
# ハイブリッド検索
注意
このガイドは、DBバージョン1.6.2以降にのみ適用されます。
このガイドでは、MyScaleでの全文検索とベクトル検索のハイブリッド検索の方法について説明します。
全文検索とベクトル検索は、それぞれ独自の強みと弱点があります。全文検索は基本的なキーワードの検索とテキストのマッチングに優れていますが、ベクトル検索はクロスドキュメントの意味的なマッチングや深い意味の理解に優れていますが、短いテキストクエリでは効率が低下する場合があります。ハイブリッド検索は、両方のアプローチの利点を組み合わせ、テキスト検索の精度と速度を向上させ、ユーザーの期待に応えるために効率的な正確な結果を提供します。
# チュートリアルの概要
このガイドでは、以下の内容をカバーしています:
- Wikipediaのデータセットとハイブリッド検索に使用される埋め込みモデル。
- テーブルの作成とインデックスの構築の手順。
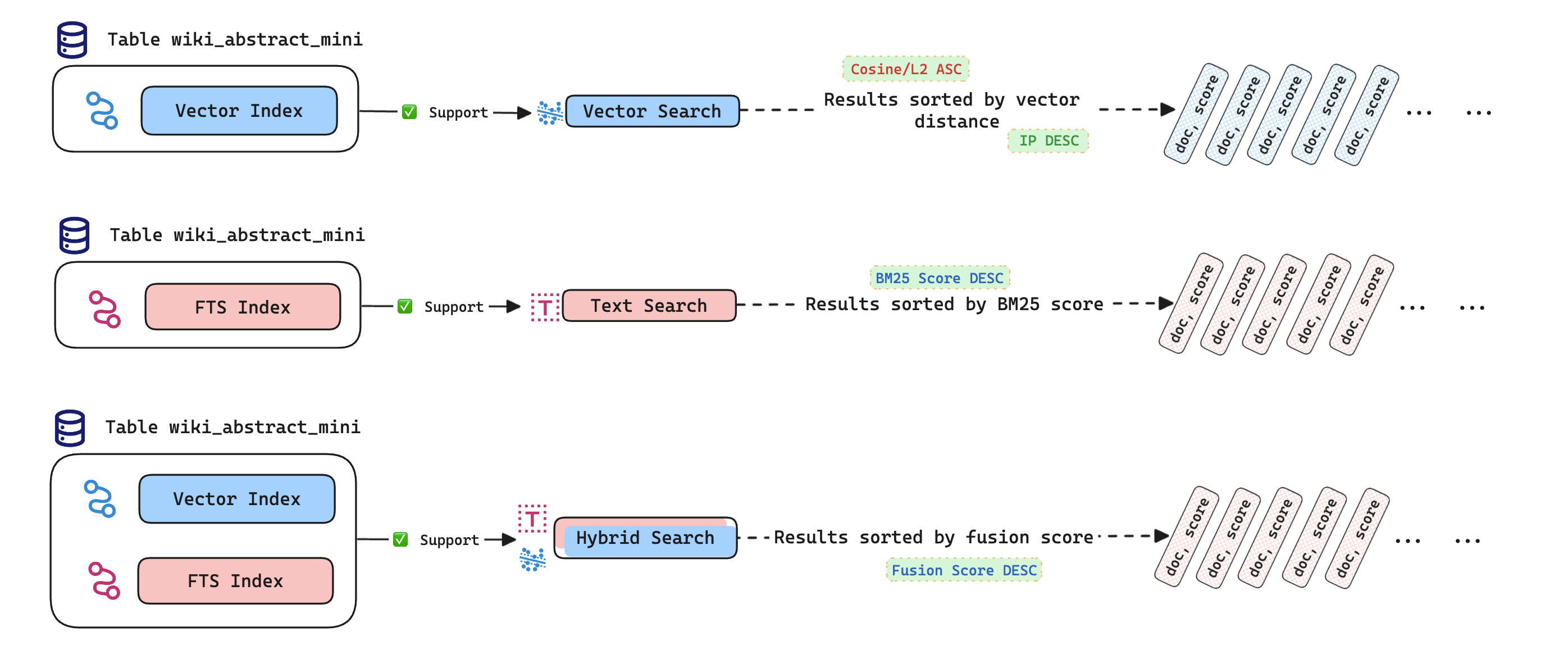
HybridSearch()関数の使用方法。- ベクトル、テキスト、ハイブリッド検索の実行例。
HybridSearch()関数は、ベクトル検索とテキスト検索の結果を組み合わせて、異なるシナリオでの適応性を高め、検索の精度を向上させます。
開始する前に、MyScaleクラスターが設定されていることを確認してください。セットアップ手順については、クイックスタートガイド (opens new window)を参照してください。
# データセット
この実験では、RediSearchが提供するWikipediaの要約データセット (opens new window)を使用しました。このデータセットには5,622,309のドキュメントエントリが含まれています。最初の10万のエントリを選択し、multilingual-e5-large (opens new window)モデルを使用してbody_vector列に格納された1024次元のベクトルを作成しました。ベクトル間の類似度は、コサイン距離を使用して計算されました。
TIP
multilingual-e5-largeの使用方法の詳細については、HuggingFaceのドキュメント (opens new window)を参照してください。
データセットwiki_abstract_100000_1024D.parquet (opens new window)は、サイズが668MBで、10万のエントリが含まれています。このデータをローカルにダウンロードする必要はありません。後続の実験では、S3経由で直接MyScaleにインポートします。
| id | body | title | url | body_vector |
|---|---|---|---|---|
| ... | ... | ... | ... | ... |
| 78 | A total solar ... the Sun for a viewer on Earth. | Solar eclipse of November 12, 1985 | https://en.wikipedia.org/wiki/Solar_eclipse_of_November_12,_1985 (opens new window) | [1.4270141,...,-1.2265089] |
| 79 | Dhamangaon Badhe is a town ... Aurangabad districts. | Dhamangaon Badhe | https://en.wikipedia.org/wiki/Dhamangaon_Badhe (opens new window) | [0.6736672,....,0.12504958] |
| ... | ... | ... | ... | ... |
# テーブルの作成とデータのインポート
MyScaleのSQLワークスペースでwiki_abstract_miniテーブルを作成するには、次のSQLステートメントを実行します。
CREATE TABLE default.wiki_abstract_mini(
`id` UInt64,
`body` String,
`title` String,
`url` String,
`body_vector` Array(Float32),
CONSTRAINT check_length CHECK length(body_vector) = 1024
)
ENGINE = MergeTree
ORDER BY id
SETTINGS index_granularity = 128;
S3からデータをテーブルにインポートします。データのインポートプロセス中は、お待ちください。
INSERT INTO default.wiki_abstract_mini
SELECT * FROM s3('https://myscale-datasets.s3.ap-southeast-1.amazonaws.com/wiki_abstract_100000_1024D.parquet', 'Parquet');
注意
データのインポートには約10分かかる見込みです。
次のクエリを実行して、テーブルに100,000行のデータがあるかどうかを確認します。
SELECT count(*) FROM default.wiki_abstract_mini;
出力:
| count() |
|---|
| 100000 |
# インデックスの構築
# FTSインデックスの作成
TIP
FTSインデックスの作成方法については、テキスト検索のドキュメントを参照してください。
