
大型语言模型(LLM)使许多任务变得更加容易,如制作聊天机器人、语言翻译、文本摘要等等。过去,我们需要为不同的任务编写模型,却总是存在性能问题。现在,我们可以借助 LLM 轻松完成大多数任务。然而,当将 LLM 应用于生产环境时,它们确实存在一些限制。由于缺乏特定或最新的信息,导致了一种称为幻觉 (opens new window)的现象,即模型生成不正确或不可预测的结果。
Vector databases (opens new window)在减轻 LLM 中的幻觉问题方面非常有帮助,它提供了模型可以引用的领域特定数据的数据库。这减少了不准确或荒谬回答的情况。
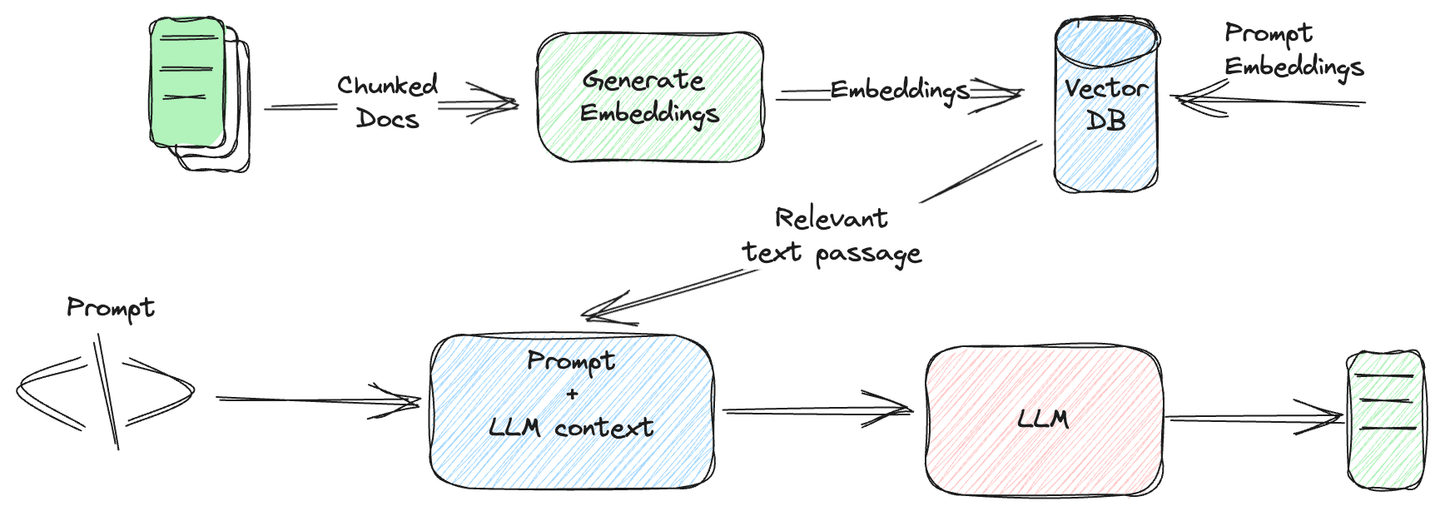
在本博客文章中,我们将看到向量数据库与 SQL 的集成如何为企业带来便利。我们将讨论传统数据库的一些限制以及导致这种新集成——SQL 向量数据库的原因。在博客的最后,我们将看到这些数据库是如何工作的,以及为什么MyScale (opens new window)可能是您在选择向量数据库时的首选。
# 什么是 SQL 向量数据库
SQL 向量数据库是一种专门的数据库类型,它结合了传统 SQL 数据库和向量数据库的功能,借助 SQL 的帮助能够高效地存储和查询高维向量。
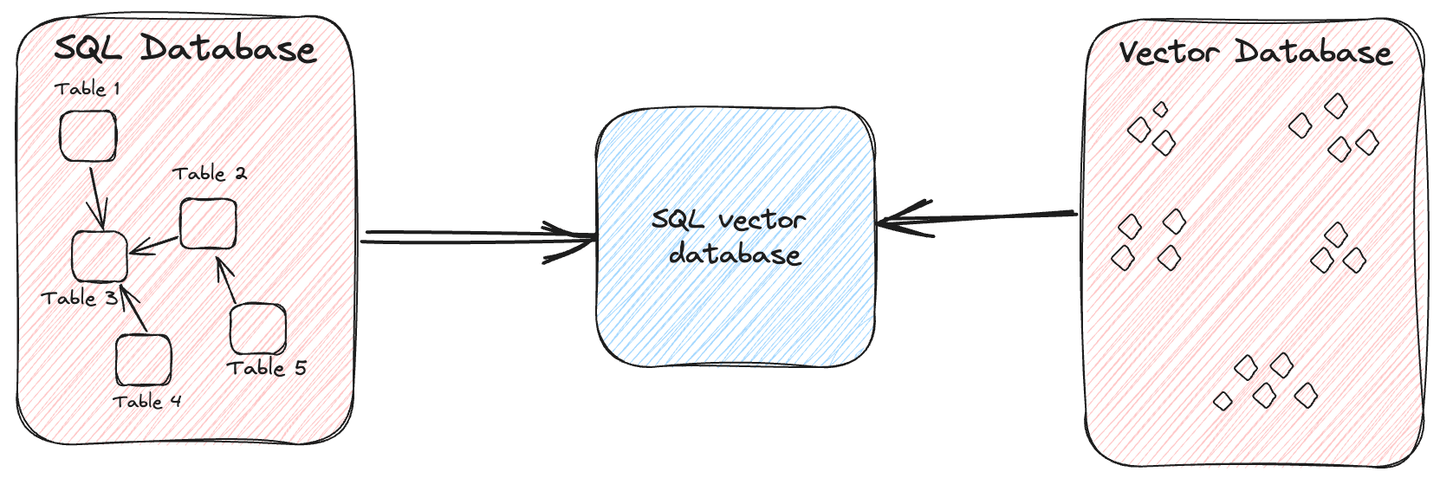
简单来说,它就像一个常规数据库,您可以用它来存储结构化数据和非结构化数据,但还具有快速查询各种数据类型(包括图像、视频、音频和文本)的能力。这种效率背后的机制在于为数据创建向量,从而便于快速识别相似条目。
现在,让我们试着理解 SQL 向量数据库的核心概念,这将有助于理解我们为什么需要 SQL 向量数据库。
