
# AIGC Prompt Management
![]()
AIGC (Artificial Intelligence Generated Content) hat viele Menschen inspiriert und inspiriert weiterhin, persönliche Bilder zu erstellen, die ihren einzigartigen Geschmack und ihre Vorlieben widerspiegeln.
Als Reaktion auf diese wachsende Faszination für AIGC erkunden die Menschen innovative Techniken wie die Integration von Stable Diffusion und LLMs (Large Language Models).
Aber was ist Stable Diffusion?
Stable Diffusion (opens new window) ist ein "Deep-Learning-Text-zu-Bild-Modell, das hauptsächlich zur Generierung detaillierter Bilder basierend auf Textbeschreibungen verwendet wird."
Sie können visuell fesselnde Bilder erzeugen, indem Sie die Leistungsfähigkeit von Stable Diffusion nutzen. In der Praxis erzeugt das Stable Diffusion-Modell beim Rendern des Bildes ein glattes und konsistentes Bild, das detailliert ist.
Im Rahmen dieses kreativen Prozesses ermöglicht es die Integration leistungsstarker LLMs (Large Language Models) den Benutzern, textuelle Anweisungen oder Beschreibungen einzugeben, sodass das KI-System entsprechende Bilder gemäß ihren ästhetischen Vorlieben generieren kann. Dadurch können die Menschen ihre künstlerischen Visionen zum Leben erwecken und die bemerkenswerten Möglichkeiten von AIGC demonstrieren, was zu einem Gefühl der Zufriedenheit führt.
Die Eingabe der anfänglichen Textanweisungen oder Beschreibungen kann jedoch eine Herausforderung darstellen. Glücklicherweise gibt es eine Lösung: Wir können die Leistungsfähigkeit einer Vektordatenbank wie MyScale nutzen, um diese Hürde zu überwinden.
Wie?
Wir können eine umfangreiche Sammlung von Anweisungen, die erfolgreich zur Generierung von Bildern verwendet wurden, in einer MyScale-Vektordatenbank speichern und organisieren. Dadurch entsteht eine wertvolle Ressource für Benutzer, die Inspiration benötigen oder Schwierigkeiten haben, geeignete Anweisungen zu finden. Eine gut kuratierte Vektordatenbank erleichtert das Auffinden und Abrufen von Anweisungen, die eng mit dem beabsichtigten Stil und Konzept eines Bildes übereinstimmen.
Dies wiederum vereinfacht den kreativen Prozess, macht ihn zugänglicher und unterstützt Benutzer bei der Auswahl ihrer Anweisungen. Die Nutzung einer Vektordatenbank ermöglicht es Benutzern letztendlich, die anfängliche Herausforderung der Anweisung zu überwinden und Bilder mit Zuversicht und Klarheit zu generieren.
# Verbesserung des AIGC-Anweisungsmanagements mit MyScale
Wo fangen wir an?
Beginnen wir damit, die folgende Pipeline zu verwenden, um eine Vektordatenbank zu erstellen, in der unsere Anweisungssammlung gespeichert und organisiert wird:
Die Anweisung für ein bestimmtes Bild finden: Um den Text zu finden, der mit einem bestimmten Bild verknüpft ist, können wir MyScale verwenden, um eine Rückwärtssuche durchzuführen. Indem wir die Merkmale des Bildes mit den gespeicherten Vektoren vergleichen, können wir die Anweisung oder Anweisungen identifizieren, die wahrscheinlich das Bild generiert haben. Dadurch können wir aus dem kreativen Prozess hinter dem Bild lernen.
Bilder finden, die einem bestimmten Stil ähneln: Durch die Verwendung von MyScale können wir nach Bildern suchen, die dem von uns angestrebten Stil nahe kommen, indem wir die Vektorrepräsentation des gewünschten Stils mit den Vektorrepräsentationen in der Datenbank vergleichen. Wir können die MyScale-Datenbank nutzen, um auf kuratierte Bilder zuzugreifen, die wertvolle Referenzen und Inspiration für die Bildgenerierung sein können.
