
Das explosive Wachstum globaler Daten, das bis 2025 voraussichtlich 181 Zettabyte erreichen wird (opens new window), wobei 80% davon unstrukturiert sind, stellt eine Herausforderung für herkömmliche Datenbanken dar, die unstrukturierte Textdaten nicht effektiv verarbeiten können. Die Volltextsuche löst dieses Problem, indem sie einen intuitiven und effizienten Zugriff auf unstrukturierte Textdaten ermöglicht und es Benutzern ermöglicht, nach Themen oder Schlüsselideen zu suchen.
MyScaleDB (opens new window), eine Open-Source-Variante von ClickHouse, die für die Vektorsuche optimiert ist, hat seine Textsuchfunktionen durch die Integration von Tantivy (opens new window), einer Volltextsuchmaschinenbibliothek, erheblich verbessert.
Dieses Upgrade bietet erhebliche Vorteile für diejenigen, die ClickHouse für das Logging verwenden, oft als Ersatz für Elasticsearch oder Loki. Es bietet auch Vorteile für Benutzer, die MyScaleDB in der Retrieval-Augmented Generation (RAG) mit großen Sprachmodellen (LLMs) einsetzen, indem sie Vektor- und Textsuche kombinieren, um die Genauigkeit zu verbessern.
In diesem Beitrag werden wir die technischen Details des Integrationsprozesses und wie er die Leistung von MyScaleDB verbessert, genauer untersuchen.
# Einschränkungen der nativen Textsuche von ClickHouse
ClickHouse bietet grundlegende Textsuchfunktionen wie hasToken, startsWith und multiSearchAny, die für einfache Termabfragen geeignet sind. Für komplexere Anforderungen wie Phrasenabfragen, unscharfe Textübereinstimmung und BM25-Relevanzbewertung sind diese Funktionen jedoch nicht ausreichend. Daher haben wir in MyScaleDB Tantivy als zugrunde liegende Implementierung für die Volltextindizierung eingeführt, um MyScaleDB mit Volltextsuchfunktionen auszustatten. Der Volltextindex von Tantivy unterstützt unscharfe Textabfragen, BM25-Relevanzbewertung und beschleunigt vorhandene Funktionen wie die Termübereinstimmung von hasToken und multiSearchAny.
# Warum wir uns für Tantivy entschieden haben
Tantivy ist eine Open-Source-Volltextsuchmaschinenbibliothek, die in Rust geschrieben ist. Sie ist auf Geschwindigkeit und Effizienz ausgelegt, insbesondere bei der Verarbeitung großer Textdatenmengen.
# Verständnis der Kernprinzipien von Tantivy
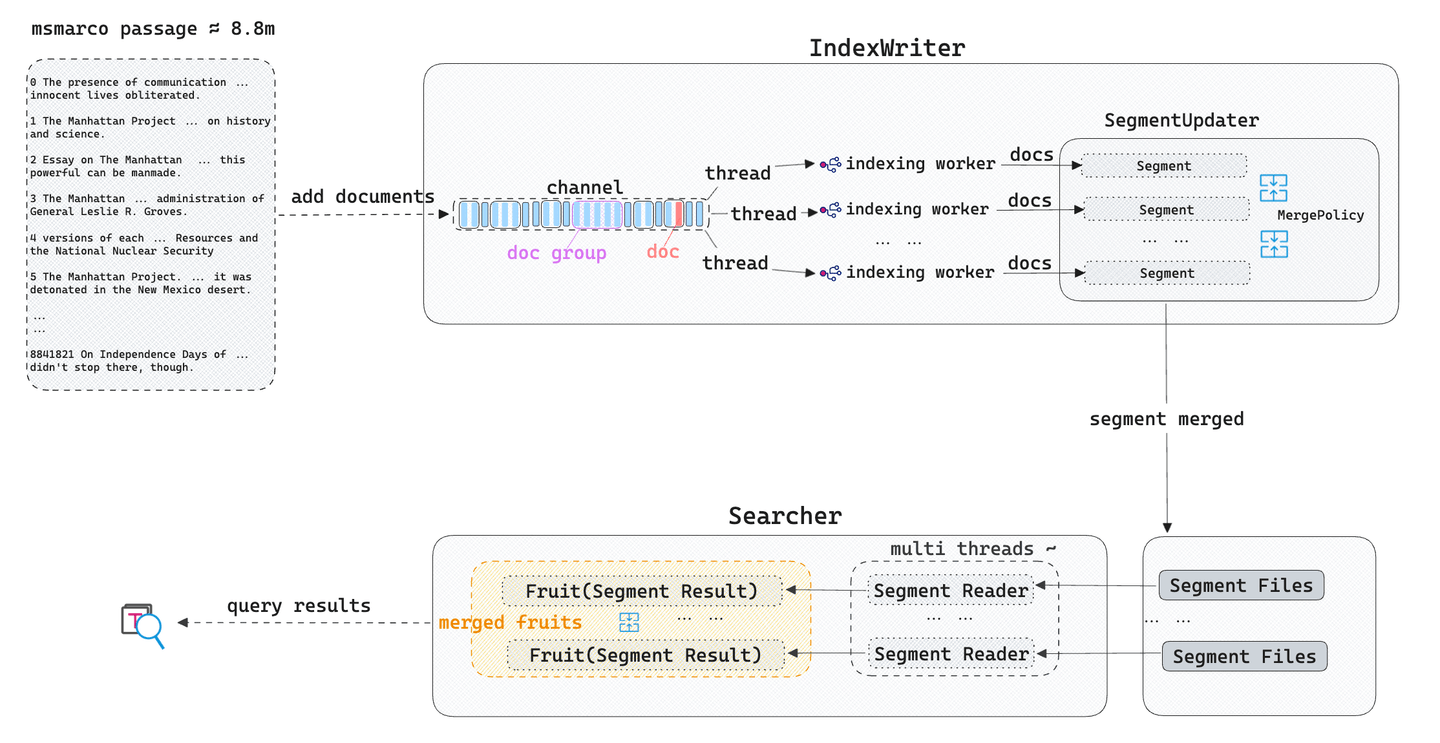
Indexerstellung: Tantivy tokenisiert den Eingabetext, teilt ihn in unabhängige Tokens auf und erstellt dann einen invertierten Index (Posting-Liste), den es in Indexdateien (Segmente) schreibt. Gleichzeitig verwenden die Hintergrundthreads von Tantivy Merge-Strategien, um diese Segmentindexdateien zusammenzuführen und zu aktualisieren.
