
# Vector Index Capacity Planning
When preparing to create a MyScale cluster, selecting the right configuration is crucial, considering your vector capacity and performance needs.
Configuring MyScale clusters is straightforward, involving two key parameters: pod size and replica count. These parameters are easily adjustable to adapt to evolving requirements.
# Factors to Consider
To determine the best MyScale cluster setup, consider:
- Type of vector index
- Number of vectors
- Dimensions of vectors
- Queries per second (QPS) requirement
We advocate using MyScale's MSTG algorithm for vector indexing, known for
exceptional performance and vector density. Our capacity and performance
guidelines are based on MSTG (see our blog
post (opens new window) for
detailed benchmarks).
Other metadata have minimal impact on vector capacity, but QPS could be influenced if queries include additional metadata. To optimize QPS in such scenarios, MyScale provides efficient filter search (opens new window).
# Pod Sizes
MyScale combines algorithmic innovations, like MSTG, with system
engineering to achieve high vector density and performance. We offer a single
pod type, with size options like x4 providing quadruple the capacity and CPU
performance of an x1 pod.
Pod sizes available are x1, x2, x4, x8, x16, and x32. Use our
Price Estimator on the pricing page (opens new window) to find
the best pod size for your needs.
Following are some estimated capacity and performance benchmarks for the x1 pod.
# Capacity
Table 1: Maximum Vector Capacity per Pod by Dimension
| Pod Size | Dimensions | Max Capacity |
|---|---|---|
| x1 | 512 | 7,500,000 |
| 768 | 5,000,000 | |
| 1024 | 3,750,000 | |
| 1536 | 2,500,000 |
Opt for a larger pod size for increased vector capacity.
# QPS
Table 2: QPS Estimates for 5M Vectors at 768 Dimensions by top_k*
| Pod Size | top_k 10 | top_k 100 |
|---|---|---|
| x1 | 152 | 117 |
*Based on MSTG index with alpha=3 (default setting). See full
benchmarks (opens new window) for more.
Boost QPS by adding replicas.
# Replicas
Replicas enhance cluster availability and QPS. A cluster's total QPS roughly equals the QPS of a single pod multiplied by the number of replicas. Note that replicas do not increase vector capacity.
# Examples
# Example 1: ChatData Application
In our ChatData (opens new window) app, we manage
an arXiv papers dataset with approximately 2.25 million vectors at 768
dimensions. A single x1 pod, supporting up to 5 million vectors at this
dimension, suffices for this dataset.
# Example 2: Large-Scale Image Search
Consider a large scale image search application requiring 80 million vectors at 512 dimensions. Referring to the Capacity section, an x16 pod is needed. For higher availability and QPS, increase the replica count to 2 or 3.
Why `x16` Pod?
An x1 pod supports 7.5 million vectors at 512 dimensions. Given the
requirement of 80 million vectors, x16 is the suitable choice among our pod
sizes of x1, x2, x4, x8, x16, and x32.
# Visualized Usage
The cluster monitoring page features a chart displaying the memory usage by the loaded vector index relative to total available memory. This tool helps users track vector usage and plan pod size upgrades before reaching capacity limits.
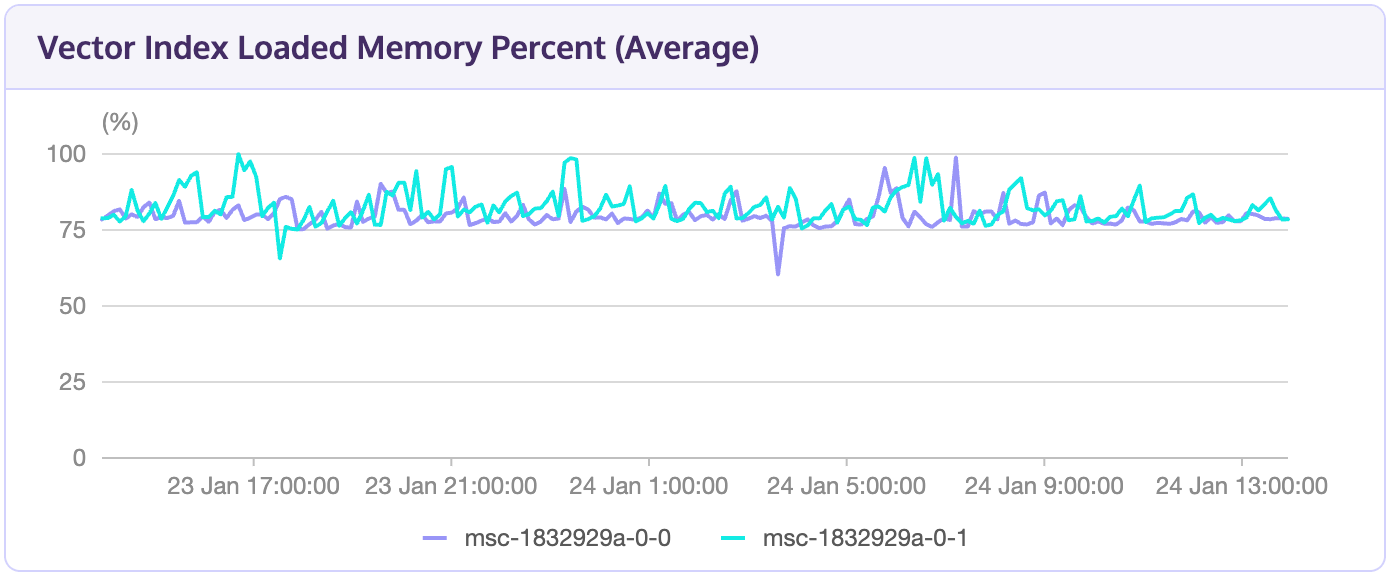
We employ the LRU algorithm for in-memory vector index management. Exceeding a pod's vector limit results in some indexes being unloaded from memory. Re-loading these indexes for subsequent searches may reduce QPS or increase query latency. In such cases, consult the aforementioned chart and consider increasing your pod size accordingly.