
检索增强生成(RAG)是一种人工智能框架,旨在通过将其与从外部知识库检索到的信息集成,增强LLM。鉴于RAG近来所受到的关注不断增加,可以合理地得出结论,RAG现在是人工智能/自然语言处理(AI/NLP)生态系统中的一个重要话题。因此,让我们深入讨论一下当RAG系统与自托管LLMs配对时可以期待什么。
在题为“*发现检索增强生成的性能提升 (opens new window)”的博客文章中,我们研究了检索到的文档数量如何提高LLM答案的质量。我们还描述了基于存储在向量数据库(如MyScale (opens new window))中的MMLU数据集的矢量化LLM如何在集成上下文相关知识时生成更准确的响应,而无需对数据集进行微调。
因此,要点如下:
RAG通过使用外部数据增强提示来填补知识空白,减少幻觉。
在应用程序中使用外部LLM API可能会对数据安全性造成潜在风险,降低控制力,并且在用户量较大时会显著增加成本。因此,引发的问题是:
如何确保更大的数据安全性并保持对系统的控制?
简明的答案是使用自托管LLM。这种方法不仅可以提供对数据和模型的更高控制力,还可以增强数据隐私和安全性,同时提高成本效益。
# 为什么选择自托管LLMs?
基于云的大型语言模型即服务(如OpenAI的ChatGPT)易于访问,并且可以为各种应用领域增加价值,提供即时和可追溯的访问。然而,公共LLM提供商可能会侵犯数据安全和隐私,以及对过度控制、知识泄漏和成本效益的担忧。
注意:
如果您对其中任何/所有这些问题感同身受,那么使用自托管LLM是值得的。
随着我们继续讨论,让我们详细讨论这四个重要问题:
# 🔒 隐私
在将LLM API与应用程序集成时,隐私必须是首要关注的问题。
为什么隐私是一个问题?
对这个问题的回答有几个方面,如下所示:
- LLM服务提供商可能会使用您的个人信息进行训练或分析,从而危及隐私和安全。
- 其次,LLM提供商可能会将您的搜索查询纳入其训练数据中。
自托管LLMs解决了这些问题,因为它们是安全的,您的数据永远不会暴露给第三方API。
# 🔧 控制力
LLM服务(如OpenAI GPT-3.5)通常会对暴力和寻求医疗建议等主题进行审查。您无法控制哪些内容被审查。然而,您可能希望开发自己的审查模型(和规则)。
如何采用符合您要求的审查模型?
总体上理论上的答案是通过构建定制的过滤器来对LLM进行自定义微调,而不是使用提示,因为经过微调的模型更加稳定。此外,自托管精调模型提供了修改和覆盖默认审查内容的自由,这是公共领域LLMs所不具备的。
# 📖 知识泄漏
如上所述,使用第三方LLM服务器时,知识泄漏是一个问题,特别是如果您运行包含专有业务信息的查询。
注意:
可能的知识泄漏是双向的,从提示到LLM,然后返回到查询应用程序。
如何防止知识泄漏?
总结起来,使用自托管LLM而不是公共领域LLM,因为您的专有业务知识库是其最有价值的资产之一。
