
Retrieval Augmented Generation (RAG) improves the performance of LLMs by connecting them with external knowledge bases. It has a lot of advantages, including lower cost/resources, optimizing LLM on particular domain knowledge, data security, etc. RAG is relatively a newer technology [1] in the context of deep learning, yet its usage is immense and increasing every day.
As RAG’s usage is on the rise, it's continuously improving too. As limitations are being discovered in the RAG systems, researchers have been identifying ways to improve their performance as well. There are some key areas where RAG can be improved in the whole pipeline:
Topics:
Query Rewriting in Advanced RAG
Today, we will talk about query improvement.
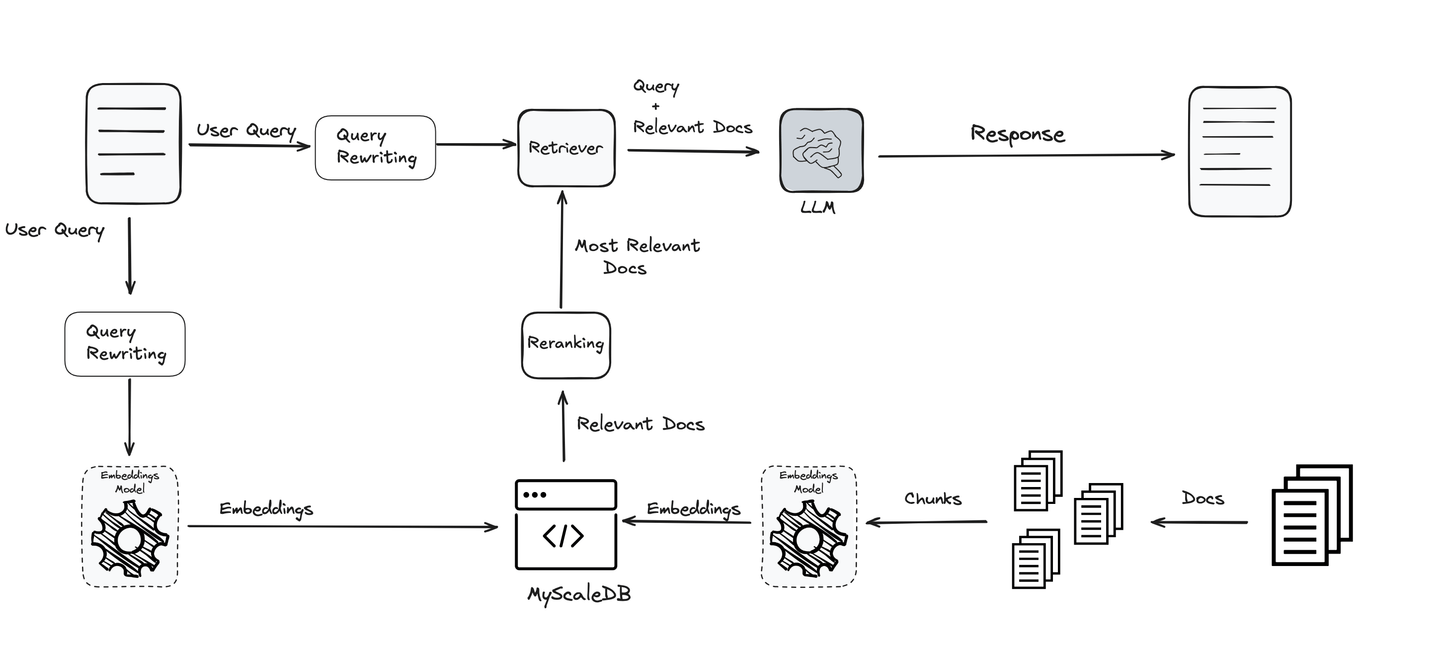
Add query rewriting step
Query is one of the most important parts of the entire RAG pipeline. Whatever you ask for sets the direction, and the LLM along with all other tools works to bring you information based on that. If the query isn’t clear or well-optimized, even the best systems can fall short. That’s why improving and refining queries is key to getting accurate and meaningful results.
