
传统上,机器学习(ML) (opens new window)可以广泛分为两种类型:有监督学习和无监督学习 (opens new window)。在有监督学习中,我们有一些带有标签的数据,这些标签用于训练模型。例如,使用(带有标签的)不同对象的图像来训练图像分类器。
另一方面,无监督学习不需要任何标签,我们在这里探索没有任何先验信息的模式。不可避免地,这很困难但也很吸引人。随着大量数据的可用性(并且每天产生新数据),获取数据总是很容易的,尽管对其进行标记需要大量的时间和金钱。
为了利用我们周围可用的大量数据,有一种先进的学习策略,称为自我-监督学习。在自我监督学习中,我们使用未标记的数据并“模拟”有监督学习。
# 自我监督学习(SSL)
在自我监督学习中,我们将数据分为正样本和负样本,类似于二元(有监督)分类,将考虑的对象视为正样本,将所有其他样本视为负样本。
自我监督学习方法学习联合嵌入,可以广泛分为两类:
- 对比方法
- 非对比方法
在对比方法中,我们采用同一数据的不同样本,例如同一图像的不同视图,并尝试最大化它们的相似性分数,同时尽量将其它样本/图像的相似性分数最小化。另一方面,非对比方法不考虑负样本。一些著名的自我监督学习方法,如BYOL或DINO,是非对比方法的很好的例子,而SimCLR和MoCo也使用负样本,是对比方法的很好的例子。
# 对比学习(CL)
对比学习的核心是选择一种表示,使得正样本对之间的相似性最大化,而负样本对之间的相似性最小化。例如,我输入一个芒果的图像,现在它的目标应该是最大化芒果图像之间的相似性,同时最小化与其他图像之间的相似性。
最简单的设置是将每个数据点(在考虑时)视为正数据点,而将其他所有数据点视为负数据点。假设点为
# 训练
对于每对数据点
为了使训练更加实用,我们以批次的形式进行训练,假设我们有一个批次包含32个图像,那么其中1个图像(它自己)需要具有最大化的相似性分数,而其他31个图像需要具有尽可能小的相似性分数。
然而,只有一个正样本与多个负样本的情况使得学习有区分性的特征变得非常困难,因此我们使用一些智能技术,如数据增强,来生成同一数据点的多个副本。
# 对比学习示例
对比学习已经存在一段时间了。在过去的10年中,它从基于普通CNN的 (opens new window)图像分类(仅仅是为了超越SIFT)发展到CLIP。一些现代的对比学习算法有:
- 对比预测编码(CPC)
- 简单的视觉表示对比学习框架(SimCLR)
- 动量对比(MoCo)
- 对比语言-图像预训练(CLIP)
让我们简要介绍它们,以更好地了解对比学习如何在实践中使用。
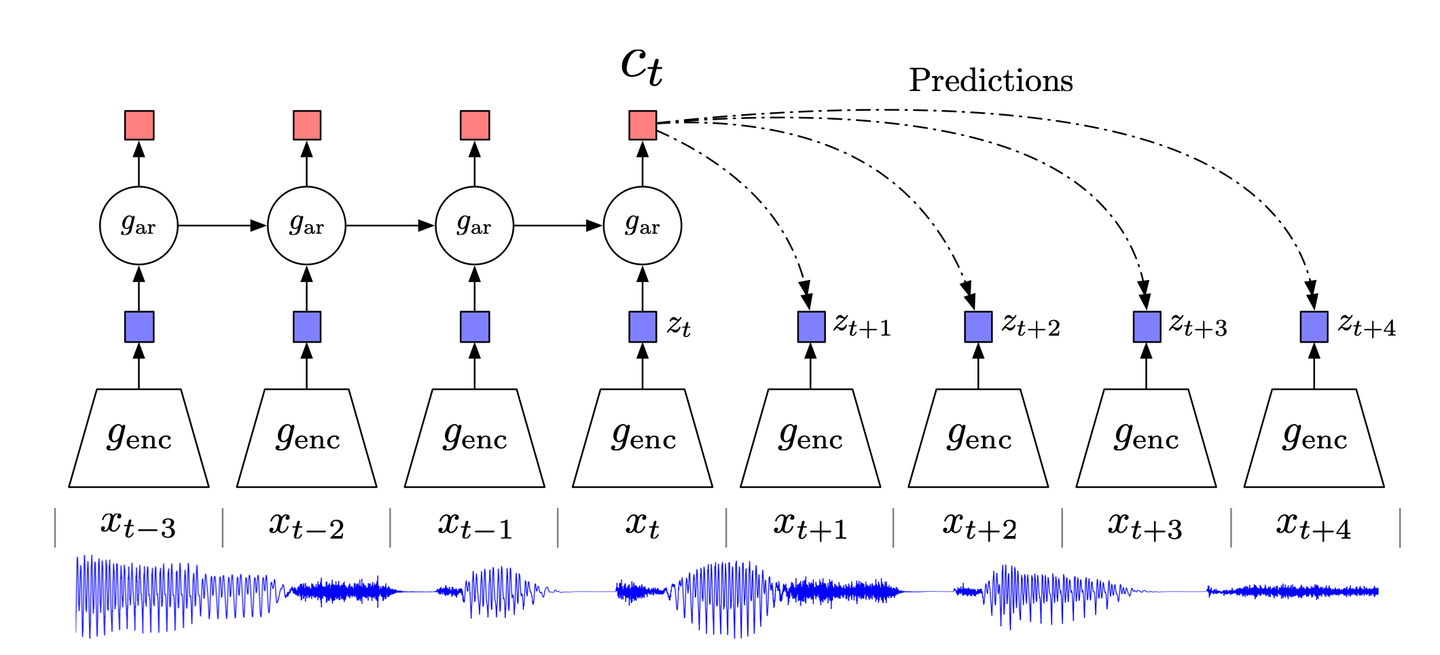
# 对比预测编码
受经典的预测编码数据压缩技术及其在神经科学中的应用的启发,对比预测编码(CPC) (opens new window)试图关注数据中的高级信息,而忽略低级/噪声信息。
CPC的工作原理如下:
- 将高维数据压缩到适当的潜在嵌入空间。这种压缩使得更容易对数据进行建模并相应地进行预测。
- 在选择的嵌入空间中进行预测。
- 使用噪声对比估计(NCE)损失函数训练模型。
