
The OpenAI Assistants API empowers developers to effortlessly create robust AI assistants within their applications. This API includes the following features/functionality in that it:
- Eliminates the need to handle conversation history,
- Provides entry to OpenAI-hosted tools like Code Interpreter and Retrieval, and
- Enhances function-calling for third-party tools.
In this article, we'll look at the Assistants API and how we can build a custom knowledge base using vector databases like MyScale and link it to Assistants API to achieve greater flexibility, accuracy, and cost savings.
![]()
![]()
# What is an OpenAI Assistant?
An OpenAI assistant is an automated workflow that can leverage Large Language Models—LLMs, tools, and knowledge bases to answer user queries. And as highlighted above, you must use the Assistants API to create an OpenAI assistant.
Let's start by taking a look inside the Assistants API:
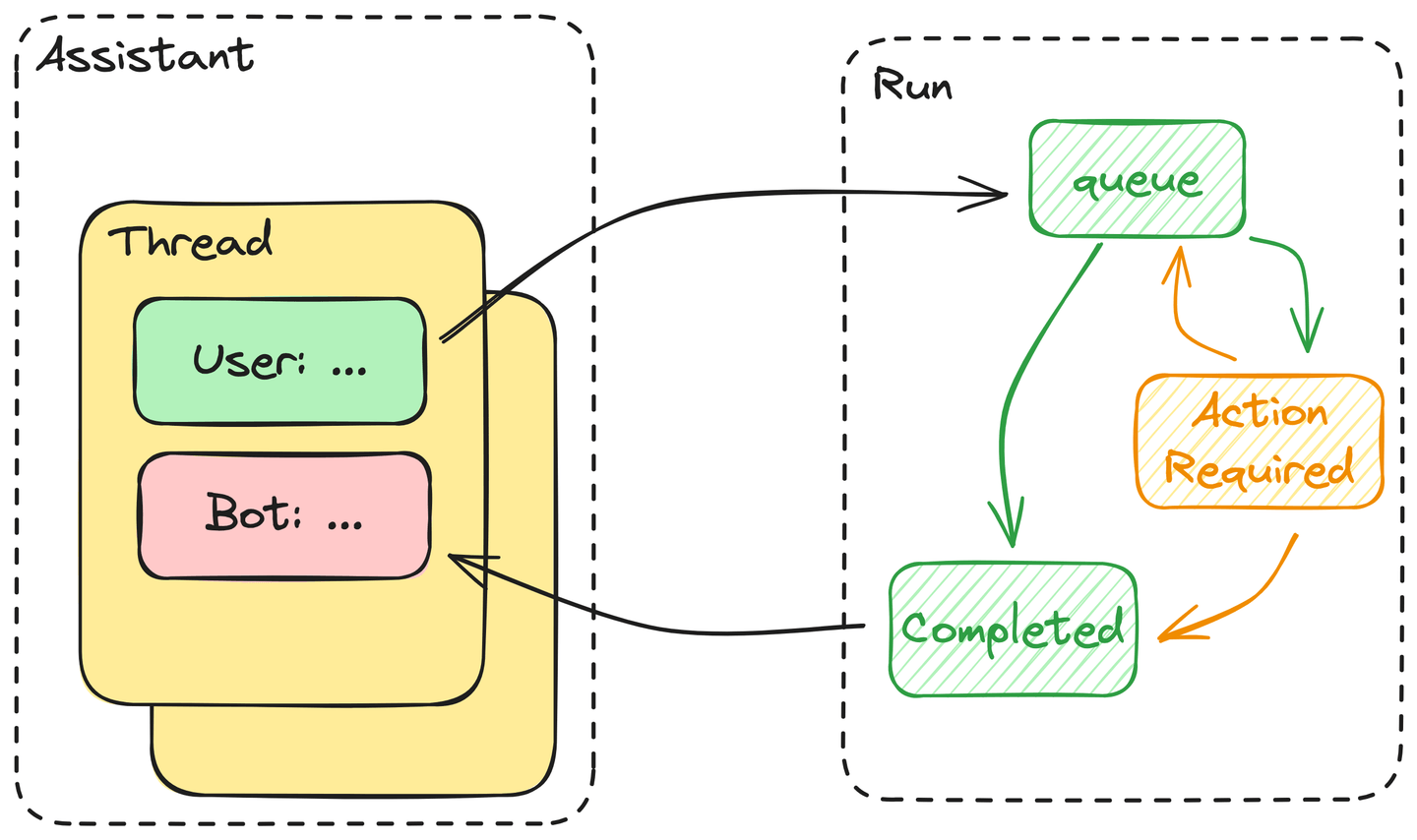
# Components
The Assistants API consists of the following core components:
- Assistant: An assistant contains the definition of the tools it can use, files it can read, and the system prompts it will attach to the threads created inside it
- Thread: Threads are made up of messages that control the assistant's conversations.
