
RAG (opens new window) besteht darin, mehrere Dokumente pro Abfrage abzurufen, und oft sind diese Dokumente nicht relevant für die Abfrage. Daher benötigen wir einige externe Techniken, um diese Ergebnisse zu verbessern. Letztendlich ist eine Suche nur so leistungsfähig wie die Relevanz ihrer Ergebnisse.
Bei der Anwendung der Vektor-Suche geht oft semantische Information verloren, aus verschiedenen Gründen. Zum Beispiel müssen Dokumente in kleinere Teil-Dokumente aufgeteilt werden, was zu einem Verlust von Kontextinformationen führen kann. Infolgedessen können RAG-Modelle Schwierigkeiten haben, Informationen über mehrere abgerufene Dokumente hinweg effektiv zu verbinden. [1]
Um diese Herausforderungen anzugehen, verwenden wir Dokumenten-Re-Ranking-Techniken im RAG-Framework. Es gibt verschiedene Methoden, um abgerufene Dokumente neu zu ordnen.
# Was ist Dokumenten-Re-Ranking
Im Zuge der Weiterentwicklung von RAG hat sich das Re-Ranking als entscheidende Komponente zur Erschließung des vollen Potenzials von RAG herausgebildet. Re-Ranking ist mehr als nur eine einfache Neuorganisation der abgerufenen Ergebnisse - es handelt sich um einen strategischen Prozess, der die Relevanz, Vielfalt und Personalisierung der den Benutzern präsentierten Informationen erheblich verbessern kann.
Durch die Nutzung zusätzlicher Signale und Heuristiken kann die Re-Ranking-Phase von RAG die anfängliche Dokumentenabfrage verfeinern und sicherstellen, dass die relevantesten und wertvollsten Daten an die Spitze gelangen. Darüber hinaus ermöglicht das Re-Ranking einen iterativen Ansatz, bei dem die Ergebnisse schrittweise verfeinert werden, um immer genauere und kontextbezogene Ausgaben zu erzielen.
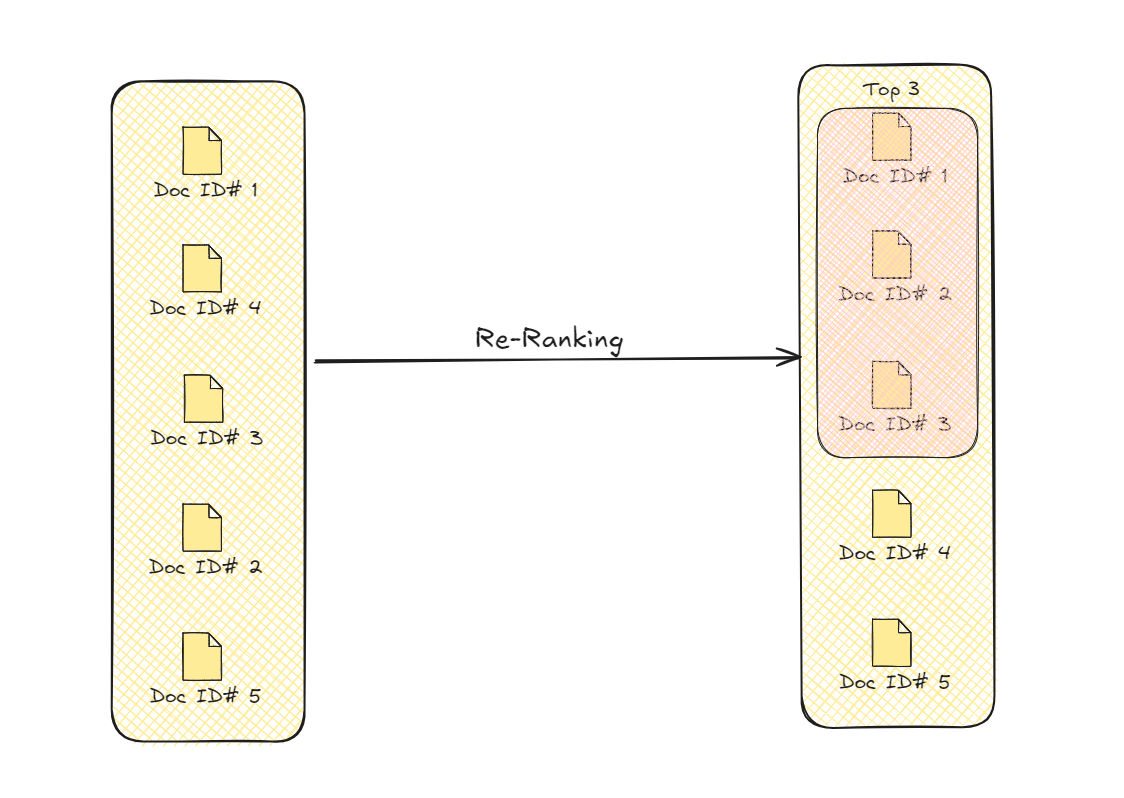
Re-Ranking von Dokumenten
Dieser Prozess verfeinert die Abrufergebnisse, indem er die Dokumente priorisiert, die für die Abfrage inhaltlich am besten geeignet sind. Diese verbesserte Auswahl verbessert die Gesamtqualität und Genauigkeit der Informationen, die das Modell zur Generierung seiner endgültigen Ausgabe verwendet.
