
Large language models (LLMs) have brought immense value with their ability to understand and generate human-like text. However, these models also come with notable challenges. They are trained on vast datasets that demand extensive cost and time. The extensive cost and time required to train these models on large datasets make it nearly impossible to retrain them regularly. This limitation means they often lack updates with the latest data, leading to potential inaccuracies when queried about unfamiliar topics. This phenomenon is known as "Hallucination," and it can deteriorate the performance of applications and raise concerns about their reliability and authenticity.
To overcome hallucination, several techniques are employed, with Retrieval Augmented Generation (RAG) being the most widely used due to its efficiency and performance (opens new window).
I’ll show how to design a complete advanced RAG system that can be used in production environments.
# What is Retrieval Augmented Generation
RAG is the most widely used technique to overcome hallucination. It ensures that LLMs remain up to date with the most recent information and provide better responses. It dynamically retrieves relevant external data during the model's response generation phase. This approach allows the LLM to access the most current information without the need for frequent retraining. It makes the model's responses more accurate and contextually appropriate.
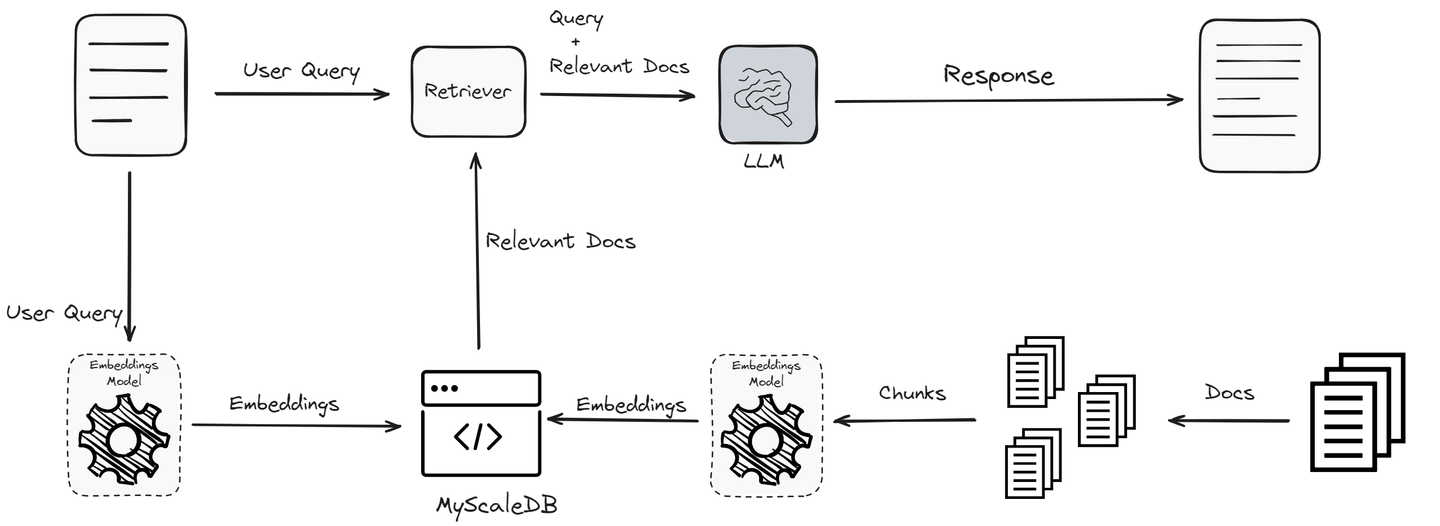
The process begins with a user query, which is transformed into embeddings via an embedding model to capture its semantic essence. These embeddings then undergo a similarity search against vectors in a knowledge base or vector database to identify the most relevant information. The top “K” results from this search are integrated as additional context into the LLM.
By processing both the original query and this supplementary data, the LLM is equipped to generate more accurate and contextually relevant responses. This not only mitigates the issue of hallucinations but also ensures the model's outputs remain up to date and reliable without frequent retraining.
Related Articles: How does RAG works (opens new window)
# What is LlamaIndex
LlamaIndex (opens new window), previously known as the GPT Index, acts like glue that helps you connect LLMs and knowledge bases. It provides some built-in methods to fetch data from different sources and use it in your RAG applications. This includes a variety of file formats, such as PDFs and PowerPoints, as well as applications like Notion and Slack and even databases like Postgres and MyScaleDB.