Keeping this importance in mind, various techniques are used to optimize and clarify queries to ensure the end user receives the best and most relevant results. These techniques make the system more effective and reliable, supporting every stage of the RAG pipeline.
# Query Rephrasing
A query written by a (mostly naïve) user can hardly be judged from an LLM’s perspective and as experience has shown, these queries have a lot of room for improvement. LLMs or any retrieval systems can also be sensitive to specific words, hence rephrasing the queries can optimize queries for better understanding.
Example:
To illustrate this further, we quote an example from [2]. The original query they provided was:
A car-manufacturing factory is considering a new site for its next plant. Which of the following would community planners be most concerned with before allowing the plant to be built?
This query was too complex to be precisely understood by the LLM and it was unable to answer it. After employing the rewriter, the rephrased query is:
What would community planners be most concerned with before allowing a car-manufacturing factory to be built?
It works perfectly well and returns the correct answer too.
There are a number of techniques for rewriting a query. Some replace them with synonyms, some append the metadata (opens new window), some are focused on improving the grammar, and some expand the query into a more meaningful form (even some methods generate permutations of the original query (opens new window)), etc. Interestingly, some of these methods involve LLMs (opens new window) themselves. So it is a bit of recursive use of LLMs where we use them to improve the input to another (or the same) LLM.
# Query Normalization
Query normalization refers to simple methods for fixing the original query’s grammar and spelling, etc. Similarly, some pre-processing like lowercasing or removing stop words can also be employed for query normalization.
For example, “Who was the author of Brothers Karamazov?” is much easier to comprehend than “who wrote broter karamov” as you note the misspellings in the latter query.
Here, it should be noted that LLMs are powerful transformer models that are usually capable of understanding sentences without too much normalization. Therefore, a balance needs to be struck between normalizing inputs and overdoing it.
# Query Expansion
Since we aren’t sure whether a query will perform well or not in most cases, a common method is to create multiple permutations of a query and return results for all of them. While we have a number of classical paraphrasing methods too, LLMs itself are really good at them, as you would have noticed before.
Here is an example (originally taken from LangChain (opens new window)) using LangChain and OpenAI’s GPT-4 model.
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain.output_parsers import PydanticToolsParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
class ParaphrasedQuery(BaseModel):
"""You have performed query expansion to generate a paraphrasing of a question."""
paraphrased_query: str = Field(
...,
description="A unique paraphrasing of the original question.",
)
system = """You are an expert at converting user questions into database queries. \
You have access to a database of tutorial videos about a software library for building LLM-powered applications. \
Perform query expansion. If there are multiple common ways of phrasing a user question \
or common synonyms for key words in the question, make sure to return multiple versions \
of the query with the different phrasings.
If there are acronyms or words you are not familiar with, do not try to rephrase them.
Return at least 3 versions of the question."""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.25)
llm_with_tools = llm.bind_tools([ParaphrasedQuery])
query_analyzer = prompt | llm_with_tools | PydanticToolsParser(tools=[ParaphrasedQuery])
Having built the query expander, we can now use it. For example:

Query expansion results
As you can see, it provides nice permutations (we can increase the number of permutations further if we would like to) which can be helpful while feeding the LLM.
# Contextual Adaptation
The process of contextual adaptation involves adjusting a query to better suit the specific context in which it is being asked. This is often achieved by leveraging reinforcement learning (RL), which helps optimize the query's phrasing based on contextual information. One method employs a small language model (LM) as a query rephraser, using external sources, such as internet data, to enrich the query's context. The RL component then fine-tunes this adaptation by learning from feedback on how well the rephrased query performs in the given context. This approach has been explored in various research studies, such as those referenced in [2] and [3], demonstrating its effectiveness in improving query relevance and performance.
# Query Decomposition
Queries often contain two (or more) diverse queries, which makes it harder for the LLMs to understand them. Plus, LLMs are quite prone to irrelevant context [4]. For example, in the classical example of Jessica’s age, the introduction of an unrelated statement (one in red) will probably confuse the LLM.

An example of inefficient query understanding (taken from [4]) leads to the need for query decomposition. The underlined statement in the red unnecessarily complicates the query and makes it extra difficult for the LLM to understand
A better solution here would be to decompose the query into something like:
“Jessica is six years older than Claire. In two years, Claire will be 20 years old.” “Twenty years ago, the age of Claire’s father is 3 times of Jessica’s age” “How old is Jessica now?”
