
# Búsqueda Híbrida
NOTA
Esta guía solo es aplicable a la versión de DB 1.6.2 o superior.
Esta guía explica cómo realizar una búsqueda híbrida de texto completo y vectorial en MyScale.
La búsqueda de texto completo y la búsqueda vectorial tienen sus propias fortalezas y debilidades. La búsqueda de texto completo es excelente para la recuperación básica de palabras clave y la coincidencia de texto, mientras que la búsqueda vectorial sobresale en la coincidencia semántica entre documentos y la comprensión profunda de la semántica, pero puede carecer de eficiencia en consultas de texto corto. La búsqueda híbrida combina los beneficios de ambos enfoques, mejorando la precisión y velocidad en las búsquedas de texto para satisfacer las expectativas de los usuarios de obtener resultados precisos de manera eficiente.
# Resumen del Tutorial
Esta guía cubre:
- El conjunto de datos de Wikipedia y el modelo de incrustación utilizado para la búsqueda híbrida.
- Instrucciones sobre crear tablas y construir índices.
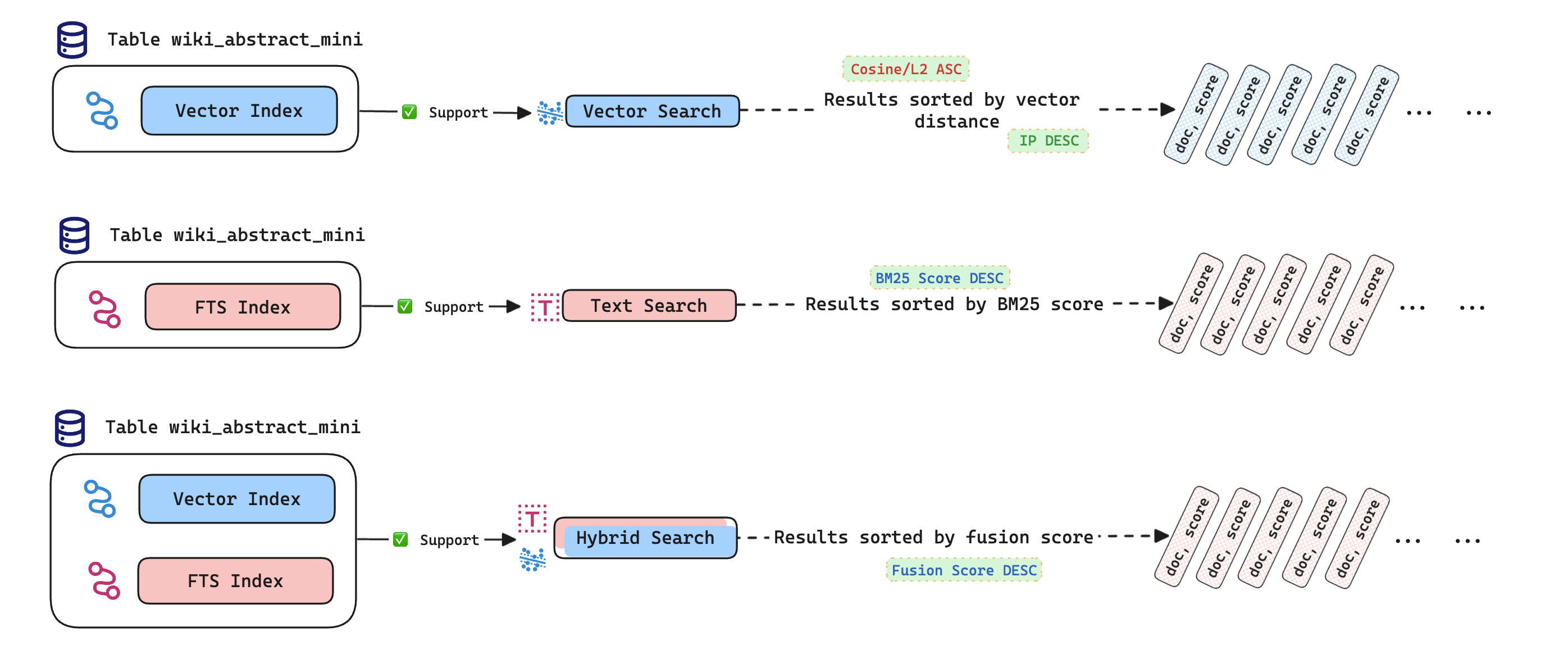
- Cómo utilizar la función
HybridSearch(). - Ejemplos de realizar búsquedas vectoriales, de texto y híbridas.
