
正如我们之前的一篇博文 (opens new window)所探讨的,向量搜索通过将文本转换为数值向量,突破了传统关键词匹配的局限,为信息检索带来了革命性的进展。这种方法能够捕捉文本的上下文信息,从而提高搜索结果的相关性。然而,向量搜索并非完美无缺。从文本到向量的转换过程不可避免地会导致信息丢失,进而影响搜索的准确性。
为了解决这一问题,我们可以采用两阶段检索系统来优化向量搜索的效果。该系统的第一阶段利用向量索引快速检索候选结果,第二阶段则对候选结果进行更精细化的重排序,从而提高最终结果的质量。
本文将以 MyScale 向量数据库为例,详细介绍如何利用重排序功能实现高效的两阶段检索系统,并结合代码示例演示如何将向量搜索与重排序技术相结合,构建兼具效率和准确性的信息检索系统。
# 什么是重排序
在深入探讨 MyScale 的两阶段检索之前,让我们首先明确 重排序(reranking) 的概念及其在信息检索中的重要性。
简而言之,重排序旨在优化向量搜索返回的结果顺序,以提升最终结果与用户搜索意图的相关性。根据维基词典 (opens new window)的定义,重排序指的是“对某物重新进行排名或以不同的方式进行排名……例如,算法在达到最佳结果之前执行多次重排序。”
重排序通常借助交叉编码器模型 (opens new window)来实现。与将文档和查询分别转换为向量进行匹配的初始向量搜索不同,交叉编码器模型会同时处理查询和文档,并根据两者的语义相关性对搜索结果进行精确的重新排序,从而提供更符合用户需求的结果。
然而,重排序并非没有缺点。其最大的挑战在于计算复杂度高,尤其是在处理海量数据集时,这严重限制了其单独应用的可行性。
# 两阶段检索系统
为了克服单独使用重排序带来的计算成本高昂的挑战,两阶段检索系统应运而生。该系统结合了向量搜索和重排序的优势,在保证效率的同时显著提升了搜索结果的准确性。
# MyScale的两阶段检索系统
MyScale 的两阶段检索系统遵循以下流程:
- 向量搜索: 系统首先利用高效的向量索引技术在数据库中执行向量搜索,快速检索与用户查询语义相似的文档。这一阶段的目标是从海量数据中筛选出一个相对较小的、与查询相关的候选文档集合。
- 重排序: 在获取候选文档集合后,系统会利用重排序函数对结果进行精细化的重新排序。重排序函数会同时考虑查询和文档的语义信息,并根据相关性评分对候选文档进行排序,确保最终返回的结果与用户搜索意图高度一致。
为了简化这个两阶段检索系统,我们已经将这些重新排序函数 (opens new window)与MyScale 集成在一起,通过简单的 SQL 查询即可访问。
