
虽然文本搜索非常常见,但在某些情况下,我们需要使用图片作为搜索查询来搜索图片 (opens new window)——比如寻找相似的照片或通过图片识别产品。这种方法被称为基于图片的搜索 (opens new window)或反向图片搜索,应用广泛——在线购物时,你可以拍下喜欢的商品找到购买渠道,或者识别未知的植物或地标等等。随着我们视觉数据的增长,这一领域变得越来越重要。
显然,这很有挑战性,因为我们没有直接的文本查询可以匹配。相反,我们需要一种方法将图片表示为可有效比较的形式。这时,embedding(嵌入) (opens new window)技术派上了用场。通过将图片转换为高维空间中的数值向量,嵌入技术可以根据图片的特征来衡量它们之间的相似性。
# 经典方法
在深度学习时代,实际上在广泛采用深度学习技术之前,寻找搜索引擎中相似图像特征的概念就已经存在了。早在2009年,Google Images就引入了类似图像功能 (opens new window),随后引入了基于内容的图像检索(CBIR)系统。这引发了一个自然的问题:在没有依赖于最先进的深度学习模型的情况下,是什么方法使得这些图像搜索成为可能?
# SIFT
尺度不变特征变换(Scale-Invariant Feature Transform,SIFT) 曾经是在深度学习架构出现之前一种高效且常用的算法。SIFT识别图像中的关键点,这些关键点对于缩放、旋转甚至一定程度的仿射变形和光照变化是不变的。在检测到这些关键点之后,SIFT通过分析每个点周围的局部梯度信息来计算特征描述符。这些描述符通常是 128维向量,可以有效地捕捉图像的局部结构。它们可以用作各种应用中的嵌入,包括图像匹配和检索。
SIFT也不乏批评。它对于较小的图像效率较低,使用了大量的内存(想象一下数千个关键点的128维向量),并且对光照敏感。此外,它最近在2020年才获得专利,因此与其他方法相比,它在社区中并不那么流行。
# SURF
为了解决SIFT的一些计算复杂性批评,加速稳健特征(Speeded-Up Robust Features,SURF) 作为一种更快的替代方法被引入。SURF为了提高计算速度,牺牲了一定的性能准确性。SIFT依赖于一阶图像导数(梯度)进行特征检测和描述,而SURF使用二阶导数(Hessian矩阵)的近似值进行更快的计算。SURF生成的特征描述符通常是64维向量,或者对于扩展版本是128维,使其适用于图像检索任务中的嵌入表示。
除了这些方法,还有其他方法,如方向梯度直方图(Histogram of Oriented Gradients,HOG)、**方向快速和旋转BRIEF(Oriented FAST and Rotated BRIEF,ORB)**等。
# 实现
使用OpenCV (opens new window)包可以很容易地实现SIFT和SURF。OpenCV(从4.4.0开始)有一个现成的SIFT_create()函数来初始化SIFT对象。然后可以进一步使用这些对象来检测和计算关键点以及它们的描述符(嵌入向量)。
import cv
image = cv2.imread('AdventureKKH/15.jpg')
grayScaleImage = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
sift = cv2.SIFT_create()