LlamaIndex provides important tools that help in collecting, organizing, retrieving and integrating data with various application frameworks. It makes your data easier to access and use, allowing you to build powerful, customized LLM applications and workflows.
Some of the main components of LlamaIndex include:
- Data connectors: These allow LlamaIndex to access a variety of data sources. Whether connecting to a local file system, a cloud-based storage service, or a database, these connectors facilitate the retrieval of necessary information.
- Index: The Index in LlamaIndex is a crucial component that organizes data in a way that makes it quickly accessible. It categorizes the information from all connected sources into a structured format that is easy to search through. This helps speed up the retrieval process and ensures that the most relevant information is available for the LLM to use when needed.
- Query engine: This component is designed to efficiently search through the connected data sources. It processes your queries, finds relevant information and retrieves it so that the LLM can use it for generating responses.
Each component of LlamaIndex plays a key role in enhancing the capabilities of RAG applications by ensuring that they can access and use a wide range of data efficiently.
# An Overview of MyScaleDB
MyScaleDB (opens new window) is an open source SQL vector database specially designed and optimized to manage large volumes of data for AI applications. It's built on top of ClickHouse (opens new window), a SQL database, combining the capacity for vector similarity search with full SQL support.
Unlike specialized vector databases, MyScaleDB seamlessly integrates vector search algorithms with structured databases, allowing both vectors and structured data to be managed together in the same database. This integration offers advantages like simplified communication, flexible metadata filtering, support for SQL and vector joint queries (opens new window), and compatibility with established tools typically used with versatile general-purpose databases.
The integration of MyScaleDB in RAG applications enhances RAG applications by enabling more complex data interactions, directly influencing the quality of generated content.