La función HybridSearch() combina los resultados de las búsquedas vectoriales y de texto, mejorando la adaptabilidad en diferentes escenarios y mejorando la precisión de la búsqueda.
Antes de comenzar, asegúrese de tener configurado un clúster de MyScale. Para obtener instrucciones de configuración, consulte nuestra Guía de inicio rápido (opens new window).
# Conjunto de Datos
El experimento utilizó el conjunto de datos de resúmenes de Wikipedia (opens new window) proporcionado por RediSearch, que consta de 5,622,309 entradas de documentos. Se seleccionaron las primeras 100,000 entradas y se procesaron utilizando el modelo multilingual-e5-large (opens new window) para crear vectores de 1024 dimensiones almacenados en la columna body_vector. La similitud entre los vectores se calculó utilizando la distancia del coseno.
TIP
Para obtener más información sobre cómo utilizar multilingual-e5-large, consulte la documentación de HuggingFace (opens new window).
El conjunto de datos wiki_abstract_100000_1024D.parquet (opens new window) tiene un tamaño de 668MB y contiene 100,000 entradas. Puede obtener una vista previa de su contenido a continuación sin necesidad de descargarlo localmente, ya que lo importaremos directamente en MyScale a través de S3 en los experimentos posteriores.
| id | body | title | url | body_vector |
|---|---|---|---|---|
| ... | ... | ... | ... | ... |
| 78 | A total solar ... the Sun for a viewer on Earth. | Solar eclipse of November 12, 1985 | https://en.wikipedia.org/wiki/Solar_eclipse_of_November_12,_1985 (opens new window) | [1.4270141,...,-1.2265089] |
| 79 | Dhamangaon Badhe is a town ... Aurangabad districts. | Dhamangaon Badhe | https://en.wikipedia.org/wiki/Dhamangaon_Badhe (opens new window) | [0.6736672,....,0.12504958] |
| ... | ... | ... | ... | ... |
# Creación de Tablas e Importación de Datos
Para crear la tabla wiki_abstract_mini en el espacio de trabajo SQL de MyScale, ejecute la siguiente declaración SQL:
CREATE TABLE default.wiki_abstract_mini(
`id` UInt64,
`body` String,
`title` String,
`url` String,
`body_vector` Array(Float32),
CONSTRAINT check_length CHECK length(body_vector) = 1024
)
ENGINE = MergeTree
ORDER BY id
SETTINGS index_granularity = 128;
Importe los datos de S3 a la tabla. Por favor, tenga paciencia durante el proceso de importación de datos.
INSERT INTO default.wiki_abstract_mini
SELECT * FROM s3('https://myscale-datasets.s3.ap-southeast-1.amazonaws.com/wiki_abstract_100000_1024D.parquet', 'Parquet');
Nota
El tiempo estimado para la importación de datos es de aproximadamente 10 minutos.
Verifique si hay 100,000 filas de datos en la tabla ejecutando esta consulta:
SELECT count(*) FROM default.wiki_abstract_mini;
Salida:
| count() |
|---|
| 100000 |
# Construir Índice
# Crear Índice FTS
TIP
Para aprender cómo crear un índice FTS, consulte la documentación de búsqueda de texto.
Al configurar un índice FTS, los usuarios tienen la opción de personalizar el tokenizador. En este ejemplo, se utiliza el tokenizador stem junto con la aplicación de stop words. El tokenizador stem puede pasar por alto los tiempos de las palabras en el texto para obtener resultados de búsqueda más precisos. Al utilizar stop words, se filtran palabras comunes como "a", "an", "of" e "in" para mejorar la precisión de la búsqueda.
ALTER TABLE default.wiki_abstract_mini
ADD INDEX body_idx (body)
TYPE fts('{"body":{"tokenizer":{"type":"stem", "stop_word_filters":["english"]}}}');
Ejecute la materialización del índice:
ALTER TABLE default.wiki_abstract_mini MATERIALIZE INDEX body_idx;
# Crear Índice Vectorial
TIP
Obtenga más información sobre el índice vectorial MSTG en la documentación de búsqueda vectorial.
Para crear el índice vectorial MSTG utilizando la distancia del coseno para el body_vec_idx en la tabla default.wiki_abstract_mini, ejecute esta declaración SQL:
ALTER TABLE default.wiki_abstract_mini
ADD VECTOR INDEX body_vec_idx body_vector
TYPE MSTG('metric_type=Cosine');
La construcción de un índice vectorial puede llevar mucho tiempo. Para monitorear su progreso, ejecute esta consulta SQL. Si la columna de estado muestra Built, el índice se ha creado correctamente. Si muestra InProgress, el proceso aún está en curso.