Ausführung von Textsuchen: Wenn ein Benutzer eine Textsuchabfrage startet, analysiert Tantivy die Abfragesyntax, extrahiert Tokens und sortiert und bewertet Dokumente für jede Segmentdatei basierend auf den Abfragebedingungen und dem BM25-Relevanzalgorithmus. Schließlich werden die Abfrageergebnisse aus diesen Segmenten basierend auf den Relevanzbewertungen zusammengeführt und dem Benutzer zurückgegeben.
# Hauptmerkmale von Tantivy
- BM25-Relevanzbewertung: Elasticsearch, Lucene und Solr verwenden alle BM25 als den Standardrelevanzbewertungsalgorithmus. Der BM25-Score bewertet die Genauigkeit und Relevanz von Textsuchen und verbessert so die Benutzererfahrung.
- Konfigurierbare Tokenizer: Unterstützt verschiedene Sprachtokenizer, um den unterschiedlichen Tokenisierungsanforderungen der Benutzer gerecht zu werden.
- Natürliche Sprachabfragen: Benutzer können Textabfragen flexibel mit Schlüsselwörtern wie AND, OR, IN kombinieren, um die Komplexität des SQL-Abfrageerstellungsprozesses zu reduzieren.
Für weitere Funktionen siehe die Tantivy-Dokumentation (opens new window).
# Nahtlose Integration mit MyScaleDB
MyScaleDB, das in C++ geschrieben ist, wurde auf der Grundlage von ClickHouse entwickelt und dient als robuste Suchmaschine für KI-native Anwendungen. Um die Volltextsuchfunktionen von MyScaleDB zu erweitern, benötigten wir eine Bibliothek, die direkt in MyScaleDB eingebettet werden kann.
Tantivy ist eine Volltextsuchbibliothek, die von Apache Lucene inspiriert wurde. Im Gegensatz zu Elasticsearch, Apache Solr und anderen ähnlichen Engines kann Tantivy in verschiedene Datenbanken wie MyScaleDB integriert werden. Tantivy ist in der Programmiersprache Rust geschrieben, die sich leicht mit C++-Programmen integrieren lässt, indem Corrosion (opens new window) verwendet wird.
# Der Integrationsprozess
# Erstellung eines C++-Wrappers für Tantivy
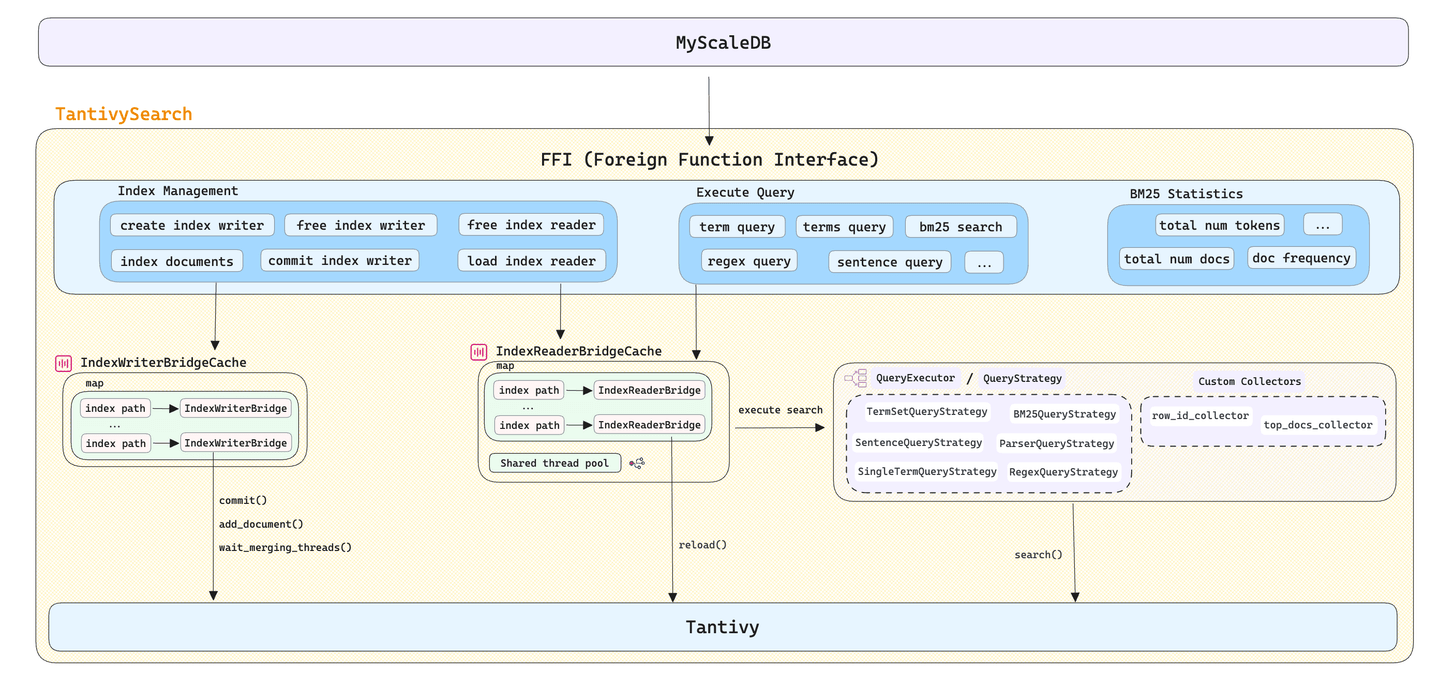