Spezifische Anweisungen für eine allgemeine Idee erhalten: Mit MyScale können wir nach Bildern suchen, die dem von uns beabsichtigten Stil nahe kommen, indem wir ihre Vektorrepräsentation mit den Vektorrepräsentationen in der Datenbank vergleichen. Die MyScale-Datenbank bietet Zugriff auf kuratierte Bilder als wertvolle Referenzen und Inspiration.
Suche und LLMs zur Verbesserung von Anweisungen verwenden: Durch die Kombination von Suchalgorithmen und LLMs kann die Effektivität unserer Anweisungen verbessert werden. Die Suche in der Vektordatenbank kann Anweisungen finden, die historisch relevante Ergebnisse erzeugt haben. Neben der Verbesserung unserer vorhandenen Anweisungen dienen diese Anweisungen als Ausgangspunkt. Mit LLMs können wir auch neue Anweisungsvarianten generieren oder vorhandene verfeinern und so den Prozess der Bildgenerierung optimieren.
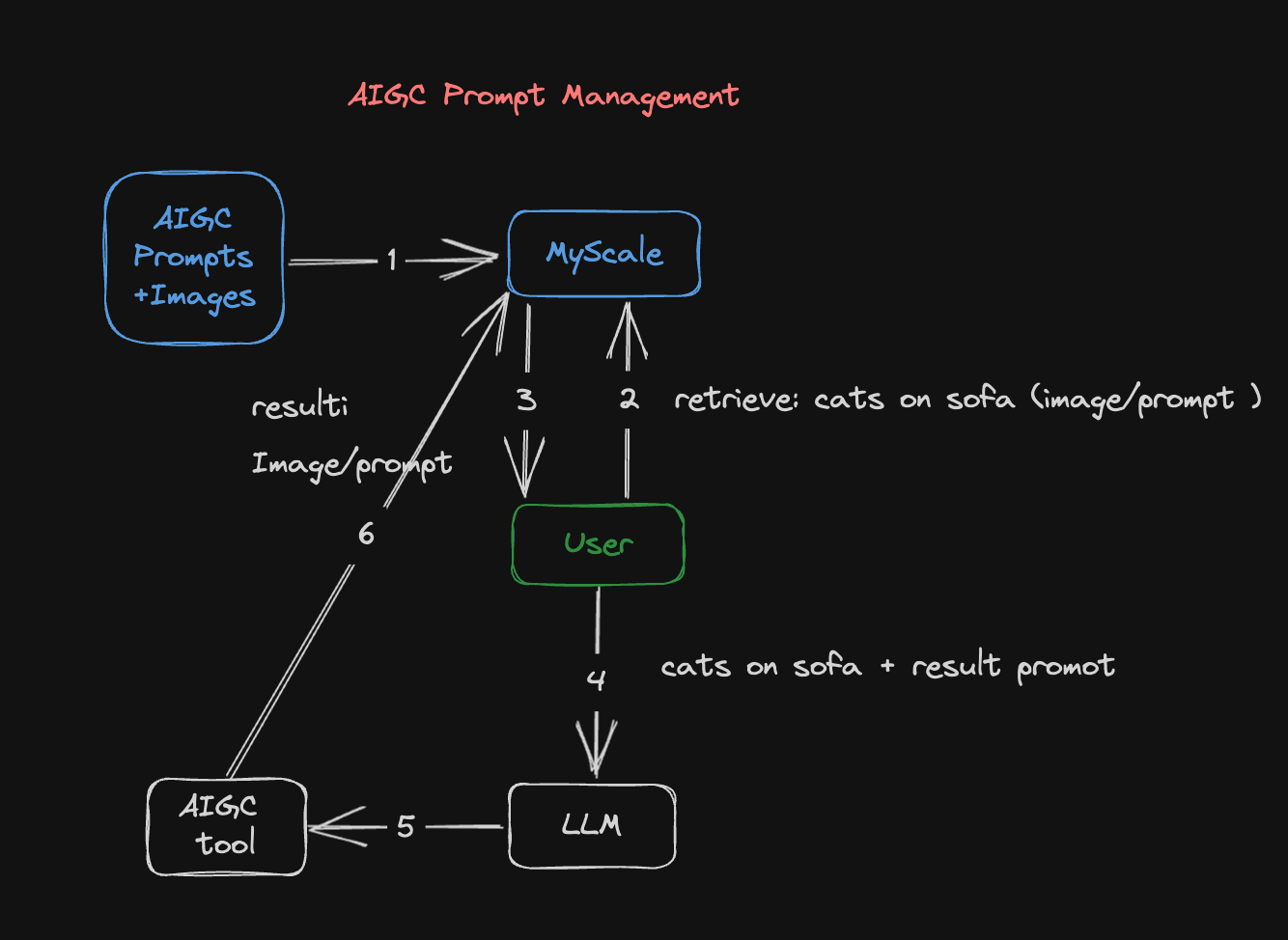
Abbildung 1: AIGC-Anweisungsmanagement-Pipeline
Diese Abbildung veranschaulicht, wie die AIGC-Anweisungsmanagement-Pipeline ein Bild generiert:
Der Datensatz mit den Bildern und den zugehörigen Anweisungen wird in Einbettungen umgewandelt und in einer MyScale-Datenbank gespeichert. Einbettungen beinhalten die Umwandlung von Bildern oder Anweisungen in Vektorrepräsentationen, die später in diesem Prozess abgerufen und verwendet werden können.
Der zweite Schritt besteht darin, die MyScale-Datenbank mit Bildern oder Anweisungen zu durchsuchen. Wenn Sie ein vorhandenes Bild haben, kann es in eine Vektorrepräsentation umgewandelt und mit den Bildvektoren in der Datenbank verglichen werden. Gleiches gilt, wenn Sie eine vorhandene Anweisung haben, die in eine Vektorrepräsentation umgewandelt und mit vorhandenen vektorisierten Anweisungen verglichen werden kann.