SELECT * FROM system.vector_indices;
# Función HybridSearch
La función HybridSearch en MyScale realiza búsquedas híbridas combinando los resultados de las búsquedas vectoriales y de texto, devolviendo los principales candidatos. La sintaxis básica es:
HybridSearch('dense_param1 = value1', 'param2 = value2')(vector_column, text_column, query_vector, query_text)
params: Parámetros específicos de la búsqueda. Los parámetros que comienzan condense_son para la búsqueda vectorial. Por ejemplo,dense_alphaestablece el parámetroalphapara el índice vectorial MSTG.vector_column: Columna que contiene los datos vectoriales a buscar.text_column: Columna que contiene los datos de texto a buscar.query_vector: Vector a buscar.query_text: Texto a buscar.
Utilice la función HybridSearch con una cláusula ORDER BY y una cláusula LIMIT para recuperar los principales candidatos. La dirección de ordenación de las columnas en la cláusula ORDER BY debe establecerse en DESC.
# Parámetros de HybridSearch Explicados
A continuación se muestra una descripción detallada de los parámetros de HybridSearch():
| Parameter | Default Value | Candidate Values | Description |
|---|---|---|---|
fusion_type | N/A | rsf, rrf | Determines the combination method in hybrid search. rsf stands for Relative Score Fusion, and rrf stands for Reciprocal Rank Fusion. This parameter is required. |
fusion_weight | 0.5 | Floating point number between 0 - 1 | Specifies the weight |
fusion_k | 60 | Positive integer no less than 1 | Specifies the sorting constant |
enable_nlq | true | true, false | Indicates whether to use natural language queries in text search. |
operator | OR | OR, AND | Specifies the logical operator used to combine terms in text search. |
# Tipos de Fusión
La búsqueda híbrida combina la puntuación BM25 de las búsquedas de texto (denotada como
- Fusión de Puntuación Relativa (RSF): En RSF, las puntuaciones de las búsquedas vectoriales y de texto se normalizan entre 0 y 1. La puntuación más alta se establece en 1, mientras que la más baja se establece en 0, y todos los demás valores se clasifican proporcionalmente dentro de este rango. La puntuación final es una suma ponderada de estas puntuaciones normalizadas:
La fórmula de normalización utilizada es:
- Fusión de Rango Recíproco (RRF): RRF no requiere normalización de puntuaciones. En su lugar, clasifica los resultados en función de sus posiciones en cada conjunto de resultados utilizando la siguiente fórmula, donde
# Realizar Búsqueda Vectorial, de Texto y Híbrida
# Crear una Función de Incrustación
Para convertir el texto de consulta en vectores, utilizaremos el modelo multilingual-e5-large (opens new window).
Gracias a las funciones de incrustación de MyScale, convertir el texto en vectores en línea es sencillo. Crearemos una función de incrustación, MultilingualE5Large, con este propósito.
TIP
Necesitará una clave gratuita de HuggingFace para crear una función de incrustación.
CREATE FUNCTION MultilingualE5Large
ON CLUSTER '{cluster}' AS (x) -> EmbedText (
concat('query: ', x),
'HuggingFace',
'https://api-inference.huggingface.co/models/intfloat/multilingual-e5-large',
'<your huggingface key, starts with `hf_`>',
''
);
# Ejecutar Búsqueda Vectorial
TIP
La expedición británica a Graham Land (BGLE) fue una expedición británica. Para obtener información detallada sobre ellos, consulte Wikipedia (opens new window).
La búsqueda vectorial generalmente funciona bien en el dominio de textos largos, pero su efectividad puede disminuir en el ámbito de textos cortos. Para ilustrar el rendimiento de la búsqueda en diferentes longitudes de texto, presentaremos dos ejemplos de búsquedas vectoriales. El contenido que estamos buscando se refiere a ubicaciones marcadas por el equipo de la expedición BGLE, siendo la diferencia entre las dos oraciones si se utiliza o no la abreviatura del nombre del equipo.
