
# Hybride Suche
HINWEIS
Dieser Leitfaden gilt nur für die DB-Version 1.6.2 oder höher.
Dieser Leitfaden erläutert, wie man eine hybride Volltext- und Vektorsuche in MyScale durchführt.
Sowohl die Volltextsuche als auch die Vektorsuche haben ihre eigenen Stärken und Schwächen. Die Volltextsuche eignet sich hervorragend für die grundlegende Schlüsselwortabfrage und Textübereinstimmung, während die Vektorsuche bei der semantischen Übereinstimmung und dem tiefen Verständnis von Semantik zwischen Dokumenten hervorragende Ergebnisse erzielt, jedoch möglicherweise bei kurzen Textabfragen an Effizienz verliert. Die hybride Suche kombiniert die Vorteile beider Ansätze und verbessert die Genauigkeit und Geschwindigkeit von Textsuchen, um den Erwartungen der Benutzer an präzise Ergebnisse effizient gerecht zu werden.
# Übersicht über das Tutorial
Dieser Leitfaden behandelt:
- Den Wikipedia-Datensatz und das für die hybride Suche verwendete Einbettungsmodell.
- Anweisungen zur Erstellung von Tabellen und zum Aufbau von Indizes.
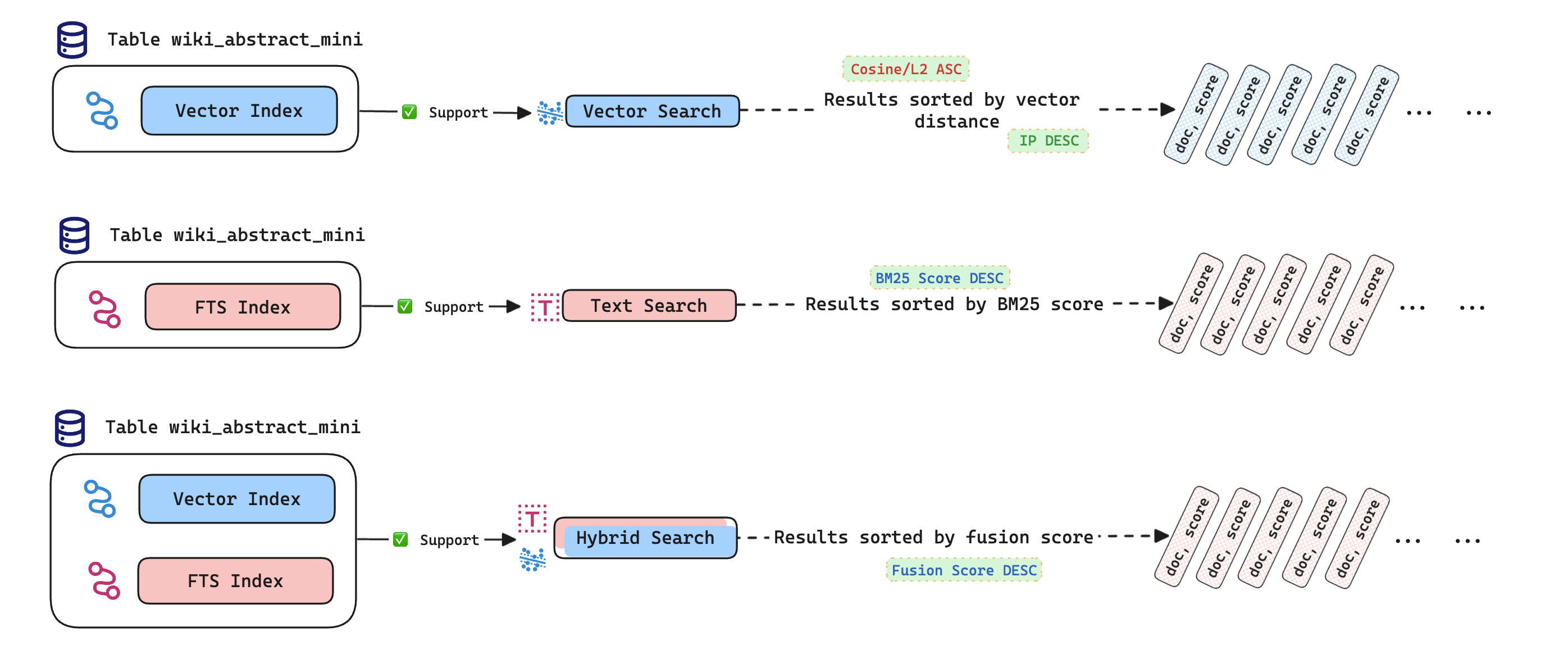
- Die Verwendung der Funktion
HybridSearch(). - Beispiele für die Durchführung von Vektor-, Text- und hybriden Suchen.