Die MyScale-Datenbank liefert Ergebnisse, die dem eingegebenen Bild oder der eingegebenen Anweisung entsprechen. Sobald die Abfrage mit dem Bild oder der Anweisung an die Datenbank gesendet wurde, liefert sie ähnliche Bilder oder Anweisungen, die dort gespeichert sind.
Sie können sich auf die aus der Datenbank zurückgegebenen Bild- und Anweisungsergebnisse beziehen und ein LLM verwenden, um die Anweisungen zu verbessern. Das LLM kann diese Ergebnisse analysieren und daraus lernen, einzigartige und optimierte Anweisungen generieren und Ihnen helfen, Ihre Erwartungen und kreativen Richtungen zu verfeinern.
Ein Stable Diffusion-Modell wird dann verwendet, um genauere Bilder basierend auf der verbesserten Anweisung zu generieren. In der Praxis geben Sie nach der Verbesserung der Anweisung diese in das Stable Diffusion-Modell ein, um Bilder zu erstellen, die mit dieser Anweisung in Verbindung stehen.
Zuletzt werden die generierten Bilder und verbesserten Anweisungen in der MyScale-Datenbank für zukünftige Verwendung gespeichert. Mit der kontinuierlichen Ansammlung von Bildern und Anweisungen in der Datenbank werden zukünftige Suchen und kreative Unternehmungen ermöglicht.
# Fallstudie: Generierung eines Bildes
In diesem Szenario verwenden wir das Stable Diffusion Model (opens new window), um ein Bild basierend auf der folgenden Anweisung zu generieren: "Eine Katze schläft auf dem Sofa."