# RAG with LlamaIndex and MyScaleDB: a Step-by-Step Guide
To build the RAG application, first we need to create an account (opens new window) on MyScaleDB that will be used as a knowledge base. MyScaleDB offers every new user free storage for up to 5 million vectors, so no initial payment is required.
Once you have created your account, go to the homepage and click on "+ New Cluster" in the top right corner. This will open a dialogue box like this:
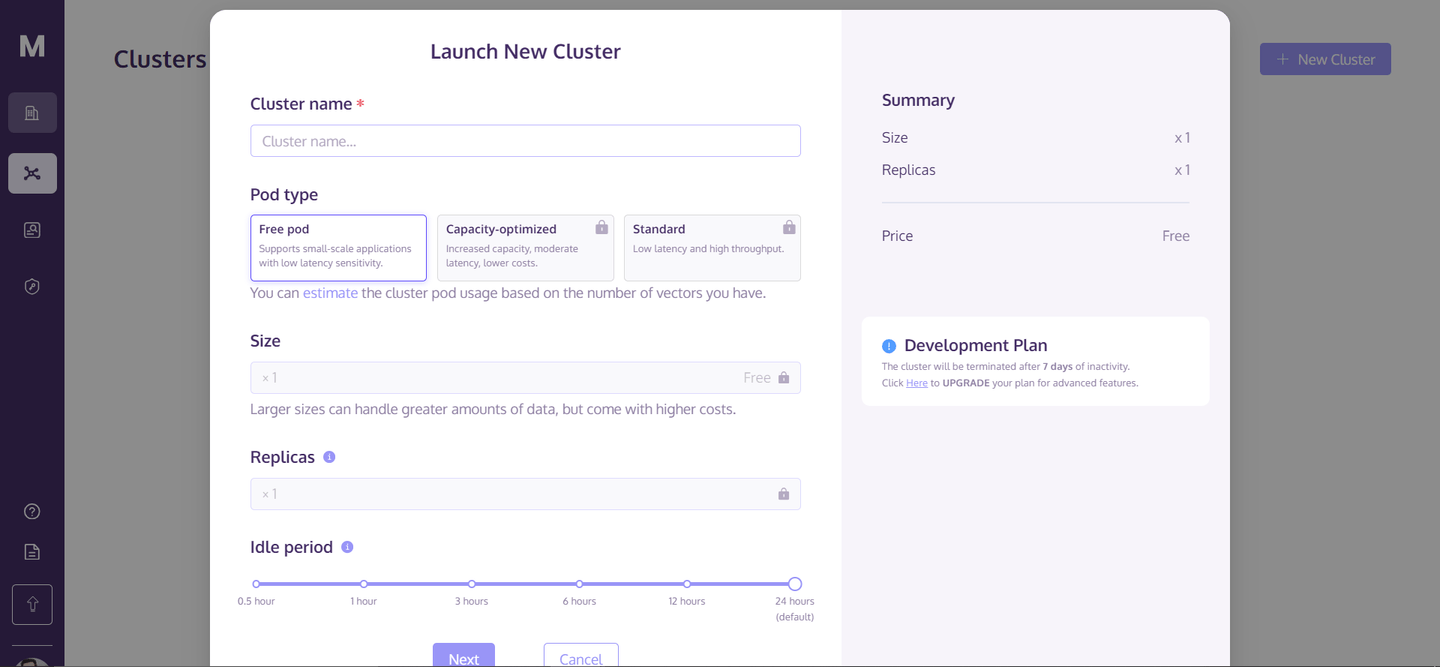
Enter the name of the cluster and click “Next.” It will take a few seconds to initialize your cluster and after that, you can access it.
To access the cluster, you can go back to your MyScaleDB profile and hover over the three vertically aligned dots below the "Actions" text, and click on the connection details.
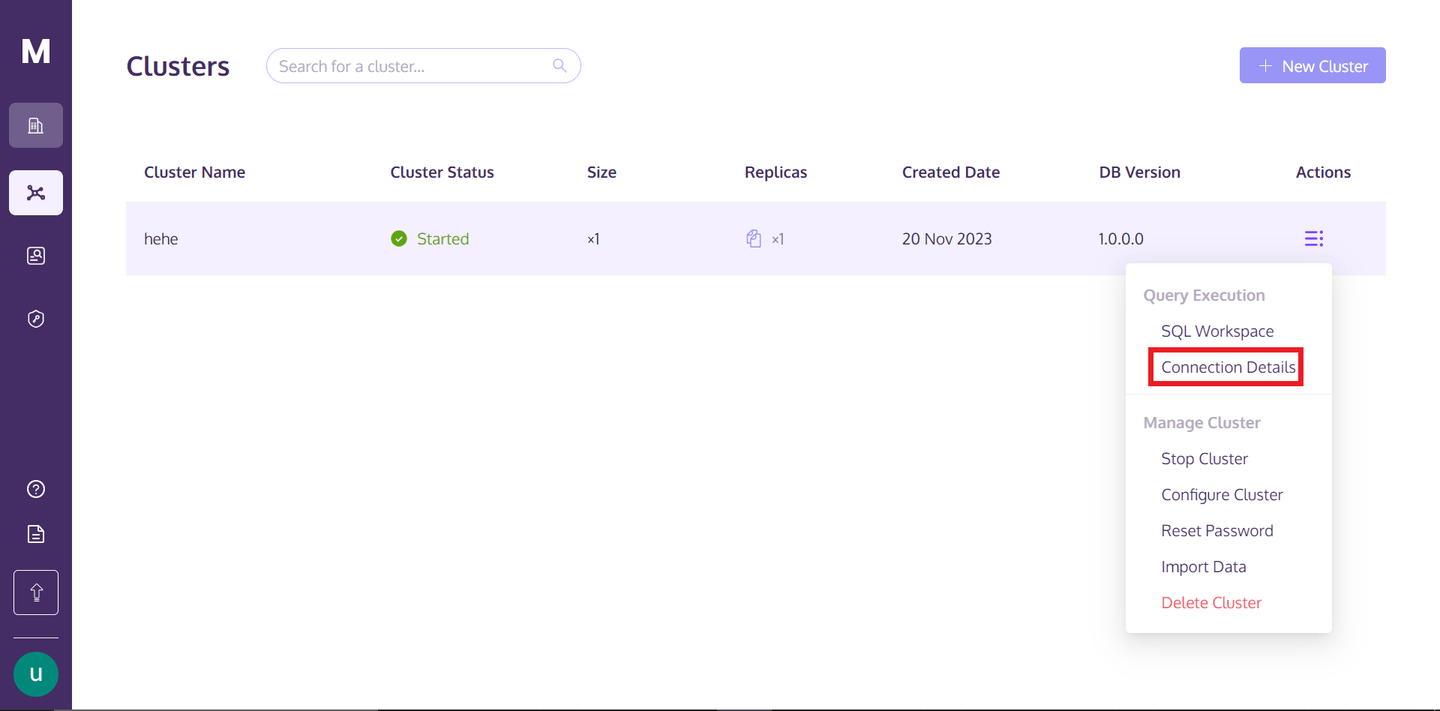
Once you click on the "Connection Details," you will see the following box:
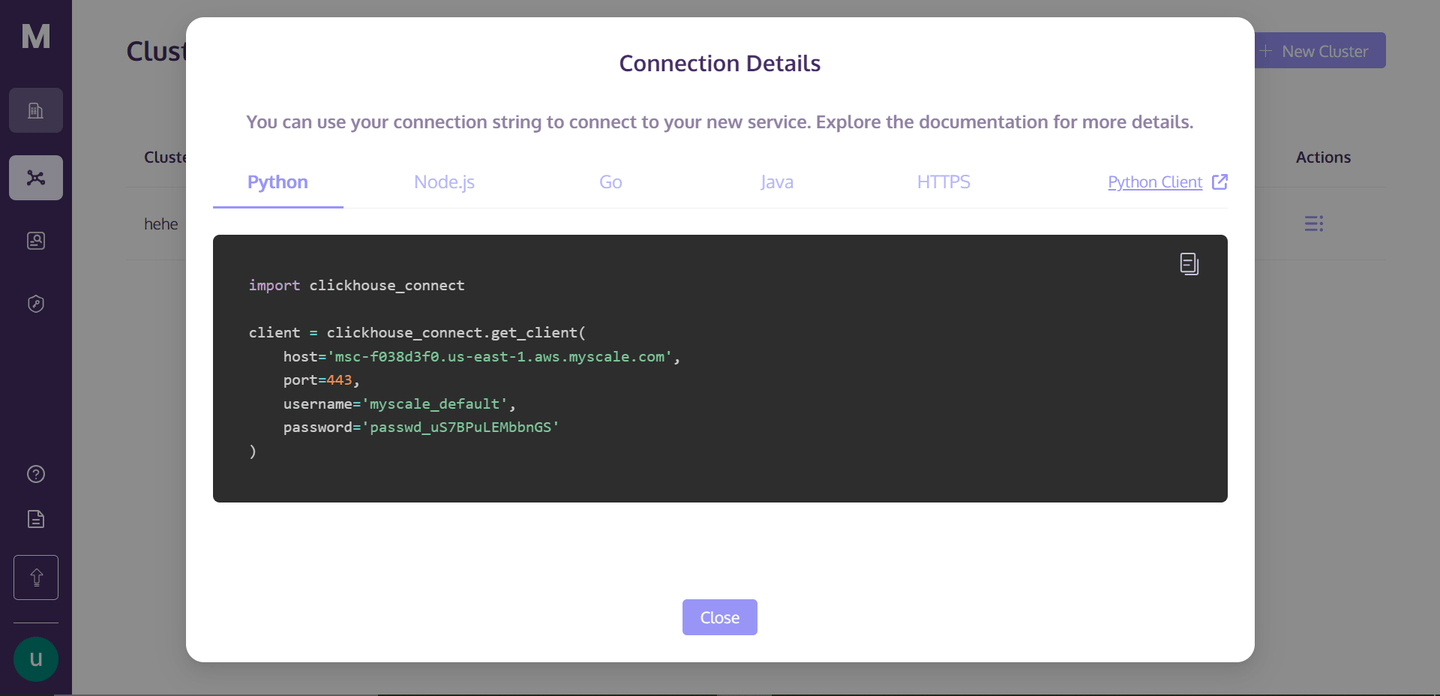
These are the connection details that you need to connect to the cluster. Just create a Python notebook file in your directory, and we will start building our RAG app.