Die Funktion HybridSearch() kombiniert die Ergebnisse von Vektor- und Textsuchen, verbessert die Anpassungsfähigkeit in verschiedenen Szenarien und erhöht die Suchgenauigkeit.
Bevor Sie beginnen, stellen Sie sicher, dass Sie einen MyScale-Cluster eingerichtet haben. Für Anweisungen zur Einrichtung lesen Sie unseren Schnellstart-Leitfaden (opens new window).
# Datensatz
Für das Experiment wurde der Wikipedia-Abstract-Datensatz (opens new window) von RediSearch verwendet, der 5.622.309 Dokumenteinträge umfasst. Wir haben die ersten 100.000 Einträge ausgewählt und sie mit dem Modell multilingual-e5-large (opens new window) in 1024-dimensionale Vektoren umgewandelt, die in der Spalte body_vector gespeichert sind. Die Ähnlichkeit zwischen den Vektoren wurde mit dem Kosinusabstand berechnet.
TIP
Weitere Informationen zur Verwendung von multilingual-e5-large finden Sie in der Dokumentation von HuggingFace (opens new window).
Der Datensatz wiki_abstract_100000_1024D.parquet (opens new window) hat eine Größe von 668 MB und enthält 100.000 Einträge. Sie können den Inhalt unten einsehen, ohne ihn lokal herunterladen zu müssen, da wir ihn in den folgenden Experimenten direkt über S3 in MyScale importieren werden.
| id | body | title | url | body_vector |
|---|---|---|---|---|
| ... | ... | ... | ... | ... |
| 78 | A total solar ... the Sun for a viewer on Earth. | Solar eclipse of November 12, 1985 | https://en.wikipedia.org/wiki/Solar_eclipse_of_November_12,_1985 (opens new window) | [1.4270141,...,-1.2265089] |
| 79 | Dhamangaon Badhe is a town ... Aurangabad districts. | Dhamangaon Badhe | https://en.wikipedia.org/wiki/Dhamangaon_Badhe (opens new window) | [0.6736672,....,0.12504958] |
| ... | ... | ... | ... | ... |
# Tabellenerstellung und Datenimport
Um die Tabelle wiki_abstract_mini im SQL-Arbeitsbereich von MyScale zu erstellen, führen Sie die folgende SQL-Anweisung aus:
CREATE TABLE default.wiki_abstract_mini(
`id` UInt64,
`body` String,
`title` String,
`url` String,
`body_vector` Array(Float32),
CONSTRAINT check_length CHECK length(body_vector) = 1024
)
ENGINE = MergeTree
ORDER BY id
SETTINGS index_granularity = 128;
Importieren Sie die Daten aus S3 in die Tabelle. Bitte haben Sie Geduld während des Datenimportprozesses.
INSERT INTO default.wiki_abstract_mini
SELECT * FROM s3('https://myscale-datasets.s3.ap-southeast-1.amazonaws.com/wiki_abstract_100000_1024D.parquet', 'Parquet');
Hinweis
Die geschätzte Zeit für den Datenimport beträgt etwa 10 Minuten.
Überprüfen Sie, ob 100.000 Zeilen Daten in der Tabelle vorhanden sind, indem Sie die folgende Abfrage ausführen:
SELECT count(*) FROM default.wiki_abstract_mini;
Ausgabe:
| count() |
|---|
| 100000 |
# Index erstellen
# FTS-Index erstellen
TIP
Weitere Informationen zur Erstellung eines FTS-Index finden Sie in der Dokumentation zur Textsuche.