注意:
MyScale 的重排序函数是对复杂底层 API 的封装,在保证功能强大的同时,为用户提供了简洁易用的界面。用户可以通过简单的 SQL 查询语句,完成原本需要大量代码才能实现的复杂排序操作,极大地提升了搜索效率和用户体验。
如下图所示,用户可以使用简单的命令启动这个两阶段检索机制,只需将向量搜索子查询与重排序查询语句结合起来,即可轻松获取最终排序结果。系统支持返回指定数量的 Top-N 文档,并可根据用户需求提取相关性最高的 K 个文档。
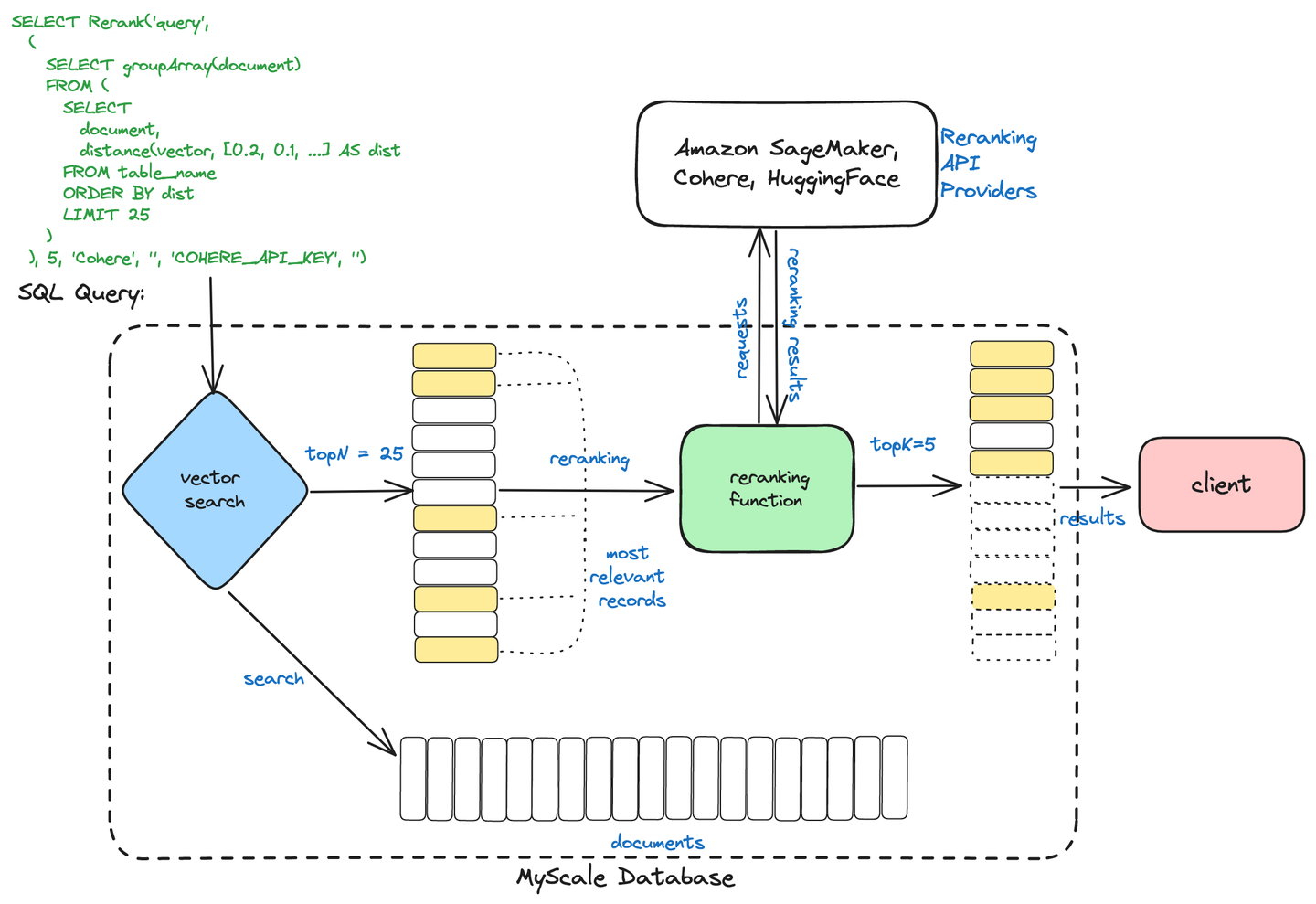
为了评估两阶段检索系统的有效性,我们使用 OpenAI Embeddings (opens new window) 对其进行了性能测试,并参考 LlamaIndex 在其博客文章中介绍的方法进行评估。结果表明,与单独使用向量搜索相比,两阶段检索系统的搜索准确性得到了显著提升。
具体来说,使用 "bge-reranker-base" 模型进行重排序后,系统的命中率(Hit Rate)从 0.854545 提升至 0.895455,平均倒数排名(MRR)也从 0.640303 提升至 0.707652。这些指标的提升充分证明了重排序在提高搜索结果相关性方面的有效性,也凸显了将重排序整合到信息检索过程中的巨大价值。
注意:
我们在这个notebook (opens new window)中详细介绍了我们的评估方法和结果,遵循了LlamaIndex在这篇博文 (opens new window)中讨论的方法。
# MyScale 两阶段检索:实战演练
为了帮助大家更好地理解 MyScale 两阶段检索系统的实际应用,我们将以一个改进的抽象问答系统 (opens new window)为例进行说明。可以参考 MyScale 文档获取更详细的信息。
注意:
我们仅对原始示例中的查询阶段 (opens new window)进行了修改,使用的表和数据保持不变。
原始的抽象问答系统使用独立的检索器将问题转换为嵌入向量,然后执行搜索查询以找到最相关的 K 个候选答案。现在,借助 MyScale 的内置函数,我们可以将这些步骤整合到一个 SQL 查询语句中,如下所示:
SELECT summary,
distance(
summary_feature,
CohereEmbedText('what is the difference between bitcoin and traditional money?')