Wir konnten die Rohbibliothek Tantivy nicht direkt in MyScaleDB verwenden. Um die Herausforderung der plattformübergreifenden Entwicklung (C++ & Rust) zu bewältigen, haben wir tantivy-search (opens new window) entwickelt, einen C++-Wrapper für Tantivy. Er bietet eine Reihe von FFI-Schnittstellen für MyScaleDB und ermöglicht die direkte Verwaltung der Indexerstellung, -zerstörung, -ladung und die flexible Behandlung von Textsuchanforderungen in verschiedenen Szenarien.
# Implementierung von Tantivy als Skipping-Index in ClickHouse
Der Skipping-Index von ClickHouse (opens new window) wird hauptsächlich verwendet, um Abfragen mit WHERE-Klauseln zu beschleunigen. Wir haben einen neuen Skipping-Index-Typ namens FTS (Full-Text Search) implementiert, wobei Tantivy als zugrunde liegende Implementierung verwendet wird. Für jeden Datenabschnitt in ClickHouse mit dem FTS-Index erstellen wir einen Tantivy-Index. Wie bereits erwähnt, generiert Tantivy mehrere Segmentdateien für jeden Index. Um die Anzahl der in einem Datenabschnitt zu speichernden Dateien zu reduzieren, serialisiert MyScaleDB diese Segmentdateien in zwei Dateien und speichert sie im Datenabschnitt. Die Datei skp_idx_[index_name].meta enthält den Namen und die Position jeder Segmentdatei, während die Datei skp_idx_[index_name].data die ursprünglichen Daten jeder Segmentdatei speichert.
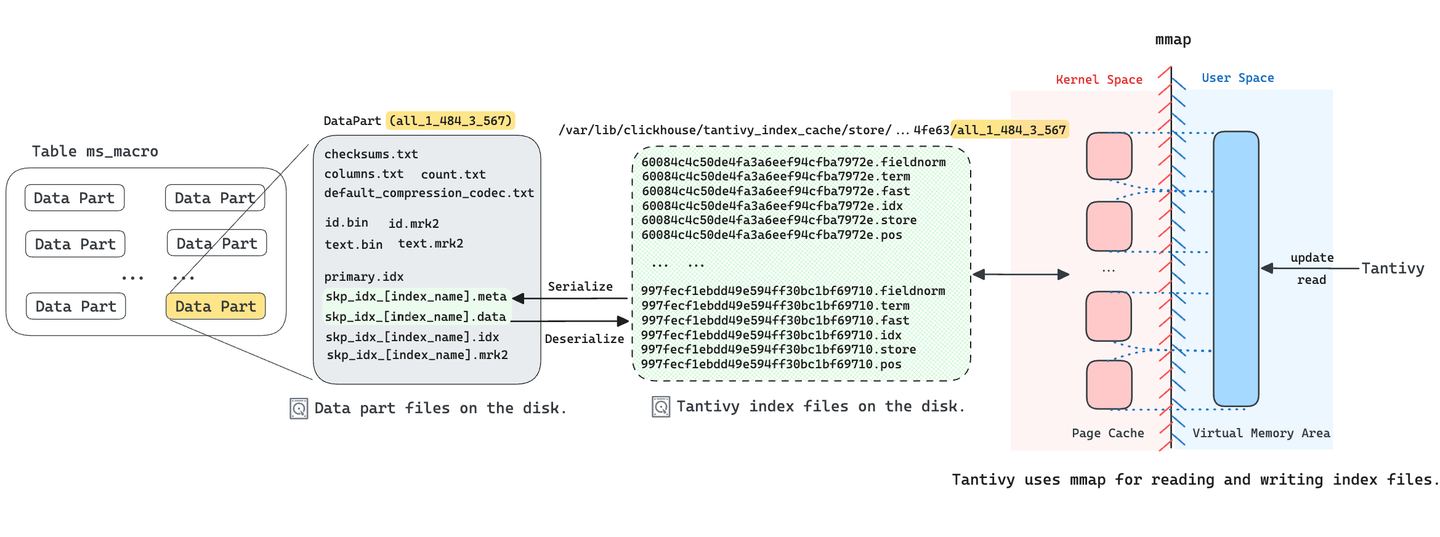
Tantivy verwendet die Speicherabbildung (mmap), um auf Segmentdateien zuzugreifen. Dieser Ansatz verbessert nicht nur die Geschwindigkeit der gleichzeitigen Suche, sondern auch die Effizienz des Indexaufbaus. Da Tantivy die Datei skp_idx_[index_name].data nicht direkt in den Speicher abbilden kann, deserialisiert MyScaleDB die Indexdateien (.meta und .data) in Tantivy-Segmentdateien in ein temporäres Verzeichnis und lädt den Tantivy-Index. Diese deserialisierten Segmentdateien werden von Tantivy über die Speicherabbildung für die Ausführung verschiedener Arten von Textsuchen geladen. Daher kann die erste Abfrageanforderung von Benutzern mehrere Sekunden dauern, bis sie abgeschlossen ist.