And probably we can even drop the second statement too.
# Challenges in Query Decomposition
Query decomposition has some advantages like better clarity and helping LLMs reason in a step-by-step manner. However, there are some challenges associated with query decomposition too, like:
- Over-Splitting: Decomposing queries too much can dilute context, leading to less relevant results.
- Combining Results: Aggregating results from sub-queries can be challenging, especially if they are contradictory or incomplete.
- Query Dependency: Some queries depend on results from earlier steps, requiring iterative processes.
- Cost and Latency: Breaking queries into multiple parts increases the number of retrieval and computation steps, which can be computationally expensive.
Although query decomposition is promising, but as we saw in the challenges being faced, it still has a lot of room for improvement. If you are in doubt about whether to use it or not, prefer to err on the safer side, especially to save the cost.
# Embeddings Optimization
Embeddings are usually generated using the common NLP models like BERT (opens new window) or Titan (opens new window), etc. These embeddings are pretty good for a number of applications but often they need to be optimized for better understanding. For these reasons, some benchmarks like Massive Text Embedding Benchmark, MTEB [5] have also been proposed for checking how well embeddings perform across 8 diverse tasks like classification, clustering and summarization.
“We find there to be no single best solution, with different models dominating different tasks.” – MTEB paper
As MTEB also discovers correctly, there is no single best solution across all the tasks: some models are good for summarization, some for classification and so on. And it's not universal across all the datasets either as models perform better on some datasets for the same task while showing sub-par results on the others.
# Hypothetical Document Embedding (HyDE)
In 2022, researchers proposed a novel zero-shot method. [6] This unique method is based on the concept of making a fake document and then using its embeddings to find similar (real) documents in the embedding space. HyDE is gaining popularity as a tool for query optimization in RAG. HyDE’s methodology can be summarized as follows:
- Generate hypothetical document
- Compute its embedding
- Use embedding to query the vector database
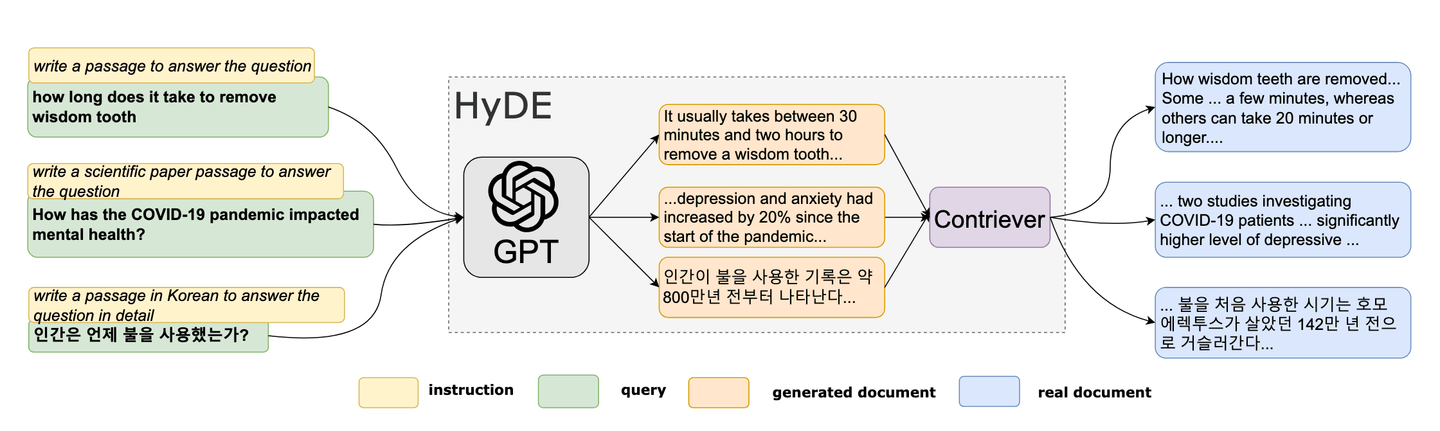
Reference: HyDE paper [6]
# Hypothetical Document Creation
As the first step, we take a query and use it to generate a hypothetical document. It could be generated as simply as prompting the LLM to “Make a document which answers this question” as we will shortly see in the example.