Bei der Einrichtung eines FTS-Index haben Benutzer die Möglichkeit, den Tokenizer anzupassen. In diesem Beispiel wird der stem-Tokenizer zusammen mit der Anwendung von Stoppwörtern verwendet. Der stem-Tokenizer kann Wortformen in Texten übersehen, um präzisere Suchergebnisse zu erzielen. Durch die Verwendung von Stoppwörtern werden häufige Wörter wie "ein", "eine", "von" und "in" herausgefiltert, um die Suchgenauigkeit zu verbessern.
ALTER TABLE default.wiki_abstract_mini
ADD INDEX body_idx (body)
TYPE fts('{"body":{"tokenizer":{"type":"stem", "stop_word_filters":["german"]}}}');
Führen Sie die Materialisierung des Index aus:
ALTER TABLE default.wiki_abstract_mini MATERIALIZE INDEX body_idx;
# Vektorindex erstellen
TIP
Weitere Informationen zum MSTG-Vektorindex finden Sie in der Dokumentation zur Vektorsuche.
Um den MSTG-Vektorindex mit Kosinusabstand für den body_vec_idx in der Tabelle default.wiki_abstract_mini zu erstellen, führen Sie die folgende SQL-Anweisung aus:
ALTER TABLE default.wiki_abstract_mini
ADD VECTOR INDEX body_vec_idx body_vector
TYPE MSTG('metric_type=Cosine');
Der Aufbau eines Vektorindex kann zeitaufwändig sein. Um den Fortschritt zu überwachen, führen Sie die folgende SQL-Abfrage aus. Wenn die Spalte "status" "Built" anzeigt, wurde der Index erfolgreich erstellt. Wenn "InProgress" angezeigt wird, ist der Vorgang noch nicht abgeschlossen.
SELECT * FROM system.vector_indices;
# HybridSearch-Funktion
Die HybridSearch()-Funktion in MyScale führt hybride Suchen durch, indem sie die Ergebnisse von Vektor- und Textsuchen kombiniert und die besten Kandidaten zurückgibt. Die grundlegende Syntax lautet:
HybridSearch('dense_param1 = value1', 'param2 = value2')(vector_column, text_column, query_vector, query_text)
params: Suchspezifische Parameter. Parameter, die mitdense_beginnen, sind für die Vektorsuche. Zum Beispiel setztdense_alphaden Parameteralphafür den MSTG-Vektorindex.vector_column: Spalte, die die zu durchsuchenden Vektordaten enthält.text_column: Spalte, die die zu durchsuchenden Textdaten enthält.query_vector: Zu durchsuchender Vektor.query_text: Zu durchsuchender Text.
Verwenden Sie die HybridSearch-Funktion mit einer ORDER BY-Klausel und einer LIMIT-Klausel, um die besten Kandidaten abzurufen. Die Sortierrichtung für Spalten in der ORDER BY-Klausel muss auf DESC gesetzt sein.
# Erläuterung der HybridSearch-Parameter
Nachfolgend finden Sie eine detaillierte Beschreibung der HybridSearch()-Parameter:
| Parameter | Default Value | Candidate Values | Description |
|---|---|---|---|
fusion_type | N/A | rsf, rrf | Determines the combination method in hybrid search. rsf stands for Relative Score Fusion, and rrf stands for Reciprocal Rank Fusion. This parameter is required. |
fusion_weight | 0.5 | Floating point number between 0 - 1 | Specifies the weight |
fusion_k | 60 | Positive integer no less than 1 | Specifies the sorting constant |
enable_nlq | true | true, false | Indicates whether to use natural language queries in text search. |
operator | OR | OR, AND | Specifies the logical operator used to combine terms in text search. |
# Fusionstypen
Die hybride Suche kombiniert den BM25-Score aus Textsuchen (bezeichnet als
- Relative Score Fusion (RSF): Bei RSF werden die Scores aus Vektor- und Textsuchen zwischen 0 und 1 normalisiert. Der höchste Rohscore wird auf 1 gesetzt, während der niedrigste auf 0 gesetzt wird und alle anderen Werte proportional in diesem Bereich eingestuft werden. Der endgültige Score ist eine gewichtete Summe dieser normalisierten Scores:
Die verwendete Normalisierungsformel lautet:
- Reciprocal Rank Fusion (RRF): RRF erfordert keine Score-Normalisierung. Stattdessen werden die Ergebnisse basierend auf ihrer Position in jedem Ergebnissatz mit der folgenden Formel gerankt, wobei
# Vektor-, Text- und hybride Suche durchführen
# Eine Einbettungsfunktion erstellen
Um Abfragetext in Vektoren umzuwandeln, verwenden wir das Modell multilingual-e5-large (opens new window).
