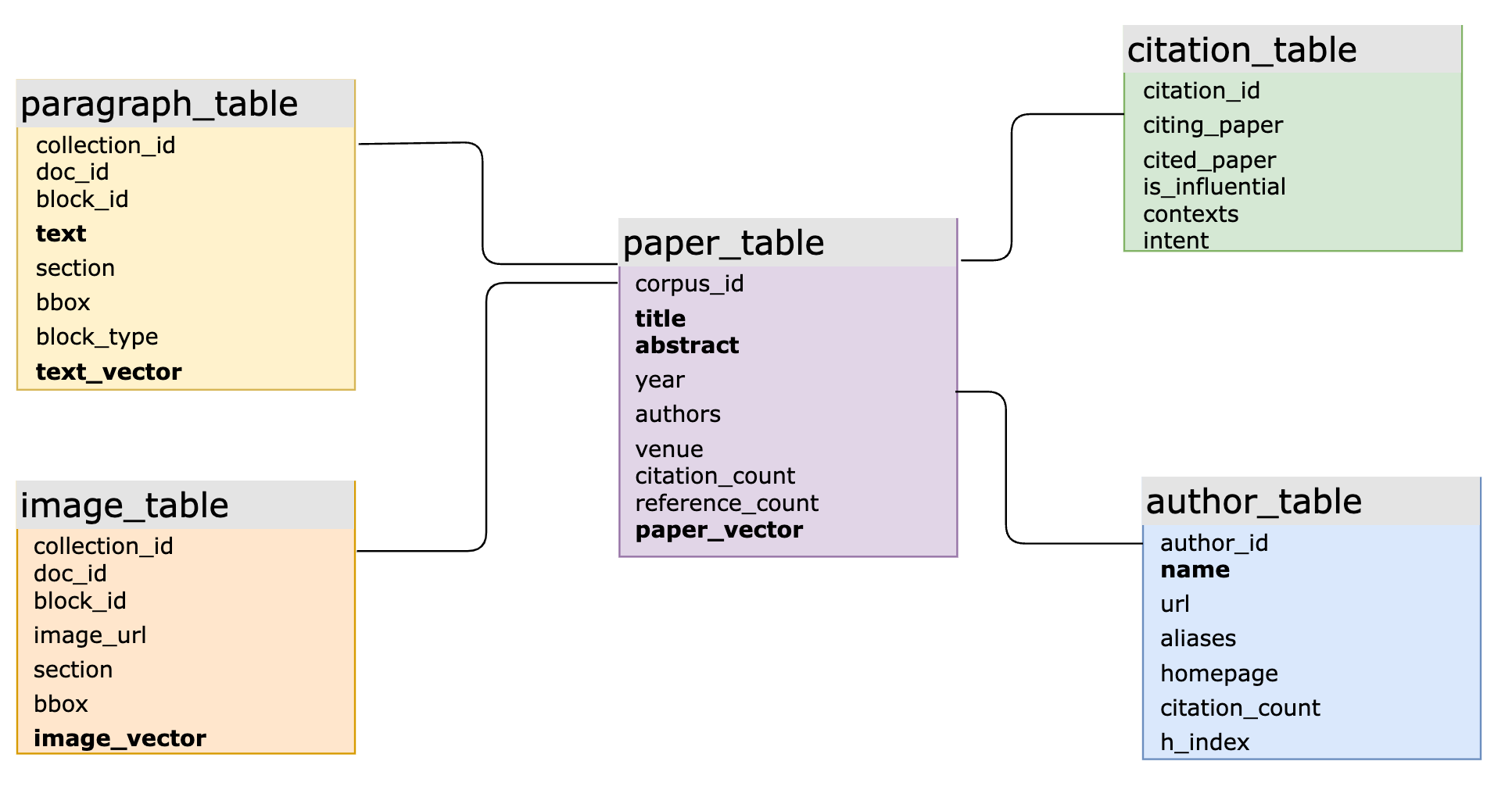
由MyScale支持的一个大规模学术产品的主要SQL向量数据库模式(加粗的列具有关联的向量索引或倒排索引)
# 提高RAG准确性和成本效益
在实际的RAG系统中,克服检索准确性(及相关的性能瓶颈)需要一种高效的方式来结合结构化、向量和关键词数据的查询。
例如,在金融应用中,当用户查询一个文档数据库时,询问“<公司名称>在2023年的全球收入是多少?”结构化元数据如“<公司名称>”和“2023年”可能无法被语义向量捕捉到或在连续文本中出现。在整个数据库上进行向量检索可能会产生噪音结果,降低最终的准确性。
然而,公司名称和年份等信息通常可以作为文档元数据获得。使用WHERE year=2023 AND company LIKE "%<公司名称>%"作为向量查询的过滤条件可以精确定位相关信息,显著提高系统的可靠性。在金融、制造和研究领域,观察到SQL向量数据建模和联合查询可以将精度从60%提高到90%。