keypoints, descriptors = sift.detectAndCompute(grayScaleImage, None)
一张图像可能有很多关键点。找到之后,我们可以简单地将它们绘制出来。
import matplotlib.pyplot as plt
image_with_keypoints = cv2.drawKeypoints(image, keypoints, None)
plt.imshow(cv2.cvtColor(image_with_keypoints, cv2.COLOR_BGR2RGB))
plt.axis('off')
plt.show()

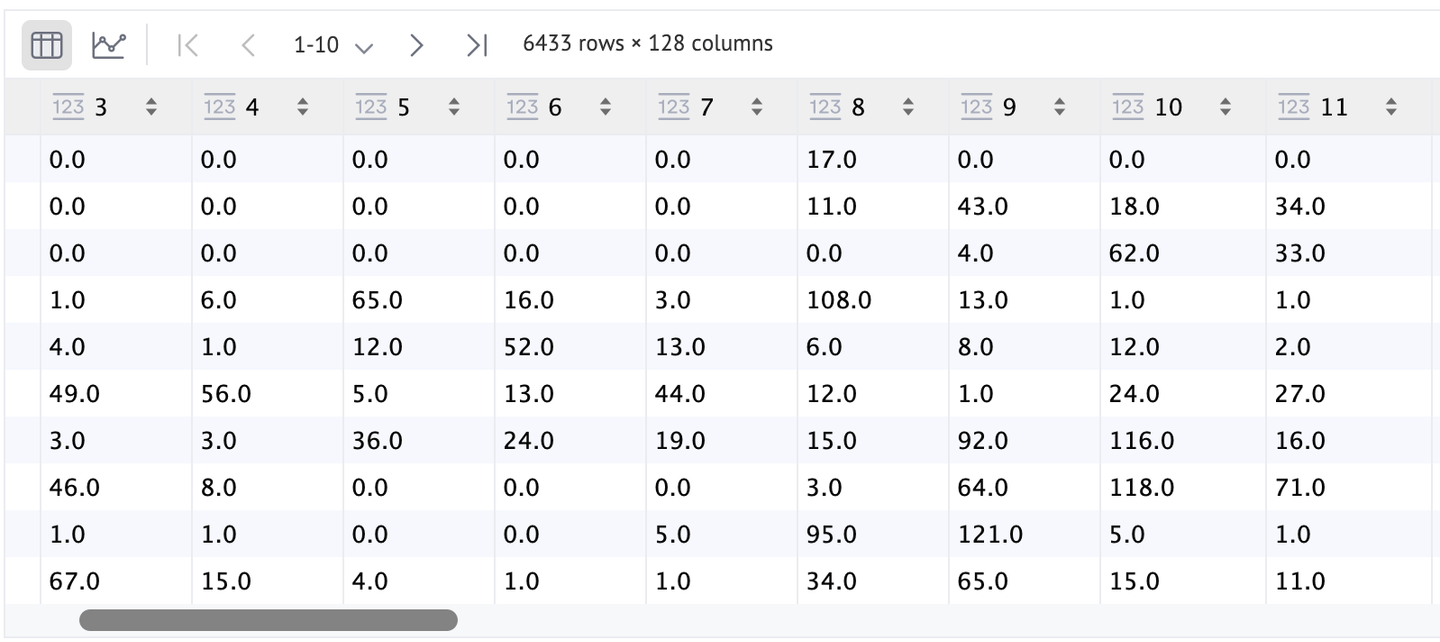
如您所见,这些关键点数量很多(准确地说是6433个),但由于与图像的低对比度,大多数关键点无法识别。作为更好的替代方案,我们可以设置flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS以以稍微更好的方式可视化它们。

特征(descriptors)也可以使用DataFrame更好地可视化。如您所见,我们为每个SIFT点(keypoints)都有一行,每个点的特征是128维的。
由于SURF是一种专利算法,因此不允许直接从OpenCV中使用。现在,让我们专注于更常见的深度架构模型。
# 基于深度架构的嵌入
基于SIFT和SURF等传统方法,这些方法侧重于从图像中提取局部特征,而深度学习模型则提供了一种更强大的图像表示方法。这些模型可以直接从数据中学习分层特征 (opens new window),捕捉手工设计算法难以识别的复杂模式和结构。这种进步使得更强大和有区分度的嵌入成为可能,增强了图像搜索和检索等任务。
有几个现成的(预训练)模型可供使用,例如**VGG (opens new window)、ResNets (opens new window)、Inception (opens new window)、MobileNet (opens new window)**等。这些卷积神经网络(CNN)在像ImageNet这样的大型数据集上进行了训练,使它们能够从图像中提取丰富多样的特征。与传统算法不同,深度学习模型可以捕捉到低级特征(如边缘和纹理)和高级概念(如对象和场景)。
使用这些模型计算嵌入相对简单。我们使用一个预训练模型,而不是使用最后的分类层的输出,并提取一个较早的层的输出,通常是分类层 (opens new window)之前的层。这个输出是一个高维特征向量,作为嵌入,有效地将图像以适合相似性比较的数值形式表示出来。
例如,让我们使用ResNet-50,这是一个以其残差连接而闻名的流行深度学习模型,有助于有效训练更深的网络。通过移除最后一层,我们可以为给定的image获取嵌入:
import torch
import torchvision.models as models
model = models.resnet50(pretrained=True)
model = torch.nn.Sequential(*(list(model.children())[:-1]))
with torch.no_grad():
embedding = model(image.unsqueeze(0))