In dem verwalteten MyScaleDB-Dienst (opens new window) speichern wir die Segmentindexdateien von Tantivy auf NVMe-SSDs. Dadurch wird die Wartezeit für die E/A-Operationen reduziert und die Leistung der Speicherabbildung in Szenarien mit zufälligem Zugriff und Behandlung von Seitenausnahmen verbessert.
# Verbesserung der nativen Textsuchefunktionen von ClickHouse
Wenn Anfragen mit Filterbedingungen auf Spalten mit FTS-Indizes gestellt werden, greift MyScaleDB zuerst auf den FTS-Index zu. Es ruft alle Zeilen-IDs der Spalte ab, die den SQL-Filterbedingungen entsprechen, und speichert diese Zeilen-IDs in einer erweiterten Bitmap-Datenstruktur, bekannt als Roaring Bitmap (opens new window). Beim Durchlaufen von Granulen wird festgestellt, ob sich der Zeilen-ID-Bereich eines Granuls mit der Bitmap überschneidet, was darauf hinweist, ob das Granul verworfen werden kann. Letztendlich greift MyScaleDB nur auf diejenigen Granulen zu, die nicht verworfen wurden, und erreicht so eine Beschleunigung der Abfrage.
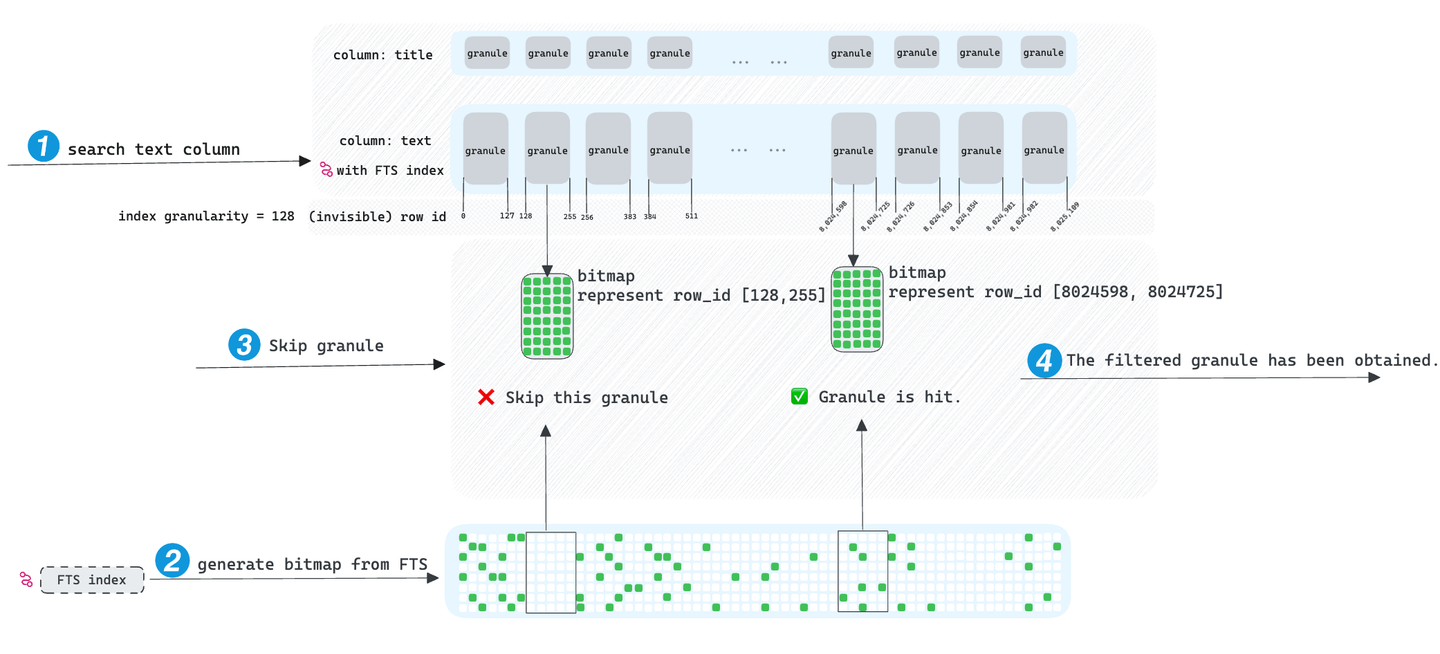
Der Skipping-Index beschleunigt idealerweise Abfragen, aber wir haben festgestellt, dass seine Wirkung begrenzt ist. Wenn der gesuchte Begriff in fast allen Granulen vorkommt, kann MyScaleDB nur eine geringe Anzahl von Granulen überspringen und muss auf eine große Anzahl von Granulen für die Abfrage zugreifen, was den Skipping-Index in solchen Fällen unwirksam macht. MyScaleDB hat jedoch die Funktion TextSearch eingeführt, die nicht nur die Unzulänglichkeiten des Skipping-Index behebt, sondern auch andere praktische Funktionen bietet.