# Re-Ranking mit Transformers
Die Verwendung von Transformer-Modellen (opens new window) für das Re-Ranking von Dokumenten hat eine Geschichte, die über die RAGs hinausgeht. Im Jahr 2020 haben Forscher einen vortrainierten (seq2seq (opens new window)) Transformer für das Re-Ranking von Dokumenten angepasst. [2] Dieses System nimmt ein Dokument als Eingabe und gibt an, ob es relevant ist oder nicht. Nachdem die relevanten Dokumente (d.h. "wahr" gekennzeichnet) herausgefiltert wurden, wurden sie mit Softmax (opens new window) als Wahrscheinlichkeitsfunktion neu geordnet.
Hinweis:
Da diese Sequenz-zu-Sequenz-Modelle ebenfalls eine Sequenz zurückgeben, wurde es modifiziert, um nur "wahr" oder "falsch" zurückzugeben.
# Verwendung von LLMs
Die Nutzung der Allrounder-Fähigkeiten von LLMs zur Verbesserung von RAG wird heutzutage immer häufiger [4-7].
In einem Ansatz verwendeten Forscher GPT-3 [4], um das Ranking ausschließlich mit Anweisungen durchzuführen, und nannten es LRL (Listwise Reranker using LLM) (opens new window). Die verwendete Anweisung war recht einfach.

Sortierte neu geordnete Dokumente
Um das Vertrauen in die Relevanz des Dokuments zu erhöhen, wurde auch eine Anweisung für die Klassifizierung verwendet und sie PRL (Pointwise Reranker with an LLM) (opens new window) genannt.

Re-Ranking mit LLMs
In einem methodischeren Ansatz [5] wird LLaMA (opens new window) zur Dokumenten-Neuordnung verwendet. Diese Methode (RankLLaMA (opens new window)) wendet die Ranking-Funktion auf die abgerufenen Dokumente an:
Nach Anwendung der Re-Ranking-Funktion optimieren wir sie weiter mit dem InfoNCE-Verlust (den wir bereits in MoCo für kontrastives Lernen (opens new window) gesehen haben).
# Verwendung von Cross-Encodern
Cross-Encoder sind eine andere Art von Transformern, die häufig für das Re-Ranking von Dokumenten verwendet werden. Wie der Name schon sagt, kodiert der Cross-Encoder sowohl die Abfrage als auch (jedes) Dokument, und seine Ausgabe zeigt die Kreisähnlichkeit/Relevanz zwischen den beiden.