) AS dist
FROM default.myscale_llm_bitcoin_qa
WHERE article_rank < 500
ORDER BY dist LIMIT 10
这段 SQL 查询语句使用了自定义的嵌入函数——CohereEmbedText,该函数基于Cohere的embed-english-light-v3.0模型 (opens new window)进行定义,代码片段如下所示。
CREATE FUNCTION CohereEmbedText ON CLUSTER '{cluster}'
AS (x) -> EmbedText(
x,
'Cohere',
'',
'YOUR_COHERE_API_KEY',
'{"model":"embed-english-light-v3.0", "input_type":"search_query"}')
为了进一步简化流程,我们引入了另一个自定义函数 CohereRerank (opens new window) 用于执行重排序操作:
CREATE FUNCTION CohereRerank ON CLUSTER '{cluster}'
AS (x,y,z) -> Rerank(
x, y, z, 'Cohere', '', 'YOUR_COHERE_API_KEY', '');
利用上述函数,我们可以使用以下 SQL 语句实现两阶段检索系统:
SELECT
tupleElement(arrayElement, 2) AS summary,
tupleElement(arrayElement, 3) AS score
FROM (
SELECT arrayJoin(CohereRerank('what is the difference between bitcoin and traditional money?',
(SELECT groupArray(summary)
FROM (
SELECT summary, distance(summary_feature, CohereEmbedText('what is the difference between bitcoin and traditional money?')) as dist
FROM default.myscale_llm_bitcoin_qa
WHERE article_rank < 500
ORDER BY dist
LIMIT 50
)
), 10
)) AS arrayElement
)
这个SQL语句包括以下步骤来实现我们的两阶段检索系统:
- 向量搜索: 系统首先使用 CohereEmbedText 函数计算查询的嵌入向量,然后利用向量索引技术在 default.myscale_llm_bitcoin_qa 表中检索与查询语义相似的 Top-50 个候选答案。
- 结果集分组: 系统使用 groupArray (opens new window) 函数将 50 个候选答案的摘要信息分组到一个数组中,为后续的重排序操作做准备。
- 重排序: 系统调用
CohereRerank函数对候选答案进行重排序,并返回相关性最高的 10 个答案。 - 结果格式化: 系统使用 arrayJoin (opens new window)(用于将结果集展开为多行)和 tupleElement (opens new window)(用于从结果行中提取指定的列)函数对最终结果进行格式化,方便用户查看。

# 结论
MyScale 的两阶段检索系统充分展现了现代搜索技术在追求简单高效方面的卓越成果。即使是将向量搜索与先进的重排序功能相结合这样复杂的操作,MyScale 也能将其无缝地融入到一个简洁的 SQL 查询语句中。
这种设计理念不仅让更广泛的用户能够轻松使用强大的检索功能,也体现了 MyScale 致力于为用户提供强大且易用的数据搜索和分析工具的承诺。 MyScale 两阶段检索系统为构建高效、精准的信息检索系统提供了全新的思路,并为未来搜索技术的发展指明了方向。