Das folgende Bild wird generiert:

Ein guter Anfang. Aber wir können dieses Bild verbessern, indem wir den folgenden Workflow durchgehen:
# Installieren der Voraussetzungen
Der erste Schritt besteht darin, die folgenden Voraussetzungen zu installieren (sowie streamlit, pandas, lmdb und torch), indem Sie den CLI-Befehl am Ende dieses Abschnitts ausführen:
transformers: Das CLIP-Modell zur Erstellung von Text- und Bild-Einbettungentqdm: Eine schöne Fortschrittsanzeigeclickhouse-connect: Der MyScale-Datenbankclient
python3 -m pip install transformers tqdm clickhouse-connect streamlit pandas lmdb torch
# Daten vorbereiten
Beginnen wir mit dem 900k Diffusion Prompts Dataset (opens new window) von Kaggle. Dieser Datensatz umfasst 900.000 Paare von Stable Diffusion-Anweisungen und ihren entsprechenden Bild-URLs. Jedes Paar enthält eine Anweisung des Stable Diffusion-Modells und eine zugehörige Bild-URL.
Beispiel:
| id | prompt | url | width | height | source_site |
|---|---|---|---|---|---|
| 00000d0e-45cb-47b6-9f72-6a481e940d78 | Mann wacht auf, dunkler und ruhiger Raum, kinematografisch ... | Bild-URL | 512 | 512 | stablediffusionweb.com (opens new window) |
Wie in diesem Beispiel zu sehen ist, besteht der Datensatz aus den folgenden sechs Spalten:
- id: Ein eindeutiger Bezeichner für jedes Anweisungs- und Bildpaar
- prompt: Die Anweisung des Bildpaars
- url: Eine URL, die auf das zugehörige Bild der Anweisung verweist
- width: Die Breite des Bildes
- height: Die Höhe des Bildes
- source_site: Das Label des Bildes
Das folgende Bild ist das tatsächliche Bild, das mit diesem Bildpaar verknüpft ist. Es wird durch Klicken auf die Bild-URL abgerufen.

# MyScale-Datenbanktabelle erstellen
Sofern Sie nicht die MyScale-Online-Konsole verwenden, benötigen Sie eine Verbindung zu unserem Datenbank-Backend, um eine Tabelle in MyScale zu erstellen.
Lesen Sie unseren ausführlichen Leitfaden zur Einrichtung eines Python-Clients (opens new window), um eine Verbindung zum MyScale-Datenbank-Backend herzustellen.
Es wird Ihnen viel einfacher fallen, mit MyScale zu arbeiten, wenn Sie mit SQL (Structured Query Language) vertraut sind. MyScale kombiniert strukturierte SQL-Abfragen mit Vektorsuchen, einschließlich der Erstellung von Datenbanktabellen. Mit anderen Worten, das Erstellen einer Vektordatenbanktabelle ist nahezu identisch mit dem Erstellen einer herkömmlichen Datenbanktabelle.
Die folgende SQL-Anweisung beschreibt, wie man in SQL eine Vektortabelle erstellt:
CREATE TABLE IF NOT EXISTS Prompt_text_900k(
id String,
prompt String,
url String,
width UInt64,
height UInt64,
source_site String,
prompt_vector Array(Float32),
CONSTRAINT vec_len CHECK length(prompt_vector) = 512
) ENGINE = MergeTree ORDER BY id;
# Text- und Bildpaare extrahieren, Datensätze erstellen
CLIP (opens new window) gleicht Texte und Bilder ab, um eine leistungsstarke Suche über verschiedene Modi hinweg zu ermöglichen. CLIP kann lernen, Objekte und Szenen in Bildern zu erkennen und den Text zur Analyse des Inhalts verwenden. Dadurch kann es Bilder und Texte mit hoher Genauigkeit und Geschwindigkeit abgleichen und eine schnelle und präzise Suche über mehrere Modi hinweg ermöglichen.