Dank der Einbettungsfunktionen von MyScale ist die Online-Umwandlung von Text in Vektoren einfach. Wir werden eine Einbettungsfunktion MultilingualE5Large für diesen Zweck erstellen.
TIP
Sie benötigen einen kostenlosen Schlüssel von HuggingFace, um eine Einbettungsfunktion zu erstellen.
CREATE FUNCTION MultilingualE5Large
ON CLUSTER '{cluster}' AS (x) -> EmbedText (
concat('query: ', x),
'HuggingFace',
'https://api-inference.huggingface.co/models/intfloat/multilingual-e5-large',
'<Ihr HuggingFace-Schlüssel, beginnt mit `hf_`>',
''
);
# Vektorsuche durchführen
TIP
Die British Graham Land Expedition (BGLE) war eine britische Expedition. Weitere Informationen über sie finden Sie in der Wikipedia (opens new window).
Die Vektorsuche funktioniert im Allgemeinen gut im Bereich langer Texte, aber ihre Effektivität kann im Bereich kurzer Texte abnehmen. Um die Suchleistung für verschiedene Textlängen zu veranschaulichen, werden wir zwei Beispiele für Vektorsuchen präsentieren. Der Inhalt, den wir suchen, bezieht sich auf Orte, die vom BGLE-Expeditionsteam markiert wurden, wobei der Unterschied zwischen den beiden Sätzen darin besteht, ob die Abkürzung des Teamnamens verwendet wird.
- Beispiel 1: langer Text: 'Vermessen von der British Graham Land Expedition'
SELECT
id,
title,
body,
distance('alpha=3')(body_vector, MultilingualE5Large('Vermessen von der British Graham Land Expedition')) AS score
FROM default.wiki_abstract_mini
ORDER BY score ASC
LIMIT 5;
Aus den folgenden Suchergebnissen wird deutlich, dass die Vektorsuche bei der Übereinstimmung langer Texte hervorragende Ergebnisse erzielt, da vier der fünf besten Suchergebnisse unseren Kriterien entsprechen.
| id | title | body | score |
|---|---|---|---|
| 15145 | Paragon Point | Paragon Point () is a small but prominent point on the southwest side of Leroux Bay, 3 nautical miles (6 km) west-southwest of Eijkman Point on the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.17197883 |
| 16459 | Link Stack | Link Stack () is a rocky pillar at the northwest end of Chavez Island, off the west coast of Graham Land, Antarctica. It was charted by the British Graham Land Expedition under John Rymill, 1934–37. | 0.17324567 |
| 47359 | Huitfeldt Point | Huitfeldt Point is a point southeast of Vorweg Point on the southwest side of Barilari Bay, on the west coast of Graham Land, Antarctica. It was charted by the British Graham Land Expedition under John Rymill, 1934–37, and was named by the UK Antarctic Place-Names Committee in 1959 for Fritz R. | 0.17347288 |
| 48138 | Santos Peak | Santos Peak () is a peak lying south of Murray Island, on the west coast of Graham Land. Charted by the Belgian Antarctic Expedition under Gerlache, 1897-99. | 0.17546016 |
| 15482 | Parvenu Point | Parvenu Point () is a low but prominent point forming the north extremity of Pourquoi Pas Island, off the west coast of Graham Land. First surveyed in 1936 by the British Graham Land Expedition (BGLE) under Rymill. | 0.17611909 |
- Beispiel 2: kurzer Text: 'Vermessen von der BGLE'
SELECT
id,
title,
body,
distance('alpha=3')(body_vector, MultilingualE5Large('Vermessen von der BGLE')) AS score
FROM default.wiki_abstract_mini
ORDER BY score ASC
LIMIT 5;
Bei der Betrachtung der Suchergebnisse für kurze Texte wird jedoch deutlich, dass die Vektorsuche in diesem Bereich weniger effektiv ist, da keines der fünf besten Dokumente Informationen über BGLE enthält.