Re-Ranking mit Cross-Encodern
Wie Sie sehen können, ist es nicht praktikabel, jedes Dokument mit der Abfrage abzugleichen, daher wählen wir die Dokumente aus, die wir mit einer kleineren Menge abgleichen möchten. Es gibt zwei häufig verwendete Methoden für die Vorauswahl:
- Verwendung von Bi-Encodern
- Verwendung von sparsamen Suchmethoden (wie BM25)
Cross-Encoder (opens new window) haben eine bessere Leistung als Bi-Encoder (opens new window) gezeigt, noch bevor sie in RAG verwendet wurden, aufgrund ihrer höheren Präzision und verbesserten kontextuellen Verständnis. [6] Es ist kaum überraschend, dass sie jetzt umfangreich für das Re-Ranking von Dokumenten für RAG verwendet werden. Hier ist eine grundlegende Implementierung mit HuggingFace (opens new window) und PyTorch (opens new window).
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
tokenizer = AutoTokenizer.from_pretrained("cross-encoder/ms-marco-TinyBERT-L-6")
model = AutoModelForSequenceClassification.from_pretrained("cross-encoder/ms-marco-TinyBERT-L-6")
def ReRank(query, documents):
scores = []
for doc in documents:
inputs = tokenizer(query, doc, return_tensors="pt", padding=True, truncation=True, max_length=512)
with torch.no_grad():
outputs = model(**inputs)
scores.append(outputs.logits.squeeze().item())
rankedDocs = [doc for _, doc in sorted(zip(scores, documents), reverse=True)]
return rankedDocs
Für eine Beispielanfrage können wir sie wie folgt verwenden:
query = "Welcher Monat ist am besten für einen Besuch in Bali geeignet?"
# Angenommen, unsere Dokumente sind in der Variable "docs" als Liste.
rankedDocs = ReRank(query, docs)
print(rankedDocs)
# Re-Ranking mit Graphen
Wenn Sie ein Akademiker/Wissenschaftler sind, haben Sie wahrscheinlich Litmaps (opens new window) und Connected Papers (opens new window) verwendet, sie sind gute Beispiele für Graphen mit semantischen Beziehungen. In diesen Graphen werden die Dokumente durch Knoten repräsentiert, während Kanten ihre semantischen Beziehungen darstellen.
Litmaps und Connected Papers
Nach dem Aufbau dieses Dokumentengraphen verwenden wir GNNs (opens new window) für Message-Passing, um die Knotenmerkmale basierend auf den Nachbarknoten zu aktualisieren. Dadurch kann das Modell aus dem Kontext, der durch verwandte Dokumente bereitgestellt wird, lernen und seine Fähigkeit verbessern, relevante Inhalte zu identifizieren, auch wenn die direkten Verbindungen zur Abfrage schwach sind.
# Abstract Meaning Representation (AMR)
Während der Aufbau des Dokumentengraphen und der Message-Passing-Mechanismus für GNN-Benutzer nicht neu sind, verdient die Abstract Meaning Representation (AMR) (opens new window) eine besondere Erwähnung.
AMR ist eine semantische Graphrepräsentation eines Satzes, die seine Bedeutung abstrakt erfasst und sich auf die ausgedrückten Konzepte und ihre Beziehungen konzentriert, anstatt auf syntaktische Details. AMR-Graphen enthalten im Vergleich zur allgemeinen Form natürlicher Sprache strukturiertere semantische Informationen. Sie sind besonders nützlich für das graphbasierte Re-Ranking von Dokumenten für Retrieval-Augmented Generation (RAG), da sie die Codierung von reichen semantischen und strukturellen Informationen in den Re-Ranking-Prozess ermöglichen.