# 💰 成本效益
自托管LLMs是否比云托管LLMs更具成本效益还有争议。文章“连续批处理如何在LLM推理中实现23倍吞吐量提升并降低p50延迟 (opens new window)”中描述的研究报告称,当延迟和吞吐量与先进的连续批处理策略正确平衡时,自托管LLMs更具成本效益。
注意:
我们将在本文后面进一步扩展这个概念。
# 通过自托管LLMs最大化您的RAG
![]()
LLMs消耗计算资源。它们需要大量资源来进行推理和提供响应。添加RAG只会增加对计算资源的需求,因为它们可以为了提高准确性而增加超过2000个标记。不幸的是,这些额外的标记会产生额外的成本,特别是如果您与像OpenAI这样的开源LLM API进行接口交互。
通过自托管LLM,使用矩阵和方法(如KV Cache (opens new window)和Continuous Batching (opens new window))可以改善效率,随着提示的增加,这些数字可能会有所改善。然而,另一方面,大多数基于云的核心GPU计算平台(如RunPod (opens new window))计费的是运行时间,而不是标记吞吐量:这对于自托管的RAG系统来说是个好消息,导致每个提示标记的较低成本费率。
下表讲述了自托管LLMs与RAG相结合可以提供成本效益和准确性的故事。总结如下:
- 当达到最大限度时,成本仅为
gpt-3.5-turbo的10%。 llama-2-13b-chatRAG流水线仅花费0.04美元,用于1840个标记的十个上下文,是没有任何上下文的gpt-3.5-turbo成本的三分之一。
