
大型语言模型(LLM)是先进的人工智能系统,可以回答各种问题。尽管它们在已知的主题上提供了有用的回答,但在陌生的主题上并不总是准确。这种现象被称为幻觉。
![]()
# 什么是幻觉?
在我们看一个LLM幻觉的例子之前,让我们先考虑一下维基百科对“幻觉”的定义:
“幻觉是在没有外部刺激的情况下产生的具有真实感的感知。”
此外:
“幻觉是生动的、实质性的,并被认为位于外部客观空间中。”
换句话说,幻觉是对某个真实或具体事物的错误(或虚假)感知。例如,ChatGPT(OpenAI的一种著名大型语言模型)被问到LLM幻觉是什么,它的回答是:

因此,问题是,我们如何改进(或修复)这个结果?简明的答案是在问题中添加事实,例如在提问之前或之后提供LLM的定义。
例如:
LLM是大型语言模型(Large Language Model),一种模拟人类口语和书写方式的人工神经网络。请告诉我,LLM幻觉是什么?
ChatGPT对这个问题的公共领域回答是:

注意:
第一句话“对我之前回答中的混淆表示抱歉”的原因是我们在给ChatGPT提问“LLM幻觉是什么”之前,给它了第二个提示:“LLM是…”。
这些补充提高了答案的质量。至少它不再认为LLM幻觉是“晚期生活偏头痛的伴随症状”!😆
# 外部知识减少幻觉
在这个关键时刻,非常重要的一点是,LLM并不是无所不能、无所不知的终极权威。LLM是在大量数据上进行训练的,它学习语言中的模式,但它可能并不总是能够获得最新的信息或对复杂主题有全面的理解。
那么现在怎么办?如何增加减少LLM幻觉的机会?
解决这个问题的方法是在查询(或提示)中包含支持文档,以引导LLM获得更准确和明智的回答。就像人类一样,它需要从这些文档中学习,以准确正确地回答您的问题。
有许多来源可以提供有用的文档,包括Google或Bing等搜索引擎以及Arxiv等数字图书馆,它们提供了一个搜索相关段落的接口。使用数据库也是一个不错的选择,提供了更灵活和私密的查询接口。
从来源中检索到的知识必须与问题/提示相关。有几种检索相关文档的方法,包括:
- **基于关键词:**在纯文本中搜索关键词,适用于对术语进行精确匹配。
- **基于向量搜索:**搜索更接近嵌入的记录,有助于搜索适当的释义或常规文档。
如今,向量搜索非常流行,因为它可以解决释义问题并计算段落的含义。向量搜索不是一种一刀切的解决方案;它应该与特定的过滤器配对使用,以保持其性能,特别是在搜索大量记录时。例如,如果您只想检索与物理学(作为一个学科)相关的知识,您必须过滤掉所有关于其他学科的信息。这样,LLM就不会被来自其他学科的知识所困惑。
# 使用SQL自动化整个过程...和向量搜索
在回答问题之前,LLM还应该学会从数据源中查询数据,自动化整个过程。实际上,LLM已经能够编写SQL查询并遵循指令。
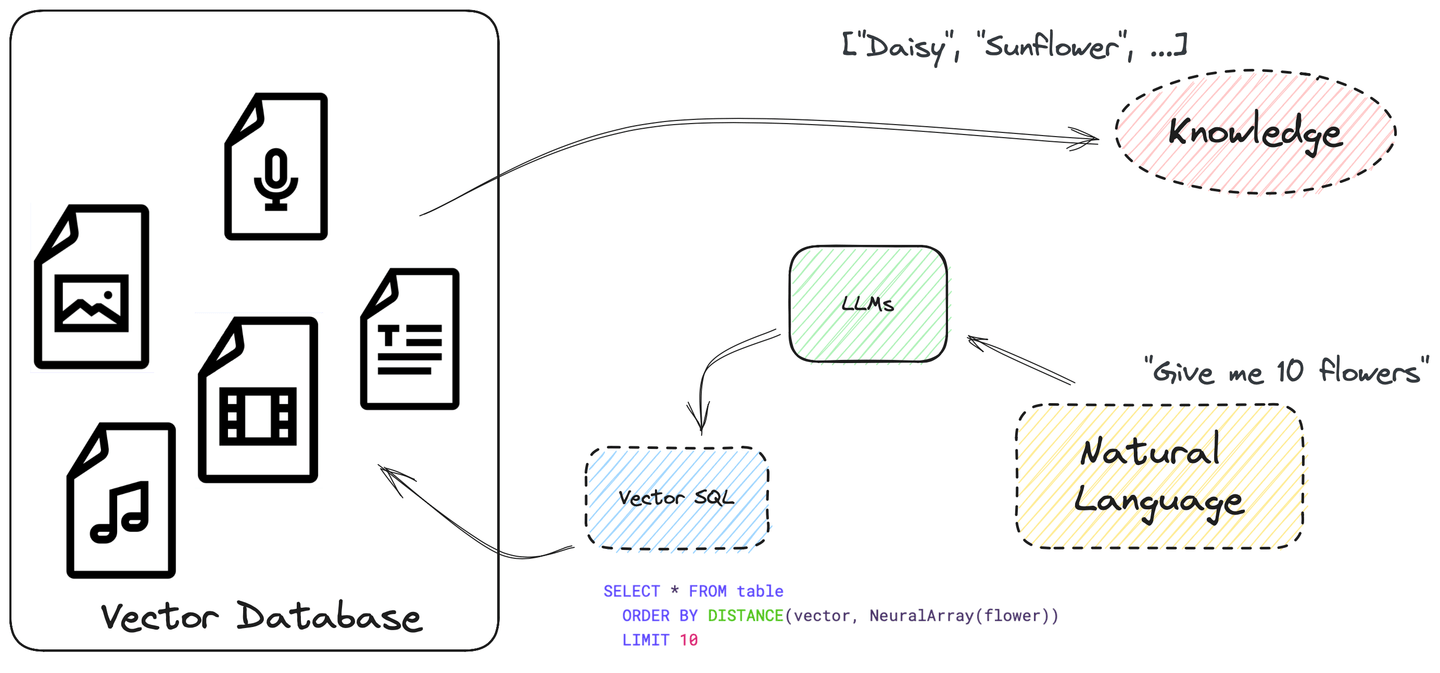
SQL功能强大,可以用于构建复杂的搜索查询。它支持许多不同的数据类型和函数。它允许我们使用ORDER BY和LIMIT编写向量搜索的SQL查询,将嵌入之间的相似度分数视为列distance。非常简单明了,不是吗?
有关如何构建向量SQL查询的更多信息,请参见下一节向量SQL的样子。
使用向量SQL构建复杂的搜索查询有很多好处,包括:
- 增加了对数据类型和函数的灵活性支持
- 提高了效率,因为SQL在数据库内部高度优化和执行
- 人类可读且易于学习,因为它是标准SQL的扩展
- 对LLM友好
注意:
互联网上有很多SQL示例和教程。LLM熟悉标准SQL以及一些方言。
除了MyScale之外,许多SQL数据库解决方案(如Clickhouse和PostgreSQL)正在将向量搜索添加到其现有功能中,允许用户使用向量SQL和LLM回答关于复杂主题的问题。同样,越来越多的应用程序开发人员开始将向量搜索与SQL集成到他们的应用程序中。
# 向量SQL的样子
向量结构化查询语言(Vector SQL)旨在教会LLM如何查询向量SQL数据库,并包含以下额外函数:
DISTANCE(column, query_vector): 此函数比较列向量和查询向量之间的距离,可以是精确匹配或近似匹配。NeuralArray(entity): 此函数将实体(例如图像或文本片段)转换为嵌入。