# G-RAG
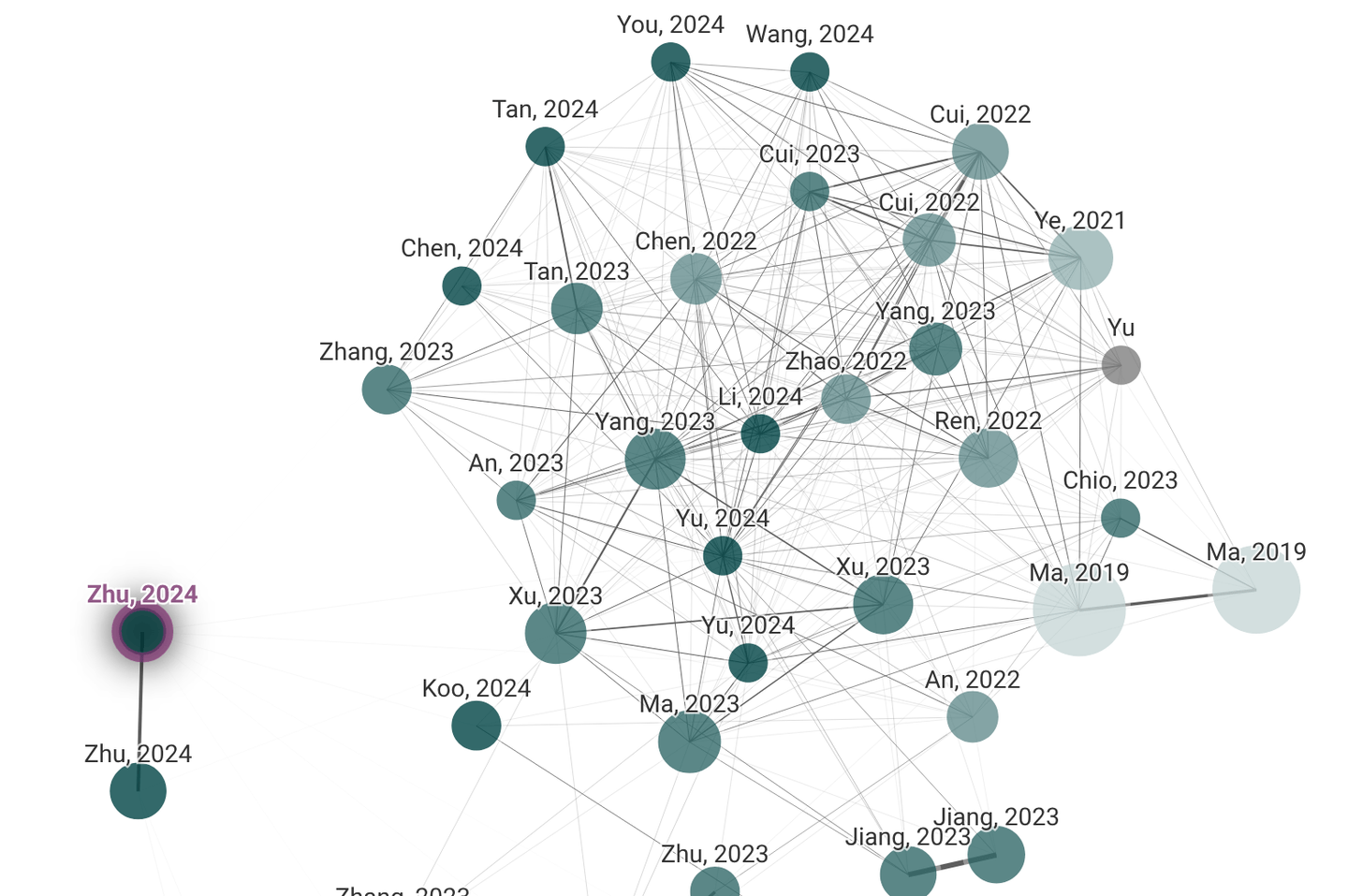
Es gibt eine kürzlich vorgeschlagene Methode, die AMRs für das Re-Ranking in RAG verwendet. G-RAG [1] In ihrer Konfiguration erstellen die Forscher AMRs, nehmen die Top-100-Dokumente und verwenden sie, um den Dokumentengraphen aufzubauen. Anstelle des traditionellen Kreuzentropie-Verlusts verwendet G-RAG den paarweisen Rangverlust, um direkt die Relevanz-Rangfolge zu optimieren, was besser mit den Zielen des Re-Rankings übereinstimmt.