# Einführung der TextSearch-Funktion
Um die Volltextsuchfunktionen von Tantivy voll auszuschöpfen, haben wir die TextSearch-Funktion in MyScaleDB integriert. Dadurch können Benutzer unscharfe Textabfragen durchführen und eine Menge von Dokumenten abrufen, die nach BM25-Score-Relevanz sortiert sind. Darüber hinaus können Benutzer innerhalb der TextSearch-Funktion natürliche Sprachabfragen verwenden, was die Komplexität des SQL-Schreibens erheblich reduziert.
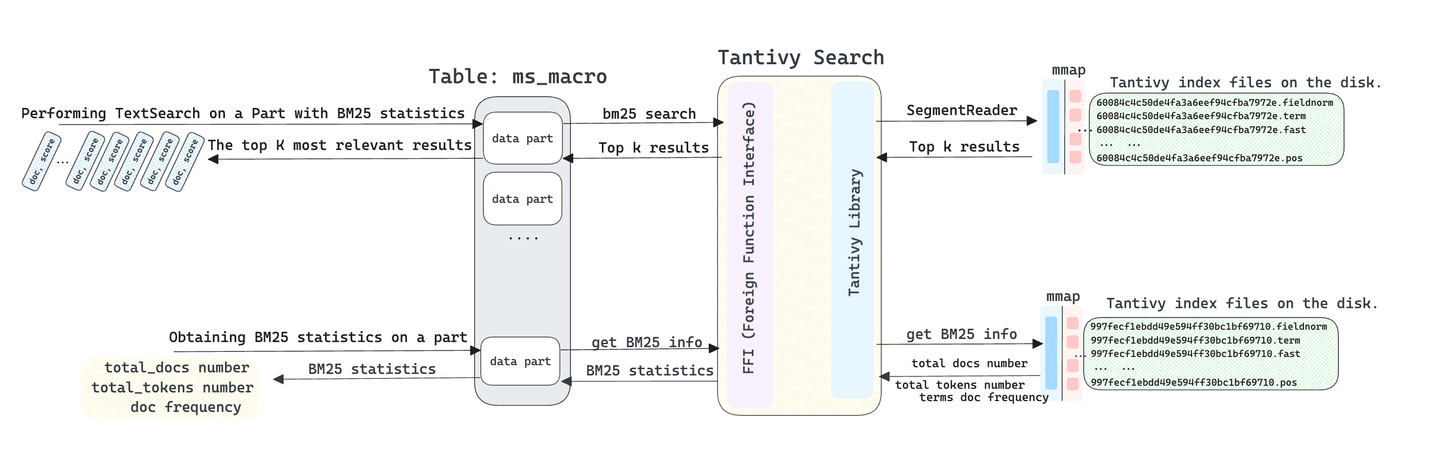
Die TextSearch-Funktion ruft die K am besten geeigneten Ergebnisse aus der Tabelle ab, wenn nach Text gesucht wird. In Bezug auf die Ausführung führt MyScaleDB gleichzeitig eine Textsuche auf allen Datenabschnitten durch. Jeder Abschnitt sammelt die K am besten geeigneten Ergebnisse, die nach BM25-Score sortiert sind. Anschließend aggregiert MyScaleDB diese Ergebnisse, die aus den Datenabschnitten stammen, basierend auf den BM25-Scores. Schließlich behält MyScaleDB die K am besten geeigneten Ergebnisse gemäß den in der SQL-Abfrage des Benutzers angegebenen ORDER BY- und LIMIT-Klauseln bei. Die TextSearch-Funktion liest die Daten nicht direkt aus dem Datenabschnitt aus. Stattdessen ruft sie die Suchergebnisse direkt über Tantivy ab, was sie extrem schnell macht.