使用这两个函数,我们可以扩展标准SQL以进行向量搜索。例如,如果您想搜索与词flower相关的10个相关记录,可以使用以下SQL语句:
SELECT * FROM table
ORDER BY DISTANCE(vector, NeuralArray(flower))
LIMIT 10
DISTANCE函数由以下内容组成:
- 内部函数
NeuralArray(flower)将词flower转换为嵌入。 - 然后将此嵌入序列化并注入
DISTANCE函数中。
向量SQL是SQL的扩展版本,需要根据所使用的向量数据库进行进一步的转换。例如,许多实现对DISTANCE函数有不同的名称。在MyScale中称为distance,在Clickhouse中称为L2Distance或CosineDistance。此外,根据数据库的不同,此函数名称将有不同的翻译。
# 如何教LLM编写向量SQL
现在我们了解了向量SQL的基本原理和其独特的函数,让我们使用LLM来帮助我们编写向量SQL查询。
# 1. 教LLM标准的向量SQL是什么
首先,我们需要教LLM标准的向量SQL是什么。我们的目标是确保LLM在编写向量SQL查询时能够自动执行以下三个操作:
- 从我们的问题/提示中提取关键词。它可以是一个对象、一个概念或一个主题。
- 决定使用哪个列执行相似性搜索。它应该始终选择一个用于相似性的向量列。
- 将我们问题的其余约束条件转换为有效的SQL。
# 2. 设计LLM提示
确定LLM构建向量SQL查询所需的确切信息后,我们可以设计提示,如下所示:
# 这是一个向量SQL提示的示例
_prompt = f"""您是一个MyScale专家。给定一个输入问题,首先创建一个语法正确的MyScale查询来运行,然后查看查询的结果并返回输入问题的答案。
MyScale查询具有一个名为`DISTANCE(column, array)`的向量距离函数,用于计算与用户问题的相关性,并通过该相关性对特征数组列进行排序。
当查询要求获取{top_k}个最接近的行时,您必须使用此距离函数计算到实体的数组在向量列上的距离,并按照距离排序以检索相关行。
*注意*:`DISTANCE(column, array)`只接受数组列作为其第一个参数,并接受一个`NeuralArray(entity)`作为其第二个参数。您还需要一个名为`NeuralArray(entity)`的用户定义函数来检索实体的数组。
除非用户在问题中指定了要获取的示例数量,否则使用LIMIT子句查询最多{top_k}个结果,正如MyScale所要求的那样。您只能按照距离函数的顺序排序。
永远不要查询表中的所有列。您必须只查询需要回答问题的列。将每个列名用双引号(")括起来,以将其标识为定界符。
注意只使用您在下面的表中看到的列名。注意不要查询不存在的列。还要注意哪个列在哪个表中。
如果问题涉及“今天”,请注意使用today()函数获取当前日期。`ORDER BY`子句应始终位于`WHERE`子句之后。不要在SQL的末尾添加分号。注意表模式中的注释。
使用以下格式:
======== 表信息 ========
<一些表信息>
问题:“问题在这里”
SQL查询:“要运行的SQL查询”
让我们开始:
======== 表信息 ========
{table_info}
问题:{input}
SQL查询:
这个提示应该能够完成其工作。但是,您添加的示例越多,构建正确的向量SQL查询的LLM过程就会越好,就像使用以下向量SQL到文本对作为提示:
SQL表创建语句:
------ 表模式 ------
CREATE TABLE "ChatPaper" (
abstract String,
id String,
vector Array(Float32),
categories Array(String),
pubdate DateTime,
title String,
authors Array(String),
primary_category String
) ENGINE = ReplicatedReplacingMergeTree()
ORDER BY id
PRIMARY KEY id
问题和答案:
问题:什么是PaperRank?这些作品的贡献是什么?使用具有超过2个类别的论文。