| id | title | body | score |
|---|---|---|---|
| 17693 | Têtes Raides | | current_members = Christian OlivierGrégoire SimonPascal OlivierAnne-Gaëlle BisquaySerge BégoutÉdith BégoutPierre GauthéJean-Luc MillotPhilippe Guarracino | 0.19922233 |
| 92351 | Badr al-Din Lu'lu' | right|thumb|250px|Badr al-Din Lu'lu', manuscript illustration from the Kitāb al-Aghānī of [[Abu al-Faraj al-Isfahani (Feyzullah Library No. 1566, Istanbul). | 0.19949186 |
| 45934 | Singing All Along | |show_name_2=|simplified=|pinyin=Xiùlì Jiāngshān Zhī Cháng Gē Xíng|translation=Splendid and Beautiful Rivers and Mountains: Long Journey of Songs}} | 0.2003029 |
| 44708 | LinQ | | current_members =Yumi TakakiSakura ArakiAyano YamakiMYUChiaki Sara YoshikawaRana KaizukiAsaka SakaiKana FukuyamaManami SakuraMaina KohinataChisa Ando | 0.20089924 |
| 43706 | Shorty (crater) | | diameter = 110 mShorty, Gazetteer of Planetary Nomenclature, International Astronomical Union (IAU) Working Group for Planetary System Nomenclature (WGPSN) | 0.20098251 |
# Textsuche durchführen
BM25, ein weit verbreiteter Textsuchalgorithmus, ist sehr ausgereift und besonders für die Übereinstimmung kurzer Texte geeignet. Wenn es jedoch darum geht, die Semantik langer Texte zu verstehen, ist BM25 nicht so effektiv wie die Vektorsuche. Das Folgende zeigt die leistungsstarke Suchfähigkeit von TextSearch() im Bereich kurzer Texte.
- Beispiel: kurzer Text: 'Vermessen von der BGLE'
SELECT
id,
title,
body,
TextSearch(body, 'Vermessen von der BGLE') AS bm25_score
FROM default.wiki_abstract_mini
ORDER BY bm25_score DESC
LIMIT 5;
| id | title | body | bm25_score |
|---|---|---|---|
| 48165 | Salmon Island | Salmon Island () is the westernmost of the Fish Islands, lying off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 15.392099 |
| 47415 | Tadpole Island | Tadpole Island () is an island just north of Ferin Head, off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 15.126007 |
| 48775 | Sohm Glacier | Sohm Glacier () is a glacier flowing into Bilgeri Glacier on Velingrad Peninsula, the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 15.126007 |
| 14327 | Trout Island | Trout Island () is an island just east of Salmon Island in the Fish Islands, off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 14.620504 |
| 49006 | Somers Glacier | Somers Glacier () is a glacier flowing northwest into Trooz Glacier on Kiev Peninsula, the west coast of Graham Land. First charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 14.620504 |
# Hybride Suche durchführen
MyScale bietet die HybridSearch()-Funktion, eine Suchmethode, die die Stärken der Vektorsuche und der Textsuche kombiniert. Dieser Ansatz verbessert nicht nur das Verständnis der Semantik langer Texte, sondern behebt auch die semantischen Mängel der Vektorsuche im Bereich kurzer Texte.