- Messages: Messages are the basic elements that make up a thread and contain all texts, including the user’s inputs and generated answers.
- Run: Users must launch a run every time they request an answer from the assistant. In practice, the assistant executes all messages inside a thread. The user must submit the tool’s output to the run if any actions are required.
# Launching a Run Using Assistants API's Tools
It is an indication of Artificial Intelligence because these assistants know how to use the tools they are given via API calls. To this end, OpenAI has proven that GPT can turn user requests into formatted usage tools via a function call passed to the API. Therefore, in human terms, this is equivalent to knowing how to use a tool.
Moreover, these assistants can decide when and which tools should be used during the execution of a single run. If we simplify this process, we will find that:
- All messages inside a thread will be queued once the user launches the run. These messages will then be picked from the queue once resources are available to process them.
- The assistant will then decide if it will use any of the tools provided in the assistant’s definition. If so, the assistant will enter an
ActionRequiredstate—the tool's output blocks it until the required action is provided. If not, the assistant will immediately return the answer and mark this run asCompleted. - The assistant will wait for output for tool callings until it exceeds the timeout threshold. If everything goes according to plan, the assistant will append the tool’s output to the thread, return the answer, and mark the run as completed, as described above.
In summary, the execution of a run is basically an automaton driven by an LLM.
# Linking MyScale to OpenAI's Assistant
MyScale has an SQL interface—a significant advantage for automated queries. Additionally, LLMs are good at writing code, including SQL. Thus, we have combined the SQL WHERE filters with a vector search—as described in our function call documentation (opens new window).
Let’s now consider expanding this function call into a link between MyScale and OpenAI’s Assistants API.
# Never Use Assistant's Retrieval Tool
OpenAI includes a Retrieval tool with the Assistants API that costs $0.2 / (GB * num_assistants) per day. Taking the Arxiv dataset, for example: its data is circa 24GB with the embedding. This will cost you $5 every day ($150 monthly) for just one assistant. Also, you never know what the retrieval performance will be for accuracy and time consumption. Only GPT knows whether it contains valuable knowledge or not. Consequently, an external vector database is a must if you have tons of data to store and search.
# Defining a Knowledge Base as a Tool for an Assistant
According to the Assistants API's official documentation, you can create an assistant using OpenAI().beta.create_assistants.create. Here is an example if you want to build an assistant with an existing knowledge base:
from openai import OpenAI
client = OpenAI()
assistant = client.beta.assistants.create(
name="ChatData",
instructions=(
"You are a helpful assistant. Do your best to answer the questions. "
),
tools=[
{
"type": "function",
"function": {
"name": "get_wiki_pages",
"description": (
"Get some related wiki pages.\n"
"You should use schema here to build WHERE string:\n\n"
"CREATE TABLE Wikipedia (\n"
" `id` String,\n"
" `text` String, -- abstract of the wiki page. avoid using this column to do LIKE match\n"
" `title` String, -- title of the paper\n"
" `view` Float32,\n"
" `url` String, -- URL to this wiki page\n"
"ORDER BY id\n"
"You should avoid using LIKE on long text columns."
),
"parameters": {
"type": "object",
"properties": {
"subject": {"type": "string", "description": "a sentence or phrase describes the subject you want to query."},
"where_str": {
"type": "string",
"description": "a sql-like where string to build filter.",
},
"limit": {"type": "integer", "description": "default to 4"},
},
"required": ["subject", "where_str", "limit"],
},
},
}
],
model="gpt-3.5-turbo",
)
The exposed function has three inputs: subject, where_str, and limit, matching the implementation of the MyScale vectorstore in LangChain (opens new window).