FTSインデックスを設定する際に、ユーザーはトークナイザーをカスタマイズするオプションがあります。この例では、stemトークナイザーを使用し、ストップワードを適用しています。stemトークナイザーは、テキスト内の単語の時制を無視してより正確な検索結果を得ることができます。ストップワードを使用することで、「a」、「an」、「of」、「in」などの一般的な単語をフィルタリングして検索の精度を向上させることができます。
ALTER TABLE default.wiki_abstract_mini
ADD INDEX body_idx (body)
TYPE fts('{"body":{"tokenizer":{"type":"stem", "stop_word_filters":["english"]}}}');
インデックスのマテリアライズを実行します。
ALTER TABLE default.wiki_abstract_mini MATERIALIZE INDEX body_idx;
# ベクトルインデックスの作成
TIP
MSTGベクトルインデックスについての詳細は、ベクトル検索のドキュメントを参照してください。
default.wiki_abstract_miniテーブルのbody_vec_idxにCosine距離を使用してMSTGベクトルインデックスを作成するには、次のSQLステートメントを実行します。
ALTER TABLE default.wiki_abstract_mini
ADD VECTOR INDEX body_vec_idx body_vector
TYPE MSTG('metric_type=Cosine');
ベクトルインデックスの構築には時間がかかる場合があります。進行状況を監視するために、次のSQLクエリを実行します。ステータス列がBuiltと表示される場合、インデックスが正常に作成されています。InProgressと表示される場合は、プロセスがまだ進行中です。
SELECT * FROM system.vector_indices;
# HybridSearch関数
MyScaleのHybridSearch()関数は、ベクトル検索とテキスト検索の結果を組み合わせて、上位の候補を返すことでハイブリッド検索を実行します。基本的な構文は次のとおりです。
HybridSearch('dense_param1 = value1', 'param2 = value2')(vector_column, text_column, query_vector, query_text)
params: 検索固有のパラメータ。dense_で始まるパラメータはベクトル検索用です。たとえば、dense_alphaはMSTGベクトルインデックスのalphaパラメータを設定します。vector_column: 検索対象のベクトルデータが含まれる列。text_column: 検索対象のテキストデータが含まれる列。query_vector: 検索するベクトル。query_text: 検索するテキスト。
ORDER BY句とLIMIT句を使用して、上位の候補を取得するためにHybridSearch関数を使用します。ORDER BY句の列のソート方向はDESCに設定する必要があります。
# HybridSearchパラメータの説明
以下に、HybridSearch()のパラメータの詳細な説明を示します。
| Parameter | Default Value | Candidate Values | Description |
|---|---|---|---|
fusion_type | N/A | rsf, rrf | Determines the combination method in hybrid search. rsf stands for Relative Score Fusion, and rrf stands for Reciprocal Rank Fusion. This parameter is required. |
fusion_weight | 0.5 | Floating point number between 0 - 1 | Specifies the weight |
fusion_k | 60 | Positive integer no less than 1 | Specifies the sorting constant |
enable_nlq | true | true, false | Indicates whether to use natural language queries in text search. |
operator | OR | OR, AND | Specifies the logical operator used to combine terms in text search. |
# 結合タイプ
ハイブリッド検索では、テキスト検索のBM25スコア(lexicalの略称で
- Relative Score Fusion (RSF): RSFでは、ベクトル検索とテキスト検索のスコアを0から1の範囲に正規化します。最高の生のスコアは1に設定され、最低のスコアは0に設定され、その他の値はこの範囲内で比例的にランク付けされます。最終的なスコアは、これらの正規化されたスコアの重み付き合計です。
使用される正規化の式は次のとおりです。
- Reciprocal Rank Fusion (RRF): RRFでは、スコアの正規化は必要ありません。代わりに、各結果セット内の位置に基づいて結果をランク付けします。以下の式を使用してランクを計算します。
# ベクトル検索、テキスト検索、ハイブリッド検索の実行
# 埋め込み関数の作成
クエリテキストをベクトルに変換するために、multilingual-e5-large (opens new window)モデルを使用します。