- Ejemplo 1. consulta de texto largo: 'Cartografiado por la Expedición Británica a Graham Land'
SELECT
id,
title,
body,
distance('alpha=3')(body_vector, MultilingualE5Large('Cartografiado por la Expedición Británica a Graham Land')) AS score
FROM default.wiki_abstract_mini
ORDER BY score ASC
LIMIT 5;
A partir de los resultados de búsqueda a continuación, es evidente que la búsqueda vectorial sobresale en la coincidencia de textos largos, con cuatro de los cinco mejores resultados de búsqueda cumpliendo con nuestros criterios.
| id | title | body | score |
|---|---|---|---|
| 15145 | Paragon Point | Paragon Point () is a small but prominent point on the southwest side of Leroux Bay, 3 nautical miles (6 km) west-southwest of Eijkman Point on the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.17197883 |
| 16459 | Link Stack | Link Stack () is a rocky pillar at the northwest end of Chavez Island, off the west coast of Graham Land, Antarctica. It was charted by the British Graham Land Expedition under John Rymill, 1934–37. | 0.17324567 |
| 47359 | Huitfeldt Point | Huitfeldt Point is a point southeast of Vorweg Point on the southwest side of Barilari Bay, on the west coast of Graham Land, Antarctica. It was charted by the British Graham Land Expedition under John Rymill, 1934–37, and was named by the UK Antarctic Place-Names Committee in 1959 for Fritz R. | 0.17347288 |
| 48138 | Santos Peak | Santos Peak () is a peak lying south of Murray Island, on the west coast of Graham Land. Charted by the Belgian Antarctic Expedition under Gerlache, 1897-99. | 0.17546016 |
| 15482 | Parvenu Point | Parvenu Point () is a low but prominent point forming the north extremity of Pourquoi Pas Island, off the west coast of Graham Land. First surveyed in 1936 by the British Graham Land Expedition (BGLE) under Rymill. | 0.17611909 |
- Ejemplo 2. consulta de texto corto: 'Cartografiado por la BGLE'
SELECT
id,
title,
body,
distance('alpha=3')(body_vector, MultilingualE5Large('Cartografiado por la BGLE')) AS score
FROM default.wiki_abstract_mini
ORDER BY score ASC
LIMIT 5;
Sin embargo, al examinar los resultados de búsqueda para textos cortos, queda claro que la búsqueda vectorial es menos efectiva en este dominio, ya que ninguno de los cinco primeros documentos contiene información sobre BGLE.
| id | title | body | score |
|---|---|---|---|
| 17693 | Têtes Raides | | current_members = Christian OlivierGrégoire SimonPascal OlivierAnne-Gaëlle BisquaySerge BégoutÉdith BégoutPierre GauthéJean-Luc MillotPhilippe Guarracino | 0.19922233 |
| 92351 | Badr al-Din Lu'lu' | right|thumb|250px|Badr al-Din Lu'lu', manuscript illustration from the Kitāb al-Aghānī of [[Abu al-Faraj al-Isfahani (Feyzullah Library No. 1566, Istanbul). | 0.19949186 |
| 45934 | Singing All Along | |show_name_2=|simplified=|pinyin=Xiùlì Jiāngshān Zhī Cháng Gē Xíng|translation=Splendid and Beautiful Rivers and Mountains: Long Journey of Songs}} | 0.2003029 |
| 44708 | LinQ | | current_members =Yumi TakakiSakura ArakiAyano YamakiMYUChiaki Sara YoshikawaRana KaizukiAsaka SakaiKana FukuyamaManami SakuraMaina KohinataChisa Ando | 0.20089924 |
| 43706 | Shorty (crater) | | diameter = 110 mShorty, Gazetteer of Planetary Nomenclature, International Astronomical Union (IAU) Working Group for Planetary System Nomenclature (WGPSN) | 0.20098251 |
# Ejecutar Búsqueda de Texto
BM25, un algoritmo de búsqueda de texto ampliamente utilizado, es muy maduro y especialmente adecuado para la coincidencia de texto corto. Sin embargo, cuando se trata de comprender la semántica de textos largos, BM25 no es tan efectivo como la búsqueda vectorial. Lo siguiente demuestra las poderosas capacidades de búsqueda de TextSearch() en el campo de texto corto.