# SimCLR
对于计算机视觉而言,SimCLR是一种先进的对比学习技术,它不需要任何预增强或专门的架构,工作原理如下:
- 随机选择一张图像,并使用不同的增强技术(如随机裁剪、随机颜色扭曲或高斯模糊)生成其视图(原始实现中有两个视图)。
- 使用基于ResNet的CNN计算图像表示/嵌入。
- 进一步将此表示转换为(非线性)投影,使用MLP实现。
- 同时训练CNN和MLP以最小化对比损失函数。
在整个过程中,我们一直在谈论无监督学习的需求,但我们也有一些标记数据可供使用。最后,如果我们在一些带有标签的图像上对CNN进行微调,可以提高其在其他(下游)任务上的性能和泛化能力。
关于对比学习工作原理的一些见解
SimCLR不仅引入了一个具有非常好性能的新模型(您可以查看其论文以获取详细的结果分析),而且其作者还提供了一些新的见解,这些见解对于几乎任何对比学习方法都可能有用。因此,我认为值得在这里分享一下:
关键是使用多种增强技术的组合:当单独使用随机裁剪和颜色扭曲时,效果并不显著,但当它们结合使用时,效果最好。
非线性投影很重要:神经网络和对比损失函数的复杂性意味着很难理解背后的运作原理,但凭经验来看,非线性投影(通过MLP)是有用的,因为它可以提高性能高达10%。这个事实在MoCov2的论文中也会被独立观察到,我们很快就会看到。
扩大规模可以提高性能:虽然某些观察结果是特定于SimCLR的,但它们主要适用于对比学习。增加模型的容量(宽度或深度),增加批次大小甚至增加训练时的迭代次数都会提高性能。
# 动量对比(MoCo)
动量对比(MoCo)将对比学习视为字典查找的一种替代方法。这种有趣的观点与Transformer模型有一些相似之处,工作原理如下:
- 首先对数据进行增强,生成两个副本
- 查询编码器(图像左侧的编码器)接收
- 动量编码器接收另一个增强副本
为了使其相关,它被实现为一个队列,它将
- 编码的查询
- 两个编码器一起训练以最小化这个对比损失。
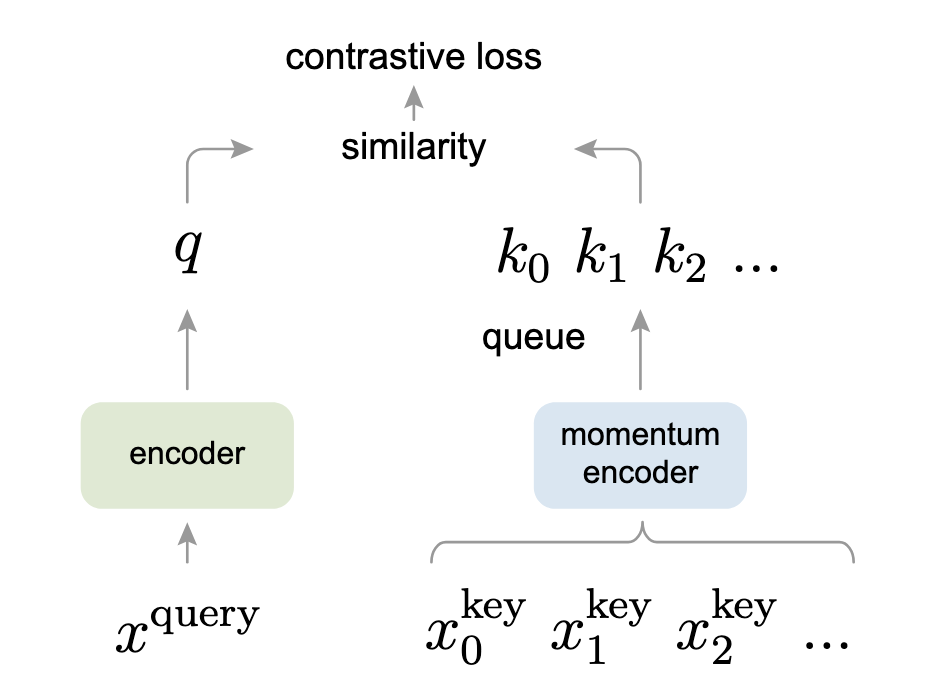
如果您熟悉Transformer,您会发现InfoNCE损失与我们在Transformer中计算注意力的方式非常相似。
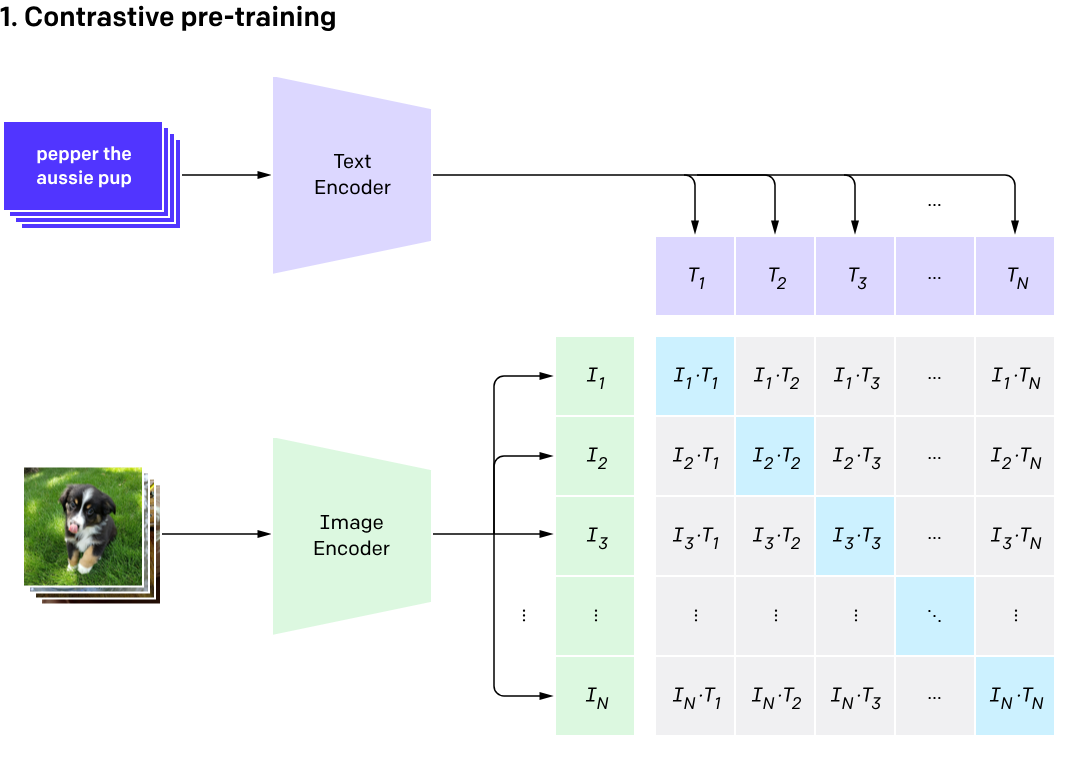
# CLIP
CLIP于2021年推出,通过结合图像和其标题,提升了性能。虽然它不是基于动量的平均方式,但它也使用了两个编码器,一个用于文本,另一个用于图像。以下是它的简要工作流程:
- 图像输入到图像编码器中,其标题输入到文本编码器中。
- 基于ViT(Vision Transformer)的图像编码器获取图像嵌入,而文本编码器对标题进行分词以获取文本特征。这些特征在嵌入空间中作为一对进行整理。
- 文本和图像编码器被训练以最大化任何给定的
- 在测试时,我们提供一个标题字典(不要与MoCo中的动态字典混淆),以及所需的图像。根据图像,它返回具有最高概率的标题。
注意:有关CLIP的更多详细信息,请阅读此文 (opens new window)。