HuggingFaceのキー (opens new window)を取得して、埋め込み関数MultilingualE5Largeを作成します。
TIP
HuggingFaceの無料キーが必要です。
CREATE FUNCTION MultilingualE5Large
ON CLUSTER '{cluster}' AS (x) -> EmbedText (
concat('query: ', x),
'HuggingFace',
'https://api-inference.huggingface.co/models/intfloat/multilingual-e5-large',
'<your huggingface key, starts with `hf_`>',
''
);
# ベクトル検索の実行
一般的に、ベクトル検索は長いテキストのドメインでは優れたパフォーマンスを発揮しますが、短いテキストのドメインでは効果が低下する可能性があります。異なるテキストの長さに対する検索パフォーマンスを示すために、ベクトル検索の2つの例を示します。検索対象のコンテンツは、BGLE遠征チームによってマークされた場所に関連するもので、2つの文の違いは、チームの名前の略語を使用するかどうかです。
- 例1. 長いテキストクエリ: 'Charted by the British Graham Land Expedition'
SELECT
id,
title,
body,
distance('alpha=3')(body_vector, MultilingualE5Large('Charted by the British Graham Land Expedition')) AS score
FROM default.wiki_abstract_mini
ORDER BY score ASC
LIMIT 5;
以下の検索結果から、ベクトル検索は長いテキストのマッチングに優れており、上位5つの検索結果のうち4つが基準を満たしていることがわかります。
| id | title | body | score |
|---|---|---|---|
| 15145 | Paragon Point | Paragon Point () is a small but prominent point on the southwest side of Leroux Bay, 3 nautical miles (6 km) west-southwest of Eijkman Point on the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.17197883 |
| 16459 | Link Stack | Link Stack () is a rocky pillar at the northwest end of Chavez Island, off the west coast of Graham Land, Antarctica. It was charted by the British Graham Land Expedition under John Rymill, 1934–37. | 0.17324567 |
| 47359 | Huitfeldt Point | Huitfeldt Point is a point southeast of Vorweg Point on the southwest side of Barilari Bay, on the west coast of Graham Land, Antarctica. It was charted by the British Graham Land Expedition under John Rymill, 1934–37, and was named by the UK Antarctic Place-Names Committee in 1959 for Fritz R. | 0.17347288 |
| 48138 | Santos Peak | Santos Peak () is a peak lying south of Murray Island, on the west coast of Graham Land. Charted by the Belgian Antarctic Expedition under Gerlache, 1897-99. | 0.17546016 |
| 15482 | Parvenu Point | Parvenu Point () is a low but prominent point forming the north extremity of Pourquoi Pas Island, off the west coast of Graham Land. First surveyed in 1936 by the British Graham Land Expedition (BGLE) under Rymill. | 0.17611909 |
- 例2. 短いテキストクエリ: 'Charted by the BGLE'
SELECT
id,
title,
body,
distance('alpha=3')(body_vector, MultilingualE5Large('Charted by the BGLE')) AS score
FROM default.wiki_abstract_mini
ORDER BY score ASC
LIMIT 5;
しかし、短いテキストの検索結果を調べると、上位5つのドキュメントにはBGLEに関する情報が含まれていないことが明らかになります。
| id | title | body | score |