- Ejemplo. consulta de texto corto: 'Cartografiado por la BGLE'
SELECT
id,
title,
body,
TextSearch(body, 'Cartografiado por la BGLE') AS bm25_score
FROM default.wiki_abstract_mini
ORDER BY bm25_score DESC
LIMIT 5;
| id | title | body | bm25_score |
|---|---|---|---|
| 48165 | Salmon Island | Salmon Island () is the westernmost of the Fish Islands, lying off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 15.392099 |
| 47415 | Tadpole Island | Tadpole Island () is an island just north of Ferin Head, off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 15.126007 |
| 48775 | Sohm Glacier | Sohm Glacier () is a glacier flowing into Bilgeri Glacier on Velingrad Peninsula, the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 15.126007 |
| 14327 | Trout Island | Trout Island () is an island just east of Salmon Island in the Fish Islands, off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 14.620504 |
| 49006 | Somers Glacier | Somers Glacier () is a glacier flowing northwest into Trooz Glacier on Kiev Peninsula, the west coast of Graham Land. First charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 14.620504 |
# Ejecutar Búsqueda Híbrida
MyScale proporciona la función HybridSearch(), un método de búsqueda que combina las fortalezas de la búsqueda vectorial y la búsqueda de texto. Este enfoque no solo mejora la comprensión de la semántica de textos largos, sino que también aborda las deficiencias semánticas de la búsqueda vectorial en el dominio de textos cortos.
- Ejemplo. consulta de texto corto: Cartografiado por la BGLE
SELECT
id,
title,
body,
HybridSearch('fusion_type=RSF', 'fusion_weight=0.6')(body_vector, body, MultilingualE5Large('Cartografiado por la BGLE'), ' BGLE') AS score
FROM default.wiki_abstract_mini
ORDER BY score DESC
LIMIT 5;
Según los resultados obtenidos de la función HybridSearch(), podemos obtener excelentes resultados de búsqueda incluso al buscar textos cortos, con una precisión significativamente mejorada.
| id | title | body | score |
|---|---|---|---|
| 48165 | Salmon Island | Salmon Island () is the westernmost of the Fish Islands, lying off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.6 |
| 47415 | Tadpole Island | Tadpole Island () is an island just north of Ferin Head, off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.5404912 |
| 48775 | Sohm Glacier | Sohm Glacier () is a glacier flowing into Bilgeri Glacier on Velingrad Peninsula, the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.5404912 |
| 49000 | Sooty Rock | Sooty Rock () is a rock midway between Lumus Rock and Betheder Islands in Wilhelm Archipelago. Discovered and named "Black Reef" by the British Graham Land Expedition (BGLE), 1934-37. | 0.5404912 |
| 14327 | Trout Island | Trout Island () is an island just east of Salmon Island in the Fish Islands, off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.4274415 |
Dalla versione del database v1.8 o successiva, è consentito utilizzare una colonna di ricerca del testo nella funzione HybridSearch() da un indice FTS multi-colonne.
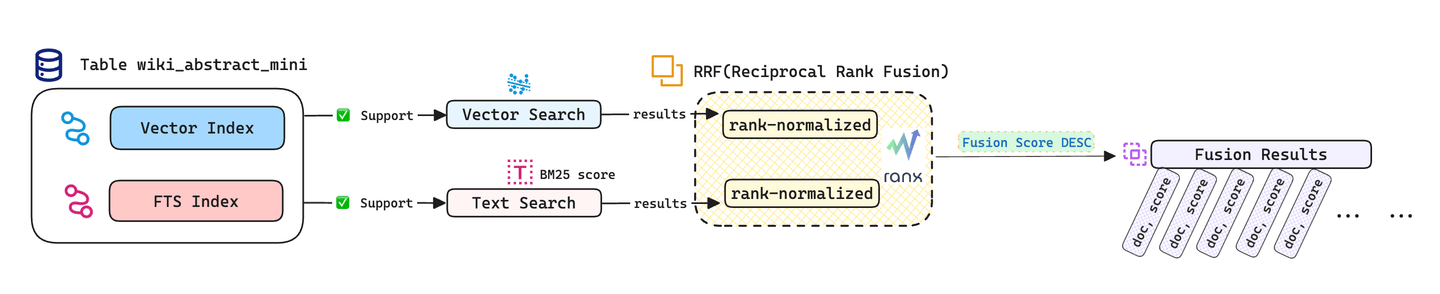
# Búsqueda Híbrida Fuera de la Base de Datos
También podemos utilizar la biblioteca ranx (opens new window) en Python para combinar los resultados de búsqueda vectorial y de texto fuera de la base de datos, implementando la estrategia de fusión RRF (Reciprocal Rank Fusion) para mejorar la precisión de la búsqueda. Para obtener estrategias de fusión alternativas, consulte ranx/fusion (opens new window).