SQL查询:SELECT ChatPaper.title, ChatPaper.id, ChatPaper.authors FROM ChatPaper WHERE length(categories) > 2 ORDER BY DISTANCE(vector, NeuralArray(PaperRank contribution)) LIMIT {top_k}
您添加的相关示例越多,LLM构建正确的向量SQL查询的能力就越好。
最后,以下是一些设计提示时的额外提示:
- 覆盖可能出现在任何问题中的所有可能函数。
- 避免单调的问题。
- 修改表模式,例如添加/删除/修改名称和数据类型。
- 对齐提示的格式。

# 一个真实世界的例子:使用MyScale
让我们现在构建一个真实世界的例子 (opens new window),按照以下步骤进行:

# 准备数据库
我们已经为您准备了一个游乐场,其中有超过200万篇论文可以查询。您可以通过将以下Python代码添加到您的应用程序中来访问这些数据。
from sqlalchemy import create_engine
MYSCALE_HOST = "msc-950b9f1f.us-east-1.aws.myscale.com"
MYSCALE_PORT = 443
MYSCALE_USER = "chatdata"
MYSCALE_PASSWORD = "myscale_rocks"
engine = create_engine(f'clickhouse://{MYSCALE_USER}:{MYSCALE_PASSWORD}@{MYSCALE_HOST}:{MYSCALE_PORT}/default?protocol=https')
如果您愿意,您可以跳过接下来的步骤,其中我们使用MyScale控制台创建表并插入数据,并跳到我们使用向量SQL和创建SQLDatabaseChain来查询数据库的部分。
创建数据库表:
CREATE TABLE default.ChatArXiv (
`abstract` String,
`id` String,
`vector` Array(Float32),
`metadata` Object('JSON'),
`pubdate` DateTime,
`title` String,
`categories` Array(String),
`authors` Array(String),
`comment` String,
`primary_category` String,
CONSTRAINT vec_len CHECK length(vector) = 768)
ENGINE = ReplacingMergeTree ORDER BY id SETTINGS index_granularity = 8192
插入数据:
INSERT INTO ChatArXiv
SELECT
abstract, id, vector, metadata,
parseDateTimeBestEffort(JSONExtractString(toJSONString(metadata), 'pubdate')) AS pubdate,
JSONExtractString(toJSONString(metadata), 'title') AS title,
arrayMap(x->trim(BOTH '"' FROM x), JSONExtractArrayRaw(toJSONString(metadata), 'categories')) AS categories,
arrayMap(x->trim(BOTH '"' FROM x), JSONExtractArrayRaw(toJSONString(metadata), 'authors')) AS authors,
JSONExtractString(toJSONString(metadata), 'comment') AS comment,
JSONExtractString(toJSONString(metadata), 'primary_category') AS primary_category
FROM
s3(
'https://myscale-demo.s3.ap-southeast-1.amazonaws.com/chat_arxiv/data.part*.zst',