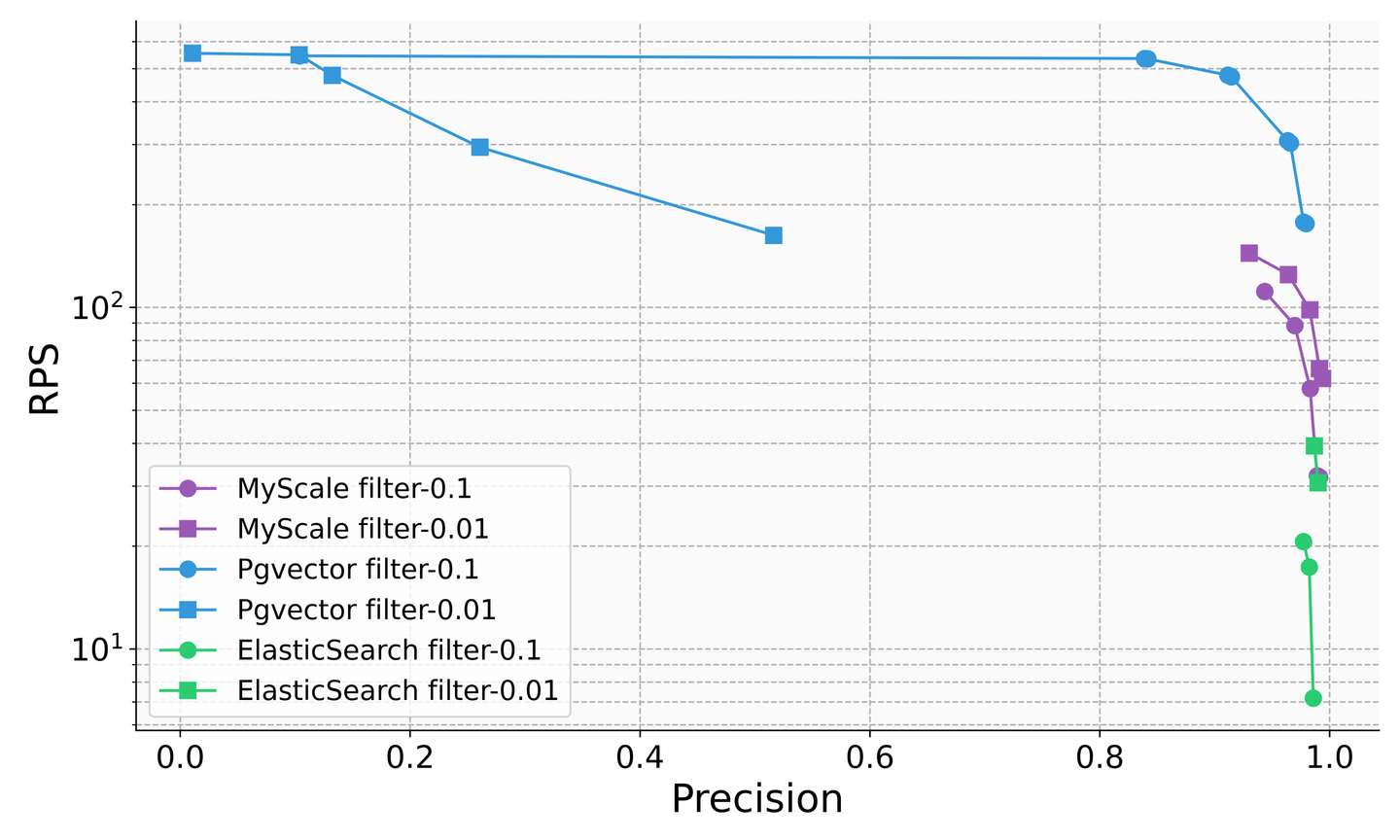
尽管传统数据库产品已经意识到在LLM时代中向量查询的重要性,并开始添加向量功能,但它们的组合查询的准确性仍然存在显著问题。例如,在过滤搜索场景中,Elasticsearch的每秒查询率(QPS)在过滤比例为0.1时下降到约5,而带有pgvector插件的PostgreSQL在过滤比例为0.01时的准确性仅约为50%。这表明了不稳定的查询准确性和性能,极大地限制了它们的使用。相比之下,SQL向量数据库MyScale在各种过滤比例场景下实现了超过100 QPS和98%的准确性,成本仅为pgvector的36%和Elasticsearch的12%。

# LLM + 大数据:构建下一代智能平台
机器学习和大数据推动了Web和移动应用的成功。但随着LLM的崛起,我们正在转变思路,构建一种新型的LLM + 大数据解决方案。