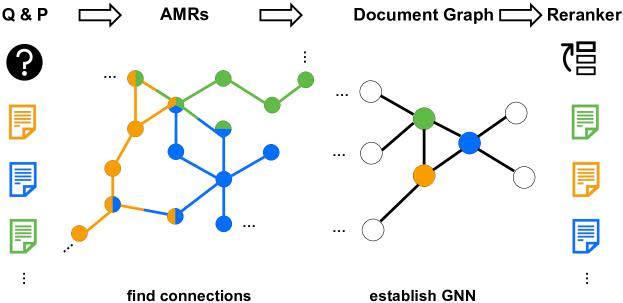
G-RAG
# MyScale's Zwei-Stufen-Retrieval
MyScaleDB verwendet einen zweistufigen Abrufprozess, um die Informationsabfrage zu optimieren. Dieser Prozess besteht aus:
Initial Retrieval: Eine breite Palette potenziell relevanter Dokumente wird schnell abgerufen, indem Methoden wie die Vektor-Suche verwendet werden, die ähnliche Dokumente auf der Grundlage numerischer Repräsentationen (Vektoren) findet.
Re-Ranking: Die abgerufenen Dokumente werden dann mit fortschrittlichen Techniken wie Cross-Encodern verfeinert und gerankt, um sicherzustellen, dass die relevantesten Ergebnisse basierend auf der Abfrage des Benutzers präsentiert werden.
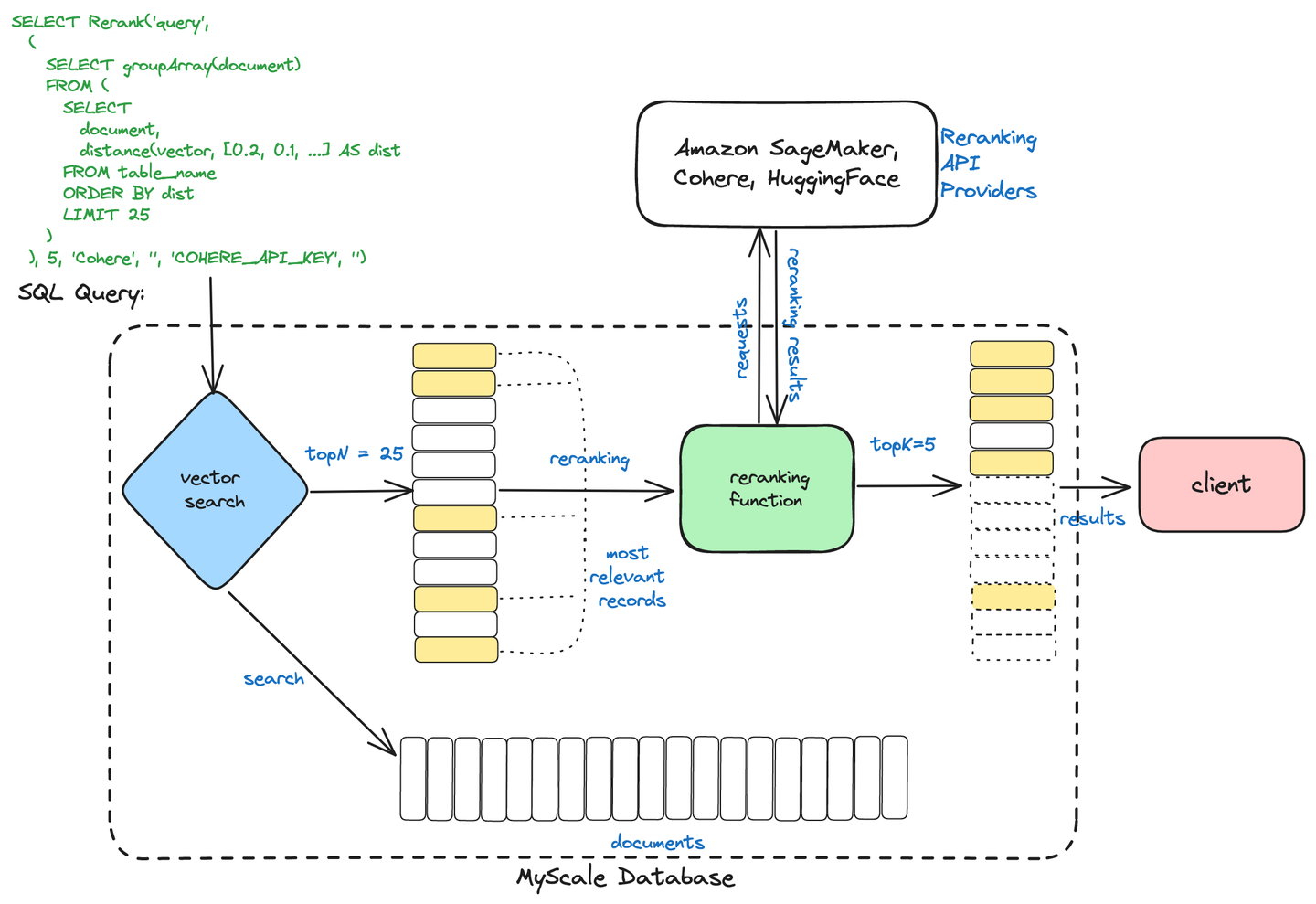
Zwei-Stufen-Retrieval
Dieser Ansatz hilft MyScaleDB, schnellere und genauere Suchergebnisse zu liefern, indem effiziente Abfrage mit präzisem Ranking kombiniert wird.
Hinweis:
Weitere Informationen zum Zwei-Stufen-Retrieval von MyScale (opens new window) finden Sie in unserem Blog.
# Re-Ranking mit MyScale und Cohere
Wir werden es mit einem vollständigen Beispiel abschließen. In diesem Beispiel verwenden wir die MyScale-Vektordatenbank, um Dokumente im RAG-Pipeline neu zu ordnen. Für die Einbettungen verwenden wir hier Cohere, es könnte aber auch ein anderer Dienst wie OpenAI oder BedRock sein.
from langchain_community.vectorstores import MyScale, MyScaleSettings
from langchain_cohere import CohereEmbeddings
config = MyScaleSettings(host='host-name', port=443, username='your-user-name', password='your-passwd')
index = MyScale(CohereEmbeddings(), config)