# SQL 向量数据库的关键概念
SQL 向量数据库引入了一些创新概念,极大地增强了数据检索和分析的能力,特别是在非结构化和高维数据的背景下。让我们探索其中的一些概念:
- 处理非结构化数据: 数据的向量表示使您能够对非结构化数据执行 ANN(近似最近邻)搜索。当您找到文本、图像或音频等非结构化数据的嵌入时,您捕捉到了语义含义,这使您能够通过测量向量之间的距离来执行相似性比较,以找到最近邻,而不管原始数据格式如何。
- ANN 搜索: SQL 向量数据库将数据存储为向量,并执行一种称为相似性搜索的搜索类型,它不针对单个行进行操作,而是进行近似最近邻(ANN)搜索。该过程涉及识别与给定查询向量最接近的向量,即那些与查询向量的属性最接近的向量。
- 向量索引: 向量索引是指用于高效组织和查询大量向量数据的专用数据结构和算法。向量数据库使用各种向量索引策略来优化数据检索和管理。一些向量数据库使用分层图算法来加速搜索性能。一些供应商可能会开发自己的索引算法,例如,MyScale 开发了一种称为多尺度树图(MSTG)的新颖技术,显著优于现有方法 (opens new window)。
注意:
向量索引的目标是在执行操作(如近似最近邻的相似性搜索)时优化搜索速度和准确性,跨高维向量查找。
# 为什么我们需要 SQL 向量数据库
那么,这里就有一个问题:为什么我们需要 SQL 向量数据库?传统数据库如 MySQL、PostgreSQL 和 Oracle 一直保持领先优势,并具备保持数据组织良好所需的所有必要功能。它们具有快速的索引方法,确保您能够轻松获取所需的确切数据。所以,为什么我们需要 SQL 向量数据库?