'JSONEachRow',
'abstract String, id String, vector Array(Float32), metadata Object(''JSON'')',
'zstd'
);
ALTER TABLE ChatArXiv ADD VECTOR INDEX vec_idx vector TYPE MSTG('metric_type=Cosine');
# 创建VectorSQLDatabaseChain
您将需要LangChain实验性包来使用VectorSQLDatabaseChain。您可以通过执行以下安装脚本来安装它:
python3 -m venv .venv
source .venv/bin/activate
pip3 install langchain langchain-experimental --upgrade
安装了此功能后,下一步是使用它来查询数据库,如下所示的Python代码:
from sqlalchemy import create_engine
MYSCALE_HOST = "msc-950b9f1f.us-east-1.aws.myscale.com"
MYSCALE_PORT = 443
MYSCALE_USER = "chatdata"
MYSCALE_PASSWORD = "myscale_rocks"
# 创建与数据库的连接
engine = create_engine(f'clickhouse://{MYSCALE_USER}:{MYSCALE_PASSWORD}@{MYSCALE_HOST}:{MYSCALE_PORT}/default?protocol=https')
from langchain.embeddings import HuggingFaceInstructEmbeddings
from langchain.callbacks import StdOutCallbackHandler
from langchain.llms import OpenAI
from langchain.utilities.sql_database import SQLDatabase
from langchain_experimental.sql.prompt import MYSCALE_PROMPT
from langchain_experimental.sql.vector_sql import VectorSQLDatabaseChain
from langchain_experimental.sql.vector_sql import VectorSQLRetrieveAllOutputParser
# 此解析器将`NeuralArray()`转换为嵌入
output_parser = VectorSQLRetrieveAllOutputParser(
model=HuggingFaceInstructEmbeddings(model_name='hkunlp/instructor-xl')
)
# 使用上述提示
PROMPT = PromptTemplate(
input_variables=["input", "table_info", "top_k"],
template=_prompt,
)
# 将元数据绑定到SqlAlchemy引擎
metadata = MetaData(bind=engine)
# 创建SQLDatabaseChain
query_chain = VectorSQLDatabaseChain.from_llm(
# GPT-3.5生成更好的有效SQL
llm=OpenAI(openai_api_key=OPENAI_API_KEY, temperature=0),
# 使用预定义的提示,根据需要更改
prompt=PROMPT,
# 返回前10个相关文档
top_k=10,
# 直接使用数据库中的结果
return_direct=True,
# 使用我们的数据库进行检索
db=SQLDatabase(engine, None, metadata),
# 将`NeuralArray()`转换为嵌入
sql_cmd_parser=output_parser)