# 基于ViT的嵌入
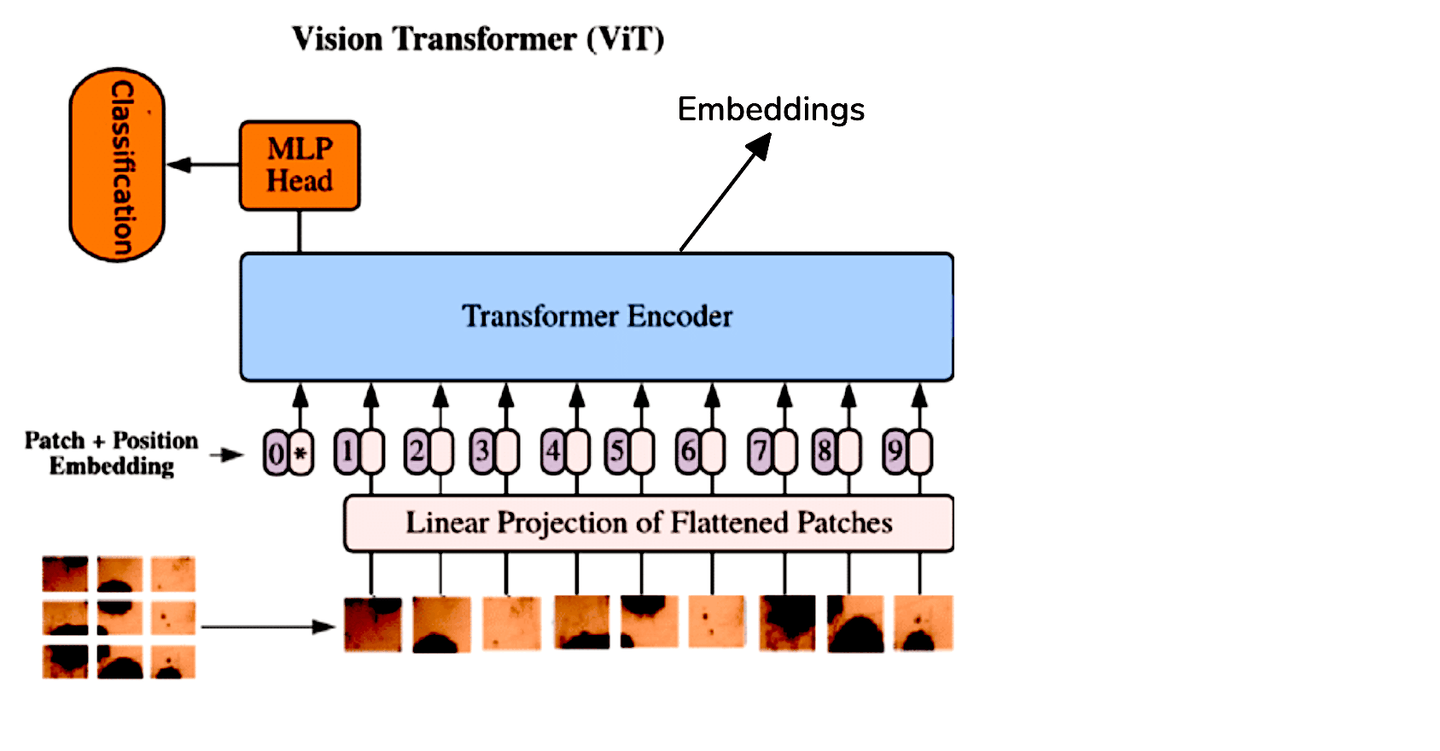
虽然CNN一直是图像处理任务的标准,但**Vision Transformers(ViT)**通过将Transformer架构应用于图像数据提供了一种不同的方法。ViT将图像视为一系列补丁(patches),并以与Transformer处理自然语言处理中的序列类似的方式处理它。这种方法使得模型能够更有效地捕捉图像内部的全局关系。
由于ViT和CNN之间的架构差异,我们通过对Transformer编码器的输出标记进行平均来提取ViT的嵌入。为了方便起见,我们可以使用Hugging Face提供的预训练ViT模型:
from transformers import ViTModel, ViTFeatureExtractor
import torch
model = ViTModel.from_pretrained('google/vit-base-patch16-224-in21k')
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224-in21k')
image = Image.open('AdventureKKH/15.jpg')
inputs = feature_extractor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
embedding = outputs.last_hidden_state.mean(dim=1)
print(embedding)
由于我们使用的是默认的ViT架构(原始论文中使用的架构[1]),嵌入向量将具有768维,如此处所示。如果您想要更好的分辨率,可以切换到ViT-Large或ViT-Huge(分别为1024和1280长度)。

# 微调
在处理需要模型微调的专门图像类型时,无论是使用卷积神经网络(CNN)还是Vision Transformer(ViT),通常最好冻结除模型的最后一层之外的所有层。这种方法允许仅微调最后一层,而不改变前面层的学习特征。
完成微调过程后,可以像之前的步骤一样删除最后一层。使用修改后的模型,然后可以通过前向传递将图像传递以生成所需的嵌入。这种方法确保模型保留其基本理解,同时适应特定图像数据的细微差别。
# 自监督方法
只需检查您自己的图片文件夹并开始注释它。您很快就会在50或100张图片后感到疲倦。微调需要大量标记数据,可惜这些数据既不容易获得,也不值得花时间。因此,更好的解决方案是使用自监督学习。有许多自监督学习方法可供选择,例如:
SimCLR和MoCo都会生成输入图像及其嵌入的两个副本。然后,基础架构(通常是ResNet)被训练以确保最小化对比损失。
另一方面,CLIP使用图像和其文本描述的嵌入分别训练模型。自那以后,这种方法变得很有名。例如,BEiT(BErt pre-training of image Transformers)、VisualBERT和ViLBERT等。
注意:要了解有关CLIP的更多信息,您可以阅读我们的博客使用CLIP进行零样本分类 (opens new window)。
在这里,我们将使用Moco(v2)来计算图像嵌入。
import torch
import torch.nn as nn
from torchvision import models
class MoCoResNet(nn.Module):