借助我们的高性能SQL向量数据库MyScaleDB,这些解决方案可以解锁大规模数据处理、知识检索、可观察性、数据分析、少样本学习等关键能力。基于MyScaleDB,数据和人工智能之间形成了一个闭环,为我们的下一代LLM + 大数据智能平台奠定了基础。这种范式转变已经在科学研究、金融、工业和医疗等领域正在进行中。
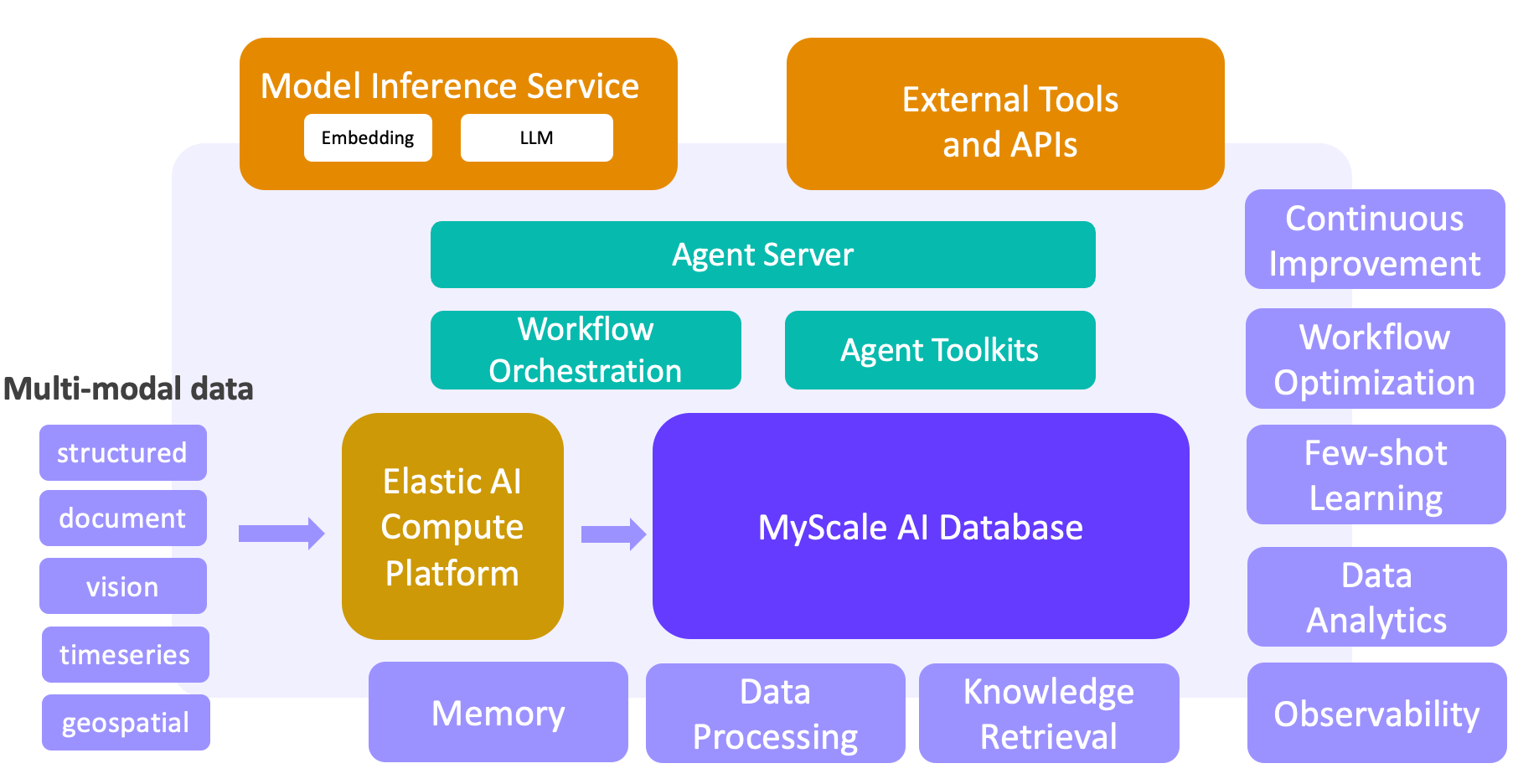
随着技术的快速发展,预计在未来五到十年内将出现某种形式的人工通用智能(AGI)。对于这个问题,我们必须问:我们需要一个静态的虚拟模型,还是另一种更全面的解决方案?数据无疑是连接LLM、用户和世界的重要纽带。我们的愿景是将LLM和大数据有机地整合在一起,创建一个更专业、实时和协作的人工智能系统,同时充满人情味和价值。
欢迎您在GitHub (opens new window)上探索开源的MyScaleDB存储库,并利用SQL和向量构建创新的生产级AI应用。