Es ist wichtig zu beachten, dass MyScaleDB mehrere Datenabschnitte zur Speicherung von Daten verwendet, wobei jeder Datenabschnitt für die Speicherung eines Teils der Daten der gesamten Tabelle verantwortlich ist. Wir können die BM25-Scores, die den gleichen Antworttexten in jedem Abschnitt entsprechen, nicht einfach durchschnittlich berechnen und sortieren. Dies liegt daran, dass jeder Abschnitt nur die "Gesamtzahl der Dokumente", "Gesamtzahl der Tokens" und "Dokumentenhäufigkeit" innerhalb des aktuellen Abschnitts berücksichtigt, wenn er BM25-Scores berechnet, ohne andere mit dem BM25-Algorithmus zusammenhängende Parameter in anderen Abschnitten zu berücksichtigen. Dadurch würde die Genauigkeit der endgültig zusammengeführten Ergebnisse verringert.
Um dieses Problem zu lösen, berechnen wir zunächst die BM25-Statistiken innerhalb jedes Abschnitts, bevor wir die Textsuchabfrage starten. Anschließend konsolidieren wir sie zu logisch entsprechenden BM25-Statistiken für die gesamte Tabelle. Darüber hinaus haben wir die Tantivy-Bibliothek so modifiziert, dass sie die Verwendung von gemeinsamen BM25-Informationen unterstützt. Dadurch wird die Korrektheit der TextSearch-Suchergebnisse über mehrere Abschnitte hinweg sichergestellt.
Nachfolgend finden Sie ein einfaches Beispiel für die Verwendung der TextSearch-Funktion zur Durchführung einer grundlegenden Textsuche auf dem ms_macro-Datensatz. Weitere Informationen zur Verwendung der TextSearch-Funktion finden Sie in unserer TextSearch-Dokumentation (opens new window).
SELECT
id,
text,
TextSearch(text, 'Wer ist Obama') AS score
FROM ms_macro
ORDER BY score DESC
LIMIT 5
Ausgabe:
| id | text | score |
|---|---|---|
| 2717481 | Sasha Obama Biografie. Geburtsname: Natasha Obama. Sasha Obama ist die jüngere Tochter des ehemaligen US-Präsidenten Barack Obama. Ihr formaler Name ist Natasha, aber sie wird meistens mit ihrem Spitznamen Sasha genannt. Sasha Obama wurde 2001 als Tochter von Barack Obama und seiner Frau Michelle Obama geboren, die 1992 geheiratet haben. Sasha Obama hat eine ältere Schwester namens Malia, die 1998 geboren wurde. | 15.448088 |
| 5016433 | Sasha Obama Biografie. Sasha Obama ist die jüngere Tochter des ehemaligen US-Präsidenten Barack Obama. Ihr formaler Name ist Natasha, aber sie wird meistens mit ihrem Spitznamen Sasha genannt. Sasha Obama wurde 2001 als Tochter von Barack Obama und seiner Frau Michelle Obama geboren, die 1992 geheiratet haben. Sasha Obama hat eine ältere Schwester namens Malia, die 1998 geboren wurde. | 15.407547 |
| 564474 | Vermögen von Michelle Obama: 11,8 Millionen US-Dollar. Michelle Obama Vermögen: Michelle Obama ist eine amerikanische Anwältin, Schriftstellerin und First Lady der Vereinigten Staaten mit einem Vermögen von 11,8 Millionen US-Dollar. Michelle Obama wurde am 17. Januar 1964 in Chicago, Illinois, geboren. Michelle Obama Vermögen: 11,8 Millionen US-Dollar. Michelle Obama Vermögen: Michelle Obama ist eine amerikanische Anwältin, Schriftstellerin und First Lady der Vereinigten Staaten mit einem Vermögen von 11,8 Millionen US-Dollar. | 14.88242 |
| 5016431 | Geburtsname: Natasha Obama. Sasha Obama ist die jüngere Tochter des ehemaligen US-Präsidenten Barack Obama. Ihr formaler Name ist Natasha, aber sie wird meistens mit ihrem Spitznamen Sasha genannt. Sasha Obama wurde 2001 als Tochter von Barack Obama und seiner Frau Michelle Obama geboren, die 1992 geheiratet haben. | 14.63069 |
| 1939756 | Michelle Obama Vermögen: Michelle Obama ist eine amerikanische Anwältin, Schriftstellerin und First Lady der Vereinigten Staaten mit einem Vermögen von Michelle Obama Vermögen: Michelle Obama ist eine amerikanische Anwältin, Schriftstellerin und First Lady der Vereinigten Staaten mit einem Vermögen von 40 Millionen US-Dollar. Michelle Obama wurde am 17. Januar 1964 in Chicago, Illinois, geboren. Sie ist am besten bekannt als Ehefrau des 44. Präsidenten der Vereinigten Staaten, Barack Obama. Sie besuchte die Princeton University und schloss 1985 cum laude ab. Anschließend erwarb sie einen Jurastudienabschluss an der Harvard Law School im Jahr 1988. | 14.230849 |

# Leistungsbewertung
Wir haben die Suchleistung von MyScaleDB unter verschiedenen Indizes mit clickhouse-benchmark (opens new window) verglichen, einschließlich des von MyScaleDB implementierten FTS-Index, des in ClickHouse integrierten Inverted Index und des Szenarios ohne Index.