毫无疑问,传统数据库非常好用,但是当数据变得庞大和非结构化时,它们确实存在一些限制。让我们来看看:
- 查询速度慢和缺乏语义理解: 传统数据库依赖于精确的关键字匹配和索引来检索数据。但随着社交媒体、传感器等非结构化数据的指数级增长,传统数据库无法理解数据的语义。我们需要的是不仅能够快速获取数据,还能够理解查询的上下文和语义的数据库。例如,在处理自然语言查询或复杂数据关系时,传统方法难以提供快速和相关的结果。
- 难以处理高维数据: 关系数据库以行和列的形式存储数据。随着列或维度的增加,查询性能下降,导致了所谓的“维度灾难”。因此,我们需要一种数据库,可以消除维度问题,同时保持查询性能。
- 难以储存非结构化数据: 关系数据库需要将非结构化数据转换和展平为表中的行和列。但是,如今越来越多的有价值的数据是非结构化的,例如图像、视频、音频、文本文档等,这些数据在关系数据库中很难存储。
- 可扩展性问题: 对于传统数据库来说,可扩展性是一个挑战,特别是当您处理大量数据时。这对于处理大型数据集的组织来说是一个问题,给它们处理和分析数据带来了问题。因此,我们需要一种可以处理大量数据并保持相同速度和效率的数据库。
为了解决这些挑战,SQL 向量数据库的开发出现了,为传统数据库提供了一个更优越的替代方案。
# SQL 向量数据库如何胜过传统数据库
将 SQL 与向量结合起来带来了许多好处,其中有几个优势因其显著的影响而突出:
- 更快的性能和语义搜索: 向量表示使数据库能够从存储的数据中提取语义含义。此外,由于我们在这里找到向量相似性,所以过程变得更快。这对于许多应用程序非常有帮助,例如推荐系统,其中数据之间的语义关系更为重要。
- 高效的数据检索: SQL 向量数据库使用近似最近邻(ANN)技术来查找匹配的记录。通过计算查询向量与数据集之间的余弦相似度,它高效地给出了最相关的前 K 个结果。
- 支持结构化和非结构化数据: SQL 引入向量数据库后,可以使用向量表示来表示非结构化数据并存储语义含义。这样,您可以轻松查询任何结构化或非结构化数据。
- 熟悉的 SQL 接口: SQL 向量数据库最大的优势之一是它们提供了熟悉的 SQL 接口来查询数据。这使您可以使用您的 SQL 技能,并在采用向量功能时减少学习曲线。查询可以使用标准的 SQL 语法编写。
# SQL 向量数据库的工作原理
SQL 和向量数据库的集成涉及以可以使用 SQL 高效查询的方式存储和索引高维向量。这个过程涉及一定的步骤。
注意:
在这个项目中,我们使用 MyScale,一个基于 SQL 的向量数据库进行初始实现。然而,不同的 SQL 向量数据库可能以不同的方式工作。
# 第一步:设置数据库
首先,你需要设置一个支持 SQL 和向量操作的数据库。一些现代数据库已经内置了对向量的支持,而其他数据库可以通过自定义数据类型和函数进行扩展。
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(100),
description TEXT,
vector Array(Float32),
CONSTRAINT check_length CHECK length(vector) = 1536,
);
在这个示例中,我们创建了一个 products 表,其中包含一个 1536D 的 vector 列,用于存储高维向量。
# 第二步:插入数据
在插入数据时,你需要同时存储结构化属性和非结构化数据的向量表示。
INSERT INTO products (id, name, description, vector)
VALUES (1, 'Smartphone', 'A high-end smartphone with a great camera.', ARRAY[0.13, 0.67, 0.29, ...]);
在这个 SQL 语句中,我们插入了一个新的产品记录以及它的向量。
注意:
要获取非结构化数据的向量表示,你可以使用 GPT-4 和 BERT 等模型。
# 第三步:向量索引
下一步是创建向量索引。这是一种定义数据库应用相似性搜索速度的技术。许多向量数据库使用专门的索引技术,如 KD 树、R 树或倒排索引结构来优化这些操作。
ALTER TABLE products ADD VECTOR INDEX idx vector TYPE MSTG
在这里,我们创建了一个 MSTG 索引,适用于索引多维数据。
注意:
MSTG 算法是 MyScale 团队开发的,它在性能和成本效益方面超过了许多专用向量数据库 (opens new window)使用的主流向量搜索索引。
# 第四步:查询数据
要查询数据,您只需将传统的 SQL 查询与向量操作结合起来。例如,如果您想要找到与查询向量相似的产品,可以使用向量 distance 函数。
SELECT name, description, distance(vector, query_vector) as dist
FROM products
ORDER BY dist LIMIT 5;
此查询找到向量列的向量表示与 query_vector 之间的距离。然后,它按照距离的升序对结果进行排序。

# 理想解决方案:SQL 向量数据库 MyScale
这就是 MyScale 的作用所在,它提供一个将关系数据库和向量数据库结合起来的解决方案。MyScale 基于开源 SQL 数据库 ClickHouse 构建,允许直接使用标准 SQL 语法运行高级向量查询,消除了集成单独的关系和向量数据库的麻烦。与 Pinecone、Milvus 和 Qdrant 等其他向量数据库不同,MyScale 为向量搜索提供了一个单一的 SQL 接口。它允许在单个数据库中存储标量和向量数据。现在,您可以直接使用熟悉的 SQL 快速获取向量结果。
人们普遍认为关系数据库无法提供与向量数据库相匹配的性能。MyScale 打破了这种观点,通过我们进行的各方面的比较,MyScale 不仅在搜索准确性和查询处理速度方面显著 优于 pgvector (opens new window),而且在 超过 Pinecone 等专用向量数据库方面 (opens new window),特别是在成本效益和索引构建时间方面,MyScale 出色的性能,加上 SQL 的便捷性,使 MyScale 成为企业的首选。
如果您有更多问题或对我们的产品感兴趣,请随时通过 Discord (opens new window) 联系我们,或关注 MyScale 的 Twitter (opens new window)。