- Beispiel: kurzer Text: Vermessen von der BGLE
SELECT
id,
title,
body,
HybridSearch('fusion_type=RSF', 'fusion_weight=0.6')(body_vector, body, MultilingualE5Large('Vermessen von der BGLE'), ' BGLE') AS score
FROM default.wiki_abstract_mini
ORDER BY score DESC
LIMIT 5;
Basierend auf den Ergebnissen der HybridSearch()-Funktion können wir auch bei der Suche nach kurzen Texten hervorragende Suchergebnisse erzielen und die Genauigkeit erheblich verbessern.
| id | title | body | score |
|---|---|---|---|
| 48165 | Salmon Island | Salmon Island () is the westernmost of the Fish Islands, lying off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.6 |
| 47415 | Tadpole Island | Tadpole Island () is an island just north of Ferin Head, off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.5404912 |
| 48775 | Sohm Glacier | Sohm Glacier () is a glacier flowing into Bilgeri Glacier on Velingrad Peninsula, the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.5404912 |
| 49000 | Sooty Rock | Sooty Rock () is a rock midway between Lumus Rock and Betheder Islands in Wilhelm Archipelago. Discovered and named "Black Reef" by the British Graham Land Expedition (BGLE), 1934-37. | 0.5404912 |
| 14327 | Trout Island | Trout Island () is an island just east of Salmon Island in the Fish Islands, off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.4274415 |
Ab der DB-Version v1.8 oder höher ist es im HybridSearch()-Funktionsmodell möglich, die Textsuchspalte aus einem mehrspaltigen FTS-Index zu verwenden.
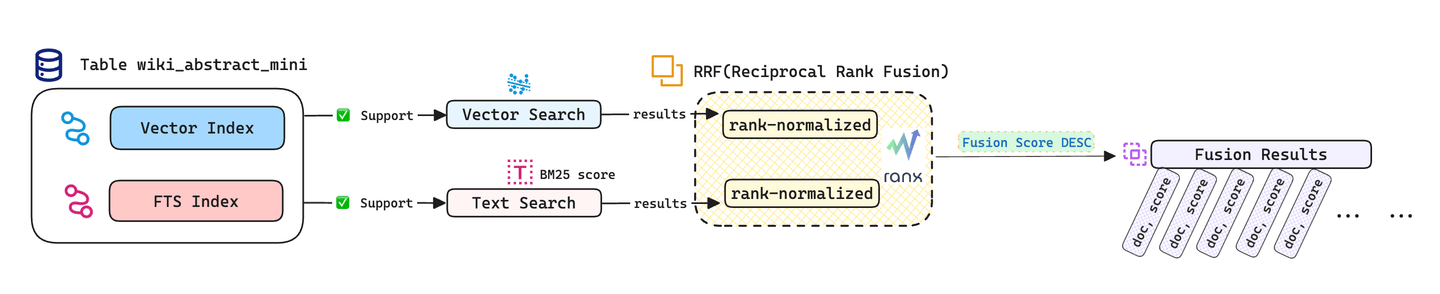
# Hybride Suche außerhalb der Datenbank
Wir können auch die Python-Bibliothek ranx (opens new window) verwenden, um die Ergebnisse von Vektor- und Textsuchen außerhalb der Datenbank zu kombinieren und die RRF-Fusionsstrategie (Reciprocal Rank Fusion) zur Verbesserung der Suchgenauigkeit zu implementieren. Für alternative Fusionsstrategien können Sie ranx/fusion (opens new window) konsultieren.
Bevor Sie den unten stehenden Democode ausführen, sollten Sie ranx installieren:
pip install -U ranx
Beispielcode in Python:
import clickhouse_connect
from numba import NumbaTypeSafetyWarning
from prettytable import PrettyTable
from ranx import Run, fuse
from ranx.normalization import rank_norm
import warnings
warnings.filterwarnings('ignore', category=NumbaTypeSafetyWarning)
# MyScale-Informationen
host = "Ihr Cluster-Endpunkt"
port = 443
username = "Ihr Benutzername"
password = "Ihr Passwort"
database = "default"
table = "wiki_abstract_mini"
# MyScale-Client initialisieren
client = clickhouse_connect.get_client(host=host, port=port, username=username, password=password)
# Eine Tabelle zur Ausgabe der Ergebnisse erstellen
def print_results(result_rows, field_names):
x = PrettyTable()
x.field_names = field_names
for row in result_rows:
x.add_row(row)
print(x)