Antes de ejecutar el código de demostración a continuación, debe instalar ranx:
pip install -U ranx
Código de ejemplo en Python:
import clickhouse_connect
from numba import NumbaTypeSafetyWarning
from prettytable import PrettyTable
from ranx import Run, fuse
from ranx.normalization import rank_norm
import warnings
warnings.filterwarnings('ignore', category=NumbaTypeSafetyWarning)
# Información de MyScale
host = "su punto final de clúster"
port = 443
username = "su nombre de usuario"
password = "su contraseña"
database = "default"
table = "wiki_abstract_mini"
# Inicializar cliente de MyScale
client = clickhouse_connect.get_client(host=host, port=port, username=username, password=password)
# Utilice una tabla para mostrar su contenido
def print_results(result_rows, field_names):
x = PrettyTable()
x.field_names = field_names
for row in result_rows:
x.add_row(row)
print(x)
# Queremos buscar un texto corto.
terms = "Cartografiado por BGLE"
# Ejecutar VectorSearch.
vector_search = f"SELECT id, title, body, distance('alpha=3')" \
f"(body_vector, MultilingualE5Large('{terms}')) AS distance FROM {database}.{table} " \
f"ORDER BY distance ASC LIMIT 100"
vector_search_res = client.query(query=vector_search)
# Ejecutar TextSearch.
text_search = f"SELECT id, title, body, TextSearch(body, '{terms}') AS score " \
f"FROM {database}.{table} " \
f"ORDER BY score DESC LIMIT 100"
text_search_res = client.query(query=text_search)
# Extraer resultados de VectorSearch y TextSearch.
stored_data = {}
for row in vector_search_res.result_rows:
stored_data[str(row[0])] = {"title": row[1], "body": row[2]}
for row in text_search_res.result_rows:
if str(row[0]) not in stored_data:
stored_data[str(row[0])] = {"title": row[1], "body": row[2]}
# Extraer id y puntuación de los resultados.
bm25_dict = {"query-0": {str(row[0]): float(row[3]) for row in text_search_res.result_rows}}
# Para la biblioteca ranx, se espera que una puntuación más alta indique una mayor relevancia,
# por lo tanto, se requiere un preprocesamiento para los métodos de cálculo de distancia vectorial como Coseno y L2.
max_value = max(float(row[3]) for row in vector_search_res.result_rows)
vector_dict = {"query-0": {str(row[0]): max_value - float(row[3]) for row in vector_search_res.result_rows}}
# Normalizar puntuación de resultados de consulta.
vector_run = rank_norm(Run(vector_dict, name="vector"))
bm25_run = rank_norm(Run(bm25_dict, name="bm25"))
# Fusionar resultados de consulta utilizando RRF.
combined_run = fuse(
runs=[vector_run, bm25_run],
method="rrf",
params={'k': 10}
)
print("\nResultados de fusión:")
pretty_results = []
for id_, score in combined_run.get_doc_ids_and_scores()[0].items():
if id_ in stored_data:
pretty_results.append([id_, stored_data[id_]["title"], stored_data[id_]["body"], score])
print_results(pretty_results[:5], ["ID", "Título", "Cuerpo", "Puntuación"])
Los resultados de la consulta de fusión son los siguientes: la búsqueda híbrida coincidió con precisión cinco artículos relacionados con las ubicaciones cartografiadas por la expedición BGLE, mostrando los beneficios de la búsqueda híbrida para procesar consultas de texto corto.
| ID | Title | Body | Score |
|---|---|---|---|
| 47415 | Tadpole Island | Tadpole Island () is an island just north of Ferin Head, off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.06432246998284734 |
| 15145 | Paragon Point | Paragon Point () is a small but prominent point on the southwest side of Leroux Bay, 3 nautical miles (6 km) west-southwest of Eijkman Point on the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.049188640973630834 |
| 48165 | Salmon Island | Salmon Island () is the westernmost of the Fish Islands, lying off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.047619047619047616 |
| 64566 | Want You Back (Haim song) | format=Digital download | recorded= |
| 45934 | Singing All Along | show_name_2= |
# Conclusión
Este documento proporciona información sobre el uso de la búsqueda híbrida de MyScale, centrándose en métodos y técnicas para buscar datos de texto no estructurados. En el ejercicio práctico, desarrollamos un ejemplo utilizando resúmenes de Wikipedia. Realizar una búsqueda híbrida es fácil con las capacidades avanzadas de búsqueda de texto completo y vectorial de MyScale, y produce resultados más precisos al combinar información de palabras clave y semántica.