|---|---|---|---|
| 17693 | Têtes Raides | | current_members = Christian OlivierGrégoire SimonPascal OlivierAnne-Gaëlle BisquaySerge BégoutÉdith BégoutPierre GauthéJean-Luc MillotPhilippe Guarracino | 0.19922233 |
| 92351 | Badr al-Din Lu'lu' | right|thumb|250px|Badr al-Din Lu'lu', manuscript illustration from the Kitāb al-Aghānī of [[Abu al-Faraj al-Isfahani (Feyzullah Library No. 1566, Istanbul). | 0.19949186 |
| 45934 | Singing All Along | |show_name_2=|simplified=|pinyin=Xiùlì Jiāngshān Zhī Cháng Gē Xíng|translation=Splendid and Beautiful Rivers and Mountains: Long Journey of Songs}} | 0.2003029 |
| 44708 | LinQ | | current_members =Yumi TakakiSakura ArakiAyano YamakiMYUChiaki Sara YoshikawaRana KaizukiAsaka SakaiKana FukuyamaManami SakuraMaina KohinataChisa Ando | 0.20089924 |
| 43706 | Shorty (crater) | | diameter = 110 mShorty, Gazetteer of Planetary Nomenclature, International Astronomical Union (IAU) Working Group for Planetary System Nomenclature (WGPSN) | 0.20098251 |
# テキスト検索の実行
BM25は、広く使用されているテキスト検索アルゴリズムであり、特に短いテキストのマッチングに適しています。ただし、長いテキストの意味を理解する場合には、BM25はベクトル検索ほど効果的ではありません。以下は、短いテキストの領域でのTextSearch()の強力な検索機能を示す例です。
- 例. 短いテキストクエリ: 'Charted by the BGLE'
SELECT
id,
title,
body,
TextSearch(body, 'Charted by the BGLE') AS bm25_score
FROM default.wiki_abstract_mini
ORDER BY bm25_score DESC
LIMIT 5;
| id | title | body | bm25_score |
|---|---|---|---|
| 48165 | Salmon Island | Salmon Island () is the westernmost of the Fish Islands, lying off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 15.392099 |
| 47415 | Tadpole Island | Tadpole Island () is an island just north of Ferin Head, off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 15.126007 |
| 48775 | Sohm Glacier | Sohm Glacier () is a glacier flowing into Bilgeri Glacier on Velingrad Peninsula, the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 15.126007 |
| 14327 | Trout Island | Trout Island () is an island just east of Salmon Island in the Fish Islands, off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 14.620504 |
| 49006 | Somers Glacier | Somers Glacier () is a glacier flowing northwest into Trooz Glacier on Kiev Peninsula, the west coast of Graham Land. First charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 14.620504 |
# ハイブリッド検索の実行
MyScaleは、ベクトル検索とテキスト検索の利点を組み合わせた検索方法であるHybridSearch()関数を提供しています。このアプローチは、長いテキストの意味を理解する能力を向上させるだけでなく、短いテキストのドメインにおけるベクトル検索の意味的な欠点に対処します。
- 例. 短いテキストクエリ: Charted by the BGLE
SELECT
id,
title,
body,