As described in the prompt:
subjectis the text used for the vector search andwhere_stris the structured filter written in an SQL format.
We also add the table schema to the tool description, helping the assistant write filters using the correct SQL functions.
# Injecting External Knowledge from MyScale into the Assistant
To inject external knowledge from MyScale into our assistant, we need a tool to retrieve this knowledge based on the arguments generated by the assistant. By way of an example, we minimized the implementation to the MyScale vector store, as the following code shows:
import clickhouse_connect
db = clickhouse_connect.get_client(
host='msc-950b9f1f.us-east-1.aws.myscale.com',
port=443,
username='chatdata',
password='myscale_rocks'
)
must_have_cols = ['text', 'title', 'views']
database = 'wiki'
table = 'Wikipedia'
def get_related_pages(subject, where_str, limit):
q_emb = emb_model.encode(subject).tolist()
q_emb_str = ",".join(map(str, q_emb))
if where_str:
where_str = f"WHERE {where_str}"
else:
where_str = ""
q_str = f"""
SELECT dist, {','.join(must_have_cols)}
FROM {database}.{table}
{where_str}
ORDER BY distance(emb, [{q_emb_str}])
AS dist ASC
LIMIT {limit}
"""
docs = [r for r in db.query(q_str).named_results()]
return '\n'.join([str(d) for d in docs])
tools = {
"get_wiki_pages": lambda subject, where_str, limit: get_related_pages(subject, where_str, limit),
}
Secondly, we need a new thread to hold our input:
thread = client.beta.threads.create()
message = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content="What is Ring in mathematics? Please query the related documents to answer this.",
)
client.beta.threads.messages.list(thread_id=thread.id)
Runs are created from threads and are linked to a specific assistant. Different runs can have different assistants. As a result, a thread can contain messages generated using different tools.
run = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id,
instructions= "You must use query tools to look up relevant information for every answer to a user's question.",
)
It is essential to constantly check this run’s status and provide outputs for every function the assistant calls.
import json
from time import sleep
while True:
run = client.beta.threads.runs.retrieve(thread_id=thread.id, run_id=run.id)
if run.status == 'completed':
print(client.beta.threads.messages.list(thread_id=thread.id))
# if the run is completed, then you don't need to do anything at all
break
elif len(run.required_action.submit_tool_outputs.tool_calls) > 0:
print("> Action Required <")
print(run.required_action.submit_tool_outputs.tool_calls)
# if the run requires actions, you will need to run tools and submit the outputs
break
sleep(1)
tool_calls = run.required_action.submit_tool_outputs.tool_calls
outputs = []
# calling tools for every action required
for call in tool_calls:
func = call.function
outputs.append({"tool_call_id": call.id, "output": tools[func.name](**json.loads(func.arguments))})
if len(tool_calls) > 0:
# submit all pending outputs
run = client.beta.threads.runs.submit_tool_outputs(
thread_id=thread.id,
run_id=run.id,
tool_outputs=outputs
)
Once the outputs are submitted, the run will reenter the queued state.
Note: We also need to check this run’s status constantly.
from time import sleep
while client.beta.threads.runs.retrieve(
thread_id=thread.id,
run_id=run.id
).status != 'completed':
print("> waiting for results... <")
sleep(1)
messages = client.beta.threads.messages.list(thread_id=thread.id).data[0].content[0].text.value
print("> generated texts <\n\n", messages)
Finally, this example demonstrates how to use the Assistants API.

# Conclusion
In conclusion, integrating the MyScale vector database as an external knowledge base with OpenAI’s Assistants API opens up new horizons for developers seeking to enhance their AI assistants. By seamlessly incorporating this valuable resource, developers can leverage the power of MyScale alongside OpenAI-hosted tools like Code Interpreter and Retrieval.
This synergy not only streamlines the development process but also empowers AI assistants with a broader knowledge base, providing users with a more robust and intelligent experience. As we continue to make advancements in the study of Artificial Intelligence, such integrations mark a significant step toward creating versatile and capable virtual assistants.
Join us on Discord (opens new window) today to share your thoughts on the Assistants API!