Jetzt fügen wir die Dokumente in MyScale hinzu. Bevor sie in die Datenbank aufgenommen werden, müssen sie (geladen und) aufgeteilt werden.
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
documents = TextLoader("../../file.txt").load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
texts = text_splitter.split_documents(documents)
index.add_documents(texts)
Wie wir im gesamten Artikel gesehen haben, benötigen wir vor dem Anwenden des Re-Rankings eine Pool/Teilmenge von Dokumenten, also holen wir uns eine Teilmenge von x Dokumenten.
retriever = index.as_retriever(search_kwargs={"k": 20})
query = "Welcher Ort auf der Erde ist am weitesten vom Zentrum entfernt?"
docs = retriever.invoke(query)
Jetzt sind wir bereit für das Re-Ranking. Wir initialisieren ein Sprachmodell mit Cohere, setzen den Re-Ranker mit CohereRerank und kombinieren ihn mit dem Basis-Retriever in einem ContextualCompressionRetriever. Diese Konfiguration komprimiert und ordnet die Abrufergebnisse neu und verfeinert die Ausgabe basierend auf der kontextuellen Relevanz.
from langchain.retrievers.contextual_compression import ContextualCompressionRetriever
from langchain_cohere import CohereRerank
from langchain_community.llms import Cohere
llm = Cohere(temperature=0)
compressor = CohereRerank()
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"Ihre-Abfrage-hier"
)
Nachdem der Re-Ranker hinzugefügt wurde, wird die Antwort Ihres RAG-Systems verfeinert, was nicht nur die Benutzererfahrung verbessert, sondern auch die Anzahl der verwendeten Tokens reduziert.