# 启动链!并将所有链调用跟踪到标准输出
query_chain.run("介绍一些在2019年左右发表的使用生成对抗网络的论文。",
callbacks=[StdOutCallbackHandler()])
# 使用 RetrievalQAwithSourcesChain 进行提问
您还可以将这个VectorSQLDatabaseChain作为检索器使用。您可以将其插入到一些检索QA链中,就像LangChain中的其他检索器一样。
from langchain_experimental.retrievers.vector_sql_database \
import VectorSQLDatabaseChainRetriever
from langchain.chains.qa_with_sources.map_reduce_prompt import combine_prompt_template
OPENAI_API_KEY = "sk-***"
# 定义如何序列化来自数据库的结构化数据
document_with_metadata_prompt = PromptTemplate(
input_variables=["page_content", "id", "title", "authors", "pubdate", "categories"],
template="内容:\n\t标题:{title}\n\t摘要:{page_content}\n\t" +
"作者:{authors}\n\t出版日期:{pubdate}\n\t类别:{categories}\n来源:{id}"
)
# 定义您用于询问LLM的提示
COMBINE_PROMPT = PromptTemplate(
template=combine_prompt_template, input_variables=["summaries", "question"])
# 使用SQLDatabaseChain创建一个检索器
retriever = VectorSQLDatabaseChainRetriever(
sql_db_chain=query_chain, page_content_key="abstract")
# 最后,使用检索器创建一个问答链
ask_chain = RetrievalQAWithSourcesChain.from_chain_type(
ChatOpenAI(model_name='gpt-3.5-turbo-16k',
openai_api_key=OPENAI_API_KEY, temperature=0.6),
retriever=retriever,
chain_type='stuff',
chain_type_kwargs={
'prompt': COMBINE_PROMPT,
'document_prompt': document_with_metadata_prompt,
}, return_source_documents=True)
# 运行链!并从LLM获取结果
ask_chain("介绍一些在2019年左右发表的使用生成对抗网络的论文。",
callbacks=[StdOutCallbackHandler()])
我们还在huggingface (opens new window)上提供了一个实时演示,代码在GitHub (opens new window)上可用!我们使用了自定义的检索QA链 (opens new window)来最大化我们的搜索和提问管道在LangChain中的性能!
# 总结
在现实中,大多数LLM都会产生幻觉。减少其出现的最实际的方法是在问题中添加额外的事实(外部知识)。外部知识对于提高LLM系统的性能至关重要,可以实现高效准确地检索答案。每个词都很重要,您不希望浪费金钱来检索通过不准确的查询获得的未使用的信息。
如何做到?
这就是向量SQL的用武之地,它允许您执行精细粒度的向量搜索,以定位和检索所需的信息。
向量SQL功能强大且易于人和机器学习。您可以使用许多数据类型和函数创建复杂的查询。LLM也喜欢向量SQL,因为它的训练数据集包含许多参考资料。
最后,可以根据不同的嵌入模型将向量SQL转换为许多向量数据库。我们相信这是向量数据库的未来。
对我们正在做的事情感兴趣吗?立即加入我们的discord (opens new window)!