注意:
有关RAG的性能提升的更多详细信息,请参阅我们的第一篇RAG博客文章 (opens new window)。
表格:总成本比较(美分)
| # 上下文 | 平均标记数 | LLaMA-2-13B准确性提升 | llama-2-13b-chat @ 1线程 | llama-2-13b-chat @ 8线程 | llama-2-13b-chat @ 32线程 | gpt-3.5-turbo |
|---|---|---|---|---|---|---|
| 0 | 417 | +0.00% | 0.3090 | 0.0423 | 0.0143 | 0.1225 |
| 1 | 554 | +4.83% | 0.3151 | 0.0450 | 0.0166 | 0.1431 |
| 3 | 737 | +6.80% | 0.3366 | 0.0514 | 0.0201 | 0.1705 |
| 5 | 1159 | +9.07% | 0.3627 | 0.0575 | 0.0271 | 0.2339 |
| 10 | 1840 | +8.77% | 0.4207 | 0.0717 | 0.0400 | 0.3360 |
# 我们的方法
我们使用text-generation-inference (opens new window)在本文中的所有评估中运行了一个未量化的llama-2-13b-chat模型。我们还租用了一个云Pod,配备1个NVIDIA A100 80GB,每小时费用为1.99美元。这种规模的Pod可以部署llama-2-13b-chat。值得注意的是,每个数字都使用第一个四分位数作为下界,第三个四分位数作为上界,以箱线图的形式直观地表示数据的分布。
注意:
使用70B的模型需要更多可用的GPU内存。
# 将LLM吞吐量推向极限
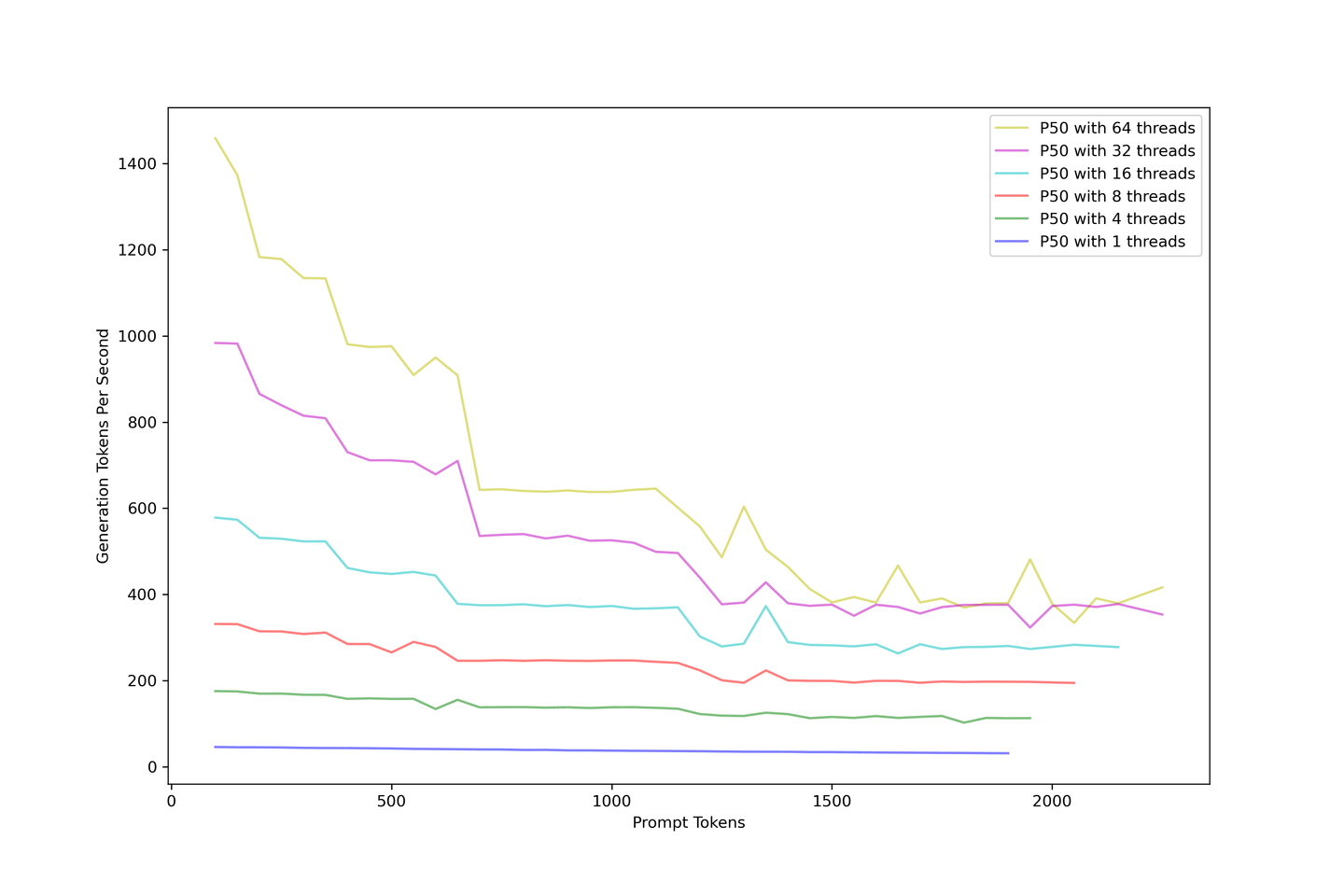
整体吞吐量应该是首要考虑的因素。我们将LLM从1个线程过载到64个线程,以模拟许多同时到达的查询。下图描述了随着提示变大,生成吞吐量如何下降。无论如何增加并发性,生成吞吐量都会在大约400个标记/秒左右收敛。
添加提示会降低吞吐量。作为解决方案,我们建议使用少于10个上下文的RAG来平衡准确性和吞吐量。
# 测量更长提示的启动时间
模型的响应速度对我们来说至关重要。我们还知道,非正式语言建模的生成过程是迭代的。为了提高模型的响应时间,我们使用KV Cache缓存了从先前生成的结果,以减少使用KV Cache生成LLM的计算时间。
注意:
您始终需要计算所有输入提示的键和值。

随着提示长度的增加,我们继续评估模型的启动时间。下图使用对数刻度来说明启动时间。
以下是关于此图表的几点说明:
- 32个线程以下的启动时间是可以接受的;
- 大多数样本的启动时间低于1000毫秒;
- 当我们增加并发性时,启动时间急剧上升;
- 使用64个线程的示例从1000毫秒以上开始,最终在大约10秒结束;