Hier ist ein Beispiel:
import torchimport clipfrom PIL import Image
# Das CLIP-Modell laden
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
# Das Bild laden und vorverarbeiten
# Den Text codieren
text = "Your text here"
text_input = clip.tokenize([text]).to(device)
with torch.no_grad():
text_features = model.encode_text(text_input)
# Die Bild- und Textmerkmale ausgeben
print("Image features shape:", image_features.shape)
print("Text features shape:", text_features.shape)
# Daten in MyScale hochladen
Als nächstes werden die Einbettungen in MyScale hochgeladen und ein Vektorindex erstellt, wie im folgenden Python-Auszug gezeigt:
# Daten aus den Datensätzen hochladen
client.insert("Prompt_text_900k",
data_text.to_records(index=False).tolist(),
column_names=data_image.columns.tolist())
# Vektorindex mit Cosine erstellen
client.command("""
ALTER TABLE Prompt_text_900k
ADD VECTOR INDEX prompt_vector_index feature
TYPE MSTG
('metric_type=Cosine')
""")
# Die MyScale-Datenbank durchsuchen
Wenn ein Benutzer eine Anweisung eingibt, wandeln wir sie in einen Vektor um und verwenden ihn, um die Datenbank abzufragen und die besten n-Anweisungen und ihre entsprechenden Bilder zurückzugeben. Wir verwenden die folgenden Schritte, um die MyScale-Datenbank zu durchsuchen:
Der erste Schritt besteht darin, die Anweisung (Frage) in einen Vektor umzuwandeln, wie im folgenden Code-Snippet angegeben:
question = 'A cat is sleeping on the sofa' emb_query = retriever.encode(question).tolist()Der zweite Schritt besteht darin, eine Abfrage auszuführen, die den Datensatz durchsucht und die besten n-Anweisungen (Texte) und ihre entsprechenden Bilder zurückgibt, wie im folgenden Code-Snippet zu sehen ist:
top_k = 2 results = client.query(f""" SELECT prompt, url, distance(prompt_vector, {emb_query}) as dist FROM Prompt_text_900k ORDER BY dist LIMIT {top_k} """) summaries = {'prompt': [], 'url': []} for res in results.named_results(): summaries['prompt'].append(res["prompt"]) summaries['url'].append(res["url"])
Die Abfrageergebnisse werden im folgenden Code-Snippet beschrieben:
{'prompt':['`two cute calico cats sleeping inside a cozy home in the evening, two multi - colored calico cats`','`two cats sleeping by the window Chinese new year digital art painting by makoto shinkai`'],
'url': ['`https://image.lexica.art/full_jpg/c6fc8242-86b6-4a2c-adee-3053bb345147`','https://image.lexica.art/full_jpg/06c4451c-ce40-4926-9ec7-0381f3dcc028']}
Mit den URLs, die auf die Bilder verweisen:


# Neue Bilder generieren
Mit der GPT4-API können wir neue Anweisungen mit GPT4 basierend auf den aus dieser Abfrage zurückgegebenen Daten erstellen, wie im folgenden Code-Snippet gezeigt:
system_message = f"""
Please provide a more native-sounding rewrite of the user-input
image generation prompt based on the following description
{summaries}
"""
Mit diesen neuen Anweisungen werden die folgenden Bilder generiert:


Die Bildsuche kann auch mit einer ähnlichen Pipeline durchgeführt werden.
# Fazit
Personalisierte Bilder stehen im Mittelpunkt des AIGC-Trends. Mit Stable Diffusion und LLMs können Sie visuell fesselnde Inhalte erstellen. Mit MyScale können Sie wie in diesem Artikel beschrieben geeignete Anweisungen finden, indem Sie auf seine umfassende Vektordatenbank zugreifen. Benutzer können mit MyScale in Verbindung mit Stable Diffusion und LLMs Herausforderungen bewältigen, Kreativität verfeinern und mit AIGC interagieren, was zu einzigartigen KI-generierten Inhalten führt.