# 代码示例
让我们通过一个代码示例来完整了解。在这里,我将使用Meta Research的MoCo的官方实现 (opens new window)。这段代码主要围绕Moco类展开。
# 构造函数
MoCo类的构造函数初始化了属性,如K、m和T。我们可以看到,它使用特征维度(dim)的默认值为128,队列大小(K)为16位(65,536),而动量系数μ为0.999(相当慢的移动平均值)。温度τ,如论文中已指定,为0.07。
此外,我们可以看到MLP的实现,我们首先在SimCLR中看到它,然后在MoCov2中也看到它(此实现包括两个版本)。
def __init__(self, base_encoder, dim=128, K=65536, m=0.999, T=0.07, mlp=False):
super(MoCo, self).__init__()
self.K = K
self.m = m
self.T = T
# create the encoders
# num_classes is the output fc dimension
self.encoder_q = base_encoder(num_classes=dim)
self.encoder_k = base_encoder(num_classes=dim)
if mlp: # hack: brute-force replacement
dim_mlp = self.encoder_q.fc.weight.shape[1]
self.encoder_q.fc = nn.Sequential(
nn.Linear(dim_mlp, dim_mlp), nn.ReLU(), self.encoder_q.fc
)
self.encoder_k.fc = nn.Sequential(
nn.Linear(dim_mlp, dim_mlp), nn.ReLU(), self.encoder_k.fc
)
for param_q, param_k in zip(
self.encoder_q.parameters(), self.encoder_k.parameters()
):
param_k.data.copy_(param_q.data) # initialize
param_k.requires_grad = False # not update by gradient
# create the queue
self.register_buffer("queue", torch.randn(dim, K))
self.queue = nn.functional.normalize(self.queue, dim=0)
self.register_buffer("queue_ptr", torch.zeros(1, dtype=torch.long))
# 动量编码器
核心部分简单而有效。在动量编码器中,我们只是实现了基于动量的平均的这个方程:
@torch.no_grad()
def _momentum_update_key_encoder(self):
for param_q, param_k in zip(