# Embedding Computation
We can use any model or service – MyScale also provides its own EmbedText() method – to compute these embeddings. Once these (hypothetical query) embeddings are available, we can use them to query the vector database.
Once we get the most similar text from the hypothetical query, we pass them with the (original) query to the LLM for response generation.
# Example of HyDE
For example, some embeddings are stored in the DocEmbeddings table in MyScale. We can query them using – say Cosine similarity – for the top-10 similar documents as follows:
Step 1: Hypothetical Document Generation
As a first step, we take the query and use it to generate the hypothetical document using OpenAI’s GPT-4 (mini) model (for most of the tasks, GPT4-mini is good enough and saves money).
from openai import OpenAI
openai_client = OpenAI(api_key='sk-xxxxx')
def Make_HyDoc(query):
response = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "system", "content": "Make a document that answers the question:"},
{"role": "user", "content": f"{query}"}],
max_tokens=100
)
return response.choices[0].message
Now, we have this function so we can use it to generate hypothetical documents based on our query(ies).
Step 2: Embeddings Computation
To calculate the embeddings, we will use MyScale’s built-in EmbedText() to directly calculate the embeddings.
service_provider = 'OpenAI'
hypoDoc = Make_HyDoc("What was the solution proposed to farmers problem by Levin?")
parameters = {'sampleString': hypoDoc, 'serviceProvider': service_provider}
x = client.query("""
SELECT EmbedText({sampleString:String}, {serviceProvider:String}, '', 'sk-*****', '{"model":"text-embedding-3-small", "batch_size":"50"}')
""", parameters=parameters)
input_embedding = x.result_rows[0][0]
Step 3: Using Embedding to Query Vector DB
Now, we have the embedding in the input_embedding , we can compare it with the vectors already stored in a table (DocEmbeddings in this case) using the simple SQL query.
SELECT
id,
title,
content,
cosineDistance(embedding, input_embedding) AS similarity
FROM
DocEmbeddings
ORDER BY
similarity ASC
LIMIT
10;
We can run it in Python and display as a dataframe.
import pandas as pd
query = f"""
SELECT
id,
sentences,
cosineDistance(embeddings, {input_embedding}) AS similarity
FROM
DocEmbeddings
LIMIT
10
"""
df = pd.DataFrame(client.query(query).result_rows)
And it returns the most relevant documents:

HyDE results

# Conclusion
RAG is a powerful and cost-effective tool that enhances the capabilities of LLMs, but it also has its limitations. In this blog post, we focused on improving queries as part of the RAG process. We explored various techniques such as rephrasing (often using LLMs), query decomposition, optimizing the quality of embeddings, and HyDE. While these methods are valuable, they represent just one aspect of the RAG pipeline. There are additional ways to enhance the entire RAG generation process. In the next post, we will delve into chunking strategies and discuss how data can be chunked into different types depending on the use case.
# References
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS. https://arxiv.org/abs/2005.11401
- Ma, X., Gong, Y., He, P., Zhao, H., & Duan, N. (2023). Query Rewriting for Retrieval-Augmented Large Language Models. EMNLP. https://arxiv.org/abs/2305.14283
- Anand, A., V, V., Setty, V., & Anand, A. (2023). Context Aware Query Rewriting for Text Rankers using LLM. ArXiv. https://arxiv.org/abs/2308.16753
- Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H. Chi, Nathanael Schärli, and Denny Zhou. Large language models can be easily distracted by irrelevant context. ICML, 2023.
- Muennighoff, N., Tazi, N., Magne, L., & Reimers, N. (2022). MTEB: Massive Text Embedding Benchmark. ArXiv. https://arxiv.org/abs/2210.07316
- Gao, L., Ma, X., Lin, J., & Callan, J. (2022). Precise Zero-Shot Dense Retrieval without Relevance Labels. ArXiv. https://arxiv.org/abs/2212.10496