- 这对于用户来说等待时间太长了。
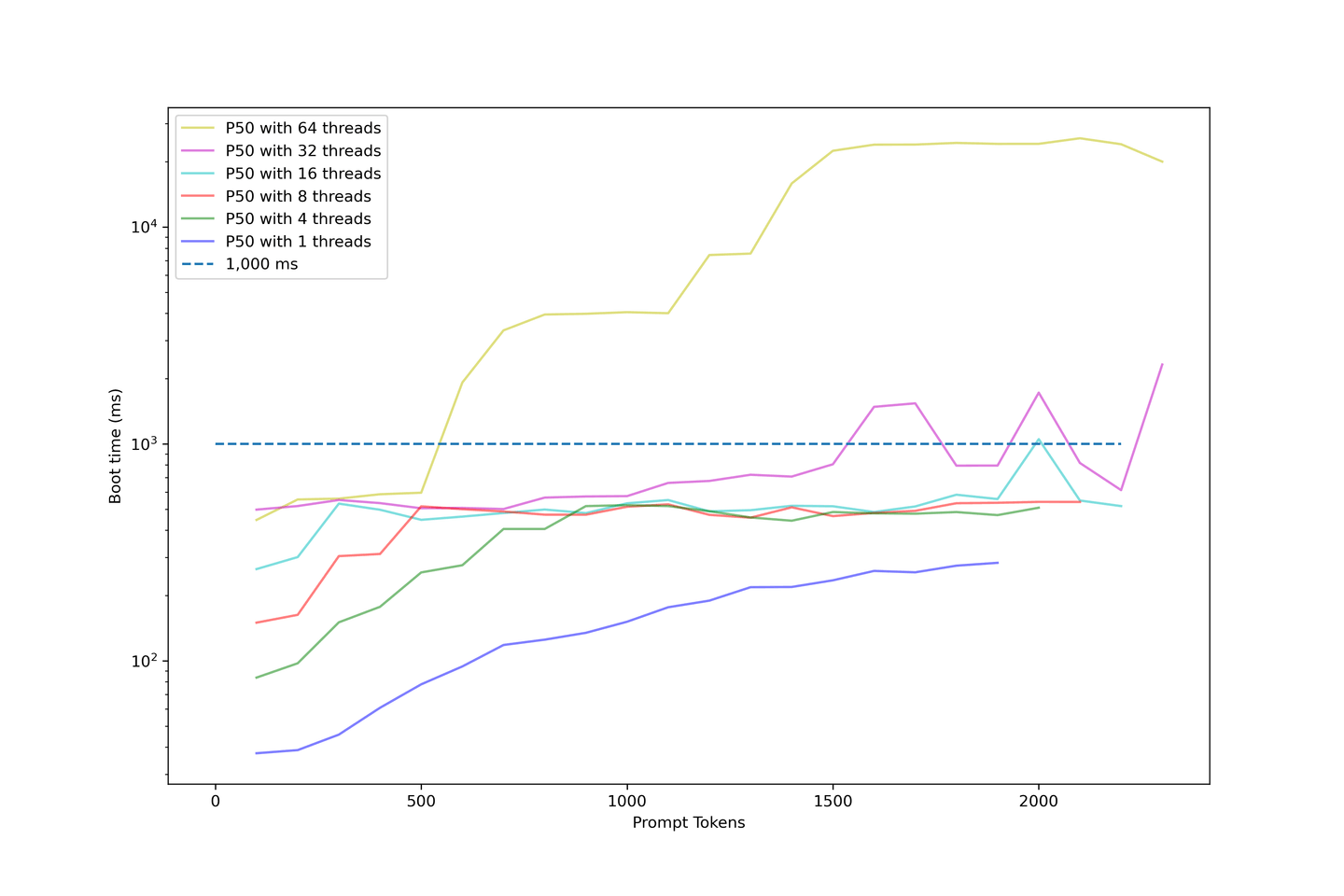
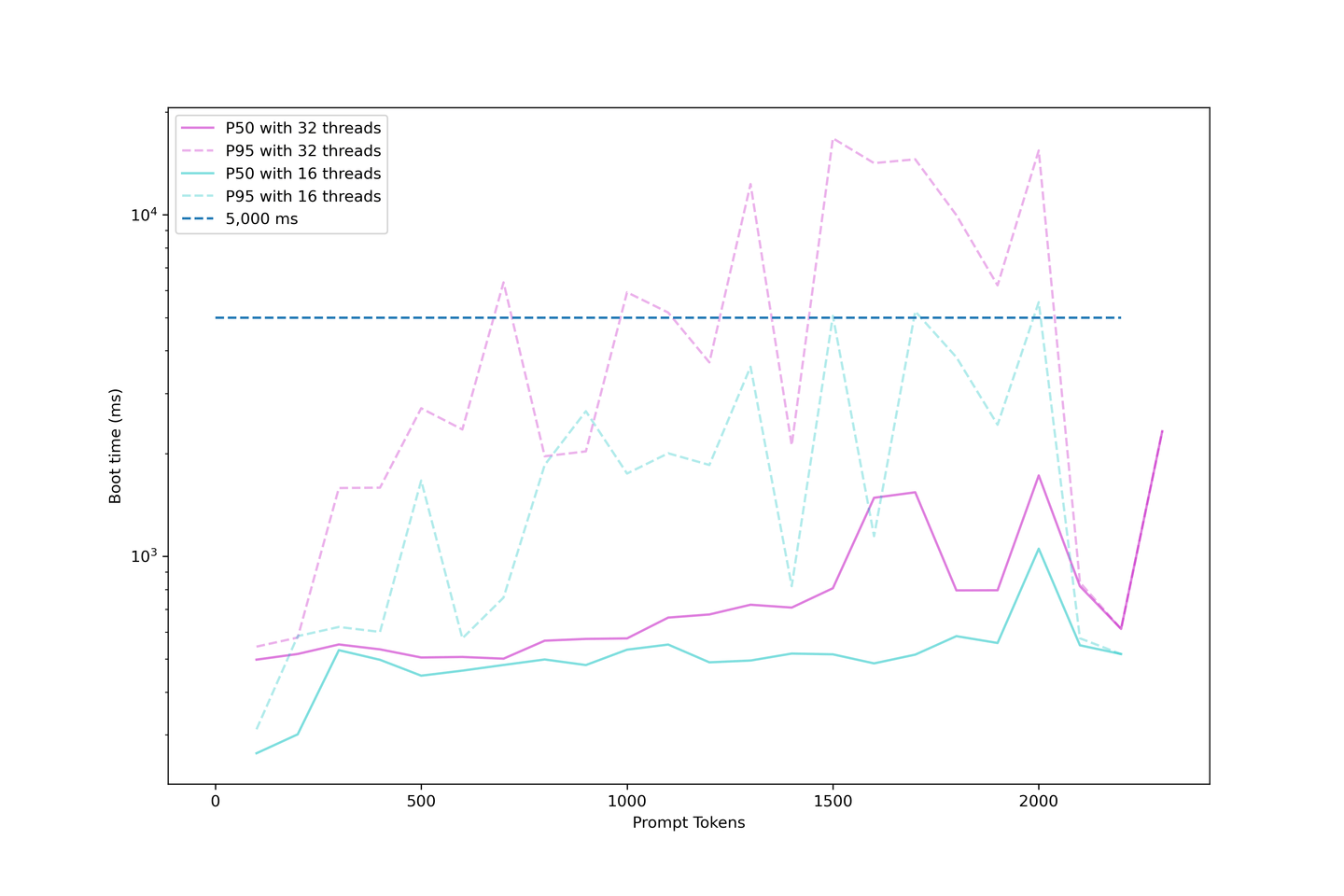
我们的设置显示,当并发性低于32个线程时,平均启动时间约为1000毫秒。因此,我们不建议过度加载LLM,因为启动时间将变得非常长。
# 评估生成延迟
我们知道,使用KV Cache的LLM生成可以分为启动时间和生成时间;我们可以评估实际的生成延迟,即用户等待在应用程序中看到下一个标记所需的时间。
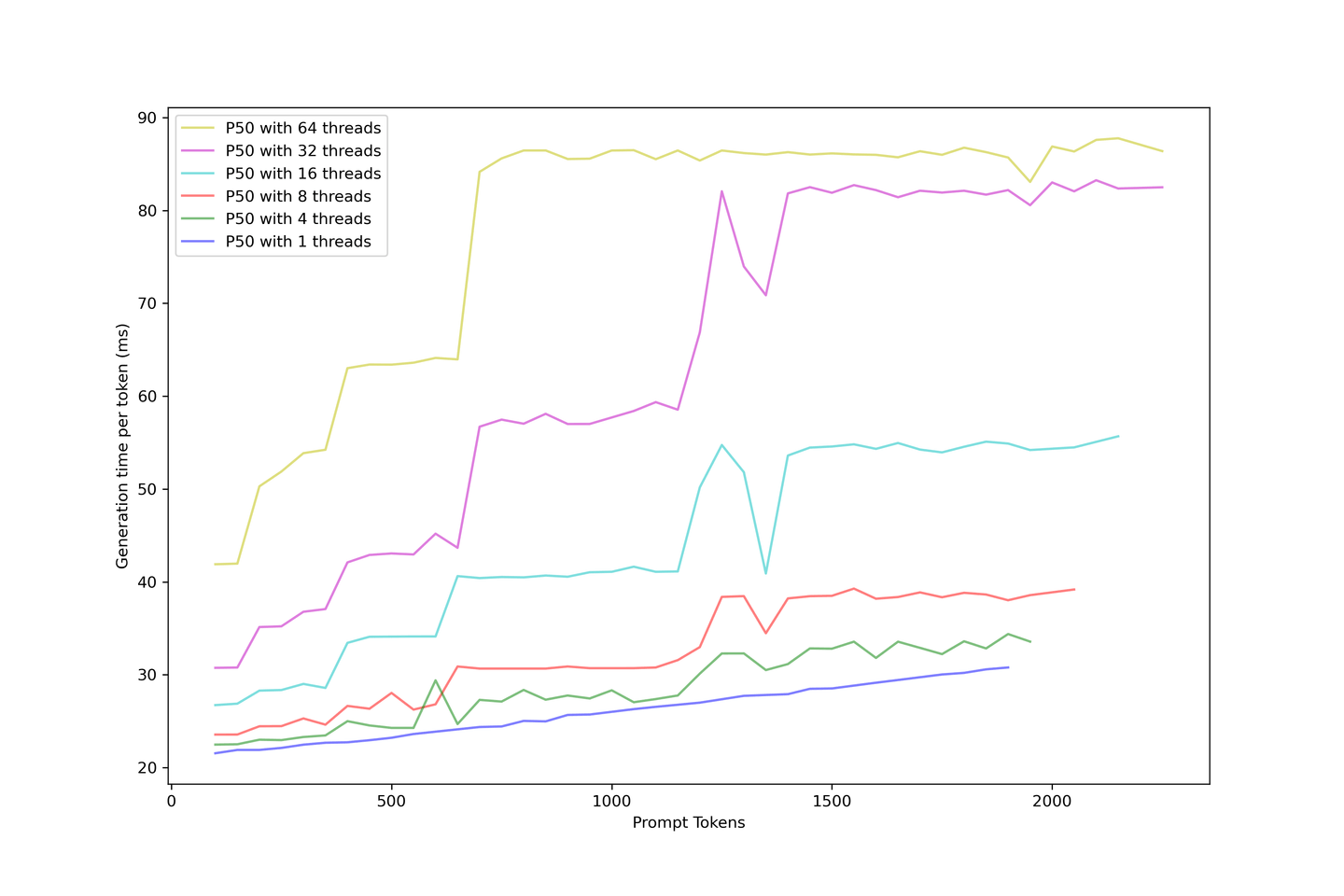
生成延迟比启动时间更稳定,因为在启动过程中较大的提示很难放置在连续批处理策略中。因此,当您有更多请求同时到达时,您必须等待前一个提示被缓存,然后才能显示下一个标记。
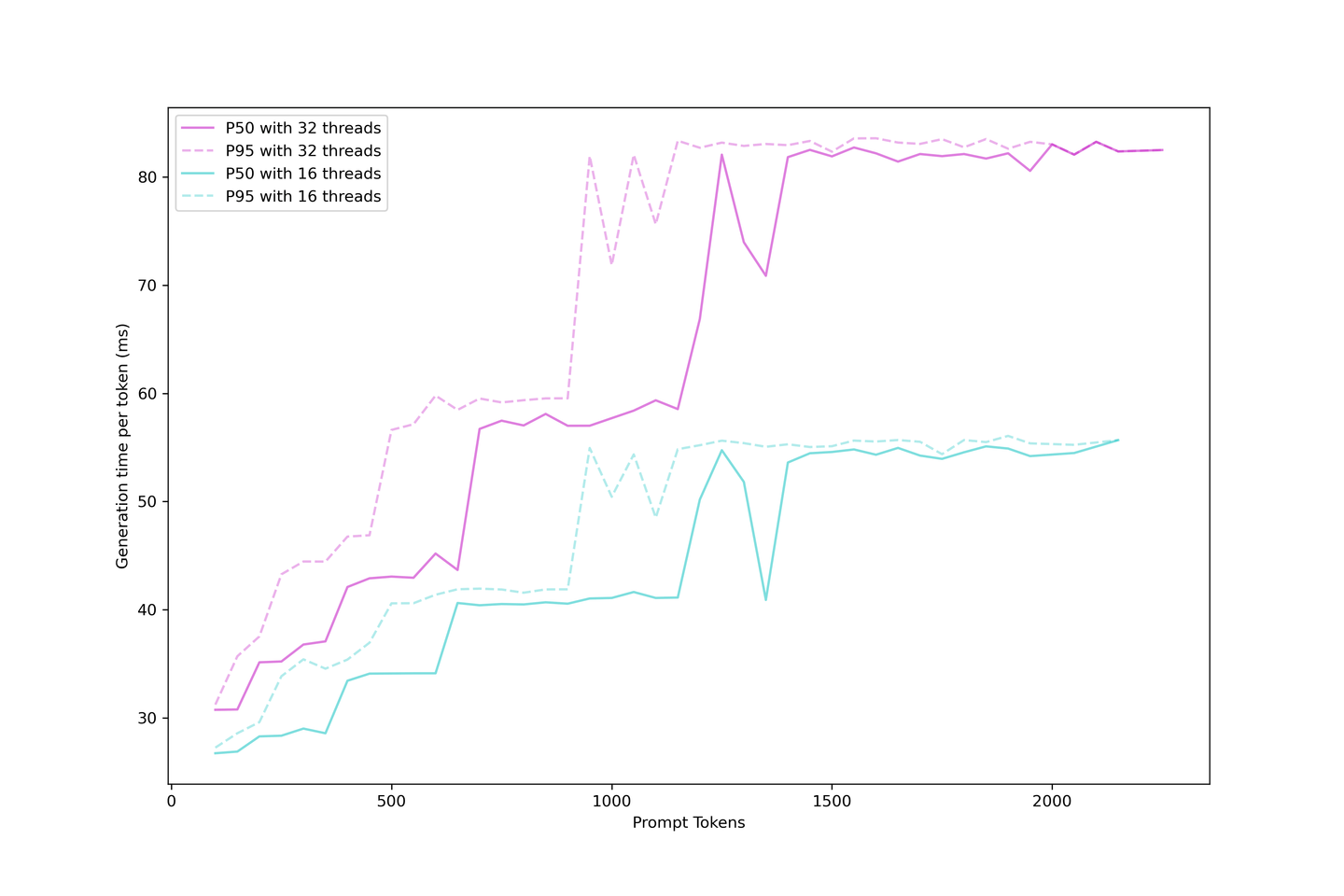
另一方面,一旦建立了缓存,生成就变得简单得多,因为KV缓存减少了迭代次数,并且在批次中有空位时,生成被安排进行。延迟在不同的步骤上升,这些步骤随着更大的提示而到达得更早,并且批次饱和。更多的请求很快就会耗尽LLM,增加限制同时提供更多的请求。
合理地预期生成延迟在90毫秒以下,甚至在60毫秒左右,如果您不过度使用上下文和并发性。因此,在此设置中,我们建议使用32个并发性的五个上下文。