self.encoder_q.parameters(), self.encoder_k.parameters()
):
param_k.data = param_k.data * self.m + param_q.data * (1.0 - self.m)
# 队列管理
最后,更新队列以删除较旧的批次数据。它的工作原理如下:
- 首先我们收集键
- 队列的指针指向
keys的转置。现在,为什么要精确地指向列而不是行,这是我很好奇的地方。 - 最后,指针移动到下一个批次(这里的模运算是为了循环队列),并且在属性(
self.queue_ptr)中也反映出来。
def _dequeue_and_enqueue(self, keys):
keys = concat_all_gather(keys)
batch_size = keys.shape[0]
ptr = int(self.queue_ptr)
assert self.K % batch_size == 0
self.queue[:, ptr : ptr + batch_size] = keys.T
ptr = (ptr + batch_size) % self.K
self.queue_ptr[0] = ptr
# 训练
在训练过程中,我们将所有这些组合在一起:
- 计算查询特征
- 计算键特征(使用动量更新)
- 计算逻辑回归(正样本和负样本)
- 使用我们刚刚讨论过的函数进行出队和入队
def forward(self, im_q, im_k):
"""
Input:
im_q: a batch of query images
im_k: a batch of key images
Output:
logits, targets
"""
# compute query features
q = self.encoder_q(im_q) # queries: NxC
q = nn.functional.normalize(q, dim=1)
# compute key features
with torch.no_grad(): # no gradient to keys
self._momentum_update_key_encoder() # update the key encoder
# shuffle for making use of BN
im_k, idx_unshuffle = self._batch_shuffle_ddp(im_k)
k = self.encoder_k(im_k) # keys: NxC
k = nn.functional.normalize(k, dim=1)
# undo shuffle
k = self._batch_unshuffle_ddp(k, idx_unshuffle)
# compute logits
# Einstein sum is more intuitive
# positive logits: Nx1
l_pos = torch.einsum("nc,nc->n", [q, k]).unsqueeze(-1)