HybridSearch('fusion_type=RSF', 'fusion_weight=0.6')(body_vector, body, MultilingualE5Large('Charted by the BGLE'), ' BGLE') AS score
FROM default.wiki_abstract_mini
ORDER BY score DESC
LIMIT 5;
HybridSearch()関数から得られた結果に基づいて、短いテキストの検索でも優れた検索結果を得ることができ、精度が大幅に向上しています。
| id | title | body | score |
|---|---|---|---|
| 48165 | Salmon Island | Salmon Island () is the westernmost of the Fish Islands, lying off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.6 |
| 47415 | Tadpole Island | Tadpole Island () is an island just north of Ferin Head, off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.5404912 |
| 48775 | Sohm Glacier | Sohm Glacier () is a glacier flowing into Bilgeri Glacier on Velingrad Peninsula, the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.5404912 |
| 49000 | Sooty Rock | Sooty Rock () is a rock midway between Lumus Rock and Betheder Islands in Wilhelm Archipelago. Discovered and named "Black Reef" by the British Graham Land Expedition (BGLE), 1934-37. | 0.5404912 |
| 14327 | Trout Island | Trout Island () is an island just east of Salmon Island in the Fish Islands, off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.4274415 |
DBバージョンv1.8以上では、HybridSearch()関数において、複数列のFTSインデックスからテキスト検索カラムを使用することが許可されています。
# データベース外でのハイブリッド検索
ベクトル検索とテキスト検索の結果をデータベース外で組み合わせるために、Pythonのranx (opens new window)ライブラリを使用することもできます。RRF(Reciprocal Rank Fusion)の結合戦略を実装するためにranxライブラリを使用し、検索の精度を向上させることができます。他の結合戦略については、ranx/fusion (opens new window)を参照してください。
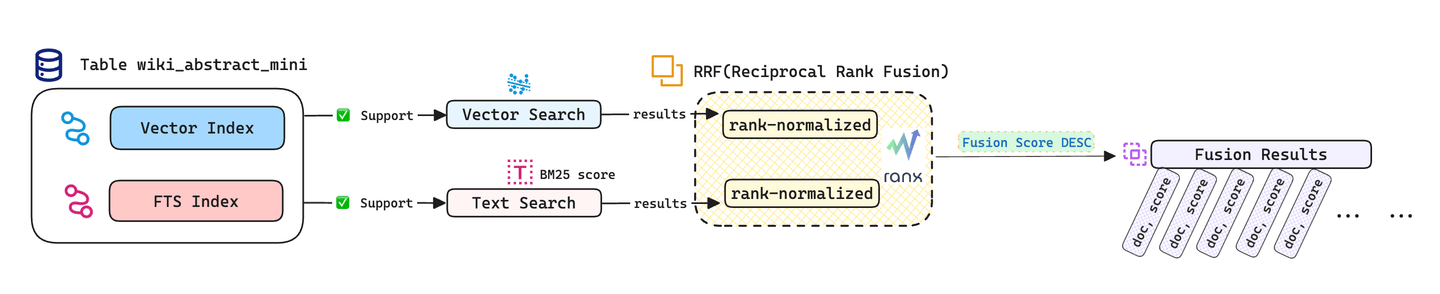
以下のデモコードを実行する前に、ranxをインストールする必要があります。
pip install -U ranx
Pythonのサンプルコード:
import clickhouse_connect
from numba import NumbaTypeSafetyWarning
from prettytable import PrettyTable
from ranx import Run, fuse
from ranx.normalization import rank_norm
import warnings
warnings.filterwarnings('ignore', category=NumbaTypeSafetyWarning)
# MyScaleの情報
host = "your cluster end-point"
port = 443
username = "your user name"
password = "your password"
database = "default"
table = "wiki_abstract_mini"
# MyScaleクライアントの初期化
client = clickhouse_connect.get_client(host=host, port=port, username=username, password=password)
# コンテンツを出力するためのテーブルを使用します
def print_results(result_rows, field_names):
x = PrettyTable()
x.field_names = field_names
for row in result_rows:
x.add_row(row)
print(x)
# 短いテキストを検索したい場合
terms = "Charted by BGLE"
# ベクトル検索を実行します。
vector_search = f"SELECT id, title, body, distance('alpha=3')" \
f"(body_vector, MultilingualE5Large('{terms}')) AS distance FROM {database}.{table} " \