# Setting up the Environment
To install the dependencies, open your terminal and enter the command:
pip install -U llama-index clickhouse-connect llama-index-postprocessor-jinaai-rerank llama-index-vector-stores-myscale
This command will install all the required dependencies. Here we use Jina Reranker (opens new window), whose algorithm significantly improves the search results, with a more than 8% increase in hit rate and a 33% increase in mean reciprocal rank.
# Establishing a Connection with the Knowledge Base
First, you need to establish a connection with MyScale vector DB. For this you can copy the details from the “Connection Details” page and paste them like this:
import clickhouse_connect
client = clickhouse_connect.get_client(
host='your-host',
port=443,
username='your-user-name',
password='your-password-here'
)
It will establish a connection with your knowledge base and create an object.
# Downloading and Loading Data
Here, we will use a Nike product catalog dataset. This code will first download the .pdf and save it locally. Then, it will load the .pdf using LlamaIndex reader.
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
import requests
url = '<https://niketeam-asset-download.nike.net/catalogs/2024/2024_Nike%20Kids_02_09_24.pdf?cb=09302022>'
response = requests.get(url)
with open('Nike_Catalog.pdf', 'wb') as f:
f.write(response.content)
reader = SimpleDirectoryReader(
input_files=["Nike_Catalog.pdf"]
)
documents = reader.load_data()
# Categorizing the Data
This function categorizes the documents into different categories. We will use it as we write some filtered queries on the entire knowledge base. By categorizing documents, targeted searches can be performed, significantly improving the efficiency and relevance of retrieval in the RAG system.
def analyze_and_assign_category(text):
if "football" in text.lower():
return "Football"
elif "basketball" in text.lower():
return "Basketball"
elif "running" in text.lower():
return "Running"
else:
return "Uncategorized"
# Create an Index
Here we will load the data into a vector store provided by MyScaleVectorStore. The metadata for each document is added first and then added to the vector store. Creating an index facilitates quick and efficient search operations. By indexing the data, the system can perform fast vector-based searches, which are essential for retrieving relevant documents based on similarity measures in RAG applications.
from llama_index.vector_stores.myscale import MyScaleVectorStore
from llama_index.core import StorageContext
for document in documents:
category = analyze_and_assign_category(document.text)
document.metadata = {"Category": category}
vector_store = MyScaleVectorStore(myscale_client=client)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context
)
Note: When creating an index with MyScaleDB, it uses embedding models from OpenAI. To enable this, you must add your OpenAI key as an environment variable.
# Simple Query
To execute a simple query, we need to convert our existing index into a query engine. The query engine is a specialized tool that can handle and interpret search queries.
query_engine = index.as_query_engine()
response = query_engine.query("I want a few running shoes")
print(response.source_nodes[0].text)
Using the query engine, we execute a query to find "I want a few running shoes." The engine processes this query, then searches through the indexed documents to find matches that best satisfy the query terms.
# Filtered Query
Here, the query engine is configured with metadata filters using the MetadataFilters and ExactMatchFilter classes. The ExactMatchFilter is applied to the “Category” metadata field to only include documents that are explicitly categorized as "Running." This filter ensures that the query engine will only consider documents related to running, which can lead to more relevant and focused results. The similarity_top_k=2 configuration limits the search to the top two most similar documents, and vector_store_query_mode="hybrid suggests a combination of vector and traditional search methods for optimal results.
from llama_index.core.vector_stores import ExactMatchFilter, MetadataFilters
query_engine = index.as_query_engine(
filters=MetadataFilters(
filters=[
ExactMatchFilter(key="Category", value="Running"),
]
),
similarity_top_k=2,
vector_store_query_mode="hybrid",
)
response = query_engine.query("I want a few running shoes?")
print(response.source_nodes[0].text)
This output should closely match the user's query, showing how effectively metadata filters can improve the precision of search results.