# negative logits: NxK
l_neg = torch.einsum("nc,ck->nk", [q, self.queue.clone().detach()])
# logits: Nx(1+K)
logits = torch.cat([l_pos, l_neg], dim=1)
# apply temperature
logits /= self.T
# labels: positive key indicators
labels = torch.zeros(logits.shape[0], dtype=torch.long).cuda()
# dequeue and enqueue
self._dequeue_and_enqueue(k)
return logits, labels
顺便说一句,所有这些注释都是作者自己写的,显示出他们不仅写了一篇清晰的论文,而且还写了一段好的、易于理解的代码。

# 对比学习和向量数据库
由于对比学习围绕着输入数据的嵌入和它们之间的距离,它们与向量数据库密切相关。使用训练好的对比学习模型,我们可以简单地应用诸如欧氏距离、余弦相似度或
因此,对比学习与向量数据库结合使用可以有无数的应用,例如:
- 使用CLIP进行零样本识别(本身可以有许多应用)
- 为在线用户提供推荐系统-基于用户的历史记录,它将建议与这些嵌入最接近的产品。
- 文档检索-从数据库中检索与用户查询嵌入最接近的文档
- 异常检测-使用先前交易的嵌入并在嵌入空间中查找此交易与交易历史的“区域”之间的相似性(或差异性),以确定此信用卡的新交易是正常还是欺诈。
# 参考资料
- Dosovitskiy, et al., Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks, IEEE PAMI, 2016.
- Hjelm, et al., Learning Deep Representations by Mutual Information Estimation and Maximization, ICLR, 2019.
- Oord, et al., Representation Learning with Contrastive Predictive Coding, arXiv 2018.
- Chen, et al., A Simple Framework for Contrastive Learning of Visual Representations, ICML 2020.
- Radford, et al., Learning Transferable Visual Models From Natural Language Supervision, arXiv 2020
- He, et al., Momentum Contrast for Unsupervised Visual Representation Learning, arXiv 2020
- He, et al., Improved Baselines with Momentum Contrastive Learning, arXiv 2020