f"ORDER BY distance ASC LIMIT 100"
vector_search_res = client.query(query=vector_search)
# テキスト検索を実行します。
text_search = f"SELECT id, title, body, TextSearch(body, '{terms}') AS score " \
f"FROM {database}.{table} " \
f"ORDER BY score DESC LIMIT 100"
text_search_res = client.query(query=text_search)
# ベクトル検索とテキスト検索の結果を抽出します。
stored_data = {}
for row in vector_search_res.result_rows:
stored_data[str(row[0])] = {"title": row[1], "body": row[2]}
for row in text_search_res.result_rows:
if str(row[0]) not in stored_data:
stored_data[str(row[0])] = {"title": row[1], "body": row[2]}
# クエリ結果のIDとスコアを抽出します。
bm25_dict = {"query-0": {str(row[0]): float(row[3]) for row in text_search_res.result_rows}}
# ranxライブラリでは、スコアが高いほど関連性が高いと予想されるため、CosineやL2などのベクトル距離計算方法に対しては前処理が必要です。
max_value = max(float(row[3]) for row in vector_search_res.result_rows)
vector_dict = {"query-0": {str(row[0]): max_value - float(row[3]) for row in vector_search_res.result_rows}}
# クエリ結果のスコアを正規化します。
vector_run = rank_norm(Run(vector_dict, name="vector"))
bm25_run = rank_norm(Run(bm25_dict, name="bm25"))
# RRFを使用してクエリ結果を結合します。
combined_run = fuse(
runs=[vector_run, bm25_run],
method="rrf",
params={'k': 10}
)
print("\nFusion results:")
pretty_results = []
for id_, score in combined_run.get_doc_ids_and_scores()[0].items():
if id_ in stored_data:
pretty_results.append([id_, stored_data[id_]["title"], stored_data[id_]["body"], score])
print_results(pretty_results[:5], ["ID", "Title", "Body", "Score"])
結合クエリの結果は次のとおりです。ハイブリッド検索は、BGLE遠征に関連する5つの記事を正確にマッチングし、短いテキストクエリの処理におけるハイブリッド検索の利点を示しています。
| ID | Title | Body | Score |
|---|---|---|---|
| 47415 | Tadpole Island | Tadpole Island () is an island just north of Ferin Head, off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.06432246998284734 |
| 15145 | Paragon Point | Paragon Point () is a small but prominent point on the southwest side of Leroux Bay, 3 nautical miles (6 km) west-southwest of Eijkman Point on the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.049188640973630834 |
| 48165 | Salmon Island | Salmon Island () is the westernmost of the Fish Islands, lying off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.047619047619047616 |
| 64566 | Want You Back (Haim song) | format=Digital download | recorded= |
| 45934 | Singing All Along | show_name_2= |
# 結論
この文書では、MyScaleハイブリッド検索の使用方法と技術についての洞察を提供しています。具体的な演習では、Wikipediaの要約を使用した例を開発しました。MyScaleの高度な全文検索とベクトル検索の機能を組み合わせることで、ハイブリッド検索を簡単に実行することができ、キーワードと意味情報を組み合わせることでより正確な結果を得ることができます。