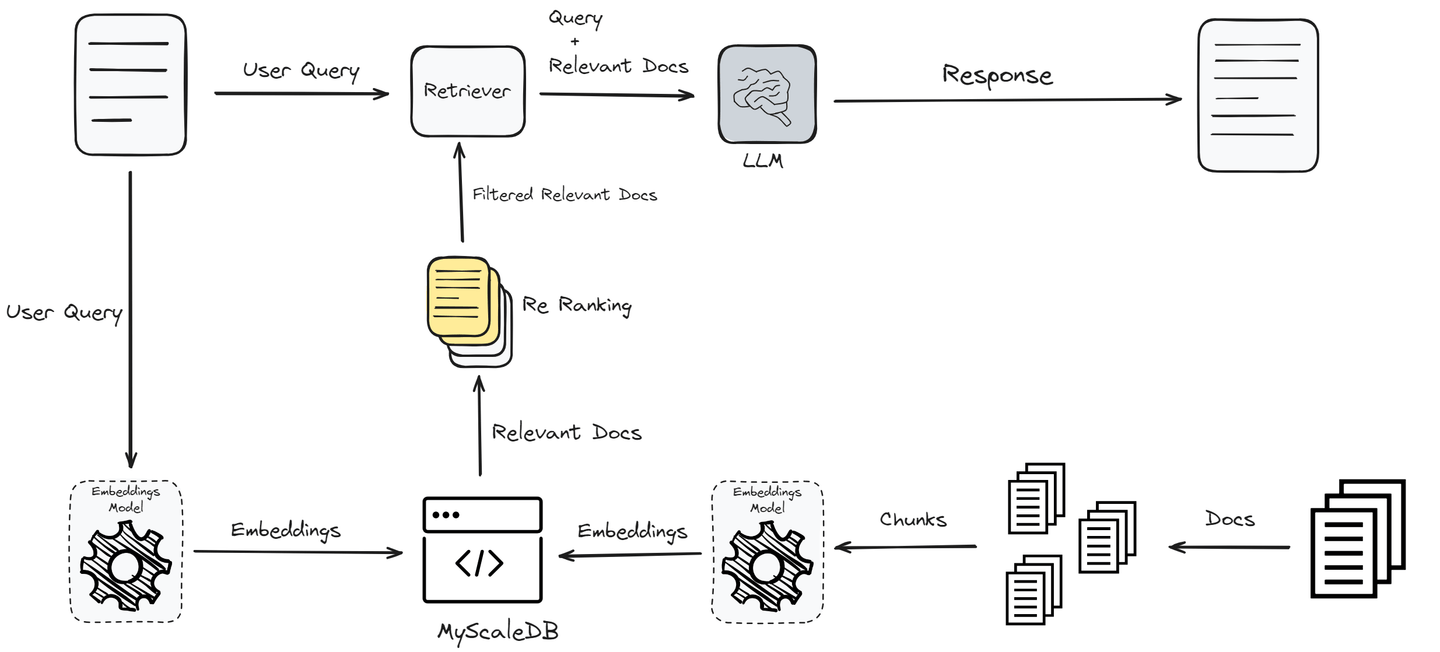
So far, we have implemented RAG in its simplest form, which may not yield the best performance. To enhance the performance and provide users with the exact answers, we will now implement a re-ranker that will further filter the retrieved documents.
# Adding a Reranker to Enhance Document Retrieval
This code integrates a reranking mechanism using Jina AI to refine the documents retrieved by the initial query.
from llama_index.postprocessor.jinaai_rerank import JinaRerank
jina_rerank = JinaRerank(api_key="api-key-here", top_n=2)
from llama_index.llms.openai import OpenAI
llm = OpenAI(model="gpt-4", temperature=0)
query_engine = index.as_query_engine(
similarity_top_k=10, llm=llm, node_postprocessors=[jina_rerank]
)
response = query_engine.query("I want a few running shoes?")
print(response.source_nodes[0].text)
Note: You can find the Jina Reranker key here (opens new window). Click on the API and scroll down the newly opened page; you will find the API key right below the Reranker API section.
# Conclusion
RAG significantly helps LLMs stay updated and ensure their responses are accurate and relevant. However, simple RAG systems often aren’t used in production-ready applications due to their performance. To enhance performance, we use advanced techniques such as reranking, pre-processing and filtered queries.
The choice of vector database is another factor that affects the performance of RAG systems.
It's crucial to select a vector database tailored to the needs of your application. MyScaleDB, being an SQL vector database, is a good choice for developers with its familiar SQL interface, in addition to being affordable, fast and optimized for production-level applications.
If you have any suggestions, please reach out to us through Twitter (opens new window) or Discord (opens new window).
This article is originally published on The New Stack. (opens new window)