# 比较gpt-3.5-turbo的成本
我们非常关注这个解决方案的成本。因此,我们根据上述收集的数据估算了成本,并为我们的流水线创建了以下成本模型:
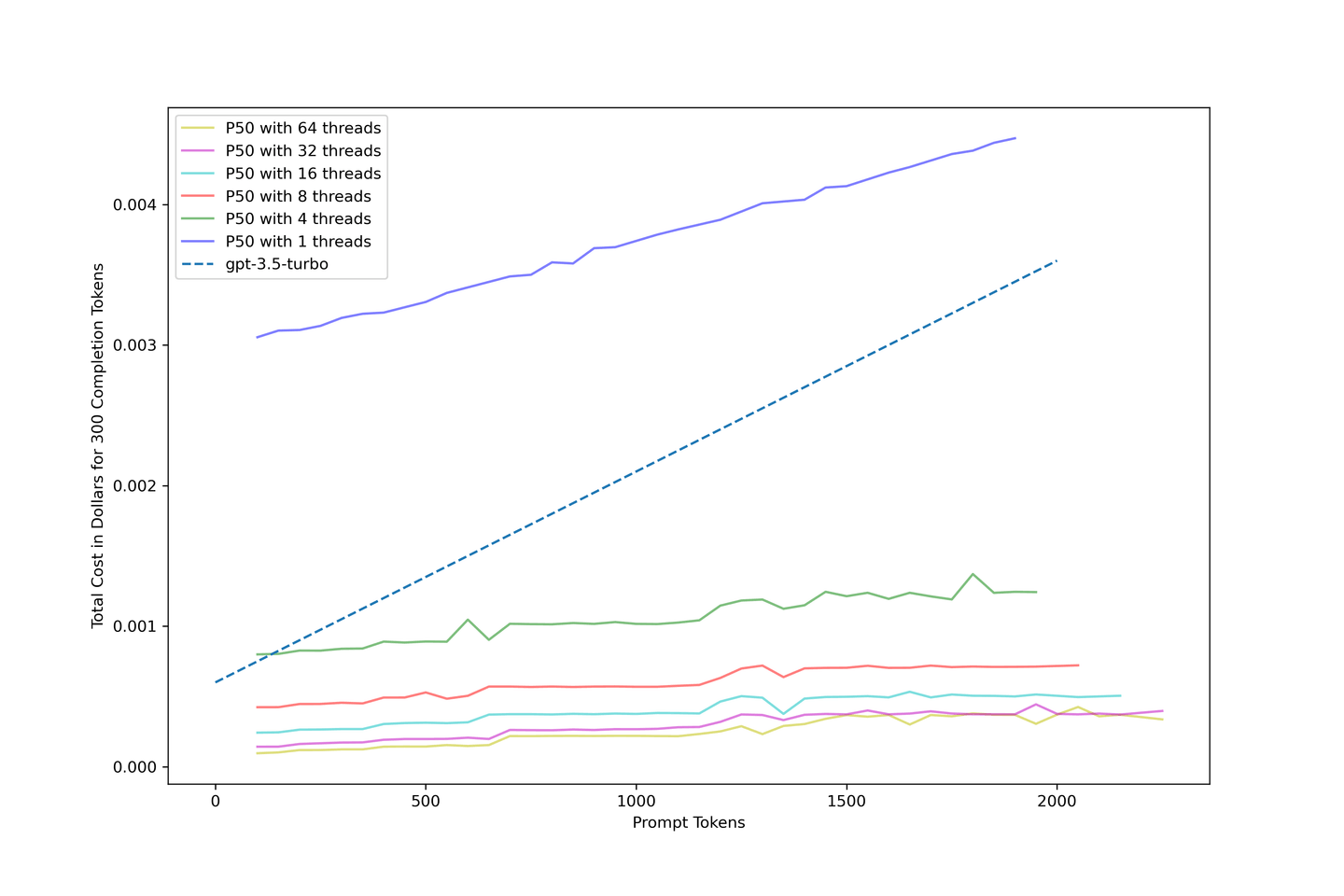
使用KV Cache和连续批处理可以提高系统的成本效益,通过正确的设置,潜在地将成本降低到gpt-3.5-turbo的十分之一。建议使用32个线程的并发性以获得最佳结果。
# 接下来做什么?
我们提出的最后一个问题是:
我们可以从这些图表中学到什么,并从哪里继续?
# 在延迟和吞吐量之间取得平衡
延迟和吞吐量之间总是存在权衡。估计您的每日使用量和用户对延迟的容忍度是一个很好的起点。为了最大化每美元的性能,我们建议您在1x NVIDIA A100 80GB上预期32个并发性,使用llama-2-13b或类似模型。这样可以获得最佳吞吐量、相对较低的延迟和合理的预算。您始终可以更改决策;请记住始终首先估计您的用例。
# 模型微调:更长和更强
您现在可以使用RAG系统对模型进行微调。这将帮助模型适应更长的上下文。有一些开源存储库对LLMs进行了更长输入长度的微调,例如Long-LLaMA (opens new window)。使用更长上下文进行微调的模型是良好的上下文学习者,并且比通过RoPE rescaling (opens new window)拉伸的模型表现更好。
# 将MyScale与RAG系统配对:推理与数据库成本分析
通过将MyScale和RunPod的10个A100 GPU与MyScale(向量数据库)配对,您可以轻松配置一个Llama2-13B + Wikipedia知识库RAG系统,无缝满足多达100个并发用户的需求。
在我们结束这个讨论之前,让我们考虑一下运行这样一个系统的简单成本分析:
| 推荐产品 | 建议规格 | 每月大约成本(美元) |
|---|---|---|
| RunPod | 10个A100 GPU | $14,000 |
| MyScale | 4000万个向量(记录)x 2个副本 | $2,000 |
| 总计 | $16,000 |
注意:
- 这些成本是基于上述突出的成本计算的近似值。
- 大规模的RAG系统显着提高了LLM的性能,向量数据库服务的额外成本不到15%。
- 随着用户数量的增加,向量数据库的摊销成本将更低。

# 总结
直观地可以得出结论,RAG中的额外提示成本更高且更慢。然而,我们的评估显示,这是一个适用于实际应用的可行解决方案。本次评估还评估了您在部署具有外部知识库的LLM时可以期望的成本和整体性能,帮助您建立成本模型。
最后,我们可以看到,MyScale的成本效益使RAG系统具有更高的可扩展性!
因此,如果您有兴趣评估RAG流水线的问答性能,请加入我们的discord (opens new window)或推特 (opens new window)。您还可以使用RQABenchmark (opens new window)评估自己的RAG流水线!
我们将向您发布有关LLMs和向量数据库的最新发现!