# Benchmark-Setup
# Details zum Datensatz
Um die Leistung der Textsuche zu testen, haben wir den von Microsoft bereitgestellten ms_macro-Datensatz (opens new window) verwendet. Der ms_macro-Datensatz besteht aus 8.841.823 Textdatensätzen, die wir für den einfachen Import in MyScaleDB in das Parquet-Format konvertiert haben. Darüber hinaus haben wir eine Reihe von SQL-Dateien erstellt, um die Suchleistung basierend auf unterschiedlichen Wortfrequenzen zu testen. Leser können auf den in diesem Test verwendeten Datensatz über S3 zugreifen:
- ms_macro_text.parquet (opens new window): 1,6 GB
- ms_macro_query_files.tar.gz (opens new window): 5,8 MB
Die Datei ms_macro_query_files.tar.gz enthält alle in diesem Test verwendeten SQL-Dateien. Der Name jeder SQL-Datei gibt beispielsweise die Häufigkeit des gesuchten Begriffs im ms_macro-Datensatz und die Anzahl der in der SQL-Datei enthaltenen Abfragen an. Die Datei ms_macro_count_hastoken_100_100k.sql enthält beispielsweise 100.000 Abfragen, und das Wort in jeder Abfrage kommt 100 Mal im Datensatz vor.
Die folgenden Beispiele zeigen hasToken- und TextSearch-Abfragen:
SELECT count(*) FROM ms_macro WHERE hasToken(text, 'Crimp');
SELECT count(*) FROM (
SELECT TextSearch(text, 'Crimp') AS score
FROM ms_macro ORDER BY score DESC LIMIT 10000000
) as subquery;
# Testumgebung
Trotz einer Speicherkapazität von 64 GB in unserer Testumgebung beträgt der Speicherverbrauch von MyScaleDB während des Tests nur etwa 2,5 GB.
| Element | Wert |
|---|---|
| Systemversion | Ubuntu 22.04.3 LTS |
| CPU | 16 Kerne (AMD Ryzen 9 6900HX) |
| Speichergeschwindigkeit | 64 GB |
| Festplatte | 512 GB NVMe SSD |
| MyScaleDB | v1.5 |
# Verfahren zum Importieren von Daten
Erstellen Sie eine Tabelle für den ms_macro-Datensatz:
CREATE TABLE default.ms_macro
(
`id` UInt64,
`text` String
)
ENGINE = MergeTree
ORDER BY id
SETTINGS index_granularity = 128;
Importieren Sie die Daten direkt von S3 in MyScaleDB:
INSERT INTO default.ms_macro
SELECT * FROM
s3('https://myscale-datasets.s3.ap-southeast-1.amazonaws.com/ms_macro_text.parquet','Parquet');
Führen Sie eine Zusammenführung der Datenabschnitte von ms_macro durch, um die Suchgeschwindigkeit zu verbessern. Beachten Sie, dass dieser Vorgang optional ist.
OPTIMIZE TABLE default.ms_macro final;
SELECT count(*) FROM system.parts WHERE table = 'ms_macro';
Ausgabe:
| count() |
|---|
| 1 |
Überprüfen Sie, ob ms_macro 8.841.823 Datensätze enthält:
SELECT count(*) FROM default.ms_macro;
Ausgabe:
| count() |
|---|
| 8841823 |
# Indexerstellung
Wir werden die Leistung von drei Arten von Indizes bewerten: FTS, Inverted und None (ein Szenario ohne Index).
- FTS-Index erstellen
-- Stellen Sie sicher, dass beim Erstellen des FTS-Index kein anderer Index auf der Textspalte von ms_macro vorhanden ist.
ALTER TABLE default.ms_macro DROP INDEX IF EXISTS fts_idx;
ALTER TABLE default.ms_macro ADD INDEX fts_idx text TYPE fts;
ALTER TABLE default.ms_macro MATERIALIZE INDEX fts_idx;
- Inverted-Index erstellen
-- Stellen Sie sicher, dass beim Erstellen des Inverted-Index kein anderer Index auf der Textspalte von ms_macro vorhanden ist.
ALTER TABLE default.ms_macro DROP INDEX IF EXISTS inverted_idx;
ALTER TABLE default.ms_macro ADD INDEX inverted_idx text TYPE inverted;
ALTER TABLE default.ms_macro MATERIALIZE INDEX inverted_idx;
- Kein Index: Stellen Sie sicher, dass die Textspalte der ms_macro-Tabelle keinen Index enthält.