# Fazit
Die Bedeutung von RAG und seine immense Anwendung sind ein offenes Geheimnis. Mit dem Abschluss unserer eingehenden Erkundung der fortschrittlichen Techniken, die Retrieval Augmented Generation (RAG) antreiben, wird deutlich, dass dieses Feld sich schnell entwickelt und die Grenzen des Möglichen mit datengesteuerter Intelligenz erweitert. Im Laufe dieser Blogserie haben wir uns mit den Feinheiten der Abfrageoptimierung, der Vektor-Suche, den Chunking-Strategien, den Re-Ranking-Methoden und einer Vielzahl anderer wesentlicher Komponenten beschäftigt, die das Fundament moderner RAG-Systeme bilden.
Indem Sie diese fortgeschrittenen Konzepte beherrschen, haben Sie das Wissen und die Werkzeuge erlangt, um das volle Potenzial Ihrer RAG-Initiativen zu entfesseln. Von der Optimierung Ihrer Abfragen, um eine blitzschnelle Abfrage relevanter Informationen zu liefern, bis hin zur Nutzung modernster Vektor-Indexierung und Suchfunktionen sind Sie nun in der Lage, RAG-Systeme aufzubauen, die Ihre Entscheidungsprozesse wirklich transformieren können.
Bei Ihrem weiteren Vorgehen sollten Sie bedenken, dass das Feld der Retrieval Augmented Generation ständig im Wandel ist. Bleiben Sie wachsam, lernen Sie weiter und erkunden Sie innovative Lösungen wie MyScale, die Ihnen helfen können, immer einen Schritt voraus zu sein. Die Zukunft der datengesteuerten Intelligenz ist vielversprechend, und mit dem Wissen, das Sie durch diese Blogserie gewonnen haben, sind Sie bereit, an vorderster Front dieser aufregenden Grenze zu stehen.
Wenn Sie mehr über die fortgeschrittenen RAG-Techniken diskutieren möchten, sind Sie herzlich eingeladen, unserem Discord (opens new window) beizutreten, um mit uns zu kommunizieren.
# Referenzen
- Dong, J., Fatemi, B., Perozzi, B., Yang, L. F., & Tsitsulin, A. (2024). Don't Forget to Connect! Improving RAG with Graph-based Reranking. ArXiv. https://arxiv.org/abs/2405.18414
- Nogueira, R., Jiang, Z., & Lin, J. (2020). Document Ranking with a Pretrained Sequence-to-Sequence Model. ArXiv. https://arxiv.org/abs/2003.06713
- Dengrong Huang, Zizhong Wei, Aizhen Yue, Xuan Zhao, Zhaoliang Chen, Rui Li, Kai Jiang, Bingxin Chang, Qilai Zhang, Sijia Zhang, et al. Dsqa-llm: Domain-specific intelligent question answering based on large language model. In International Conference on AI-generated Content, pages 170–180. Springer, 2023.
- Xueguang Ma, Xinyu Zhang, Ronak Pradeep, and Jimmy Lin. Zero-shot listwise document reranking with a large language model. arXiv preprint arXiv:2305.02156, 2023
- Xueguang Ma, Liang Wang, Nan Yang, Furu Wei, and Jimmy Lin. Fine-tuning llama for multi-stage text retrieval. arXiv preprint arXiv:2310.08319, 2023.
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS. https://arxiv.org/abs/2005.11401
- Zhang, L., Zhang, Y., Long, D., Xie, P., Zhang, M., & Zhang, M. (2023). A Two-Stage Adaptation of Large Language Models for Text Ranking. ArXiv. https://arxiv.org/abs/2311.16720
- Cunxiang Wang, Zhikun Xu, Qipeng Guo, Xiangkun Hu, Xuefeng Bai, Zheng Zhang, and Yue Zhang. Exploiting Abstract Meaning Representation for open-domain question answering. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Findings of the Association for Computational Linguistics: ACL 2023, pages 2083–2096, Toronto, Canada, July 2023b. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-acl.131.