def __init__(self, base_encoder=models.resnet50, feature_dim=128):
super(MoCoResNet, self).__init__()
self.encoder_q = base_encoder(pretrained=False)
self.encoder_q.fc = nn.Identity() # Removing final layer
def forward(self, x):
return self.encoder_q(x)
model = MoCoResNet()
checkpoint = torch.load('/Users/talha/Downloads/moco_v2_800ep_pretrain.tar', map_location='mps', weights_only=True)
model.load_state_dict(checkpoint['state_dict'])
计算图像嵌入的方法与之前预训练的普通CNN模型相同。
with torch.no_grad():
embedding = model(image.unsqueeze(0))
它也返回一个2048维的向量,我们可以确认。

# 应用
这些图像嵌入在一些图像搜索应用中非常有用。例如:
- 电子商务:正如我们之前提到的,它在在线购物中非常有用。它可以以多种方式使用。这是CBIR的众多用途之一。
- 图像分类:我们也可以使用这些嵌入来训练CNN和ViT。
- 图像字幕:如果我们同时使用文本嵌入,我们可以制作一个图像字幕系统。CLIP是一个很好的例子。
# 比较
提供所有各自模型的比较分析将是很好的。
| 算法 | 速度 | 优点 | 缺点 |
|---|---|---|---|
| SIFT | 中等 | 可以在较少的数据上操作 | 不可扩展,对于非深度学习方法来说速度较慢 |
| SURF | 快 | 更快 | 不如其他方法稳健 |
| 预训练CNN | 快 | 有多种模型可供选择,稳健 | 过于通用 |
| 预训练ViT | 中等到快 | 稳健 | 没有明显的优势 |
| 微调模型 | 慢(推理速度快,但训练可能需要很长时间) | 可以更好地适应目标数据,可以给出最佳结果 | 需要大量标记图像和训练资源 |
| 自监督模型 | 取决于训练集,但通常较慢 | 不需要标记图像,结果相当不错 | 需要训练资源 |

# 结论
嵌入方法已经改变了图像搜索,使我们能够以前所未有的速度和精度定位视觉内容。从SIFT和SURF等经典方法到现代深度学习架构,图像嵌入的演变使得这种转变成为可能。
图像嵌入的未来看起来更加令人兴奋,趋势如多模态嵌入 (opens new window)(结合文本、图像和音频数据)和自监督方法消除了对大型标记数据集的依赖。借助像MyScale (opens new window)这样的数据库,它结合了SQL和向量搜索,现在更容易构建先进的图像搜索 (opens new window)应用程序。MyScale支持强大的图像嵌入和通过向量索引快速检索,为图像搜索领域的未来创新提供了坚实的基础。
随着研究的进展,我们可能会看到更快、更准确、更智能的图像搜索能力。这些进步不仅将增强平台上的用户体验,还将重新定义我们在在线视觉信息中的交互方式,使图像搜索像文本搜索一样自然和高效。