# Durchführung des Benchmarks
Verwenden Sie clickhouse-benchmark für den Stresstest. Weitere Anweisungen zur Verwendung finden Sie in der ClickHouse-Dokumentation (opens new window).
clickhouse-benchmark -c 8 --timelimit=60 --randomize --log_queries=0 --delay=0 < ms_macro_count_hastoken_100_100k.sql -h 127.0.0.1 --port 9000
# Bewertungsergebnisse
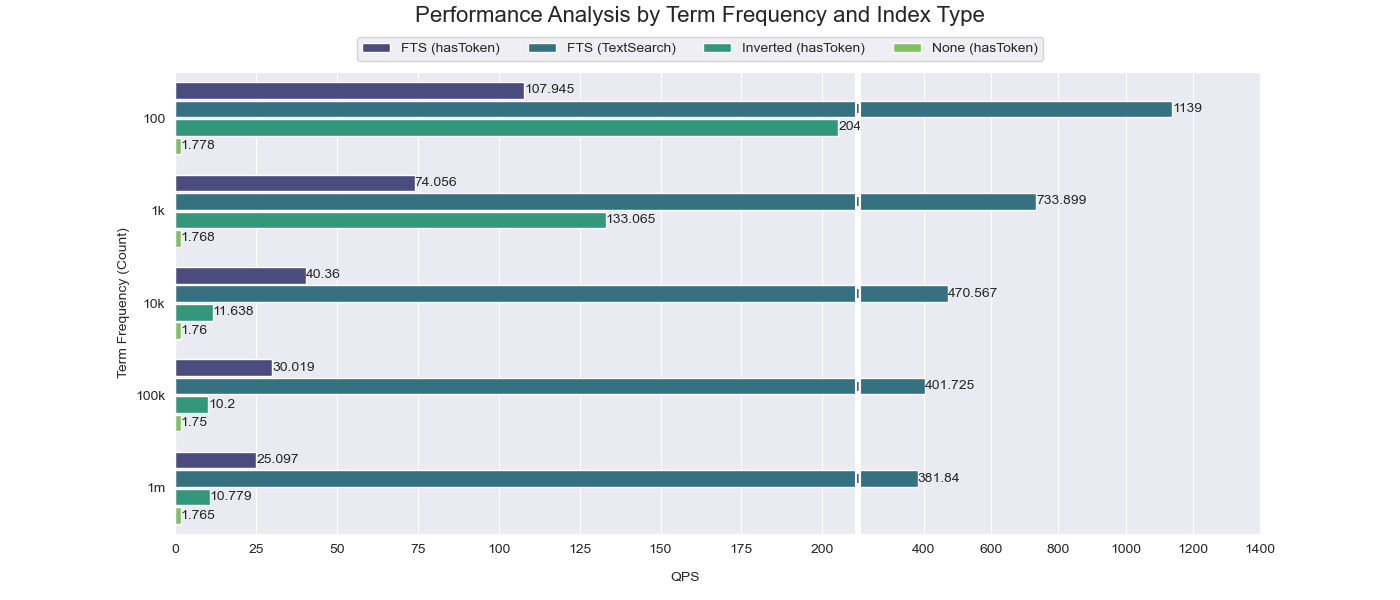
Aus den Vergleichsergebnissen geht hervor, dass der Beschleunigungseffekt des Skipping-Index bei hoher Häufigkeit des gesuchten Wortes (100K~1M) recht begrenzt ist (nur eine zehnfache Verbesserung im Vergleich zur Leistung ohne Einrichtung eines Index). Wenn die Häufigkeit des gesuchten Wortes jedoch niedrig ist (100~1K), kann der Skipping-Index einen erheblichen Beschleunigungseffekt erzielen (bis zu einer hundertfachen Verbesserung im Vergleich zur Leistung ohne Einrichtung eines Index).
Die TextSearch-Funktion hingegen übertrifft sowohl den Skipping-Index als auch den Inverted-Index in allen Szenarien. Dies liegt daran, dass TextSearch direkt die Volltextsuchfunktionen von Tantivy nutzt und somit das Durchsuchen von Granulen umgeht und die Ergebnisse direkt aus dem Index abruft. Dies führt zu einem viel schnelleren und effizienteren Suchprozess.
# Fazit
Die Integration von Tantivy in MyScaleDB hat die Textsuchfunktionen erheblich verbessert und macht sie zu einem leistungsstarken Werkzeug für die Analyse von Textdaten und die Retrieval-Augmented Generation (RAG) mit großen Sprachmodellen (LLMs). Durch die Behebung der Einschränkungen der nativen Textsuchefunktionen von ClickHouse und die Einführung fortschrittlicher Funktionen wie der BM25-Relevanzbewertung, konfigurierbarer Tokenizer und natürlicher Sprachabfragen bietet MyScaleDB nun eine robuste und effiziente Lösung für komplexe Textsuchanforderungen.
Die Implementierung eines C++-Wrappers für Tantivy, die Erstellung eines neuen Skipping-Index und die Einführung der TextSearch-Funktion haben alle zu dieser Verbesserung beigetragen. Diese Verbesserungen steigern nicht nur die Leistung von MyScaleDB, sondern erweitern auch ihre Anwendungsmöglichkeiten und machen sie zur ersten Wahl für eine effiziente und genaue Textsuche in verschiedenen Anwendungen.
Weitere Informationen zur Verwendung der TextSearch-Funktion und anderer Funktionen finden Sie in unserer Dokumentation zur Textsuche (opens new window) und zur hybriden Suche (opens new window).
Wir hoffen, dass dieser Beitrag wertvolle Einblicke in den Integrationsprozess und die Vorteile, die er MyScaleDB bringt, bietet. Bleiben Sie gespannt auf weitere Updates und Verbesserungen, während wir die Fähigkeiten von MyScaleDB weiterentwickeln.