# Wir möchten nach einem kurzen Text suchen.
terms = "Vermessen von der BGLE"
# VektorSearch ausführen.
vector_search = f"SELECT id, title, body, distance('alpha=3')" \
f"(body_vector, MultilingualE5Large('{terms}')) AS distance FROM {database}.{table} " \
f"ORDER BY distance ASC LIMIT 100"
vector_search_res = client.query(query=vector_search)
# TextSearch ausführen.
text_search = f"SELECT id, title, body, TextSearch(body, '{terms}') AS score " \
f"FROM {database}.{table} " \
f"ORDER BY score DESC LIMIT 100"
text_search_res = client.query(query=text_search)
# VektorSearch- und TextSearch-Ergebnisse extrahieren.
stored_data = {}
for row in vector_search_res.result_rows:
stored_data[str(row[0])] = {"title": row[1], "body": row[2]}
for row in text_search_res.result_rows:
if str(row[0]) not in stored_data:
stored_data[str(row[0])] = {"title": row[1], "body": row[2]}
# Ergebnisse extrahieren.
bm25_dict = {"query-0": {str(row[0]): float(row[3]) for row in text_search_res.result_rows}}
# Für die ranx-Bibliothek wird erwartet, dass ein höherer Score eine größere Relevanz anzeigt,
# daher ist eine Vorverarbeitung für Vektordistanzberechnungsmethoden wie Kosinus und L2 erforderlich.
max_value = max(float(row[3]) for row in vector_search_res.result_rows)
vector_dict = {"query-0": {str(row[0]): max_value - float(row[3]) for row in vector_search_res.result_rows}}
# Normalisierte Ergebnisse.
vector_run = rank_norm(Run(vector_dict, name="vector"))
bm25_run = rank_norm(Run(bm25_dict, name="bm25"))
# Fusion der Ergebnisse mit RRF.
combined_run = fuse(
runs=[vector_run, bm25_run],
method="rrf",
params={'k': 10}
)
print("\nFusionsergebnisse:")
pretty_results = []
for id_, score in combined_run.get_doc_ids_and_scores()[0].items():
if id_ in stored_data:
pretty_results.append([id_, stored_data[id_]["title"], stored_data[id_]["body"], score])
print_results(pretty_results[:5], ["ID", "Titel", "Inhalt", "Score"])
Die fusionierten Suchergebnisse lauten wie folgt: Die hybride Suche hat fünf Artikel genau den Orten zugeordnet, die von der BGLE-Expedition vermessen wurden, und zeigt die Vorteile der hybriden Suche bei der Verarbeitung von Kurztextabfragen.
| ID | Title | Body | Score |
|---|---|---|---|
| 47415 | Tadpole Island | Tadpole Island () is an island just north of Ferin Head, off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.06432246998284734 |
| 15145 | Paragon Point | Paragon Point () is a small but prominent point on the southwest side of Leroux Bay, 3 nautical miles (6 km) west-southwest of Eijkman Point on the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.049188640973630834 |
| 48165 | Salmon Island | Salmon Island () is the westernmost of the Fish Islands, lying off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.047619047619047616 |
| 64566 | Want You Back (Haim song) | format=Digital download | recorded= |
| 45934 | Singing All Along | show_name_2= |
# Fazit
Dieses Dokument gibt Einblicke in die Verwendung der MyScale Hybrid-Suche und konzentriert sich auf Methoden und Techniken zur Suche in unstrukturierten Textdaten. In der praktischen Übung haben wir ein Beispiel mit Wikipedia-Abstracts entwickelt. Die Durchführung einer Hybrid-Suche ist mit den fortschrittlichen Volltext- und Vektorsuchfunktionen von MyScale einfach und liefert genauere Ergebnisse, indem sowohl Schlüsselwort- als auch semantische Informationen kombiniert werden.